description120ask.com
120ask.com 时间:2021-03-25 阅读:()
AKnowledgeBasedApproachforTacklingMislabeledMulti-classBigSocialDataMinyiGuo1,YiLiu1,JieLi1,HuakangLi2,andBeiXu21DepartmentofComputerScienceandEngineering,ShanghaiJiaoTongUniversity,Chinaguo-my@cs.
sjtu.
edu.
cn2SchoolofComputerScience&SchoolofSoftware,NanjingUniversityofPostsandTelecommunications,Chinahuakanglee@njupt.
edu.
cnAbstract.
Theperformanceofclassicationmodelsextremelyreliesonthequalityoftrainingdata.
However,labelimperfectionisaninherentfaultoftrainingdata,whichisimpossiblemanuallyhandledinbigdataenvironment.
Variousmethodshavebeenproposedtoremovelabelnoisesinordertoimproveclassicationquality,withthesideeectofcuttingdowndatabulk.
Inthispaper,weproposeaknowledgebasedapproachfortacklingmislabeledmulti-classbigdata,inwhichknowledgegraphtechniqueiscombinedwithotherdatacorrectionmethodtoperceiveandcorrecttheerrorlabelsinbigdata.
Theknowledgegraphisbuiltwiththemedicalconceptsextractedfromonlinehealthconsultingandmedicalguidance.
Experimentalresultsshowourknowledgegraphbasedapproachcaneectivelyimprovedataqualityandclassicationaccuracy.
Furthermore,thisapproachcanbeappliedinotherdataminingtasksrequiringdeepunderstanding.
Keywords:#eswc2014Guo,labelimperfection,knowledgegraph,labelcorrection,classication.
1IntroductionFormachinelearningresearch,manyresearchersfocusonimprovinglearningalgorithmswithleastlearningbias,thusthedataqualityhasbecomethecrucialissuewhenitisgiventoacertainmachinelearningalgorithm.
Unfortunately,realworlddatainevitablycontainsunexpectednoises(i.
e.
labelerrors)whichcandisturbtheperformanceofclassicationinmultipleaspectslikeaccuracy,modelingtimeandcomputingcomplexity.
Itprovesthatclassicationaccuraciesalmostdeclinelinearlywiththeincreaseofnoiselevel[1].
Mostlabelerrorsintrainingdatacomefromdataentryerrors,transmiterrorsandsubjectivityoftaggersandsoon.
Dataentryerrorsinlargedatasetaresevereandcommon.
Thenoiselevelisusuallyaround5%ormore[1].
Furthermore,itseemsdiculttoavoidoreventocutdownontheerrorsbecausetherearenostandardsorspecicationsdealingwithdataentryerrors.
TransmissionerrorsV.
Presuttietal.
(Eds.
):ESWC2014,LNCS8465,pp.
349–363,2014.
cSpringerInternationalPublishingSwitzerland2014350M.
Guoetal.
takeplaceincommunicationbreakdown.
Therefore,inordertoincreasetheaccuracy,mostoftrainingdataarelabeledmanuallyevenifthepeopleareverysubjectivebecauseoftheknowledgelimitationinspecicdomains.
Evenexpertsandprofessionalsarenotabsolutelycondentabouttheirlabeling.
Therefore,thenecessityofdevelopingmethodstoremoveorcorrectlabelerrorsisself-evident.
Manylearningalgorithmsmadelabelnoisedtreatmentmechanisms.
Forex-ample,pruningindecisiontreealgorithmcanavoidover-ttingcausedbynoises[2].
Still,whennoiselevelishigh,learningalgorithmsarenotabletoeectively.
Othermethodstrytohandlethenoisesindatabeforeclassication,includinglteringnoisesandcorrectingnoises.
Thispaperproposedanapproachbasedonknowledgegraphtechniquetoperceiveandcorrectlabelerrorsinbigdataenvironment.
KnowledgegraphisaconceptproposedbyGoogle1foritssearchengineandotherapplications,whosekernelisutilizingontologytosimulateentitiesandrelationshipsintherealworldtohelpmachineunderstandtheworldintelligently.
Theusageofknowl-edgegraphenablemachinestobetterunderstandtextdocuments[3].
Thereforeweintroducethisconceptinnoisecorrectiontobetterperceivethenaturecon-ditions.
WeusebigsocialdatacollectedfrommedicalQ&Awebsitestovalidateourapproachfortacklinglabelimperfection.
MedicalQ&Asystemservesforonlinehealthconsultingandmedicalguidance.
Astudyreports83%ofInternetusersintheU.
S.
seekhealthinformationonline[4]andhealthcaresystemareplayingamuchmoreessentialroleintherecentlife[5].
OurapproachimplementstheknowledgegraphonalabelcorrectionmethodraisedbyTengetal.
[6].
Concretely,NaiveBayesclassierisutilizedtorec-ognizeandmodifytheerrorlabelsoftrainingdata.
Afterlabelmodication,thenoiselevelhasproventodeclinedramaticallythanbefore.
Thenweusethemodieddatatoconstructclassierforclassicationratherthancorrection,andtheaccuracyhasimprovedthanbefore.
Themaincontributionsofthispaperareoutlinedasfollows:Webuildaknowledgegraphbasecontainingmedicalentitiessuchasdiseasesentities,symptomentities,medicineentitiesandtheirrelationshipsfromlargescaleofQ&Ahealthcarewebsites,usingseveralknowledgeextractiontechniques.
Wevalidatetheeectofknowledgegraphintacklinglabelimperfectionproblemcomparingwithotherapproaches.
Ourapproachismoreeectivethanotherwaysonimprovingclassicationqualityanddataquality.
Ourapproachcanbeusedforarelativelyhighnoiselevelandstillachievesatisfyingperformance.
Thispaperisorganizedasfollows.
Section2reviewsthemostrelatedworksinrespectsoflabelerrorshandling.
Section3presentsourapproachtoconstructknowledgegraphbase.
Section4describespolishingandourknowledgegraphbasedcombinedapproach.
Section5describestheexperimentalperformanceandmeasurestheaectionofdepthofknowledgeaswell.
Finally,weconcludeanddiscussthepossibledirectionsoffutureworksinSection6.
1http://www.
google.
com/insidesearch/features/search/knowledge.
htmlAKnowledgeBasedApproachforTacklingMislabels3512RelatedWorkOverthecourseofthepast20years,solvingtheproblemofnoisesinthedatahasbeentheconsiderableattentionintheeldofmachinelearninganddatamining.
Mostoflearningalgorithmsdevelopedmechanismstodiminishtheimpactthatnoisesbringtotheclassicationperformance.
Pruninginadecisiontreeisusedtoavoidoverttingcausedbynoise.
Wilsonetal.
[7,8]appliedseveralinstance-pruningtechniqueswhichcanremovenoisefromthetrainingsetandreducethestorageconsumption.
However,theperformanceoftheselearningalgorithmsbecomesverybadwhenthenoiselevelistoohigh,andclassicationaccuracydeclinesalmostlinearlywiththeriseofthenoiselevel[1].
Aslongasthenoiseexistsintrainingdata,theclassicationqualitywillbeaectedseverely.
Thus,someapproachesuselteringmechanismstoidentifyandlterthenoiseexamplesbeforefeedingthemtotheclassier.
Wilsonetal.
[9]attemptedtolterthenoiseexamplesbyusinga3-NNclassierandapply1-NNclassierontheltereddata.
Ahaetal.
[10]proposedIB3(aversionofinstance-basedlearningalgorithm)toremovenoisewithlowerupdatingcostsandlowerstoragerequirements.
Brodleyetal.
[11,12]usedasetoflearningalgorithmstoconstructclassiersaslterstodatasetbeforefeedingittoclassierandachievedtosignicantlyimprovementfornoiselevelupto30%.
However,lteringnoisesenhancesdataqualityatthecostofdecreasingtheamountofdataretainedfortraining.
Italsoseemspettyandinappropriatetodiscarderrorlabeldataespeciallywhenthetrainingdataisdiculttore-collectsuchashistoricaldata[13].
Correctingthelabelerrorinsteadofsimplylteringthemisabetterapproachthataccomplishesbothdataqualityanddataamount.
Zengetal.
[6]proposedamethodcalledADE(automaticdataenhancement),whichcancorrectlabelerrorsthroughnumbersofiterationsusingmulti-layerneuralnetworkstrainedbybackpropagationinthebasicframework.
Tengetal.
[13,14]introducedanoisecorrectionmechanismcalledpolishingandcorrectnoisesbothinclassesandattributes.
Tengalsocomparedpolishingwithlteringandtraditionalapproachofavoidingovertting,andprovednoisecorrectionrecoversinformationnotavailablewiththeothertwoapproaches[14,15].
Sinceweapplypolishingasourbasicmethod,moredetaileddescriptionaboutpolishingwillbepresentedinSection4.
1.
Theapproachesdiscussedabovecontainthefollowinglimitations:(i)Someuselteringwhichmaydecreasethebulkofdata.
(ii)Mostoftheseapproacheshavenosignicantperformanceatahighnoiselevel.
(iii)Mostoftheseworksonlymeasuredthepromotionthattheirapproachesbringtoclassicationper-formance,yethaven'tmeasuredtheexactvaluesofdataqualitypromotion.
Therefore,weproposeanapproachbasedonknowledgegraphtotackletheselimitations.
352M.
Guoetal.
3KnowledgeGraphBuilding3.
1DataSourceWeuseabigdatasetover1000GBcollectedfromaChinesemedicalsocialQ&Awebsite2andChineseEncyclopediawebsiteBaiduEncyclopedia(BE)3tobuildamedicalknowledgebase.
Figure1showsaglimpseofafewentitiesandrela-tionshipsinthegraph.
Theedgebetweenadiseaseentityandasymptomentityimpliesthediseaseseemstohavealotofsymptoms.
Forexample,gastritishasdiarrheaandvomitsymptoms,andfatiguecanbeexplainedbyanemiaorParkinson.
