Lucenegraphcore
graphcore 时间:2021-03-26 阅读:()
Semi-AutomatedPreventionandCurationofDuplicateContentinSocialSupportSystemsIgorA.
PodgornyIntuit,Inc.
SanDiego,USAigor_podgorny@intuit.
comChrisGielowIntuit,Inc.
SanDiego,USAchris_gielow@intuit.
comABSTRACTTurboTaxAnswerXchangeisapopularsocialQ&AsystemsupportingusersworkingonU.
S.
federalandstatetaxreturns.
Basedonacustom-builtduplicatescoringmodel,35%ofAnswerXchangequestionshavebeenfoundtobenear-duplicatesresponsiblefor56%ofAnswerXchangedocumentviews.
Thisdegradestheuserexperienceforboththeaskerwhoisunabletofindanansweramidduplicates,andtheanswererwhoisunabletoefficientlyansweratscale.
Theduplicatequestionstendtoformmicro-clustersthatgrowviapreferentialattachmentand,onceexceedingsome25questionsinsize,startmorphingintomega-clusterswithacomplexnetworktopology.
Thisbehaviorcanbeleveragedtodesignsemi-automatedcontentcurationsystemstodetectwhetheranewlypostedquestionisaduplicateand,ifso,whichduplicateclusteritbelongsto.
InordertoimproveuserexperienceinAnswerXchange,weexplorehowhumanandartificialintelligencecanbejointlyemployedandthenpresentseveraldata-drivenintelligentuserinterfaces.
Theduplicatescoringmodelscanbeutilizedaselementsofquestion-postingandansweringexperiences,unansweredquestionqueueingandanswerbots.
TheseapproachescanbeextendedtoanysocialsupportQ&Asystemwhereduplicatepostingnegativelyimpactssearchrelevanceandcontentconsumption.
AuthorKeywordsTurboTax;AnswerXchange;CQA;communityquestionanswering;socialquestionanswering;duplicateclusters;contentdeduplication.
ACMClassificationKeywordsH.
5.
m.
InformationInterfacesandPresentation(e.
g.
HCI):MiscellaneousINTRODUCTIONSocialQ&Asystemsprovideaconvenientself-supportoptionfortaxandfinancialsoftwareapplicationswherepersonalizedlong-tailcontentgeneratedbytheuserscansupplementcuratedknowledgebaseanswers.
Usersoftenpreferself-helptoassistedmeasures(e.
g.
phonesupportoronlinechat)andareoftenabletofindandapplytheirsolutionfaster.
Thisalsoreducestheloadonassistedchannels,ensuringtheyremainavailabletothosewhoneedit.
AnswerXchange(http://ttlc.
intuit.
com)isasocialQ&AsitewherecustomerscanlearnandsharetheirknowledgewithotherTurboTaxcustomerswhilepreparingU.
S.
federalandstatetaxreturnsandalsofindstep-by-stepinstructionsonusingtheTurboTaxapplication[5,6].
AstheusersstepthroughtheTurboTaxinterviewpages,theycanaskquestionsaboutsoftwareandtaxtopics(Figure1)andreceiveanswersinamatterofminutes.
AnswerXchangehasgeneratedmillionsofquestionsandanswersthathavehelpedtensofmillionsofTurboTaxcustomerssincelaunchingin2007.
Figure1.
AnswerXchangequestion-postinguserexperience.
Questiontitle(ashortsummaryofquestionlimitedto255characters)ismandatory.
Questiondetails(notshown)areoptionalandunlimitedinsize.
Themajorityofuserscanfindanswersbysearchingtheexistingcontent.
Theoverallqualityofacustomerself-helpsystemisthereforedeterminedbyhowwelltheself-helpsystemassistsinfindingtherelevantcontent.
Thenumberofsearchsessionsresultinginassistedsupportcontacts(beingaslargeashundredsofthousandsofcustomersperyear)andfractionofuserupordownvotesonself-supportcontentprovideaconvenientproxymetricsofcontentqualityandsearchrelevanceinTurboTaxself-help[5].
2018.
Copyrightfortheindividualpapersremainswiththeauthors.
Copyingpermittedforprivateandacademicpurposes.
ESIDA'18,March11,Tokyo,Japan.
Figure2.
AnexampleofduplicateAnswerXchangesearchresults.
Questiontitlesandanswersnippetsareshowninpurpleandinblack,respectively.
Oneproblemwiththeexistingquestion-postingexperience(Figure1)isthatsearchesmayresultinmultipleandoftenduplicateanswersthatarerelativelyclosetotheintentoftheoriginalquestion,butstilldonotmatchtheoriginalsearchintent(Figure2).
Thisinterfereswiththeuser'sabilitytoselectfromadiversesetofpossibleanswers[5]and,oftenresultseitherinthesubmissionofaduplicatequestionorswitchingtoaless-desiredsupportchannel.
Arelatedproblemisthatusersmaysubmitpoorqualityquestionsbynotprovidingalloftherelevantinformationneededforagoodqualityanswer[5].
Onesolutionisamanualreviewoftheusergeneratedcontenttoarchivesomeoftheduplicatequestionsandrelatedanswers,ifany,andkeepingthebestperformingcontentin"live"status(i.
e.
makingitavailableforsearch).
Thisapproachislaborintensiveanddoesnotaddresstheproblemwiththequestion-postinguserexperience.
Duplicatequestionsmayquicklybuildup,addingunnecessaryburdenoncommunityquestionansweringalongtheway.
ThegoalofthisstudyistoaddresstheproblemsofduplicatecontentpreventioninAnswerXchangebycombiningmachinelearningandintelligentuserinterfaces.
Inwhatfollows,wedescribeduplicatedetectionalgorithmsdevelopedearlierandpresentacustommodeltrainedonAnswerXchangequestions.
Next,weintroducetheconceptof"duplicateclusters"thatprovideaframeworkforsemi-automatedduplicatecontentprevention.
Finally,wepresentseveralcustomdesigneddata-drivenintelligentuserinterfacesforaddressingduplicatecontentproblem.
RELATEDWORKThetaskofestimatingsemanticsimilarityoftextdocumentshasmultiplepracticalapplicationsandisofgrowinginterestfromtheresearchcommunity.
Theareasofresearchincludewebpagesimilarity,documentsimilarity,sentencesimilarity,searchquerysimilarityandutterancesimilarityinconversationaluserinterfaces.
Thesetasksarealsorelatedtoamoregeneralproblemofdetectingduplicatesindatabaserecords[2].
QuestionsinsocialQ&Asystemsmediaareoftenconfinedtooneortworelativelyshortsentencesandmaywarrantdomainspecificapproachestoaddressingquestionsimilarity.
Forexample,twoquestionsinasocialQ&Asystemcanbeconsideredsemanticallyidenticalifasingleanswersatisfiestheneedsofbothoriginalaskers[3].
Theanswermaynotyetexistintheproductiondatabasebutcouldbegeneratedifneeded.
Thetaskofduplicate-questiondetectionisalsorelatedtothetaskofre-formulatinganewlyformedquestion[6]andautomaticallyfindingananswertoanewquestion[8].
Themostrecentresultsintheareaofduplicatecontentscoringcamefromthe2017Kaggle"QuoraPair"competitionwithmodelsubmissionsfrommorethan3,000teams(https://www.
kaggle.
com/c/quora-question-pairs).
Inthiscompetition,theparticipantsweretaskedtoclassifyifQuoraquestionpairsareduplicatesornotbasedon200,000traininginstances.
Finally,SemEval2017TaskonCommunityQuestionAnswering("Question–CommentSimilarity","Question–QuestionSimilarity",etc.
)resultedinsubmissionsfrom23teams[4].
TheproblemofduplicatedetectionandcurationiscloselyrelatedtothetaskofpredictingcontentqualityinsocialQ&Asystems.
Contentqualitymetricsmaybehelpfulinselectingthebestperformingquestionandanswerfortheduplicate-questionpair.
AnswerandquestionqualityinthesocialQ&Asystemshasbeenthefocusofincreasingattentionfromthescientificcommunity[1,9].
DUPLICATE-SCORINGMODELAnswerXchangeSearchAnswerXchangesearchisbuiltwithApacheLuceneopen-sourcesoftware(http://lucene.
apache.
org).
Bydefault,Luceneuses"tf-idf"(https://en.
wikipedia.
org/wiki/tf-idf)and"cosine-similarity"asstandardmethodsofrankingsearchresults.
Shorterdocumentswiththesamesetofmatchingkeywordstypicallyrankhigherthanlongerdocumentswithsimilarsemanticmeaning.
AnaverageAnswerXchangesearchqueryis2-3termslong(i.
e.
shorterthanatypicalAnswerXchangequestion)anditisoftencomparableinlengthwiththetitleofapotentiallyduplicatequestion.
ThequestiondetailsplayalesserrolecomparedtotitlescontributingtoextraboostingofduplicatecontentbyLucene.
TheAnswerXchangeLucenerankingalgorithmtendstoboostnewcontentandalsoaccountsforvariousmetadatasuchashelpfulnessvotes.
TrainingDataTheproblemofnear-duplicatedetectioncanbeformulatedasanunsupervisedorsupervisedmachinelearningtask[7].
Intheunsupervisedcase,duplicatepairsandclusterscanbefoundbasedondistancemetricssuchascosine-similarityoftheweightedtf-idfvectors,Jaccardsimilaritycoefficient,distanceinword2vecspace,etc.
Inthesupervisedcase,theproblemoffindingtopicalnear-duplicaterelationscanbeformulatedasfollows:givenapairofquestions,themachinelearntmodelhastopredicta"duplicatescore"anddetermineifquestionsareduplicatesbasedonapre-definedthreshold.
