如何抓取网页上的数据求教,怎么抓取网页中的表格数据
如何抓取网页上的数据 时间:2021-08-21 阅读:()
如何抓取某个网页上的目录下的所有数据
用直连的方法,连接数据就可以了,代码如下: .addressList.baseDao; import java.sql.*; /** * 连接数据库的单元(getConnection) * 关闭数据库的单元 * * @author Owner * */ public class DBConnection { //连接驱动; private static final String DRIVER_CLASS = &.microsoft.jdbc.sqlserver.SQLServerDriver"; //连接数据库 private static final String DATABASE_URL = "jdbc:microsoft:sqlserver://localhost:1433;DatabaseName=数据库名"; //用户名 private static final String DATABASE_USER = "sa"; //密码 private static final String DATABASE_PASSWORD = ""; /** * 连接数据库,返回一个Connection conn * @return conn */ public static Connection getConnection(){ Connection conn = null; try { Class.forName(DRIVER_CLASS); //注册驱动 conn = DriverManager.getConnection(DATABASE_URL,DATABASE_USER,DATABASE_PASSWORD); //建立连接 } //异常处理 catch (Exception e) { // TODO Auto-generated catch block e.printStackTrace(); } //返回连接对象 return conn; } /** * 关闭连接对象 * @param conn Connection */ public static void closeConnection(Connection conn){ try{ if(conn != null){ conn.close(); } }catch(SQLException se){ conn = null; se.printStackTrace(); } } /** * 关闭statement对象 * @param st */ public static void closeStatement(Statement st){ try{ if(st != null){ st.close(); } }catch(SQLException se){ se.printStackTrace(); }finally{ st = null; } } /** * 关闭ResuleSet对象 * @param rs */ public static void closeResultSet(ResultSet rs){ try{ if(rs != null){ rs.close(); } }catch(SQLException se){ se.printStackTrace(); }finally{ rs = null; } } }如何抓取网页上的信息?
1、识别url重定向,互联网信息数据量很庞大,涉及众多的链接,但是在这个过程中可能会因为各种原因页面链接进行重定向,在这个过程中就要求百度蜘蛛对url重定向进行识别 2、对网站抓取的友好性,百度蜘蛛在抓取互联网上的信息时为了更多、更准确的获取信息,会制定一个规则最大限度的利用带宽和一切资源获取信息,同时也会仅最大限度降低对所抓取网站的压力。3、对作弊信息的抓取,在抓取页面的时候经常会遇到低质量页面、买卖链接等问题,百度出台了绿萝、石榴等算法进行过滤,据说内部还有一些其他方法进行判断,这些方法没有对外透露。
4、无法抓取数据的获取,在互联网中可能会出现各种问题导致百度蜘蛛无法抓取信息,在这种情况下百度开通了手动提交数据。
5、百度蜘蛛抓取优先级合理使用,由于互联网信息量十分庞大,在这种情况下是无法使用一种策略规定哪些内容是要优先抓取的,这时候就要建立多种优先抓取策略,目前的策略主要有:深度优先、宽度优先、PR优先、反链优先。
怎么把网页的表格里的内容提取出来!
我来回答 用javascript 当然是一个不错的选择 在html中 <table id=myTable> <tr> <td id=myContent>Content<td> <tr> </table> 在script中 <script> //通过表格找行再找单元格最后得到内容 var itemContent1=.getElelmentById("myTable").childNodes[0].childNodes[0].nodeValue; //也可以直接通过Id得到 var itemContent2=document.getElementById("myContent"); </script>求教,怎么抓取网页中的表格数据
1.通过搜索引擎,找到国家旅游局的网站,点击主菜单的【政务公开】——【统计数据】,则可以看到一系列包含数据的网页。2.打开一个网页,确认该网页包含了数据表。
复制该网页的网址,备用。
3.启动Excel文件,在一个工作表中,点击【数据】——>【自网站】 4.按ctrl+V键,粘贴刚才上一步复制的网址; 点击网址栏右侧的【转到】; 网页显示后,单击数据表格左上角的【横箭头】,变为绿色的【对号】; 点击整个窗口右下角的【导入】。
5.选择一个工作表位置,导入数据。
6.结果如下图所示。
虽然已经导入了数据,这实际上相当于建立了Excel文件与网页间的连接,这个Excel文件复制到别处,因为连接关系破坏,所以数据可能无法显示。
建议复制导入的数据到一个新的Excel文件,【选择性粘贴】为纯数值,这样就万无一失了。
- 如何抓取网页上的数据求教,怎么抓取网页中的表格数据相关文档
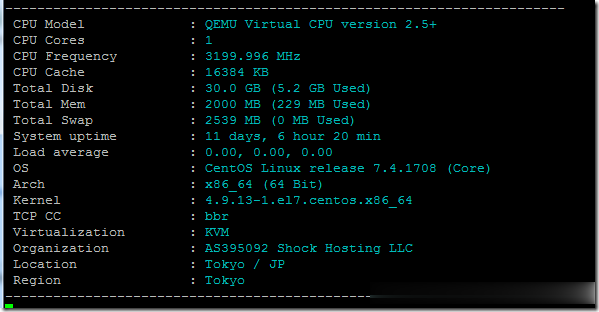
ShockHosting日本机房VPS测试点评
这个月11号ShockHosting发了个新上日本东京机房的邮件,并且表示其他机房可以申请转移到日本,刚好赵容手里有个美国的也没数据就发工单申请新开了一个,这里做个简单的测试,方便大家参考。ShockHosting成立于2013年,目前提供的VPS主机可以选择11个数据中心,包括美国洛杉矶、芝加哥、达拉斯、杰克逊维尔、新泽西、澳大利亚、新加坡、日本、荷兰和英国等。官方网站:https://shoc...
HostKvm($4.25/月)俄罗斯/香港高防VPS
HostKvm又上新了,这次上架了2个线路产品:俄罗斯和香港高防VPS,其中俄罗斯经测试电信CN2线路,而香港高防VPS提供30Gbps攻击防御。HostKvm是一家成立于2013年的国外主机服务商,主要提供基于KVM架构的VPS主机,可选数据中心包括日本、新加坡、韩国、美国、中国香港等多个地区机房,均为国内直连或优化线路,延迟较低,适合建站或者远程办公等。俄罗斯VPSCPU:1core内存:2G...
TMThosting:VPS月付55折起,独立服务器9折,西雅图机房,支持支付宝
TMThosting发布了今年黑色星期五的促销活动,即日起到12月6日,VPS主机最低55折起,独立服务器9折起,开设在西雅图机房。这是一家成立于2018年的国外主机商,主要提供VPS和独立服务器租用业务,数据中心包括美国西雅图和达拉斯,其中VPS基于KVM架构,都有提供免费的DDoS保护,支持选择Windows或者Linux操作系统。Budget HDD系列架构CPU内存硬盘流量系统价格单核51...
如何抓取网页上的数据为你推荐
-
对称矩阵实对称矩阵是什么意思?移动开发什么是android移动应用开发安卓开发环境搭建最新电脑安卓开发环境的搭建方法?安卓开发环境搭建安卓开发环境怎么搭建?u盾证书转款叫我下载U盾证书,是什么意思高级工程师证书查询如何查工程师证阿里学院首页阿里学院成都站--让成都电子商务的发展势如破竹red5集群JAVA服务集群与非集群的区别?it人物IT界名人有哪些?一看视频就死机一看视频就死机是怎么回事