Thereare3typesofentitiesintheknowledgegraph,andtwoentitiesofthesametypecannotbeconnecteddirectly.
Thisassumptionisjustiable.
Becauseintherealworld,twodiseasesarerelatedsincetheyshareseveralcom-monsymptoms.
Twomedicinesarerelatedsincetheycanbebothemployedtotreatonedisease.
Theirrelationshipislinkedbyotherentities,notthemselvesdirectly.
Besides,theQ&Aarchivesareusedtoestablishtrainingdatasetsappliedforlabelcorrection.
TheQ&Aarchivescontainnearly20millionQ&Apairsinwhicheverypaircontainsthequestionputforwardbypatientsandtheanswergivenbydoctorsandmedicalexperts.
Thepairalsocontainsdepartmentalin-formationaboutwhichhospitaldepartmentthepatientshouldseekhelpfor.
It'sappropriatetousethesedatatovalidateourapproach.
WeextractatrainingexamplefromeachQ&Apair.
Featuresareextractedfrompatients'descriptionsinquestions,anddepartmentsareusedaslabelsinthecorrectionphase.
vertigovomitheadacheanemiaaspirininfluenzadiarrheagastritisfatigueParkinsontremblephenothiazinediseasesymptommedicineMeniere'ssyndromeclarithromycinFig.
1.
Alocalstructureofthemedicalknowledgegraph2http://www.
120ask.
com3http://baike.
baidu.
comAKnowledgeBasedApproachforTacklingMislabels3533.
2EntitiesExtractionTobuildtheknowledgegraphbase,weextractdiseaseentities,symptomentitiesandmedicineentities.
Thesearedonebyfollowingsteps:Intherstphase,weusewebcrawlingtechniquetoacquirediseaseentities,medicineentitiesfromBE.
AsBEpagesarewellstructuredandtagged,weadoptMaximumEntropyalgorithmtoclassifytheseentitiestobroadcategories.
Aftersortingouttheseentitiesandtheircategories,weobtainaknownentityset.
Inthesecondphase,weconcludelinguisticpatternsofentitiesandusethesepatternstondmoreentitiesintheQ&Aarchives.
Bootstrappingonsyn-tacticpatternsarefrequentlyusedtoextractknowledge[3].
Chinesewordsarecomposedofcharacters,andaxes(prexesandsuxes,containsoneormorecharacters)usuallyhavespecicmeaningaboutthetypeofwords.
Forexample,medicinewords'mizolastine','clemastine'and'levocabastine'allsharethesamesux'stine',becausetheyaresimilarinchemicalcom-position.
Soweuseprexesandsuxesconcludedfromtheknownentitiessettondmoreandmoreentities.
Afteracquiringthesenewentities,weconductarticialselectiontodiscardentitieswhichdonotbelongtothemedicaldomain.
Hence,wegetabiggersetofentitiesthantherstphase.
Thenweperformseveraliterationofthesecondphaseandnallygetasetofnearly30,000diseaseentitiesand30,000medicineentities.
Sincemostpatientsdescribetheirsymptomsorallyandinformally,symptomscannotbeextractedfromencyclopediawebsites.
WerstlyuseTFIDF[16]andIG(informationgain)techniques[17]tondwordsandphrasesthataremoreinformativeintheQ&Aarchives,andarticiallyselectsomesymptomentities.
Thenweusebootstrappingtoseekmoreandmoresymptomentities.
Finallyweobtainasetofnearly4,000symptomentities.
3.
3RelationshipExtractionInmostoftheexistedknowledgebasessuchasWikipedia4,Freebase5,YAGO6,Wordnet7,therelationshipsbetweenentitiesorrelationshipsbetweenentitiesandtheirattributesareestablishedmanuallybyexpertsinrelatedeld.
Ourknowledgebasecontainsarelativelybigamountofentitiesandwedon'thaveprofessionalknowledgeinmedicaltaxonomy.
Thereforeweadoptamethodtoautomaticallyextractrelationshipsbetweenentitiesfrombigdata,whosedetailswillbediscussedinSection4.
2.
Inouropinion,theentitythatoccurssimultaneouslyinoneQ&Apairthathassomerelationships.
Wemakeanassumptionthatthemorefrequentlyentities4http://www.
wikipedia.
org5http://www.
freebase.
com6http://www.
mpi-inf.
mpg.
de/yago-naga/yago7http://wordnet.
princeton.
edu354M.
Guoetal.
occursimultaneouslyinQ&Apair,thestrongerrelationshipstheyhave.
Hence,weextractrelationshipsbetweenentitiesbasedonthecooccurrencerateofentities.
DetailsoncooccurrenceratearediscussedinSection4.
2.
4MislabelCorrectionAswementionedabove,polishingproposedbyTengetal.
[13,14]provestobequitewellinmislabeledcorrection.
Thekernelofourapproachistoadoptpolishingasthebasicmethodanduseinformationfromtheestablishedknowl-edgegraphtoadjusttheweightofentityfeaturesinlabelcorrectionphase.
Sinceknowledgegraphrepresentstherelationshipsofentityfeatures,itcanbeutilizedtostrengthenthemoreinformativeentityfeaturesandweakenthelessinforma-tiveentityfeatures.
Weassumethattheentitywithmoreconnectiontootherentitiesandgreaterco-occurrencerateswithothersplaysthemoreimportantroleinmislabeledcorrection.
Thus,theyshouldbeendowedwithmoreweight.
4.
1PolishingThebasicpolishingalgorithmcomprisestwophases:predictionandadjustment[14].
Thepredictionphaseaimsatndingcandidatetrainingexamplesthataresuspectedtocontrolerrorlabels,whiletheadjustmentphasedecidesthenalchangesintothecandidates.
Thepolishingalgorithmcanpredictandcorrectbothattributeserrorsandlabelerrors(i.
e.
classerrors).
Inthispaper,weuseittocorrectlabelerrors.
Inthepredictionphase,achosenlearningalgorithmperformsK-foldcrossvalidation.
Tengetal.
setKtobe10.
TheK-foldcrossvalidationdividesalltheexamplesinKgroupscalledfolds,andconstructsKclassierseachusingK-1foldsastrainingsetandthefoldingleftoutasthetestset.
IftheK-foldcrossvalidationalgorithmpredictsalabelinconsistentwiththeoriginallabel,thissamplewillbeaddedtosuspectedcandidates.
Intheadjustmentphase,foreachexampleofcandidatesset,Kclassiersconstructedinthepredictionphaseareusedtopredictlabelsofthisexample.
IfthepredictedlabelsofKclassiersareidenticalanddierentfromtheoriginallabel,polishingjudgesthenewlabeltobetherightoneandmodiestheexampleusingthenewlabel.
4.
2KnowledgeGraphWedeneourknowledgegraphtobeasetofvertices(v1,v2,vm)andedges(e1,e2,em).
Eachvertexrepresentsanentityandeachedgerepresentsadirectrelationshipbetweentwoentities.
Directrelationshipmeansastrongcon-nectionbetweentwoentityvertices.
Forinstance,abriefexampleofrelation-shipsofseveralentitieshavebeenshowninFig.
1,gastritishassymptomsofvomitanddiarrhea,sotheyareconnecteddirectly.
Andtherelationshipbe-tweenMenieressyndromeandgastritiscannotbedescribed,weonlyknowtheysharesomecommonsymptoms,sotheirrelationshipisindirect.
AKnowledgeBasedApproachforTacklingMislabels355Wedenedistanceastheshortestpathlengthbetweentwovertices.
distancebetweenanytwoverticescanbecomputedoncethelengthofanyedgesisknown.
Thelengthofedgeiscomputedusingtheformula:length(vi,vj)=1cooccurrencerate(vi,vj))(1)cooccurrenceratecanmeasureclosenessoftwoentityverticesiftheyhavedirectrelationship.
Thesmallerlengthis,thelargercooccurrencerateis,meaningtherelationshipbetweentwoentityverticesiscloser.
ThecooccurrencerateiscomputedfromtheQ&Adataaccordingtotheformula:cooccurrencerate(vi,vj)=2nijni+nj(2)Herevi,vjrepresentsanytwoentityvertices.
nijrepresentsthenumberofQ&Apairsinwhichviandvjoccursimultaneously,nidenestheaccountofpairsinwhichvioccurs,andnjdenesthenumberofpairsinwhichvjoccurs.
Apparentlythecooccurrencerateismaximumvalue1iftwoentitiesalwaysoccursimultaneouslyinQ&Apair.
IfcooccurrencerateisbelowathresholdM,weassumethetwoentityverticeshavenodirectrelationship,thusnoedgeexistingbetweenthem.
Also,wedenerelateddegreetomeasurerelationshipclosenessbetweentwoverticesevenwhentheyarenotdirectlyconnectedintheknowledgegraph(namelynoedgebetweenthem).
relateddegree(vi,vj)=1distance(vi,vj)(3)Obviouslyrelateddegreeisequivalenttocooccurrenceratewhenthereisanedgedirectlyconnectingtwoentityvertices.
distanceiscomputedusingDijkstraShortestPathalgorithm[18].
Andwedenestep(vi,vj)astheedgenumoftheshortestpathbetweenviandvj.
stepmeasuresthedepthofknowledgewediginthegraph.
Oneadvantageofknowledgegraphisthatwecanextendormodifythegraphoncewegraspnewknowledgethroughscienceresearches.
Whenwediscoveranewdisease,weadditintothegraphandconnectittoothersymptomsormedicinesbasedontheinformationweknowaboutit.
Andifthelatestmedicalresearchshowssomekindofmedicinecanhelptreatadisease,whichhasn'tbeenappliedbefore,wecanconnectthemandendowthemsomekindofrelationship.
4.
3WeightAdjustmentNumerousfeatureweightingmethodshavebeenappliedtoclassicationandprovetohaveapromotiveeectonclassicationaccuracy.
Thesemethodsincludeinformationgain(IG),termfrequency-inversedocumentfrequency(TFIDF),mutualinformation(MI),χ2statistic(CHI)[17].