Inthispaper,weemploya"hybrid"approachstartingwithcosine-similaritymetricsfordatapre-processingandthenaddingamoreaccuratecustom-builtscoringmodeltotheprocessingpipeline.
AsthefractionofduplicatepairsinAnswerXchangeisrelativelylow,thequestionpairsrankedbycosine-similarityprovideaconvenientdatasetforlabelingbasedontheimportancesamplingapproach.
Towardsthisgoal,wecomputedbag-of-wordscosine-similarity(AppendixA)for790,000questionsavailableforsearchinAnswerXchangeattheendof2017U.
S.
TaxDay(April18).
Next,fourAnswerXchangemoderatorsaddedclasslabels(0or1)toarandomsampleof4,000near-duplicatepairs.
Instancesopentodoubthavebeenflaggedbymoderatorsandthenre-labeledbyaconsensus.
1,000randomlysamplednon-duplicatepairshavebeenaddedforthefinalversionofthetrainingdatasettomakeitequallydividedbetweenduplicateandnon-duplicatepairs.
Duplicate-ScoringModelFeaturesThemodelfeaturescanbelearntfromtrainingdataand/orbyknowledgeacquisitionfromAnswerXchangemoderators.
Wehaveusedthefollowingmodelfeatures:Cosine-similaritywithtf-idfweighting(seeAppendixA).
ProbabilistictopicIDofthequestioncomputedwithLatentDirichletAllocation(seeAppendixA).
U.
S.
taxyearinthequestion.
Distinctwordsinthequestionpair.
Commonwordsinthequestionpair.
Typeofthequestion(e.
g.
"closed-ended"questions"CanIdeduct…"typicallyaccountfortaxrelated,while"how"questionsoftenaccountforproductrelatedquestion).
Firstwordofthequestion.
Duplicate-ScoringModelPerformanceBasedonthesetof5,000labeledquestionpairs,wetrainedandtestedalinear(logisticregression)andnon-linear(randomforest)binaryclassifiersusingPythonmachinelearninglibrary"scikit-learn".
Themodelpredictsclasslabel(0foranon-duplicateand1forduplicatepair)andalsotheduplicatescore(i.
e.
probabilityofthequestionpairtobelongtoeitherclassrangingfrom0.
0to1.
0)thatcanbeusedtoselectuserexperiencebasedonpredefinedthreshold(s).
Wealsotrainedaseparateversionofthelogisticregressionclassifierusingcosine-similarityasasinglemodelfeature.
ShowninTable1arecommonmetricsusedforpredictivemodelevaluation:areaundercurve(AUC)forreceiveroperatingcharacteristic,F1scoreandlogarithmicloss(logloss)functionforclassification.
ModelAUCF1ScoreLogLossLogisticRegression0.
950.
880.
27RandomForest0.
940.
870.
31Cosine-similarity0.
830.
730.
48Table1.
Modelperformancemetricsforduplicate-scoringmodels(detailsareexplainedinthetext).
AsseenfromTable1,bothlogisticregressionandrandomforestmodelsachieveperformancethatisconsistentwiththegoalsofthisexploratorystudy.
Atthesametime,cosine-similarityversionunderperformsthefirsttwobyawidemargin.
Thiscanbeexplainedbytheinabilitytofindanoptimalthresholdseparatingduplicateandnon-duplicatepairsusingthecosine-similarityalone.
Thefollowingtwoexamplesillustratetherelationshipbetweenkeyword-basedcosine-similarityandduplicate-questionscorecomputedwithlogisticregression.
ThefirstexampleisanAnswerXchangequestionpairwitharelativelylowcosine-similarityof0.
61:(1)"Ineedacopyofmyfederaltaxreturnfor2014"and(2)"Ineed2015TaxReturn".
BothquestionscanbeansweredwithasingleinstructionaboutgettingacopyofprioryeartaxreturnfiledwithTurboTaxandhenceareduplicates.
Thesecondexampleisaquestionpairwithhighcosine-similarityof1.
0:(1)"doihavetofilestatetaxes"and(2)"howtofilestatetaxes".
Thesequestionsarenotduplicatesbecausetheybelongtotaxandproductcategories[5],respectively,andwouldrequiretwodifferentanswers.
DUPLICATECLUSTERSPreferentialAttachmentandTopologyAfteridentifying5,597,799duplicatequestionpairsinAnswerXchange(AppendixA),webuiltanundirectedgraphof281,031duplicatequestions.
Eachduplicatepairandduplicatequestionidentifiedwiththemodelconstitutedgraphedgeandgraphvertex,respectively.
Theresultinggraphconsistsof14,616connectedcomponentshereafterreferredtoas"duplicateclusters.
"Toexploreduplicate-clusterscalingbehavior,werankedclustersbythenumberofquestionsandplottedthenumberofquestionsperclustervs.
clusterrankinlog-logscale(Figure3).
Thelargestclusterhas23,236questionsandthesmallestonesonlyhavetwo.
Theplotalsoincludesgraph(oredge)density:=21,whereEisnumberofedges(i.
e.
duplicatepairs)andVisthenumberofvertices(i.
e.
questions).
Graphdensityisequalto1.
0forthefullyconnectedgraphs.
Inthelattercase,eachquestionintheclusterisconnectedtoallremainingquestionsinthesameduplicatecluster.
Basedonbothquestioncountsandgraphdensity,theduplicateclustersinFigure3canbedividedintothreedistinctgroupsmarkedasmega-clusters,transitionalclustersandmicro-clusters.
Thesegroupsaccountfor84%,2%and14%ofduplicatequestions,respectively.
Figure3.
Scalingbehaviorofduplicateclusters(blackdots)inAnswerXchangequestions.
Theclustersarerankedbythenumberofquestionsinthedescendingorder.
Graphdensityfortheclustersisshowningray.
CyanandreddotsrefertotheclustersshowninFigures4and5,respectively.
Anexampleofmicro-clusterwith23verticesisshowninFigure4.
Graphdensityis0.
54andmostofverticesareinterconnectedwithanexceptionofthreeverticesconnectedbybridgestoadensergraphcore.
Thecorrespondingarticulationpointsaremarkedbybluedots.
Notethatevenifquestions1and2areduplicatesandquestions2and3areduplicates,thisdoesnotmeanthatquestions1and3areduplicatesaswell.
Thisexplainswhyaduplicate-clusterdensityistypicallylessthan1.
0unlessthegraphsizeislimitedtotwoquestions.
AsseenfromFigure3,micro-clusterscalingbehaviorfollowsZipfdistribution(https://en.
wikipedia.
org/wiki/zipf's_law):=+,,whererrangesfromabout100tothetotalnumberofclustersR.
Accordingly,thegrowthofN(Δ)andR(Δ)wouldbeconstrainedbythefollowingequation:Δ=Δ.
ItisworthmentioningthatZipfdistributionisanasymptoticcaseofamoregeneralYule-Simondistribution(https://en.
wikipedia.
org/wiki/Yule-Simon_distribution)typicalforthepreferentialattachmentprocess,meaningthatanewlypostedduplicateismorelikelytobecomeattachedtotheexistingclusterthantoformanewduplicatepair.
Thescalingparameterforthemicro-clusters:=log4log5log(4)log(5)canbeestimatedas0.
6.
ByextrapolatingZipfdistributiontor=1(thatwouldcorrespondtoanon-existinglargestmicro-cluster),onecanestimateNvalueas400.
Thisvalue,however,isalmosttwoordersofmagnitudelessthanthenumberofquestionsinthetopmega-cluster.
Figure4.
Amicro-clustermarkedbycyandotinFigure3.
Articulationpointsareshownbysmallerbluedots.
ToexplainthescalebreakinthedistributionshowninFigure3,letusexaminelargerduplicateclustersinmoredetail.
ShowninFigure5isamega-clusterwith4,549questions.
Theclusterhasdensityequalto0.
0017and1048articulationpoints.
Thismeansthatthemega-clustersmayconsistofmultiplesub-clustersthataresemanticallyrelatedtoeachotherbutwiththeelementsthatarenotduplicatesunlesstheybelongtothesamesub-cluster.
Figure5.
SameasinFigure4,butnowforamega-cluster.
Asthenumberofduplicatesreachescertainlevel,theclustersstartcoalescingbyestablishingbridgeswithotherclusters,duplicatepairsandstand-alonequestions,quicklyevolvingfromdenseconnectedgraphstosparsegraphswithacomplexnetworktopology.
TheareaoftransitionismarkedastransitionalclustersinFigure3.
Semi-AutomatedDuplicateContentCurationWhilethetaskofduplicatecontentarchivingisstraightforwardonceduplicatepairsarefound(AppendixA),theduplicatecontentcanbuildupagainunlessquestion-postingand/orsearchexperiencesaremodified.
Ournextgoalisthereforetoexplorehowtheconceptofduplicateclustersdiscussedintheprevioussectioncanbeappliedtothesetasks.
Thecurationofmicro-clusterscanbedoneautomaticallyorsemi-automatically(i.
e.
withminimumhumaninvolvement)byretainingoneorfewbestperforminglong-taildocuments(i.
e.
documentsthatincludebothquestionsandanswers)andassigningthemaclusterIDforsubsequentre-use.
Thecurationofmega-clustersrepresentsamorechallengingproblem.
First,asinglebestperformingdocumentinamega-clustermaysimplynotexistsincetheclustermaycontainmultiplesub-clustersconnectedbybridges.
Second,duplicatecurationbyahumanisacumbersometaskduetothemega-clustercomplextopology.
Whiletheexactsolutionmaysimplynotexist,approximatesolutionsmaybesufficienttoreducethenumberofduplicatespostedintheAnswerXchangetoanacceptablelevel.
Oneapproachwouldbetobreakthemega-clustersintosmallerpartsbydeletingbridgesinthegraphorbyemployingaconventionalhierarchicalclustering.
Forexample,theduplicateclustershowninFigure5canbesplitto1363connectedcomponentsbyremovingallarticulationpoints(bluedotsinFigure5).
Mostoftheresultingconnectedcomponents,however,aredisconnecteddocuments.
Amorepracticalapproachistoarchivenon-performingshort-tailcontentfromthemega-clusterandcuratetheresultingconnectedcomponents.
ShowninFigure6isasubsetofmega-clusterfromFigure5thatnowonlyincludesdocumentswithatleast100views.
Thisresultsinbreakingtheoriginalmega-clusterinto68connectedcomponentswhichareeasiertocurate.
Figure6.
Asubsetofthemega-clustershowninFigure5.
GreydotsmarkdocumentsusedinFigure7.
Thenexttaskistopresentduplicatecontentinaformsuitableforsemi-automatedcontentcuration.
Figure7showsanexampleofduplicatecontentmetricsforeightdocumentswithatleast1000views.
Theleftcolumnisasub-clusterIDfollowedbyapostIDidentifyinganAnswerXchangedocumentconsistingoftheoriginalquestionandallaccumulatedanswers(notshown).
Thetextofthequestionandtypeofthequestion(i.
e.
user-generatedcontentmarkedasUGCorknowledgebasecontentlabeledasFAQ)areincludedinthethirdandfourthcolumns,respectively.
Thelasttwocolumnsareviewsaccumulatedoveragivenperiodandpercentageofup-votes.
Thedocumentscanberankedbyviewsand/orvotesprovidingamechanismofidentifyingandremovingnon-performingcontenteithermanuallyorautomaticallybasedonasetofpredefinedcontentqualitythresholds.
Figure7.
DuplicatedocumentmetricsforthedocumentsmarkedbygreydotsinFigure6.
Duplicatemetricscanbeoperationalizedbyaddinganalgorithmtomatchthebestquestiontothebestanswerinthesub-cluster.
Suchasystemwouldincludeanswerdeletingandmergingmanuallyorautomaticallybyattachingautomaticallygenerated"best"answertothe"best"duplicatequestion.
Thesolutioncanbeimplementedasaback-endtoolfortrustedusersassignedtothetaskofduplicatearchivingandhiddenfromthelessexperiencedregularusers.
Thesolutiongoesbeyondsimpleduplicatearchivingbyprovidinganoptiontomergeavailableanswerstotheexistingduplicatequestions.
Thenon-humanpartofthesolutionincludesqualityrankingoftheexistinganswers,e.
g.
upanddownvotestatisticsasshowninFigure7.
Inthisway,thenewlyformedquestion-answerpairsprovidebetterqualitycontentavailableforsearchbycombiningthevisuallyappealingquestionsandthebestrankedanswers.
Thisisdonebycombiningartificialandhumanintelligencesincetheanswertoarelatedquestion(thatthesystemrecommended)canbeconfirmedbythecontributorifneeded.
Theclusternotescanbeeditedbytrustedusersandappliedtoallarticleswithinthecluster.
RealTimeDuplicateDetectionFindingduplicatestoagivenquestionrequires(N-1)pairwisecomparisonstothequestionsinthedatabaseandmaybenotfeasibleinrealtime.
ThecomputationaltimecanbereducedbyselectingpotentialduplicatematcheswithAnswerXchangesearch.
ThetopperformingdocumentsintheclusterscanbeassignedanIDandindexedseparatelybythesearchengine.
Oncethesearchenginereturnsthedocumentsrankedbyrelevancytothenewlyformulatedquestion,theduplicate-scoringmodelisappliedtothetopmatchestoseeifthenewquestionisaduplicateand,ifso,whichduplicateclusteritbelongsto.
IDPOST_IDDOCUMENTTYPEVIEWSUPVOTE11,899,475CanIdeductjob-searchexpensesFAQ17,01974.
812,666,148HI.
WheredoIentermyjobsearchUGC1,75977.
913,048,015WheredoIincludejobsearchUGC1,06078.
113,356,358WheredoIentermyjobsearchFAQ6,72770.
313,705,028WheredoIdeductjobsearchUGC2,9996722,895,188WheredoIentermymedicalFAQ25,24379.
922,899,090WhydoesntmyrefundchangeafterIentermymedicalexpensesFAQ13,76579.
122,956,890wheredoienterOUTOFPOCKETmedicalexpensesUGC1,50986.
6DATA-DRIVENUSEREXPERIENCESAccumulationofduplicatecontentcanbepreventedbyintegratingacustom-builtduplicate-scoringmodelandquestion-postingexperience.
Anotheroptionistoexposeanintelligentinterfacetothetrustedusersbyprovidingextrafeaturesforansweringduplicatequestions.
Finally,theduplicatequestioncurationcanbepartofthecontentmoderationprocesscarriedoutbytheAnswerXchangetrustedusersortrainedbots.
QuestionDeduplicationWhilePostingThefirstfeature(Figure8)extendstheAnswerXchange"QuestionOptimizer"system[6].
Thesystempromptstheaskerwithpersonalizedinstructionscreateddynamicallybasedonrealtimeanalysisofthequestion'ssemanticsandwritingstyle.
The"QuestionOptimizer"hasbeenre-designedtomakeduplicatequestionmoredifficulttosubmitwithoutaddressingtherecommendedre-phrasing.
Theannotationstoconceptarepresentednext.
Figure8.
Question-postingexperiencerevealstheduplicatesandhelpsusersre-phraseasauniquequestion.
A)The"Question-Optimizer"technologyisenvisionedtoincludeduplicatecontentdetectioninadditiontoprovidingtimelyadviceonhowtore-phraseordeflect.
B)Ifquestionfallsinaknownduplicatecluster,thebestmatchingandmostreferencedanswermatchesareshown.
C)Trustedusersmayattach"clusternotes"tocuratedduplicateclustersandappearautomaticallywithanyquestionwithinthecluster.
IntheexampleshowninFigure8,theduplicateclusterisaboutprintingandthemessagenotesthattheprintingexperiencerecentlychangedintheproduct-informationwhichmaybeusefultoanyonewithprinting-relatedquestions.
D)Thesuggestedanswersarededuplicatedusingduplicatescoreequalizationsotheanswersaremoreuseful.
A"clusterbrowser"isalsoaddedbelowtotheresultstohelprefineamongstthemostpopularvariations.
QuestionDeduplicationWhileAnsweringThesecondfeatureaddressesthesituationwhereapotentialduplicatehasbeensubmittedandneedstobeinterceptedaspartofquestionansweringexperience.
ThisconceptisillustratedinFigures9-10.
Figure9.
Contributorexperiencetaggingandattachingcuratedanswertothequestion.
Specifically,Figure9illustratesthecontributor(typicallyatrusteduser)answeringexperienceandincludesthefollowingannotation:Chris,trythistodownloadanewcopySUGGESTEDANSWERSANSWERTHISIneedacopyofmy2014Taxreturncopyof2014returnSignbackintoyourTurboTaxonlineaccount.
FromtheWelcomeBackscreen,selectVisitMyTaxTimelineIneedtogetacopyofmy2014returnandIdon'thavethecd.
92%match2,314duplicates5/3/16450attachattachandmarkansweredIneedacopyofmy2014TaxreturnAnswerEChrisasked30minutesagoE)Thesuggestedansweredquestionduplicateispresentedtotheoriginalaskerandalsodisplaystheduplicateprobability.
Thecontributorcaneasilyattachittotheiranswer,whichalsotellsthesystemthequestionwasaduplicateandshouldbearchivedinfavoroftheattached.
Figure10.
Originalaskerviewofdeduplicatedquestionwithpersonalizedanswer.
Oncetheduplicatequestionisanswereditbecomesavailabletotheoriginalasker(Figure10).
C)Re-purposingtrustedusersnotessimilartothoseusedinquestion-postingexperience(Figure8).
F)Apersonalizednoteintroducesthe"recommendedanswer"whileexplainingit'saduplicate.
G)Theduplicateanswerispresentedwithasenseofauthority.
H)Iftheoriginalaskerisunsatisfiedwiththeanswer,theymayrevisetheirquestionanditwillre-entertheanswerqueue.
Theyalsohavetheoptiontorequestanewanswerwithoutsubmittingthequestion.
Finally,flaggingtheunansweredquestionautomaticallyasaduplicatemaybevalidatedorinvalidatedbythetrustedusersandtoupdatetrainingdatasetformodelre-training.
QuestionDeduplicationwithAutomatedAnswersThe"AnswerBot"(Figure11)isafeaturedrivenbyartificialintelligencealone.
The"AnswerBot"increasesself-supportefficiencybyrespondingtoacustomer'squestionsbye-mailwithanswersfromthematchingduplicateclusterifthepostedquestionisflaggedbytheduplicate-scoringmodelasaduplicate.
I)"AnswerBots"mayautomaticallyanswerquestionsdeterminedtobeduplicates.
Likethecontributor-assistedexperience,thebotwillrecommendtheanswerfromthebestanswerwithintheduplicatecluster.
Theuserismadeawarethatabotansweredthequestion,andifunsatisfiedmayrequestanewanswer,orrevisetheirquestion.
Figure11.
Automateddeduplicationuserexperienceaspartofcustomizede-mailtotheoriginalasker.
Further,the"AnswerBot"attachesthequestiontotheexistingduplicateclusterautomaticallywhileprovidingagenericorpersonalizedanswer.
Thebotrepliestriggerautomatedarchivingoftheduplicatecontent.
ThequestionremainsvisibletotheoriginalaskerbutisnotmadeavailabletoAnswerXchangeusersandissuppressedfromsearchresults.
Arelatedoptionistocreatetwoseparatequeuesofduplicatequestionsforanswering.
Thequestionsinthefirstqueuewouldbeassignedtodesignatedmoderatorswhocancustomizeduplicatecontentfortheoriginalaskerandarchiveitafterwards.