Mostofthemde-pendonstatisticalanalysisontrainingdatatoselectandstrengthenthein-formativefeatures.
Whenapplyingthesemethodsinlabelcorrection,thenoise356M.
Guoetal.
partoftrainingdataprobablyinterferencestheoutcomewhenthenoiselevelisrelativelyhigh.
Thereforeweuseknowledgegraphtoadjustweightsofentityfeatures,becauseknowledgegraphhasseveraladvantagesasbelow:Knowledgegraphtechniqueisabletominedeeprelationshipsamongfea-tures,whiletraditionalstatisticalmethodssimplyanalyzeshallowrelation-shipsamongfeatures.
Knowledgegraphissimilartoarealworldmodel.
Itismorereasonableandprecisetosimulaterelationships.
Theknowledgecannotonlybeextractedfromcorporabutalsocomefromscienticknowledgeandlatestresearch,whichmakesthegraphtobeexten-sibleandrenewable.
Specically,wecomputetheweightsofentityfeaturesaccordingtothefor-mula:weight(vi)=initialweight+αvj∈V,vj=virelateddegree(vi,vj),step(vi,vj)Wedeneinitialweighttobe1,andαistheadjustmentfactortocontroltheimpactofknowledgegraphtofeatureweights.
MAXSTEPsetsalimittowhichverticestobeconsideredwhencomputingtheweightofavertex,namelytheanalysisdepthofknowledgegraph.
Webelievetheweightismorespecicifthedepthgoesdeeper.
However,thereisatradeobetweenanal-ysisdepthandcomputationalcomplexitybecausetherelatedverticesnumberisquitelargewhenweanalyzegraphquitedeeply.
WewillconductexperimentsabouttheeectofknowledgedepthoncorrectionlabelsintheSection4.
2.
4.
4CombinedAlgorithmOurapproachcombinespolishingandweightadjustmentbyknowledgegraphtocorrectnoiselabelsintrainingexamples.
WeuseMultinomialNaiveBayes(MNB)classierasthebasicclassierinK-foldcrossvalidation.
WechooseMNBbecauseitprovestobebothecientandaccuratefortextclassicationtasks[19].
Still,MNBmakesapoorassumptionthatfeaturesofexamplesareindependentofothers,whichareclearlyunreasonableinmostreal-worldtasks.
WeadjustfeatureweightsinMNBclassieraccordingtoknowledgegraphtocompensateforthisassumption.
Weightsofentityfeaturesarecalculatedac-cordingtoformula(4)andweightsofotherfeaturesaredenedas1.
Whencorrupttrainingdataisprepared,weadjusttheweightoffeaturesinthetrain-ingexamples,andgettheadjustedtrainingdata.
ThenweutilizethisdatatofollowthesameproceduresforpolishinginSection4.
1.
WealsosetKtobe10intheK-foldcrossvalidation.
Afterwardswecanobtaindatacorrectedbyourcombinedapproach.
ExperimentsofourcombinedapproachtomedicalQ&AAKnowledgeBasedApproachforTacklingMislabels357datawillberevealedinthefollowingsection.
Wewillevaluatetheeectofourapproachonbothclassicationaccuracyanddataqualitypromotion.
5ExperimentandEvaluationThissectionprovidesempiricalevidencethatourknowledgegraphbasedap-proachiseectiveinimprovingdataqualityandclassicationscores.
5.
1DataSetsTable1.
theformatofQ&ApairsdescriptionanswerdepartmentI'm23andmyhandsalwaysshake.
.
.
anditgetsworsewhenI'mnervous.
.
.
Therearemanyreasonsforyourshakyhands.
It'shardtoguessit.
.
.
neurologyIplaybadmintonandwhenIusebackhandserve,myhandtremble.
Mybrachioradialishurtstoo.
.
.
Itmaybecausedbyoverexercise,Isuggestyouseeabonesurgerydoctorto.
.
.
surgeryAswementionedabove,ourdataisextractedfromahugesetofnearly20millionmedicalQ&Apairs.
TheformatofdataisspeciedinTable1,eachexamplehasadescriptiontextwhichpatientsdepictabouttheircircumstancesandsymptoms,andeachexamplehasadepartmentlabelshowingthedepart-mentwherethispatientshouldbetreated.
ThedescriptiontextofQ&Apairisusuallyshort,lessthan200characters.
Thewholedatasetscontainmorethan10departments,Table2showsthedepartmentnamesandtheirprobabilitydis-tribution.
Weuseourapproachtoobtainandcorrecttheerrordepartmentlabelsintrainingexamples.
SincethecorpusisinChinese,weuseseveralNLPmeth-odsspecializedinhandlingChinesetext:tokenizingChinesetextandtransfertraditionalChinesecharacterstoChinesesimpliedcharacters.
Afterwards,weextractedapproximately200,000featuresfromtherawdata.
Finally,wegetnearly9,725,000traininginstances.
Inordertoobtainthecorruptdata,wearticiallycorruptthedatawithrandomlabelnoises.
Inthefollowingsubsectionswewillconductourapproachwithdierentnoiselevels.
5.
2EvaluationMeasuresAsTengetal.
pointsout,therearetwokindsofmeasurementmethodstoeval-uationlabelcorrection[13].
Onemethodaimsatndingouttowhatdegreethelabelcorrectionimprovesclassicationscore,includingaccuracy,F1score,F2scoreetc.
Wechooseaccuracyasthemeasuremetrictoevaluatetheclassi-cationqualityimprovementafterlabelcorrection.
Theothermethodmeasures358M.
Guoetal.
Table2.
departmentlabelsandtheirdistributiondepartmentdistributionobstetricsandgynaecology26.
6%internalmedicine20.
4%surgery11.
3%pediatrics9.
9%dermatology7.
9%ophthalmologyandotorhinolaryngology5.
8%neurology5.
5%psychology5.
1%traditionalChineseMedicine3.
1%infectiousdiseases1.
9%oncology1.
9%plasticsurgery1.
0%thedataqualityinaclassication-independentway,consideringwemaywanttoputthecorrecteddatainadditionalusesotherthanbuildingclassiers.
UnliketheNetReductionandCorrectAdjustmentusedbyTeng[13]tomeasurere-ductioninattributenoises,weusedierentmetricstoevaluatethedataqualitypromotion.
Thesemetricsarenoisereductionrate,precisionandrecall.
Asourapproachandinpolishingcorrectlabelsbythejudgementof10classiervoters,thechangesmadetotheexamplesarenotalwaysright.
Sothesemetricsareusedtoevaluatethesechanges.
noisereductionrate(NRR)isdenedin(5)andmeasuresthenoiseleveldecreaseafterlabelcorrection.
precisionmeasuresthepercentageofrightchangesinthewholechangesmadebylabelcorrectionapproaches.
recallmeasuresthepercentageoferrorlabelswhichisactuallycor-rected.
It'sobviousthatnoisereductionratemostintuitivelyreectsthedataqualitypromotion.
NRR=noiselevelinorigindatanoiselevelincorrecteddata(5)Weusethreemethods:Unpolishing,PolishingandPolishing+KGinclassicationaccuracycomparison.
Unpolishingapproachusestheunmodiedcorruptdatatobuildclassier.
Polishingapproachusesthedatacorrectedbypolishingmethodtobuildclassier.
AndPolishing+KGapproachusesthedatacorrectedbyourapproachtobuildclassier.
Allthethreeapproachesareappliedinaccuracycomparison,andthelattertwoareappliedinmislabeledreductionratecomparison.
Inaddition,wesetMAXSTEPto1inPolishing+KGwhencomparedwithothertwoapproaches.
5.
3ClassicationAccuracyWecomparetheclassicationaccuracyontrainingdataproducedbythreeap-proachesmentionedabove.
Foreachapproach,10-foldcrossvalidationisper-formedondatatoobtainclassicationaccuracy.
Ineachtrial,ninefoldsareAKnowledgeBasedApproachforTacklingMislabels359Fig.
2.
AcomparisonaccuracyondatabyUnpolishing,PolishingandPolishing+KGonthemedicalQ&Adatasetusedfortrainingdatatotesttheaccuracyoftherestfold.
Thenalaccuracyistheaverageaccuracyof10trials.
Hereweusecrossvalidationtoevaluateclassi-cationaccuracy,dierentfromlabelcorrectionphasewherecrossvalidationisusedtopickupcandidatesandconstructclassiersasvoters.
Wechoosecrossvalidationtovalidateaccuracybecauseitcanreducetheriskofoverttingonthetestset.
Figure2showsthecomparisonofthreeapproachonclassicationaccuracyatdierentnoiselevels.
ForUnpolishingapproach,accuracydeclinesalmostlinearlywiththenoiselevelincrease.
Atmostcases,theimprovementofPolishingandPolishing+KGonUnpolishingisquitesignicant,theperformanceofPolishingis10%-30%higherthanUnpolishing,whileourapproachPolishing+KGac-quiresaccuracyusually1%-4%higherthanthepurePolishing.
Wecanseenoisedatacutdownaccuracydramaticallywhennocorrectionisconducted.
Polishingcorrectspartoftheerrorlabelsandprovidesamuchhigheraccuracy.
Further-more,Polishing+KGapproachminestherelationshipsbetweenentityfeaturesandendowsmoreweightstothemoreinformativeones,soitachievesbetterac-curacyscorethanPolishing.
Particularly,atnoiselevelof0%,theimprovementsofPolishingandPolishing+KGarebothnotremarkable,Polishingismerely0.
3%higherthanUnpolishing,andPolish+KGis1.
3%higherthanUnpolishing,webelievePolishing+KGalsohaseectonimprovingclassicationaccuracyevenwhendataisnearlynoise-free.
360M.
Guoetal.
5.
4DataQualityPromotionWecomparetheclassication-independentmetricstotestdataqualitypromo-tionbyPolishingandPolishing+KGapproach.
Whenwearticiallycorruptthedata,wehavemadeamarktoeveryexamplewhatisthereallabelofit.