Thelesscomplicatedquestionsinthesecondqueuecanbeassignedtothe"AnswerBot".
Yourquestionsharesthesameanswerasthissimilarquestion:Ineedacopyofmy2014TaxreturnChris,trythistodownloadanewcopyJaneDoe73SuperUser15minutesagoSweetieJeanRisingStar1yearagoSignbackintoyourTurboTaxonlineaccount.
FromtheWelcomeBackscreen,selectVisitMyTaxTimelineSelect2014astheyearfromyourTaxTimelineFromthelistofSomeThingsYouCanDoonyourTaxTimeline,selectDownload/PrintMyReturn(PDF)RECOMMENDEDANSWERNotetheprintingexperienceinTurboTaxchangedin2016FGCMOREACTIONSRevisemyquestionHRequestanewanswerIthinkyourquestionmightsharethesameanswerasthissimilarquestion:Ineedacopyofmy2014TaxreturnIamabot,andthisactionwasperformedautomatically.
Ifmyanswerisunhelpful,youmayrequestanewanswerorreviseyourquestion.
AnswerBot15minutesagoSignbackintoyourTurboTaxonlineaccount.
FromtheWelcomeBackscreen,selectVisitMyTaxTimelineSelect2014astheyearfromyourTaxTimelineFromthelistofSomeThingsYouCanDoonyourTaxTimeline,selectDownload/PrintMyReturn(PDF)RECOMMENDEDANSWERIDISCUSSIONANDCONCLUSIONSocialQ&Asystemsoftenpresumethattheuserscomplywithrecommendationsnottoreplicatetheexistingcontent.
ThisisnotthecaseforAnswerXchangewhereusersoftenavoidconsumingexistingcontentbypostinganewduplicatequestion.
TheseusersmaynotrealizethatAnswerXchangeisasocialQ&Asiteorlacktheabilitytofindandapplyexistinganswerstotheirquestion.
Weneedtointervenewithintelligentuserinterfacestoaltertheduplicatepostingbehavior.
Towardsthisgoal,wepresenttwoalgorithmsforduplicatecontentcurationandprovidingrealtimeinputstotheAnswerXchangeuserinterfaces.
Thefirstalgorithmdeterminesiftwoquestionsarenear-duplicatesandcanbecombinedwithasearchtodetectduplicatesinrealtime.
ThesecondalgorithmuncoversallduplicatepairsinAnswerXchangeandiscapableofhandlingdeduplicationtaskwithacorpusofmillionsofquestions.
Weconcludethepaperbypresentingthreequestiondeduplicationuserinterfaces.
Ourhypothesistovalidateinclude:(1)Willaskersacceptaduplicatewhenpresentedwithanacceptableanswer(2)Willtheyacceptaduplicatewithorwithoutapersonalizedcontributornote(3)Ifdissatisfiedwilltheyreviseorrequestanewanswer(4)WilltheyacceptrecommendedanswersfromAnswerBotsWeareplanningtovalidatethesehypothesiswithasetofrapidexperimentspriortoproduction.
APPENDIXA:DUPLICATEPAIRDETECTIONDetectingduplicatesforN=790,000questionsbasedonacustom-builtmodelwouldrequire(N(N-1)/2pairwisecomputations.
Thetaskoffindingduplicatepairsbecomescomputationallyexpensiveoncethecorpusreachesseveralhundredthousanddocuments.
Atthesametime,computingcosine-similarityforaquestionpairisfasterthanscoringthesamepairwithcustom-builtmodelandcanbeusedtoreducethenumberofpotentialduplicatepairsfrombillionstomillionsofpairs.
Further,dividingcontentbyMprobabilistictopicscanreducethenumberofpairwisecomparisonsbyM,whilenotnecessarilyaffectingthenumberofexpectednear-duplicatepairs.
MDuplicatesExecutiontime(min)5063,355133072,92018.
51073,06836183,773265TableA1.
Duplicatestatisticsandcomputationtimevs.
numberofprobabilistictopics(M).
Cosine-similaritythresholdis0.
7.
M=1meansprocessingN(N-1)/2pairs.
ShowninTableA1areresultsofthenumericalexperimentsconductedonMacBookProlaptopwith2.
8GHzprocessorspeed.
Theprocessingpipelineincluded(1)dividingquestionsintoMtopics,(2)computingcosine-similarityforallpairsinatopic,and(3)applyingduplicate-scoringmodeltothepairswithcosine-similarityaboveapre-definedthreshold.
Thetotalnumberofduplicatepairswasfoundtobe5,597,799andcontained281,031uniquequestions(or35%oftheAnswerXchange"live"questions).
In2017,theycontributed56%totheAnswerXchangedocumentviews.
Thedocumentsintheidentifiedduplicatepairscanberankedbyasuitablequestion(andanswer)proxycontentqualitymetricsasdiscussedearlier,forexamplebythenumberofviews,votes,ageofthepost,orbyaweighedcombinationthereof.
Thedocumentwiththelowerscorecanberemovedconsecutivelyfromeachpairresultinginaremovalof217,767documents(27%oftheAnswerXchange"live"questions).
ACKNOWLEDGMENTSWethankanonymousreviewersforvaluablecomments.
REFERENCES1.
EugeneAgichtein,CarlosCastillo,DeboraDonato,AristidesGionis,GiladMishne.
2008.
FindingHigh-QualityContentinSocialMedia.
In:Proc.
oftheInternationalConferenceonWebSearchandDataMining,183-193.
2.
AhmedK.
Elmagarmid,PanagiotisG.
Ipeirotis,VassiliosS.
Verykios.
2007.
DuplicateRecordDetection:ASurvey.
IEEETrans.
Knowl.
DataEng.
,19,1-16.
3.
KlemensMuthmann,AlinaPetrova.
2014.
Anautomaticapproachforidentifyingtopicalnear-duplicaterelationsbetweenquestionsfromsocialmediaQ/Asites.
In:ClassifyingBigDatafromtheWeb,1-6.
4.
PreslavNakov,DorisHoogeveen,LluísMàrquez,AlessandroMoschitti,HamdyMubarak,TimothyBaldwin,KarinVerspoor.
2017.
SemEval-2017Task3:CommunityQuestionAnswering.
In:Proc.
ofthe11thInt.
WorkshoponSemanticEvaluation,27-48.
5.
IgorA.
Podgorny,MatthewCannon,ToddGoodyear.
2015a.
Pro-activedetectionofcontentqualityinTurboTaxAnswerXchange.
In:Proc.
ofACMConferenceCompaniononCSCW,143-146.
6.
IgorA.
Podgorny,ChrisGielow,MatthewCannon,ToddGoodyear.
2015b.
Realtimedetectionandinterventionofpoorlyphrasedquestions.
InCHI'15ExtendedAbstracts,2205-2210.
7.
R.
S.
Ramya,K.
R.
Venugopal,S.
S.
Iyengar,L.
Patnaik.
2016.
FeatureExtractionandDuplicateDetectionforTextMining:ASurvey.
GlobalJournalofComputerScienceandTechnology56,5.
8.
AnnaShtok,GideonDror,YoelleMaarek,IdanSzpektor.
2012.
LearningfromthePast:AnsweringNewQuestionswithPastAnswers,WWW,759-768.
9.
IvanSrba,MáriaBieliková.
2016.
AComprehensiveSurveyandClassificationofApproachesforCommunityQuestionAnswering.
In:TWEB,10(3),18:1-18:63.
PodgornyIntuit,Inc.
SanDiego,USAigor_podgorny@intuit.
comChrisGielowIntuit,Inc.
SanDiego,USAchris_gielow@intuit.
comABSTRACTTurboTaxAnswerXchangeisapopularsocialQ&AsystemsupportingusersworkingonU.
S.
federalandstatetaxreturns.
Basedonacustom-builtduplicatescoringmodel,35%ofAnswerXchangequestionshavebeenfoundtobenear-duplicatesresponsiblefor56%ofAnswerXchangedocumentviews.
Thisdegradestheuserexperienceforboththeaskerwhoisunabletofindanansweramidduplicates,andtheanswererwhoisunabletoefficientlyansweratscale.
Theduplicatequestionstendtoformmicro-clustersthatgrowviapreferentialattachmentand,onceexceedingsome25questionsinsize,startmorphingintomega-clusterswithacomplexnetworktopology.
Thisbehaviorcanbeleveragedtodesignsemi-automatedcontentcurationsystemstodetectwhetheranewlypostedquestionisaduplicateand,ifso,whichduplicateclusteritbelongsto.
InordertoimproveuserexperienceinAnswerXchange,weexplorehowhumanandartificialintelligencecanbejointlyemployedandthenpresentseveraldata-drivenintelligentuserinterfaces.
Theduplicatescoringmodelscanbeutilizedaselementsofquestion-postingandansweringexperiences,unansweredquestionqueueingandanswerbots.
TheseapproachescanbeextendedtoanysocialsupportQ&Asystemwhereduplicatepostingnegativelyimpactssearchrelevanceandcontentconsumption.
AuthorKeywordsTurboTax;AnswerXchange;CQA;communityquestionanswering;socialquestionanswering;duplicateclusters;contentdeduplication.
ACMClassificationKeywordsH.
5.
m.
InformationInterfacesandPresentation(e.
g.
HCI):MiscellaneousINTRODUCTIONSocialQ&Asystemsprovideaconvenientself-supportoptionfortaxandfinancialsoftwareapplicationswherepersonalizedlong-tailcontentgeneratedbytheuserscansupplementcuratedknowledgebaseanswers.
Usersoftenpreferself-helptoassistedmeasures(e.
g.
phonesupportoronlinechat)andareoftenabletofindandapplytheirsolutionfaster.
Thisalsoreducestheloadonassistedchannels,ensuringtheyremainavailabletothosewhoneedit.
AnswerXchange(http://ttlc.
intuit.
com)isasocialQ&AsitewherecustomerscanlearnandsharetheirknowledgewithotherTurboTaxcustomerswhilepreparingU.
S.
federalandstatetaxreturnsandalsofindstep-by-stepinstructionsonusingtheTurboTaxapplication[5,6].
AstheusersstepthroughtheTurboTaxinterviewpages,theycanaskquestionsaboutsoftwareandtaxtopics(Figure1)andreceiveanswersinamatterofminutes.
AnswerXchangehasgeneratedmillionsofquestionsandanswersthathavehelpedtensofmillionsofTurboTaxcustomerssincelaunchingin2007.
Figure1.
AnswerXchangequestion-postinguserexperience.
Questiontitle(ashortsummaryofquestionlimitedto255characters)ismandatory.
Questiondetails(notshown)areoptionalandunlimitedinsize.
Themajorityofuserscanfindanswersbysearchingtheexistingcontent.
Theoverallqualityofacustomerself-helpsystemisthereforedeterminedbyhowwelltheself-helpsystemassistsinfindingtherelevantcontent.
Thenumberofsearchsessionsresultinginassistedsupportcontacts(beingaslargeashundredsofthousandsofcustomersperyear)andfractionofuserupordownvotesonself-supportcontentprovideaconvenientproxymetricsofcontentqualityandsearchrelevanceinTurboTaxself-help[5].
2018.
Copyrightfortheindividualpapersremainswiththeauthors.
Copyingpermittedforprivateandacademicpurposes.
ESIDA'18,March11,Tokyo,Japan.
Figure2.
AnexampleofduplicateAnswerXchangesearchresults.
Questiontitlesandanswersnippetsareshowninpurpleandinblack,respectively.
Oneproblemwiththeexistingquestion-postingexperience(Figure1)isthatsearchesmayresultinmultipleandoftenduplicateanswersthatarerelativelyclosetotheintentoftheoriginalquestion,butstilldonotmatchtheoriginalsearchintent(Figure2).
Thisinterfereswiththeuser'sabilitytoselectfromadiversesetofpossibleanswers[5]and,oftenresultseitherinthesubmissionofaduplicatequestionorswitchingtoaless-desiredsupportchannel.
Arelatedproblemisthatusersmaysubmitpoorqualityquestionsbynotprovidingalloftherelevantinformationneededforagoodqualityanswer[5].
Onesolutionisamanualreviewoftheusergeneratedcontenttoarchivesomeoftheduplicatequestionsandrelatedanswers,ifany,andkeepingthebestperformingcontentin"live"status(i.
e.
makingitavailableforsearch).
Thisapproachislaborintensiveanddoesnotaddresstheproblemwiththequestion-postinguserexperience.
Duplicatequestionsmayquicklybuildup,addingunnecessaryburdenoncommunityquestionansweringalongtheway.
ThegoalofthisstudyistoaddresstheproblemsofduplicatecontentpreventioninAnswerXchangebycombiningmachinelearningandintelligentuserinterfaces.
Inwhatfollows,wedescribeduplicatedetectionalgorithmsdevelopedearlierandpresentacustommodeltrainedonAnswerXchangequestions.
Next,weintroducetheconceptof"duplicateclusters"thatprovideaframeworkforsemi-automatedduplicatecontentprevention.
Finally,wepresentseveralcustomdesigneddata-drivenintelligentuserinterfacesforaddressingduplicatecontentproblem.
RELATEDWORKThetaskofestimatingsemanticsimilarityoftextdocumentshasmultiplepracticalapplicationsandisofgrowinginterestfromtheresearchcommunity.
Theareasofresearchincludewebpagesimilarity,documentsimilarity,sentencesimilarity,searchquerysimilarityandutterancesimilarityinconversationaluserinterfaces.
Thesetasksarealsorelatedtoamoregeneralproblemofdetectingduplicatesindatabaserecords[2].
QuestionsinsocialQ&Asystemsmediaareoftenconfinedtooneortworelativelyshortsentencesandmaywarrantdomainspecificapproachestoaddressingquestionsimilarity.
Forexample,twoquestionsinasocialQ&Asystemcanbeconsideredsemanticallyidenticalifasingleanswersatisfiestheneedsofbothoriginalaskers[3].
Theanswermaynotyetexistintheproductiondatabasebutcouldbegeneratedifneeded.
Thetaskofduplicate-questiondetectionisalsorelatedtothetaskofre-formulatinganewlyformedquestion[6]andautomaticallyfindingananswertoanewquestion[8].
Themostrecentresultsintheareaofduplicatecontentscoringcamefromthe2017Kaggle"QuoraPair"competitionwithmodelsubmissionsfrommorethan3,000teams(https://www.
kaggle.
com/c/quora-question-pairs).
Inthiscompetition,theparticipantsweretaskedtoclassifyifQuoraquestionpairsareduplicatesornotbasedon200,000traininginstances.
Finally,SemEval2017TaskonCommunityQuestionAnswering("Question–CommentSimilarity","Question–QuestionSimilarity",etc.
)resultedinsubmissionsfrom23teams[4].
TheproblemofduplicatedetectionandcurationiscloselyrelatedtothetaskofpredictingcontentqualityinsocialQ&Asystems.
Contentqualitymetricsmaybehelpfulinselectingthebestperformingquestionandanswerfortheduplicate-questionpair.
AnswerandquestionqualityinthesocialQ&Asystemshasbeenthefocusofincreasingattentionfromthescientificcommunity[1,9].
DUPLICATE-SCORINGMODELAnswerXchangeSearchAnswerXchangesearchisbuiltwithApacheLuceneopen-sourcesoftware(http://lucene.
apache.
org).
Bydefault,Luceneuses"tf-idf"(https://en.
wikipedia.
org/wiki/tf-idf)and"cosine-similarity"asstandardmethodsofrankingsearchresults.
Shorterdocumentswiththesamesetofmatchingkeywordstypicallyrankhigherthanlongerdocumentswithsimilarsemanticmeaning.
AnaverageAnswerXchangesearchqueryis2-3termslong(i.
e.
shorterthanatypicalAnswerXchangequestion)anditisoftencomparableinlengthwiththetitleofapotentiallyduplicatequestion.
ThequestiondetailsplayalesserrolecomparedtotitlescontributingtoextraboostingofduplicatecontentbyLucene.
TheAnswerXchangeLucenerankingalgorithmtendstoboostnewcontentandalsoaccountsforvariousmetadatasuchashelpfulnessvotes.
TrainingDataTheproblemofnear-duplicatedetectioncanbeformulatedasanunsupervisedorsupervisedmachinelearningtask[7].
Intheunsupervisedcase,duplicatepairsandclusterscanbefoundbasedondistancemetricssuchascosine-similarityoftheweightedtf-idfvectors,Jaccardsimilaritycoefficient,distanceinword2vecspace,etc.
Inthesupervisedcase,theproblemoffindingtopicalnear-duplicaterelationscanbeformulatedasfollows:givenapairofquestions,themachinelearntmodelhastopredicta"duplicatescore"anddetermineifquestionsareduplicatesbasedonapre-definedthreshold.
Inthispaper,weemploya"hybrid"approachstartingwithcosine-similaritymetricsfordatapre-processingandthenaddingamoreaccuratecustom-builtscoringmodeltotheprocessingpipeline.
AsthefractionofduplicatepairsinAnswerXchangeisrelativelylow,thequestionpairsrankedbycosine-similarityprovideaconvenientdatasetforlabelingbasedontheimportancesamplingapproach.
Towardsthisgoal,wecomputedbag-of-wordscosine-similarity(AppendixA)for790,000questionsavailableforsearchinAnswerXchangeattheendof2017U.
S.
TaxDay(April18).
Next,fourAnswerXchangemoderatorsaddedclasslabels(0or1)toarandomsampleof4,000near-duplicatepairs.
Instancesopentodoubthavebeenflaggedbymoderatorsandthenre-labeledbyaconsensus.
1,000randomlysamplednon-duplicatepairshavebeenaddedforthefinalversionofthetrainingdatasettomakeitequallydividedbetweenduplicateandnon-duplicatepairs.
Duplicate-ScoringModelFeaturesThemodelfeaturescanbelearntfromtrainingdataand/orbyknowledgeacquisitionfromAnswerXchangemoderators.
Wehaveusedthefollowingmodelfeatures:Cosine-similaritywithtf-idfweighting(seeAppendixA).
ProbabilistictopicIDofthequestioncomputedwithLatentDirichletAllocation(seeAppendixA).
U.
S.
taxyearinthequestion.
Distinctwordsinthequestionpair.
Commonwordsinthequestionpair.
Typeofthequestion(e.
g.
"closed-ended"questions"CanIdeduct…"typicallyaccountfortaxrelated,while"how"questionsoftenaccountforproductrelatedquestion).
Firstwordofthequestion.
Duplicate-ScoringModelPerformanceBasedonthesetof5,000labeledquestionpairs,wetrainedandtestedalinear(logisticregression)andnon-linear(randomforest)binaryclassifiersusingPythonmachinelearninglibrary"scikit-learn".
Themodelpredictsclasslabel(0foranon-duplicateand1forduplicatepair)andalsotheduplicatescore(i.
e.
probabilityofthequestionpairtobelongtoeitherclassrangingfrom0.
0to1.
0)thatcanbeusedtoselectuserexperiencebasedonpredefinedthreshold(s).
Wealsotrainedaseparateversionofthelogisticregressionclassifierusingcosine-similarityasasinglemodelfeature.
ShowninTable1arecommonmetricsusedforpredictivemodelevaluation:areaundercurve(AUC)forreceiveroperatingcharacteristic,F1scoreandlogarithmicloss(logloss)functionforclassification.