Afterlabelcorrectionbytwoapproaches,wechecktheprecision,recallandnoisere-ductionratedependingonthesemarks.
Weusenoisereductionrateasthemainmetricondataqualitypromotion,whiletheothertwohelpustounderstandandexplaintherelevantpromotion.
Figure3showsnoisereductionratebytwoapproaches.
ThenoisereductionrateofPolishing+KGisapproximately1%-4%higherthanPolishing.
Itseemsoddthatthenoisereductionisnegativeatnoiselevelof0%,whichmeansthenoisesincreaseafterlabelcorrection.
However,thisphenomenoncanbeexplained.
Atnoiselevelof0%,weassumedatatobenoise-free,whiledatacan'tbecompletelynoise-freeinreal-world.
SoitisreasonablethatPolishingandPolishing+KGhasmodiedsomelabelswhicharequitepossiblyerrorlabels.
Generallyspeaking,itisshownthatPolishinghasenormoussignicanceindataqualitypromotionandPolishing+KGachievesbetterperformanceonthebasisofPolishing.
Figure4showstheprecisionandrecall.
Wedonotconsiderateprecisionandrecallatnoiselevelof0%becauseit'smeaningless.
Atmostnoiselevels,precisionofPolishing+KGislessthanPolishing,howevertherecallofPolishing+KGismuchhigherthanPolishing.
Usuallyprecisionandrecallhaveacontradictoryrelationshipthatprecisiondecreasesalongwhenrecallincreases.
Soit'sreason-ablethatPolishing+KGhasaloweroverallprecision.
Whenthenoiselevelisquitehigher,theprecisionandrecallofPolishing+KGarebothhigherthanFig.
3.
AcomparisonofnoisereductionratebyPolishingandPolishing+KGonthemedicalQ&AdatasetAKnowledgeBasedApproachforTacklingMislabels361Fig.
4.
Acomparisonofprecision,recallbyPolishingandPolishing+KGonthemedicalQ&AdatasetPolishing.
Weassumethisiscausedbythatknowledgediminishestheinterfer-enceofnoises,theeectismoreremarkablewhenthenoiselevelishigher.
5.
5KnowledgeDepthAectionWeconductanexperimentofhowknowledgedepthaectstheresults.
Accordingto(3),weadjusttheentityweightsbycomputingclosenessofanentitytootherentities.
WebelievethebiggerMAXSTEPis,themorepreciseweightswillbegenerated.
Thisthoughtisdrivenbythatwegetmoreinformationaboutsome-thingwhenwerecognizeitmoredeeply.
Figure5showstheaccuratecomparisonofdierentknowledgedepthfrom1to3.
Theaccuracyimproves0-1.
3%whenFig.
5.
Knowledgedepthaectiononaccuracy362M.
Guoetal.
knowledgedepthgrowsfrom1to2atdierentnoiselevels,whiletheaccuracyimprovementisinsignicantwhendepthgrowsfrom2to3.
Whenknowledgedepthgrows,theamountofrelationshipsofoneentitytoothersgrowsrapidlyandmoreweightsareendowedwiththemoreinformativeones.
Theresultsshowdeepknowledgeperceptioncanenhanceclassicationperformance.
6ConclusionInthispaper,wepresentaknowledgegraphbasedapproachcombinedwithpol-ishingtohandlelabelimperfectionproblem.
Thismethodisdistinctfromprevi-ousstatisticalmethodsinthatittriestorecognizethedatainawaysimilartotherealworld.
Experimentalresultsdemonstrateourapproachhasanimpactonboostingclassicationperformanceanddataquality.
Itcaneectivelycorrectmislabeledevenunderthecircumstanceofaquitehighnoiselevelofapproxi-mately60%.
Besidehandlingthenoisedata,theknowledgegraphtechniqueweusedcanbeappliedinfeatureselectioninclassicationaswell.
Ourfutureworkwillbefocusedonamelioratingthegraphbyestablishingmoretypesofentitiesandmoredetailedrelationshipsinit.
Moreresearcheswillbeconductedtorecognizedatanoisesinamorehuman-likeratherthanmachine-likeapproach.
Inaddition,weshallapplyourapproachtoothereldssuchassocialnetworksandbusinessdataanalysis.
Acknowledgement.
ThisworkwassupportedbytheNSFC(No.
61272099,61261160502and61202025),ShanghaiExcellentAcademicLeadersPlan(No.
11XD1402900),theProgramforChangjiangScholarsandInnovativeResearchTeaminUniversityofChina(IRT1158,PCSIRT),theScienticInnovationActofSTCSM(No.
13511504200),SingaporeNRF(CREATEE2S2),andtheEUFP7CLIMBERproject(No.
PIRSES-GA-2012-318939).
References1.
Zhu,X.
,Wu,X.
:Classnoisevs.
attributenoise:Aquantitativestudy.
ArticialIntelligenceReview22(3),177–210(2004)2.
Quinlan,J.
R.
:Inductionofdecisiontrees.
MachineLearning1(1),81–106(1986)3.
Wu,W.
,Li,H.
,Wang,H.
,Zhu,K.
Q.
:Probase:Aprobabilistictaxonomyfortextunderstanding.
In:Proceedingsofthe2012ACMSIGMODInternationalConfer-enceonManagementofData,pp.
481–492.
ACM(2012)4.
Zhang,Y.
:Contextualizingconsumerhealthinformationsearching:ananalysisofquestionsinasocialq&acommunity.
In:Proceedingsofthe1stACMInternationalHealthInformaticsSymposium,pp.
210–219.
ACM(2010)5.
Kunz,H.
,Schaaf,T.
:Generalandspecicformalizationapproachforabalancedscorecard:Anexpertsystemwithapplicationinhealthcare.
ExpertSystemswithApplications38(3),1947–1955(2011)6.
Zeng,X.
,Martinez,T.
R.
:Analgorithmforcorrectingmislabeleddata.
IntelligentDataAnalysis5(6),491–502(2001)AKnowledgeBasedApproachforTacklingMislabels3637.
Wilson,D.
R.
,Martinez,T.
R.
:Instancepruningtechniques.
In:ICML,vol.
97,pp.
403–411(1997)8.
Wilson,D.
R.
,Martinez,T.
R.
:Reductiontechniquesforinstance-basedlearningalgorithms.
MachineLearning38(3),257–286(2000)9.
Wilson,D.
L.
:Asymptoticpropertiesofnearestneighborrulesusingediteddata.
IEEETransactionsonSystems,ManandCybernetics(3),408–421(1972)10.
Aha,D.
W.
,Kibler,D.
F.
:Noise-tolerantinstance-basedlearningalgorithms.
In:IJCAI,pp.
794–799.
Citeseer(1989)11.
Brodley,C.
E.
,Friedl,M.
A.
:Identifyingandeliminatingmislabeledtrainingin-stances.
In:AAAI/IAAI,vol.
1,pp.
799–805.
Citeseer(1996)12.
Brodley,C.
E.
,Friedl,M.
A.
:Identifyingmislabeledtrainingdata.
arXivpreprintarXiv:1106.
0219(2011)13.
Teng,C.
M.
:Evaluatingnoisecorrection.
In:Mizoguchi,R.
,Slaney,J.
K.
(eds.
)PRICAI2000.
LNCS,vol.
1886,pp.
188–198.
Springer,Heidelberg(2000)14.
Teng,C.
M.
:Polishingblemishes:Issuesindatacorrection.
IEEEIntelligentSys-tems19(2),34–39(2004)15.
Teng,C.
M.
:Acomparisonofnoisehandlingtechniques.
In:FLAIRSConference,pp.
269–273(2001)16.
Li,J.
,Zhang,K.
,etal.
:Keywordextractionbasedontf/idfforchinesenewsdocument.
WuhanUniversityJournalofNaturalSciences12(5),917–921(2007)17.
Yang,Y.
,Pedersen,J.
O.
:Acomparativestudyonfeatureselectionintextcatego-rization.
In:ICML,vol.
97,pp.
412–420(1997)18.
Dijkstra,E.
W.
:Anoteontwoproblemsinconnexionwithgraphs.
NumerischeMathematik1(1),269–271(1959)19.
McCallum,A.
,Nigam,K.
,etal.
:Acomparisonofeventmodelsfornaivebayestextclassication.
In:AAAI1998WorkshoponLearningforTextCategorization,vol.
752,pp.
41–48.
Citeseer(1998)
sjtu.
edu.
cn2SchoolofComputerScience&SchoolofSoftware,NanjingUniversityofPostsandTelecommunications,Chinahuakanglee@njupt.
edu.
cnAbstract.
Theperformanceofclassicationmodelsextremelyreliesonthequalityoftrainingdata.
However,labelimperfectionisaninherentfaultoftrainingdata,whichisimpossiblemanuallyhandledinbigdataenvironment.
Variousmethodshavebeenproposedtoremovelabelnoisesinordertoimproveclassicationquality,withthesideeectofcuttingdowndatabulk.
Inthispaper,weproposeaknowledgebasedapproachfortacklingmislabeledmulti-classbigdata,inwhichknowledgegraphtechniqueiscombinedwithotherdatacorrectionmethodtoperceiveandcorrecttheerrorlabelsinbigdata.
Theknowledgegraphisbuiltwiththemedicalconceptsextractedfromonlinehealthconsultingandmedicalguidance.
Experimentalresultsshowourknowledgegraphbasedapproachcaneectivelyimprovedataqualityandclassicationaccuracy.
Furthermore,thisapproachcanbeappliedinotherdataminingtasksrequiringdeepunderstanding.
Keywords:#eswc2014Guo,labelimperfection,knowledgegraph,labelcorrection,classication.
1IntroductionFormachinelearningresearch,manyresearchersfocusonimprovinglearningalgorithmswithleastlearningbias,thusthedataqualityhasbecomethecrucialissuewhenitisgiventoacertainmachinelearningalgorithm.