ModelAUCF1ScoreLogLossLogisticRegression0.
950.
880.
27RandomForest0.
940.
870.
31Cosine-similarity0.
830.
730.
48Table1.
Modelperformancemetricsforduplicate-scoringmodels(detailsareexplainedinthetext).
AsseenfromTable1,bothlogisticregressionandrandomforestmodelsachieveperformancethatisconsistentwiththegoalsofthisexploratorystudy.
Atthesametime,cosine-similarityversionunderperformsthefirsttwobyawidemargin.
Thiscanbeexplainedbytheinabilitytofindanoptimalthresholdseparatingduplicateandnon-duplicatepairsusingthecosine-similarityalone.
Thefollowingtwoexamplesillustratetherelationshipbetweenkeyword-basedcosine-similarityandduplicate-questionscorecomputedwithlogisticregression.
ThefirstexampleisanAnswerXchangequestionpairwitharelativelylowcosine-similarityof0.
61:(1)"Ineedacopyofmyfederaltaxreturnfor2014"and(2)"Ineed2015TaxReturn".
BothquestionscanbeansweredwithasingleinstructionaboutgettingacopyofprioryeartaxreturnfiledwithTurboTaxandhenceareduplicates.
Thesecondexampleisaquestionpairwithhighcosine-similarityof1.
0:(1)"doihavetofilestatetaxes"and(2)"howtofilestatetaxes".
Thesequestionsarenotduplicatesbecausetheybelongtotaxandproductcategories[5],respectively,andwouldrequiretwodifferentanswers.
DUPLICATECLUSTERSPreferentialAttachmentandTopologyAfteridentifying5,597,799duplicatequestionpairsinAnswerXchange(AppendixA),webuiltanundirectedgraphof281,031duplicatequestions.
Eachduplicatepairandduplicatequestionidentifiedwiththemodelconstitutedgraphedgeandgraphvertex,respectively.
Theresultinggraphconsistsof14,616connectedcomponentshereafterreferredtoas"duplicateclusters.
"Toexploreduplicate-clusterscalingbehavior,werankedclustersbythenumberofquestionsandplottedthenumberofquestionsperclustervs.
clusterrankinlog-logscale(Figure3).
Thelargestclusterhas23,236questionsandthesmallestonesonlyhavetwo.
Theplotalsoincludesgraph(oredge)density:=21,whereEisnumberofedges(i.
e.
duplicatepairs)andVisthenumberofvertices(i.
e.
questions).
Graphdensityisequalto1.
0forthefullyconnectedgraphs.
Inthelattercase,eachquestionintheclusterisconnectedtoallremainingquestionsinthesameduplicatecluster.
Basedonbothquestioncountsandgraphdensity,theduplicateclustersinFigure3canbedividedintothreedistinctgroupsmarkedasmega-clusters,transitionalclustersandmicro-clusters.
Thesegroupsaccountfor84%,2%and14%ofduplicatequestions,respectively.
Figure3.
Scalingbehaviorofduplicateclusters(blackdots)inAnswerXchangequestions.
Theclustersarerankedbythenumberofquestionsinthedescendingorder.
Graphdensityfortheclustersisshowningray.
CyanandreddotsrefertotheclustersshowninFigures4and5,respectively.
Anexampleofmicro-clusterwith23verticesisshowninFigure4.
Graphdensityis0.
54andmostofverticesareinterconnectedwithanexceptionofthreeverticesconnectedbybridgestoadensergraphcore.
Thecorrespondingarticulationpointsaremarkedbybluedots.
Notethatevenifquestions1and2areduplicatesandquestions2and3areduplicates,thisdoesnotmeanthatquestions1and3areduplicatesaswell.
Thisexplainswhyaduplicate-clusterdensityistypicallylessthan1.
0unlessthegraphsizeislimitedtotwoquestions.
AsseenfromFigure3,micro-clusterscalingbehaviorfollowsZipfdistribution(https://en.
wikipedia.
org/wiki/zipf's_law):=+,,whererrangesfromabout100tothetotalnumberofclustersR.
Accordingly,thegrowthofN(Δ)andR(Δ)wouldbeconstrainedbythefollowingequation:Δ=Δ.
ItisworthmentioningthatZipfdistributionisanasymptoticcaseofamoregeneralYule-Simondistribution(https://en.
wikipedia.
org/wiki/Yule-Simon_distribution)typicalforthepreferentialattachmentprocess,meaningthatanewlypostedduplicateismorelikelytobecomeattachedtotheexistingclusterthantoformanewduplicatepair.
Thescalingparameterforthemicro-clusters:=log4log5log(4)log(5)canbeestimatedas0.
6.
ByextrapolatingZipfdistributiontor=1(thatwouldcorrespondtoanon-existinglargestmicro-cluster),onecanestimateNvalueas400.
Thisvalue,however,isalmosttwoordersofmagnitudelessthanthenumberofquestionsinthetopmega-cluster.
Figure4.
Amicro-clustermarkedbycyandotinFigure3.
Articulationpointsareshownbysmallerbluedots.
ToexplainthescalebreakinthedistributionshowninFigure3,letusexaminelargerduplicateclustersinmoredetail.
ShowninFigure5isamega-clusterwith4,549questions.
Theclusterhasdensityequalto0.
0017and1048articulationpoints.
Thismeansthatthemega-clustersmayconsistofmultiplesub-clustersthataresemanticallyrelatedtoeachotherbutwiththeelementsthatarenotduplicatesunlesstheybelongtothesamesub-cluster.
Figure5.
SameasinFigure4,butnowforamega-cluster.
Asthenumberofduplicatesreachescertainlevel,theclustersstartcoalescingbyestablishingbridgeswithotherclusters,duplicatepairsandstand-alonequestions,quicklyevolvingfromdenseconnectedgraphstosparsegraphswithacomplexnetworktopology.
TheareaoftransitionismarkedastransitionalclustersinFigure3.
Semi-AutomatedDuplicateContentCurationWhilethetaskofduplicatecontentarchivingisstraightforwardonceduplicatepairsarefound(AppendixA),theduplicatecontentcanbuildupagainunlessquestion-postingand/orsearchexperiencesaremodified.
Ournextgoalisthereforetoexplorehowtheconceptofduplicateclustersdiscussedintheprevioussectioncanbeappliedtothesetasks.
Thecurationofmicro-clusterscanbedoneautomaticallyorsemi-automatically(i.
e.
withminimumhumaninvolvement)byretainingoneorfewbestperforminglong-taildocuments(i.
e.
documentsthatincludebothquestionsandanswers)andassigningthemaclusterIDforsubsequentre-use.
Thecurationofmega-clustersrepresentsamorechallengingproblem.
First,asinglebestperformingdocumentinamega-clustermaysimplynotexistsincetheclustermaycontainmultiplesub-clustersconnectedbybridges.
Second,duplicatecurationbyahumanisacumbersometaskduetothemega-clustercomplextopology.
Whiletheexactsolutionmaysimplynotexist,approximatesolutionsmaybesufficienttoreducethenumberofduplicatespostedintheAnswerXchangetoanacceptablelevel.
Oneapproachwouldbetobreakthemega-clustersintosmallerpartsbydeletingbridgesinthegraphorbyemployingaconventionalhierarchicalclustering.
Forexample,theduplicateclustershowninFigure5canbesplitto1363connectedcomponentsbyremovingallarticulationpoints(bluedotsinFigure5).
Mostoftheresultingconnectedcomponents,however,aredisconnecteddocuments.
Amorepracticalapproachistoarchivenon-performingshort-tailcontentfromthemega-clusterandcuratetheresultingconnectedcomponents.
ShowninFigure6isasubsetofmega-clusterfromFigure5thatnowonlyincludesdocumentswithatleast100views.
Thisresultsinbreakingtheoriginalmega-clusterinto68connectedcomponentswhichareeasiertocurate.
Figure6.
Asubsetofthemega-clustershowninFigure5.
GreydotsmarkdocumentsusedinFigure7.
Thenexttaskistopresentduplicatecontentinaformsuitableforsemi-automatedcontentcuration.
Figure7showsanexampleofduplicatecontentmetricsforeightdocumentswithatleast1000views.
Theleftcolumnisasub-clusterIDfollowedbyapostIDidentifyinganAnswerXchangedocumentconsistingoftheoriginalquestionandallaccumulatedanswers(notshown).
Thetextofthequestionandtypeofthequestion(i.
e.
user-generatedcontentmarkedasUGCorknowledgebasecontentlabeledasFAQ)areincludedinthethirdandfourthcolumns,respectively.
Thelasttwocolumnsareviewsaccumulatedoveragivenperiodandpercentageofup-votes.
Thedocumentscanberankedbyviewsand/orvotesprovidingamechanismofidentifyingandremovingnon-performingcontenteithermanuallyorautomaticallybasedonasetofpredefinedcontentqualitythresholds.
Figure7.
DuplicatedocumentmetricsforthedocumentsmarkedbygreydotsinFigure6.
Duplicatemetricscanbeoperationalizedbyaddinganalgorithmtomatchthebestquestiontothebestanswerinthesub-cluster.
Suchasystemwouldincludeanswerdeletingandmergingmanuallyorautomaticallybyattachingautomaticallygenerated"best"answertothe"best"duplicatequestion.
Thesolutioncanbeimplementedasaback-endtoolfortrustedusersassignedtothetaskofduplicatearchivingandhiddenfromthelessexperiencedregularusers.
Thesolutiongoesbeyondsimpleduplicatearchivingbyprovidinganoptiontomergeavailableanswerstotheexistingduplicatequestions.
Thenon-humanpartofthesolutionincludesqualityrankingoftheexistinganswers,e.
g.
upanddownvotestatisticsasshowninFigure7.
Inthisway,thenewlyformedquestion-answerpairsprovidebetterqualitycontentavailableforsearchbycombiningthevisuallyappealingquestionsandthebestrankedanswers.
Thisisdonebycombiningartificialandhumanintelligencesincetheanswertoarelatedquestion(thatthesystemrecommended)canbeconfirmedbythecontributorifneeded.
Theclusternotescanbeeditedbytrustedusersandappliedtoallarticleswithinthecluster.
RealTimeDuplicateDetectionFindingduplicatestoagivenquestionrequires(N-1)pairwisecomparisonstothequestionsinthedatabaseandmaybenotfeasibleinrealtime.
ThecomputationaltimecanbereducedbyselectingpotentialduplicatematcheswithAnswerXchangesearch.
ThetopperformingdocumentsintheclusterscanbeassignedanIDandindexedseparatelybythesearchengine.
Oncethesearchenginereturnsthedocumentsrankedbyrelevancytothenewlyformulatedquestion,theduplicate-scoringmodelisappliedtothetopmatchestoseeifthenewquestionisaduplicateand,ifso,whichduplicateclusteritbelongsto.
IDPOST_IDDOCUMENTTYPEVIEWSUPVOTE11,899,475CanIdeductjob-searchexpensesFAQ17,01974.
812,666,148HI.
WheredoIentermyjobsearchUGC1,75977.
913,048,015WheredoIincludejobsearchUGC1,06078.
113,356,358WheredoIentermyjobsearchFAQ6,72770.
313,705,028WheredoIdeductjobsearchUGC2,9996722,895,188WheredoIentermymedicalFAQ25,24379.
922,899,090WhydoesntmyrefundchangeafterIentermymedicalexpensesFAQ13,76579.
122,956,890wheredoienterOUTOFPOCKETmedicalexpensesUGC1,50986.
6DATA-DRIVENUSEREXPERIENCESAccumulationofduplicatecontentcanbepreventedbyintegratingacustom-builtduplicate-scoringmodelandquestion-postingexperience.
Anotheroptionistoexposeanintelligentinterfacetothetrustedusersbyprovidingextrafeaturesforansweringduplicatequestions.
Finally,theduplicatequestioncurationcanbepartofthecontentmoderationprocesscarriedoutbytheAnswerXchangetrustedusersortrainedbots.
QuestionDeduplicationWhilePostingThefirstfeature(Figure8)extendstheAnswerXchange"QuestionOptimizer"system[6].
Thesystempromptstheaskerwithpersonalizedinstructionscreateddynamicallybasedonrealtimeanalysisofthequestion'ssemanticsandwritingstyle.
The"QuestionOptimizer"hasbeenre-designedtomakeduplicatequestionmoredifficulttosubmitwithoutaddressingtherecommendedre-phrasing.
Theannotationstoconceptarepresentednext.
Figure8.
Question-postingexperiencerevealstheduplicatesandhelpsusersre-phraseasauniquequestion.
A)The"Question-Optimizer"technologyisenvisionedtoincludeduplicatecontentdetectioninadditiontoprovidingtimelyadviceonhowtore-phraseordeflect.
B)Ifquestionfallsinaknownduplicatecluster,thebestmatchingandmostreferencedanswermatchesareshown.
C)Trustedusersmayattach"clusternotes"tocuratedduplicateclustersandappearautomaticallywithanyquestionwithinthecluster.
IntheexampleshowninFigure8,theduplicateclusterisaboutprintingandthemessagenotesthattheprintingexperiencerecentlychangedintheproduct-informationwhichmaybeusefultoanyonewithprinting-relatedquestions.
D)Thesuggestedanswersarededuplicatedusingduplicatescoreequalizationsotheanswersaremoreuseful.
A"clusterbrowser"isalsoaddedbelowtotheresultstohelprefineamongstthemostpopularvariations.
QuestionDeduplicationWhileAnsweringThesecondfeatureaddressesthesituationwhereapotentialduplicatehasbeensubmittedandneedstobeinterceptedaspartofquestionansweringexperience.
ThisconceptisillustratedinFigures9-10.
Figure9.
Contributorexperiencetaggingandattachingcuratedanswertothequestion.
Specifically,Figure9illustratesthecontributor(typicallyatrusteduser)answeringexperienceandincludesthefollowingannotation:Chris,trythistodownloadanewcopySUGGESTEDANSWERSANSWERTHISIneedacopyofmy2014Taxreturncopyof2014returnSignbackintoyourTurboTaxonlineaccount.
FromtheWelcomeBackscreen,selectVisitMyTaxTimelineIneedtogetacopyofmy2014returnandIdon'thavethecd.
92%match2,314duplicates5/3/16450attachattachandmarkansweredIneedacopyofmy2014TaxreturnAnswerEChrisasked30minutesagoE)Thesuggestedansweredquestionduplicateispresentedtotheoriginalaskerandalsodisplaystheduplicateprobability.
Thecontributorcaneasilyattachittotheiranswer,whichalsotellsthesystemthequestionwasaduplicateandshouldbearchivedinfavoroftheattached.
Figure10.
Originalaskerviewofdeduplicatedquestionwithpersonalizedanswer.
Oncetheduplicatequestionisanswereditbecomesavailabletotheoriginalasker(Figure10).
C)Re-purposingtrustedusersnotessimilartothoseusedinquestion-postingexperience(Figure8).
F)Apersonalizednoteintroducesthe"recommendedanswer"whileexplainingit'saduplicate.
G)Theduplicateanswerispresentedwithasenseofauthority.
H)Iftheoriginalaskerisunsatisfiedwiththeanswer,theymayrevisetheirquestionanditwillre-entertheanswerqueue.
Theyalsohavetheoptiontorequestanewanswerwithoutsubmittingthequestion.
Finally,flaggingtheunansweredquestionautomaticallyasaduplicatemaybevalidatedorinvalidatedbythetrustedusersandtoupdatetrainingdatasetformodelre-training.
QuestionDeduplicationwithAutomatedAnswersThe"AnswerBot"(Figure11)isafeaturedrivenbyartificialintelligencealone.
The"AnswerBot"increasesself-supportefficiencybyrespondingtoacustomer'squestionsbye-mailwithanswersfromthematchingduplicateclusterifthepostedquestionisflaggedbytheduplicate-scoringmodelasaduplicate.
I)"AnswerBots"mayautomaticallyanswerquestionsdeterminedtobeduplicates.
Likethecontributor-assistedexperience,thebotwillrecommendtheanswerfromthebestanswerwithintheduplicatecluster.
Theuserismadeawarethatabotansweredthequestion,andifunsatisfiedmayrequestanewanswer,orrevisetheirquestion.
Figure11.
Automateddeduplicationuserexperienceaspartofcustomizede-mailtotheoriginalasker.
Further,the"AnswerBot"attachesthequestiontotheexistingduplicateclusterautomaticallywhileprovidingagenericorpersonalizedanswer.
Thebotrepliestriggerautomatedarchivingoftheduplicatecontent.
ThequestionremainsvisibletotheoriginalaskerbutisnotmadeavailabletoAnswerXchangeusersandissuppressedfromsearchresults.
Arelatedoptionistocreatetwoseparatequeuesofduplicatequestionsforanswering.
Thequestionsinthefirstqueuewouldbeassignedtodesignatedmoderatorswhocancustomizeduplicatecontentfortheoriginalaskerandarchiveitafterwards.
Thelesscomplicatedquestionsinthesecondqueuecanbeassignedtothe"AnswerBot".
Yourquestionsharesthesameanswerasthissimilarquestion:Ineedacopyofmy2014TaxreturnChris,trythistodownloadanewcopyJaneDoe73SuperUser15minutesagoSweetieJeanRisingStar1yearagoSignbackintoyourTurboTaxonlineaccount.
FromtheWelcomeBackscreen,selectVisitMyTaxTimelineSelect2014astheyearfromyourTaxTimelineFromthelistofSomeThingsYouCanDoonyourTaxTimeline,selectDownload/PrintMyReturn(PDF)RECOMMENDEDANSWERNotetheprintingexperienceinTurboTaxchangedin2016FGCMOREACTIONSRevisemyquestionHRequestanewanswerIthinkyourquestionmightsharethesameanswerasthissimilarquestion:Ineedacopyofmy2014TaxreturnIamabot,andthisactionwasperformedautomatically.
Ifmyanswerisunhelpful,youmayrequestanewanswerorreviseyourquestion.
AnswerBot15minutesagoSignbackintoyourTurboTaxonlineaccount.
FromtheWelcomeBackscreen,selectVisitMyTaxTimelineSelect2014astheyearfromyourTaxTimelineFromthelistofSomeThingsYouCanDoonyourTaxTimeline,selectDownload/PrintMyReturn(PDF)RECOMMENDEDANSWERIDISCUSSIONANDCONCLUSIONSocialQ&Asystemsoftenpresumethattheuserscomplywithrecommendationsnottoreplicatetheexistingcontent.
ThisisnotthecaseforAnswerXchangewhereusersoftenavoidconsumingexistingcontentbypostinganewduplicatequestion.
TheseusersmaynotrealizethatAnswerXchangeisasocialQ&Asiteorlacktheabilitytofindandapplyexistinganswerstotheirquestion.
Weneedtointervenewithintelligentuserinterfacestoaltertheduplicatepostingbehavior.
Towardsthisgoal,wepresenttwoalgorithmsforduplicatecontentcurationandprovidingrealtimeinputstotheAnswerXchangeuserinterfaces.
Thefirstalgorithmdeterminesiftwoquestionsarenear-duplicatesandcanbecombinedwithasearchtodetectduplicatesinrealtime.
ThesecondalgorithmuncoversallduplicatepairsinAnswerXchangeandiscapableofhandlingdeduplicationtaskwithacorpusofmillionsofquestions.