Unfortunately,realworlddatainevitablycontainsunexpectednoises(i.
e.
labelerrors)whichcandisturbtheperformanceofclassicationinmultipleaspectslikeaccuracy,modelingtimeandcomputingcomplexity.
Itprovesthatclassicationaccuraciesalmostdeclinelinearlywiththeincreaseofnoiselevel[1].
Mostlabelerrorsintrainingdatacomefromdataentryerrors,transmiterrorsandsubjectivityoftaggersandsoon.
Dataentryerrorsinlargedatasetaresevereandcommon.
Thenoiselevelisusuallyaround5%ormore[1].
Furthermore,itseemsdiculttoavoidoreventocutdownontheerrorsbecausetherearenostandardsorspecicationsdealingwithdataentryerrors.
TransmissionerrorsV.
Presuttietal.
(Eds.
):ESWC2014,LNCS8465,pp.
349–363,2014.
cSpringerInternationalPublishingSwitzerland2014350M.
Guoetal.
takeplaceincommunicationbreakdown.
Therefore,inordertoincreasetheaccuracy,mostoftrainingdataarelabeledmanuallyevenifthepeopleareverysubjectivebecauseoftheknowledgelimitationinspecicdomains.
Evenexpertsandprofessionalsarenotabsolutelycondentabouttheirlabeling.
Therefore,thenecessityofdevelopingmethodstoremoveorcorrectlabelerrorsisself-evident.
Manylearningalgorithmsmadelabelnoisedtreatmentmechanisms.
Forex-ample,pruningindecisiontreealgorithmcanavoidover-ttingcausedbynoises[2].
Still,whennoiselevelishigh,learningalgorithmsarenotabletoeectively.
Othermethodstrytohandlethenoisesindatabeforeclassication,includinglteringnoisesandcorrectingnoises.
Thispaperproposedanapproachbasedonknowledgegraphtechniquetoperceiveandcorrectlabelerrorsinbigdataenvironment.
KnowledgegraphisaconceptproposedbyGoogle1foritssearchengineandotherapplications,whosekernelisutilizingontologytosimulateentitiesandrelationshipsintherealworldtohelpmachineunderstandtheworldintelligently.
Theusageofknowl-edgegraphenablemachinestobetterunderstandtextdocuments[3].
Thereforeweintroducethisconceptinnoisecorrectiontobetterperceivethenaturecon-ditions.
WeusebigsocialdatacollectedfrommedicalQ&Awebsitestovalidateourapproachfortacklinglabelimperfection.
MedicalQ&Asystemservesforonlinehealthconsultingandmedicalguidance.
Astudyreports83%ofInternetusersintheU.
S.
seekhealthinformationonline[4]andhealthcaresystemareplayingamuchmoreessentialroleintherecentlife[5].
OurapproachimplementstheknowledgegraphonalabelcorrectionmethodraisedbyTengetal.
[6].
Concretely,NaiveBayesclassierisutilizedtorec-ognizeandmodifytheerrorlabelsoftrainingdata.
Afterlabelmodication,thenoiselevelhasproventodeclinedramaticallythanbefore.
Thenweusethemodieddatatoconstructclassierforclassicationratherthancorrection,andtheaccuracyhasimprovedthanbefore.
Themaincontributionsofthispaperareoutlinedasfollows:Webuildaknowledgegraphbasecontainingmedicalentitiessuchasdiseasesentities,symptomentities,medicineentitiesandtheirrelationshipsfromlargescaleofQ&Ahealthcarewebsites,usingseveralknowledgeextractiontechniques.
Wevalidatetheeectofknowledgegraphintacklinglabelimperfectionproblemcomparingwithotherapproaches.
Ourapproachismoreeectivethanotherwaysonimprovingclassicationqualityanddataquality.
Ourapproachcanbeusedforarelativelyhighnoiselevelandstillachievesatisfyingperformance.
Thispaperisorganizedasfollows.
Section2reviewsthemostrelatedworksinrespectsoflabelerrorshandling.
Section3presentsourapproachtoconstructknowledgegraphbase.
Section4describespolishingandourknowledgegraphbasedcombinedapproach.
Section5describestheexperimentalperformanceandmeasurestheaectionofdepthofknowledgeaswell.
Finally,weconcludeanddiscussthepossibledirectionsoffutureworksinSection6.
1http://www.
google.
com/insidesearch/features/search/knowledge.
htmlAKnowledgeBasedApproachforTacklingMislabels3512RelatedWorkOverthecourseofthepast20years,solvingtheproblemofnoisesinthedatahasbeentheconsiderableattentionintheeldofmachinelearninganddatamining.
Mostoflearningalgorithmsdevelopedmechanismstodiminishtheimpactthatnoisesbringtotheclassicationperformance.
Pruninginadecisiontreeisusedtoavoidoverttingcausedbynoise.
Wilsonetal.
[7,8]appliedseveralinstance-pruningtechniqueswhichcanremovenoisefromthetrainingsetandreducethestorageconsumption.
However,theperformanceoftheselearningalgorithmsbecomesverybadwhenthenoiselevelistoohigh,andclassicationaccuracydeclinesalmostlinearlywiththeriseofthenoiselevel[1].
Aslongasthenoiseexistsintrainingdata,theclassicationqualitywillbeaectedseverely.
Thus,someapproachesuselteringmechanismstoidentifyandlterthenoiseexamplesbeforefeedingthemtotheclassier.
Wilsonetal.
[9]attemptedtolterthenoiseexamplesbyusinga3-NNclassierandapply1-NNclassierontheltereddata.
Ahaetal.
[10]proposedIB3(aversionofinstance-basedlearningalgorithm)toremovenoisewithlowerupdatingcostsandlowerstoragerequirements.
Brodleyetal.
[11,12]usedasetoflearningalgorithmstoconstructclassiersaslterstodatasetbeforefeedingittoclassierandachievedtosignicantlyimprovementfornoiselevelupto30%.
However,lteringnoisesenhancesdataqualityatthecostofdecreasingtheamountofdataretainedfortraining.
Italsoseemspettyandinappropriatetodiscarderrorlabeldataespeciallywhenthetrainingdataisdiculttore-collectsuchashistoricaldata[13].
Correctingthelabelerrorinsteadofsimplylteringthemisabetterapproachthataccomplishesbothdataqualityanddataamount.
Zengetal.
[6]proposedamethodcalledADE(automaticdataenhancement),whichcancorrectlabelerrorsthroughnumbersofiterationsusingmulti-layerneuralnetworkstrainedbybackpropagationinthebasicframework.
Tengetal.
[13,14]introducedanoisecorrectionmechanismcalledpolishingandcorrectnoisesbothinclassesandattributes.
Tengalsocomparedpolishingwithlteringandtraditionalapproachofavoidingovertting,andprovednoisecorrectionrecoversinformationnotavailablewiththeothertwoapproaches[14,15].
Sinceweapplypolishingasourbasicmethod,moredetaileddescriptionaboutpolishingwillbepresentedinSection4.
1.
Theapproachesdiscussedabovecontainthefollowinglimitations:(i)Someuselteringwhichmaydecreasethebulkofdata.
(ii)Mostoftheseapproacheshavenosignicantperformanceatahighnoiselevel.
(iii)Mostoftheseworksonlymeasuredthepromotionthattheirapproachesbringtoclassicationper-formance,yethaven'tmeasuredtheexactvaluesofdataqualitypromotion.
Therefore,weproposeanapproachbasedonknowledgegraphtotackletheselimitations.
352M.
Guoetal.
3KnowledgeGraphBuilding3.
1DataSourceWeuseabigdatasetover1000GBcollectedfromaChinesemedicalsocialQ&Awebsite2andChineseEncyclopediawebsiteBaiduEncyclopedia(BE)3tobuildamedicalknowledgebase.
Figure1showsaglimpseofafewentitiesandrela-tionshipsinthegraph.
Theedgebetweenadiseaseentityandasymptomentityimpliesthediseaseseemstohavealotofsymptoms.
Forexample,gastritishasdiarrheaandvomitsymptoms,andfatiguecanbeexplainedbyanemiaorParkinson.
Thereare3typesofentitiesintheknowledgegraph,andtwoentitiesofthesametypecannotbeconnecteddirectly.
Thisassumptionisjustiable.
Becauseintherealworld,twodiseasesarerelatedsincetheyshareseveralcom-monsymptoms.
Twomedicinesarerelatedsincetheycanbebothemployedtotreatonedisease.
Theirrelationshipislinkedbyotherentities,notthemselvesdirectly.
Besides,theQ&Aarchivesareusedtoestablishtrainingdatasetsappliedforlabelcorrection.
TheQ&Aarchivescontainnearly20millionQ&Apairsinwhicheverypaircontainsthequestionputforwardbypatientsandtheanswergivenbydoctorsandmedicalexperts.
Thepairalsocontainsdepartmentalin-formationaboutwhichhospitaldepartmentthepatientshouldseekhelpfor.
It'sappropriatetousethesedatatovalidateourapproach.
WeextractatrainingexamplefromeachQ&Apair.
Featuresareextractedfrompatients'descriptionsinquestions,anddepartmentsareusedaslabelsinthecorrectionphase.
vertigovomitheadacheanemiaaspirininfluenzadiarrheagastritisfatigueParkinsontremblephenothiazinediseasesymptommedicineMeniere'ssyndromeclarithromycinFig.
1.
Alocalstructureofthemedicalknowledgegraph2http://www.
120ask.
com3http://baike.
baidu.
comAKnowledgeBasedApproachforTacklingMislabels3533.
2EntitiesExtractionTobuildtheknowledgegraphbase,weextractdiseaseentities,symptomentitiesandmedicineentities.
Thesearedonebyfollowingsteps:Intherstphase,weusewebcrawlingtechniquetoacquirediseaseentities,medicineentitiesfromBE.
AsBEpagesarewellstructuredandtagged,weadoptMaximumEntropyalgorithmtoclassifytheseentitiestobroadcategories.
Aftersortingouttheseentitiesandtheircategories,weobtainaknownentityset.
Inthesecondphase,weconcludelinguisticpatternsofentitiesandusethesepatternstondmoreentitiesintheQ&Aarchives.
Bootstrappingonsyn-tacticpatternsarefrequentlyusedtoextractknowledge[3].
Chinesewordsarecomposedofcharacters,andaxes(prexesandsuxes,containsoneormorecharacters)usuallyhavespecicmeaningaboutthetypeofwords.
Forexample,medicinewords'mizolastine','clemastine'and'levocabastine'allsharethesamesux'stine',becausetheyaresimilarinchemicalcom-position.
Soweuseprexesandsuxesconcludedfromtheknownentitiessettondmoreandmoreentities.
Afteracquiringthesenewentities,weconductarticialselectiontodiscardentitieswhichdonotbelongtothemedicaldomain.
Hence,wegetabiggersetofentitiesthantherstphase.
Thenweperformseveraliterationofthesecondphaseandnallygetasetofnearly30,000diseaseentitiesand30,000medicineentities.
Sincemostpatientsdescribetheirsymptomsorallyandinformally,symptomscannotbeextractedfromencyclopediawebsites.
WerstlyuseTFIDF[16]andIG(informationgain)techniques[17]tondwordsandphrasesthataremoreinformativeintheQ&Aarchives,andarticiallyselectsomesymptomentities.
Thenweusebootstrappingtoseekmoreandmoresymptomentities.
Finallyweobtainasetofnearly4,000symptomentities.
3.
3RelationshipExtractionInmostoftheexistedknowledgebasessuchasWikipedia4,Freebase5,YAGO6,Wordnet7,therelationshipsbetweenentitiesorrelationshipsbetweenentitiesandtheirattributesareestablishedmanuallybyexpertsinrelatedeld.
Ourknowledgebasecontainsarelativelybigamountofentitiesandwedon'thaveprofessionalknowledgeinmedicaltaxonomy.
Thereforeweadoptamethodtoautomaticallyextractrelationshipsbetweenentitiesfrombigdata,whosedetailswillbediscussedinSection4.
2.
Inouropinion,theentitythatoccurssimultaneouslyinoneQ&Apairthathassomerelationships.
Wemakeanassumptionthatthemorefrequentlyentities4http://www.
wikipedia.
org5http://www.
freebase.
com6http://www.
mpi-inf.
mpg.
de/yago-naga/yago7http://wordnet.
princeton.
edu354M.
Guoetal.
occursimultaneouslyinQ&Apair,thestrongerrelationshipstheyhave.
Hence,weextractrelationshipsbetweenentitiesbasedonthecooccurrencerateofentities.
DetailsoncooccurrenceratearediscussedinSection4.
2.
4MislabelCorrectionAswementionedabove,polishingproposedbyTengetal.
[13,14]provestobequitewellinmislabeledcorrection.
Thekernelofourapproachistoadoptpolishingasthebasicmethodanduseinformationfromtheestablishedknowl-edgegraphtoadjusttheweightofentityfeaturesinlabelcorrectionphase.
Sinceknowledgegraphrepresentstherelationshipsofentityfeatures,itcanbeutilizedtostrengthenthemoreinformativeentityfeaturesandweakenthelessinforma-tiveentityfeatures.
Weassumethattheentitywithmoreconnectiontootherentitiesandgreaterco-occurrencerateswithothersplaysthemoreimportantroleinmislabeledcorrection.
Thus,theyshouldbeendowedwithmoreweight.
4.
1PolishingThebasicpolishingalgorithmcomprisestwophases:predictionandadjustment[14].
Thepredictionphaseaimsatndingcandidatetrainingexamplesthataresuspectedtocontrolerrorlabels,whiletheadjustmentphasedecidesthenalchangesintothecandidates.
Thepolishingalgorithmcanpredictandcorrectbothattributeserrorsandlabelerrors(i.
e.
classerrors).
Inthispaper,weuseittocorrectlabelerrors.
Inthepredictionphase,achosenlearningalgorithmperformsK-foldcrossvalidation.
Tengetal.
setKtobe10.
TheK-foldcrossvalidationdividesalltheexamplesinKgroupscalledfolds,andconstructsKclassierseachusingK-1foldsastrainingsetandthefoldingleftoutasthetestset.
IftheK-foldcrossvalidationalgorithmpredictsalabelinconsistentwiththeoriginallabel,thissamplewillbeaddedtosuspectedcandidates.
Intheadjustmentphase,foreachexampleofcandidatesset,Kclassiersconstructedinthepredictionphaseareusedtopredictlabelsofthisexample.
IfthepredictedlabelsofKclassiersareidenticalanddierentfromtheoriginallabel,polishingjudgesthenewlabeltobetherightoneandmodiestheexampleusingthenewlabel.
4.
2KnowledgeGraphWedeneourknowledgegraphtobeasetofvertices(v1,v2,vm)andedges(e1,e2,em).
Eachvertexrepresentsanentityandeachedgerepresentsadirectrelationshipbetweentwoentities.
Directrelationshipmeansastrongcon-nectionbetweentwoentityvertices.
Forinstance,abriefexampleofrelation-shipsofseveralentitieshavebeenshowninFig.
1,gastritishassymptomsofvomitanddiarrhea,sotheyareconnecteddirectly.
Andtherelationshipbe-tweenMenieressyndromeandgastritiscannotbedescribed,weonlyknowtheysharesomecommonsymptoms,sotheirrelationshipisindirect.
AKnowledgeBasedApproachforTacklingMislabels355Wedenedistanceastheshortestpathlengthbetweentwovertices.
distancebetweenanytwoverticescanbecomputedoncethelengthofanyedgesisknown.
Thelengthofedgeiscomputedusingtheformula:length(vi,vj)=1cooccurrencerate(vi,vj))(1)cooccurrenceratecanmeasureclosenessoftwoentityverticesiftheyhavedirectrelationship.
Thesmallerlengthis,thelargercooccurrencerateis,meaningtherelationshipbetweentwoentityverticesiscloser.
ThecooccurrencerateiscomputedfromtheQ&Adataaccordingtotheformula:cooccurrencerate(vi,vj)=2nijni+nj(2)Herevi,vjrepresentsanytwoentityvertices.
nijrepresentsthenumberofQ&Apairsinwhichviandvjoccursimultaneously,nidenestheaccountofpairsinwhichvioccurs,andnjdenesthenumberofpairsinwhichvjoccurs.
Apparentlythecooccurrencerateismaximumvalue1iftwoentitiesalwaysoccursimultaneouslyinQ&Apair.
IfcooccurrencerateisbelowathresholdM,weassumethetwoentityverticeshavenodirectrelationship,thusnoedgeexistingbetweenthem.
Also,wedenerelateddegreetomeasurerelationshipclosenessbetweentwoverticesevenwhentheyarenotdirectlyconnectedintheknowledgegraph(namelynoedgebetweenthem).
relateddegree(vi,vj)=1distance(vi,vj)(3)Obviouslyrelateddegreeisequivalenttocooccurrenceratewhenthereisanedgedirectlyconnectingtwoentityvertices.
distanceiscomputedusingDijkstraShortestPathalgorithm[18].
Andwedenestep(vi,vj)astheedgenumoftheshortestpathbetweenviandvj.
stepmeasuresthedepthofknowledgewediginthegraph.
Oneadvantageofknowledgegraphisthatwecanextendormodifythegraphoncewegraspnewknowledgethroughscienceresearches.
Whenwediscoveranewdisease,weadditintothegraphandconnectittoothersymptomsormedicinesbasedontheinformationweknowaboutit.
Andifthelatestmedicalresearchshowssomekindofmedicinecanhelptreatadisease,whichhasn'tbeenappliedbefore,wecanconnectthemandendowthemsomekindofrelationship.
4.
3WeightAdjustmentNumerousfeatureweightingmethodshavebeenappliedtoclassicationandprovetohaveapromotiveeectonclassicationaccuracy.
Thesemethodsincludeinformationgain(IG),termfrequency-inversedocumentfrequency(TFIDF),mutualinformation(MI),χ2statistic(CHI)[17].
Mostofthemde-pendonstatisticalanalysisontrainingdatatoselectandstrengthenthein-formativefeatures.
Whenapplyingthesemethodsinlabelcorrection,thenoise356M.
Guoetal.
partoftrainingdataprobablyinterferencestheoutcomewhenthenoiselevelisrelativelyhigh.
Thereforeweuseknowledgegraphtoadjustweightsofentityfeatures,becauseknowledgegraphhasseveraladvantagesasbelow:Knowledgegraphtechniqueisabletominedeeprelationshipsamongfea-tures,whiletraditionalstatisticalmethodssimplyanalyzeshallowrelation-shipsamongfeatures.
Knowledgegraphissimilartoarealworldmodel.
Itismorereasonableandprecisetosimulaterelationships.
Theknowledgecannotonlybeextractedfromcorporabutalsocomefromscienticknowledgeandlatestresearch,whichmakesthegraphtobeexten-sibleandrenewable.
Specically,wecomputetheweightsofentityfeaturesaccordingtothefor-mula:weight(vi)=initialweight+αvj∈V,vj=virelateddegree(vi,vj),step(vi,vj)
MAXSTEPsetsalimittowhichverticestobeconsideredwhencomputingtheweightofavertex,namelytheanalysisdepthofknowledgegraph.
Webelievetheweightismorespecicifthedepthgoesdeeper.
However,thereisatradeobetweenanal-ysisdepthandcomputationalcomplexitybecausetherelatedverticesnumberisquitelargewhenweanalyzegraphquitedeeply.
WewillconductexperimentsabouttheeectofknowledgedepthoncorrectionlabelsintheSection4.
2.
4.
4CombinedAlgorithmOurapproachcombinespolishingandweightadjustmentbyknowledgegraphtocorrectnoiselabelsintrainingexamples.
WeuseMultinomialNaiveBayes(MNB)classierasthebasicclassierinK-foldcrossvalidation.