Weconcludethepaperbypresentingthreequestiondeduplicationuserinterfaces.
Ourhypothesistovalidateinclude:(1)Willaskersacceptaduplicatewhenpresentedwithanacceptableanswer(2)Willtheyacceptaduplicatewithorwithoutapersonalizedcontributornote(3)Ifdissatisfiedwilltheyreviseorrequestanewanswer(4)WilltheyacceptrecommendedanswersfromAnswerBotsWeareplanningtovalidatethesehypothesiswithasetofrapidexperimentspriortoproduction.
APPENDIXA:DUPLICATEPAIRDETECTIONDetectingduplicatesforN=790,000questionsbasedonacustom-builtmodelwouldrequire(N(N-1)/2pairwisecomputations.
Thetaskoffindingduplicatepairsbecomescomputationallyexpensiveoncethecorpusreachesseveralhundredthousanddocuments.
Atthesametime,computingcosine-similarityforaquestionpairisfasterthanscoringthesamepairwithcustom-builtmodelandcanbeusedtoreducethenumberofpotentialduplicatepairsfrombillionstomillionsofpairs.
Further,dividingcontentbyMprobabilistictopicscanreducethenumberofpairwisecomparisonsbyM,whilenotnecessarilyaffectingthenumberofexpectednear-duplicatepairs.
MDuplicatesExecutiontime(min)5063,355133072,92018.
51073,06836183,773265TableA1.
Duplicatestatisticsandcomputationtimevs.
numberofprobabilistictopics(M).
Cosine-similaritythresholdis0.
7.
M=1meansprocessingN(N-1)/2pairs.
ShowninTableA1areresultsofthenumericalexperimentsconductedonMacBookProlaptopwith2.
8GHzprocessorspeed.
Theprocessingpipelineincluded(1)dividingquestionsintoMtopics,(2)computingcosine-similarityforallpairsinatopic,and(3)applyingduplicate-scoringmodeltothepairswithcosine-similarityaboveapre-definedthreshold.
Thetotalnumberofduplicatepairswasfoundtobe5,597,799andcontained281,031uniquequestions(or35%oftheAnswerXchange"live"questions).
In2017,theycontributed56%totheAnswerXchangedocumentviews.
Thedocumentsintheidentifiedduplicatepairscanberankedbyasuitablequestion(andanswer)proxycontentqualitymetricsasdiscussedearlier,forexamplebythenumberofviews,votes,ageofthepost,orbyaweighedcombinationthereof.
Thedocumentwiththelowerscorecanberemovedconsecutivelyfromeachpairresultinginaremovalof217,767documents(27%oftheAnswerXchange"live"questions).
ACKNOWLEDGMENTSWethankanonymousreviewersforvaluablecomments.
REFERENCES1.
EugeneAgichtein,CarlosCastillo,DeboraDonato,AristidesGionis,GiladMishne.
2008.
FindingHigh-QualityContentinSocialMedia.
In:Proc.
oftheInternationalConferenceonWebSearchandDataMining,183-193.
2.
AhmedK.
Elmagarmid,PanagiotisG.
Ipeirotis,VassiliosS.
Verykios.
2007.
DuplicateRecordDetection:ASurvey.
IEEETrans.
Knowl.
DataEng.
,19,1-16.
3.
KlemensMuthmann,AlinaPetrova.
2014.
Anautomaticapproachforidentifyingtopicalnear-duplicaterelationsbetweenquestionsfromsocialmediaQ/Asites.
In:ClassifyingBigDatafromtheWeb,1-6.
4.
PreslavNakov,DorisHoogeveen,LluísMàrquez,AlessandroMoschitti,HamdyMubarak,TimothyBaldwin,KarinVerspoor.
2017.
SemEval-2017Task3:CommunityQuestionAnswering.
In:Proc.
ofthe11thInt.
WorkshoponSemanticEvaluation,27-48.
5.
IgorA.
Podgorny,MatthewCannon,ToddGoodyear.
2015a.
Pro-activedetectionofcontentqualityinTurboTaxAnswerXchange.
In:Proc.
ofACMConferenceCompaniononCSCW,143-146.
6.
IgorA.
Podgorny,ChrisGielow,MatthewCannon,ToddGoodyear.
2015b.
Realtimedetectionandinterventionofpoorlyphrasedquestions.
InCHI'15ExtendedAbstracts,2205-2210.
7.
R.
S.
Ramya,K.
R.
Venugopal,S.
S.
Iyengar,L.
Patnaik.
2016.
FeatureExtractionandDuplicateDetectionforTextMining:ASurvey.
GlobalJournalofComputerScienceandTechnology56,5.
8.
AnnaShtok,GideonDror,YoelleMaarek,IdanSzpektor.
2012.
LearningfromthePast:AnsweringNewQuestionswithPastAnswers,WWW,759-768.
9.
IvanSrba,MáriaBieliková.
2016.
AComprehensiveSurveyandClassificationofApproachesforCommunityQuestionAnswering.
In:TWEB,10(3),18:1-18:63.
- Lucenegraphcore相关文档
- 股份graphcore
- 行业graphcore
- ridgraphcore
- surveygraphcore
- disadvantagegraphcore
- "GlobalUnicornClub:PrivateCompaniesValuedat$1B+(asofMarch14,2019)",,,,,
ATCLOUD.NET-OVH海外高防云主机,采用KVM架构,稳定安全且便宜好用,仅3刀起
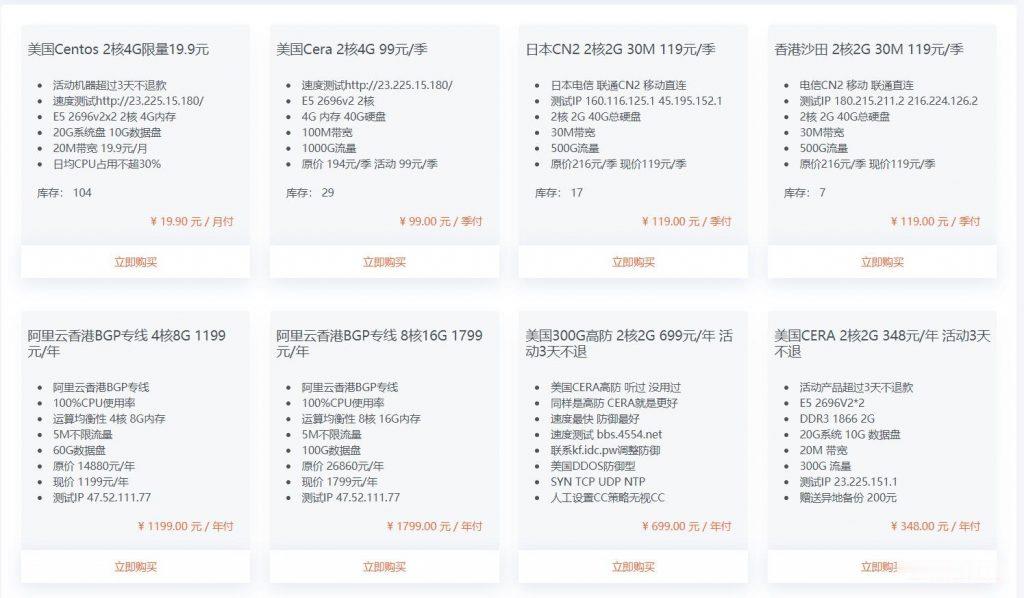
官方网站:点击访问ATCLOUD.NET官网优惠码:目前提供Cloud VPS与Storage VPS两款产品的六折优惠活动(续费同价,截止至2021年5月31日)优惠码:UMMBPBR20Z活动方案:一、型号CPU内存磁盘流量优惠价格购买链接VPS-1GB0.5×2.6+GHz1GB20GB1TB$3立即购买VPS-2GB1×2.6+GHz2GB50GB2TB$6立即购买VPS-4GB2×2.6...

virmach:AMD平台小鸡,赌一把,单车变摩托?$7.2/年-512M内存/1核/10gSSD/1T流量,多机房可选
virmach送来了夏季促销,价格低到爆炸,而且在低价的基础上还搞首年8折,也就是说VPS低至7.2美元/年。不过,这里有一点要说明:你所购买的当前的VPS将会在09/30/2021 ~ 04/30/2022进行服务器转移,而且IP还会改变,当前的Intel平台会换成AMD平台,机房也会变动(目前来看以后会从colocrossing切换到INAP和Psychz),采取的是就近原则,原来的水牛城可能...
美国cera机房 2核4G 19.9元/月 宿主机 E5 2696v2x2 512G
美国特价云服务器 2核4G 19.9元杭州王小玉网络科技有限公司成立于2020是拥有IDC ISP资质的正规公司,这次推荐的美国云服务器也是商家主打产品,有点在于稳定 速度 数据安全。企业级数据安全保障,支持异地灾备,数据安全系数达到了100%安全级别,是国内唯一一家美国云服务器拥有这个安全级别的商家。E5 2696v2x2 2核 4G内存 20G系统盘 10G数据盘 20M带宽 100G流量 1...
graphcore为你推荐
-
对对塔对对塔和魔方格那个是正宗的?百度指数词什么是百度指数m.kan84.net那里有免费的电影看?javbibibibi直播是真的吗www.kaspersky.com.cn卡巴斯基杀毒软件有免费的吗?稳定版的怎么找?www.36ybyb.com有什么网址有很多动漫可以看的啊?我知道的有www.hnnn.net.很多好看的!但是...都看了!我想看些别人哦!还有优酷网也不错...m.yushuwu.org花样滑冰名将YU NA KIM的资料谁有?www4399com4399小游戏 请记住本站网站 4399.urlwww.1diaocha.com哪个网站做调查问卷可以赚钱 啊鹤城勿扰黑龙江省的那个 城市是被叫做鹤城?