WechooseMNBbecauseitprovestobebothecientandaccuratefortextclassicationtasks[19].
Still,MNBmakesapoorassumptionthatfeaturesofexamplesareindependentofothers,whichareclearlyunreasonableinmostreal-worldtasks.
WeadjustfeatureweightsinMNBclassieraccordingtoknowledgegraphtocompensateforthisassumption.
Weightsofentityfeaturesarecalculatedac-cordingtoformula(4)andweightsofotherfeaturesaredenedas1.
Whencorrupttrainingdataisprepared,weadjusttheweightoffeaturesinthetrain-ingexamples,andgettheadjustedtrainingdata.
ThenweutilizethisdatatofollowthesameproceduresforpolishinginSection4.
1.
WealsosetKtobe10intheK-foldcrossvalidation.
Afterwardswecanobtaindatacorrectedbyourcombinedapproach.
ExperimentsofourcombinedapproachtomedicalQ&AAKnowledgeBasedApproachforTacklingMislabels357datawillberevealedinthefollowingsection.
Wewillevaluatetheeectofourapproachonbothclassicationaccuracyanddataqualitypromotion.
5ExperimentandEvaluationThissectionprovidesempiricalevidencethatourknowledgegraphbasedap-proachiseectiveinimprovingdataqualityandclassicationscores.
5.
1DataSetsTable1.
theformatofQ&ApairsdescriptionanswerdepartmentI'm23andmyhandsalwaysshake.
.
.
anditgetsworsewhenI'mnervous.
.
.
Therearemanyreasonsforyourshakyhands.
It'shardtoguessit.
.
.
neurologyIplaybadmintonandwhenIusebackhandserve,myhandtremble.
Mybrachioradialishurtstoo.
.
.
Itmaybecausedbyoverexercise,Isuggestyouseeabonesurgerydoctorto.
.
.
surgeryAswementionedabove,ourdataisextractedfromahugesetofnearly20millionmedicalQ&Apairs.
TheformatofdataisspeciedinTable1,eachexamplehasadescriptiontextwhichpatientsdepictabouttheircircumstancesandsymptoms,andeachexamplehasadepartmentlabelshowingthedepart-mentwherethispatientshouldbetreated.
ThedescriptiontextofQ&Apairisusuallyshort,lessthan200characters.
Thewholedatasetscontainmorethan10departments,Table2showsthedepartmentnamesandtheirprobabilitydis-tribution.
Weuseourapproachtoobtainandcorrecttheerrordepartmentlabelsintrainingexamples.
SincethecorpusisinChinese,weuseseveralNLPmeth-odsspecializedinhandlingChinesetext:tokenizingChinesetextandtransfertraditionalChinesecharacterstoChinesesimpliedcharacters.
Afterwards,weextractedapproximately200,000featuresfromtherawdata.
Finally,wegetnearly9,725,000traininginstances.
Inordertoobtainthecorruptdata,wearticiallycorruptthedatawithrandomlabelnoises.
Inthefollowingsubsectionswewillconductourapproachwithdierentnoiselevels.
5.
2EvaluationMeasuresAsTengetal.
pointsout,therearetwokindsofmeasurementmethodstoeval-uationlabelcorrection[13].
Onemethodaimsatndingouttowhatdegreethelabelcorrectionimprovesclassicationscore,includingaccuracy,F1score,F2scoreetc.
Wechooseaccuracyasthemeasuremetrictoevaluatetheclassi-cationqualityimprovementafterlabelcorrection.
Theothermethodmeasures358M.
Guoetal.
Table2.
departmentlabelsandtheirdistributiondepartmentdistributionobstetricsandgynaecology26.
6%internalmedicine20.
4%surgery11.
3%pediatrics9.
9%dermatology7.
9%ophthalmologyandotorhinolaryngology5.
8%neurology5.
5%psychology5.
1%traditionalChineseMedicine3.
1%infectiousdiseases1.
9%oncology1.
9%plasticsurgery1.
0%thedataqualityinaclassication-independentway,consideringwemaywanttoputthecorrecteddatainadditionalusesotherthanbuildingclassiers.
UnliketheNetReductionandCorrectAdjustmentusedbyTeng[13]tomeasurere-ductioninattributenoises,weusedierentmetricstoevaluatethedataqualitypromotion.
Thesemetricsarenoisereductionrate,precisionandrecall.
Asourapproachandinpolishingcorrectlabelsbythejudgementof10classiervoters,thechangesmadetotheexamplesarenotalwaysright.
Sothesemetricsareusedtoevaluatethesechanges.
noisereductionrate(NRR)isdenedin(5)andmeasuresthenoiseleveldecreaseafterlabelcorrection.
precisionmeasuresthepercentageofrightchangesinthewholechangesmadebylabelcorrectionapproaches.
recallmeasuresthepercentageoferrorlabelswhichisactuallycor-rected.
It'sobviousthatnoisereductionratemostintuitivelyreectsthedataqualitypromotion.
NRR=noiselevelinorigindatanoiselevelincorrecteddata(5)Weusethreemethods:Unpolishing,PolishingandPolishing+KGinclassicationaccuracycomparison.
Unpolishingapproachusestheunmodiedcorruptdatatobuildclassier.
Polishingapproachusesthedatacorrectedbypolishingmethodtobuildclassier.
AndPolishing+KGapproachusesthedatacorrectedbyourapproachtobuildclassier.
Allthethreeapproachesareappliedinaccuracycomparison,andthelattertwoareappliedinmislabeledreductionratecomparison.
Inaddition,wesetMAXSTEPto1inPolishing+KGwhencomparedwithothertwoapproaches.
5.
3ClassicationAccuracyWecomparetheclassicationaccuracyontrainingdataproducedbythreeap-proachesmentionedabove.
Foreachapproach,10-foldcrossvalidationisper-formedondatatoobtainclassicationaccuracy.
Ineachtrial,ninefoldsareAKnowledgeBasedApproachforTacklingMislabels359Fig.
2.
AcomparisonaccuracyondatabyUnpolishing,PolishingandPolishing+KGonthemedicalQ&Adatasetusedfortrainingdatatotesttheaccuracyoftherestfold.
Thenalaccuracyistheaverageaccuracyof10trials.
Hereweusecrossvalidationtoevaluateclassi-cationaccuracy,dierentfromlabelcorrectionphasewherecrossvalidationisusedtopickupcandidatesandconstructclassiersasvoters.
Wechoosecrossvalidationtovalidateaccuracybecauseitcanreducetheriskofoverttingonthetestset.
Figure2showsthecomparisonofthreeapproachonclassicationaccuracyatdierentnoiselevels.
ForUnpolishingapproach,accuracydeclinesalmostlinearlywiththenoiselevelincrease.
Atmostcases,theimprovementofPolishingandPolishing+KGonUnpolishingisquitesignicant,theperformanceofPolishingis10%-30%higherthanUnpolishing,whileourapproachPolishing+KGac-quiresaccuracyusually1%-4%higherthanthepurePolishing.
Wecanseenoisedatacutdownaccuracydramaticallywhennocorrectionisconducted.
Polishingcorrectspartoftheerrorlabelsandprovidesamuchhigheraccuracy.
Further-more,Polishing+KGapproachminestherelationshipsbetweenentityfeaturesandendowsmoreweightstothemoreinformativeones,soitachievesbetterac-curacyscorethanPolishing.
Particularly,atnoiselevelof0%,theimprovementsofPolishingandPolishing+KGarebothnotremarkable,Polishingismerely0.
3%higherthanUnpolishing,andPolish+KGis1.
3%higherthanUnpolishing,webelievePolishing+KGalsohaseectonimprovingclassicationaccuracyevenwhendataisnearlynoise-free.
360M.
Guoetal.
5.
4DataQualityPromotionWecomparetheclassication-independentmetricstotestdataqualitypromo-tionbyPolishingandPolishing+KGapproach.
Whenwearticiallycorruptthedata,wehavemadeamarktoeveryexamplewhatisthereallabelofit.
Afterlabelcorrectionbytwoapproaches,wechecktheprecision,recallandnoisere-ductionratedependingonthesemarks.
Weusenoisereductionrateasthemainmetricondataqualitypromotion,whiletheothertwohelpustounderstandandexplaintherelevantpromotion.
Figure3showsnoisereductionratebytwoapproaches.
ThenoisereductionrateofPolishing+KGisapproximately1%-4%higherthanPolishing.
Itseemsoddthatthenoisereductionisnegativeatnoiselevelof0%,whichmeansthenoisesincreaseafterlabelcorrection.
However,thisphenomenoncanbeexplained.
Atnoiselevelof0%,weassumedatatobenoise-free,whiledatacan'tbecompletelynoise-freeinreal-world.
SoitisreasonablethatPolishingandPolishing+KGhasmodiedsomelabelswhicharequitepossiblyerrorlabels.
Generallyspeaking,itisshownthatPolishinghasenormoussignicanceindataqualitypromotionandPolishing+KGachievesbetterperformanceonthebasisofPolishing.
Figure4showstheprecisionandrecall.
Wedonotconsiderateprecisionandrecallatnoiselevelof0%becauseit'smeaningless.
Atmostnoiselevels,precisionofPolishing+KGislessthanPolishing,howevertherecallofPolishing+KGismuchhigherthanPolishing.
Usuallyprecisionandrecallhaveacontradictoryrelationshipthatprecisiondecreasesalongwhenrecallincreases.
Soit'sreason-ablethatPolishing+KGhasaloweroverallprecision.
Whenthenoiselevelisquitehigher,theprecisionandrecallofPolishing+KGarebothhigherthanFig.
3.
AcomparisonofnoisereductionratebyPolishingandPolishing+KGonthemedicalQ&AdatasetAKnowledgeBasedApproachforTacklingMislabels361Fig.
4.
Acomparisonofprecision,recallbyPolishingandPolishing+KGonthemedicalQ&AdatasetPolishing.
Weassumethisiscausedbythatknowledgediminishestheinterfer-enceofnoises,theeectismoreremarkablewhenthenoiselevelishigher.
5.
5KnowledgeDepthAectionWeconductanexperimentofhowknowledgedepthaectstheresults.
Accordingto(3),weadjusttheentityweightsbycomputingclosenessofanentitytootherentities.
WebelievethebiggerMAXSTEPis,themorepreciseweightswillbegenerated.
Thisthoughtisdrivenbythatwegetmoreinformationaboutsome-thingwhenwerecognizeitmoredeeply.
Figure5showstheaccuratecomparisonofdierentknowledgedepthfrom1to3.
Theaccuracyimproves0-1.
3%whenFig.
5.
Knowledgedepthaectiononaccuracy362M.
Guoetal.
knowledgedepthgrowsfrom1to2atdierentnoiselevels,whiletheaccuracyimprovementisinsignicantwhendepthgrowsfrom2to3.
Whenknowledgedepthgrows,theamountofrelationshipsofoneentitytoothersgrowsrapidlyandmoreweightsareendowedwiththemoreinformativeones.
Theresultsshowdeepknowledgeperceptioncanenhanceclassicationperformance.
6ConclusionInthispaper,wepresentaknowledgegraphbasedapproachcombinedwithpol-ishingtohandlelabelimperfectionproblem.
Thismethodisdistinctfromprevi-ousstatisticalmethodsinthatittriestorecognizethedatainawaysimilartotherealworld.
Experimentalresultsdemonstrateourapproachhasanimpactonboostingclassicationperformanceanddataquality.
Itcaneectivelycorrectmislabeledevenunderthecircumstanceofaquitehighnoiselevelofapproxi-mately60%.
Besidehandlingthenoisedata,theknowledgegraphtechniqueweusedcanbeappliedinfeatureselectioninclassicationaswell.
Ourfutureworkwillbefocusedonamelioratingthegraphbyestablishingmoretypesofentitiesandmoredetailedrelationshipsinit.
Moreresearcheswillbeconductedtorecognizedatanoisesinamorehuman-likeratherthanmachine-likeapproach.
Inaddition,weshallapplyourapproachtoothereldssuchassocialnetworksandbusinessdataanalysis.
Acknowledgement.
ThisworkwassupportedbytheNSFC(No.
61272099,61261160502and61202025),ShanghaiExcellentAcademicLeadersPlan(No.
11XD1402900),theProgramforChangjiangScholarsandInnovativeResearchTeaminUniversityofChina(IRT1158,PCSIRT),theScienticInnovationActofSTCSM(No.
13511504200),SingaporeNRF(CREATEE2S2),andtheEUFP7CLIMBERproject(No.
PIRSES-GA-2012-318939).
References1.
Zhu,X.
,Wu,X.
:Classnoisevs.
attributenoise:Aquantitativestudy.
ArticialIntelligenceReview22(3),177–210(2004)2.
Quinlan,J.
R.
:Inductionofdecisiontrees.
MachineLearning1(1),81–106(1986)3.
Wu,W.
,Li,H.
,Wang,H.
,Zhu,K.
Q.
:Probase:Aprobabilistictaxonomyfortextunderstanding.
In:Proceedingsofthe2012ACMSIGMODInternationalConfer-enceonManagementofData,pp.
481–492.
ACM(2012)4.
Zhang,Y.
:Contextualizingconsumerhealthinformationsearching:ananalysisofquestionsinasocialq&acommunity.
In:Proceedingsofthe1stACMInternationalHealthInformaticsSymposium,pp.
210–219.
ACM(2010)5.
Kunz,H.
,Schaaf,T.
:Generalandspecicformalizationapproachforabalancedscorecard:Anexpertsystemwithapplicationinhealthcare.
ExpertSystemswithApplications38(3),1947–1955(2011)6.
Zeng,X.
,Martinez,T.
R.
:Analgorithmforcorrectingmislabeleddata.
IntelligentDataAnalysis5(6),491–502(2001)AKnowledgeBasedApproachforTacklingMislabels3637.
Wilson,D.
R.
,Martinez,T.
R.
:Instancepruningtechniques.
In:ICML,vol.
97,pp.
403–411(1997)8.
Wilson,D.
R.
,Martinez,T.
R.
:Reductiontechniquesforinstance-basedlearningalgorithms.
MachineLearning38(3),257–286(2000)9.
Wilson,D.
L.
:Asymptoticpropertiesofnearestneighborrulesusingediteddata.
IEEETransactionsonSystems,ManandCybernetics(3),408–421(1972)10.
Aha,D.
W.
,Kibler,D.
F.
:Noise-tolerantinstance-basedlearningalgorithms.
In:IJCAI,pp.
794–799.
Citeseer(1989)11.
Brodley,C.
E.
,Friedl,M.
A.
:Identifyingandeliminatingmislabeledtrainingin-stances.
In:AAAI/IAAI,vol.
1,pp.
799–805.
Citeseer(1996)12.
Brodley,C.
E.
,Friedl,M.
A.
:Identifyingmislabeledtrainingdata.
arXivpreprintarXiv:1106.
0219(2011)13.
Teng,C.
M.
:Evaluatingnoisecorrection.
In:Mizoguchi,R.
,Slaney,J.
K.
(eds.
)PRICAI2000.
LNCS,vol.
1886,pp.
188–198.
Springer,Heidelberg(2000)14.
Teng,C.
M.
:Polishingblemishes:Issuesindatacorrection.
IEEEIntelligentSys-tems19(2),34–39(2004)15.
Teng,C.
M.
:Acomparisonofnoisehandlingtechniques.
In:FLAIRSConference,pp.
269–273(2001)16.
Li,J.
,Zhang,K.
,etal.
:Keywordextractionbasedontf/idfforchinesenewsdocument.
WuhanUniversityJournalofNaturalSciences12(5),917–921(2007)17.
Yang,Y.
,Pedersen,J.
O.
:Acomparativestudyonfeatureselectionintextcatego-rization.
In:ICML,vol.
97,pp.
412–420(1997)18.
Dijkstra,E.
W.
:Anoteontwoproblemsinconnexionwithgraphs.
NumerischeMathematik1(1),269–271(1959)19.
McCallum,A.
,Nigam,K.
,etal.
:Acomparisonofeventmodelsfornaivebayestextclassication.
In:AAAI1998WorkshoponLearningforTextCategorization,vol.
752,pp.
41–48.
Citeseer(1998)
- description120ask.com相关文档
- models120ask.com
- close120ask.com
- easing120ask.com
- 肠道120ask.com
- 120ask.com一个人吃什么药死的快不难受 site:www.120ask.com
- 120ask.comfpsa/tpsa比值为22.35什么意思
819云互联(800元/月),香港BGP E5 2650 16G,日本 E5 2650 16G
819云互联 在本月发布了一个购买香港,日本独立服务器的活动,相对之前的首月活动性价比更高,最多只能享受1个月的活动 续费价格恢复原价 是有些颇高 这次819云互联与机房是合作伙伴 本次拿到机房 活动7天内购买独立服务器后期的长期续费价格 加大力度 确实来说这次的就可以买年付或者更长时间了…本次是5个机房可供选择,独立服务器最低默认是50M带宽,不限制流量,。官网:https://ww...
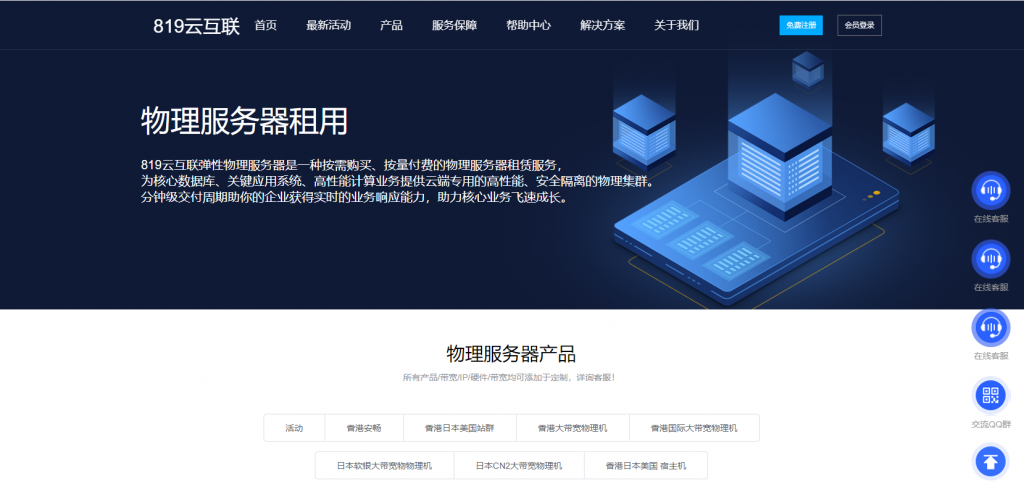
Gcore(gcorelabs)俄罗斯海参崴VPS简单测试
有一段时间没有分享Gcore(gcorelabs)的信息了,这是一家成立于2011年的国外主机商,总部位于卢森堡,主要提供VPS主机和独立服务器租用等,数据中心包括俄罗斯、美国、日本、韩国、新加坡、荷兰、中国(香港)等多个国家和地区的十几个机房,商家针对不同系列的产品分为不同管理系统,比如VPS(Hosting)、Cloud等都是独立的用户中心体系,部落分享的主要是商家的Hosting(Virtu...
美国多IP站群VPS商家选择考虑因素和可选商家推荐
如今我们很多朋友做网站都比较多的采用站群模式,但是用站群模式我们很多人都知道要拆分到不同IP段。比如我们会选择不同的服务商,不同的机房,至少和我们每个服务器的IP地址差异化。于是,我们很多朋友会选择美国多IP站群VPS商家的产品。美国站群VPS主机商和我们普通的云服务器、VPS还是有区别的,比如站群服务器的IP分布情况,配置技术难度,以及我们成本是比普通的高,商家选择要靠谱的。我们在选择美国多IP...

120ask.com为你推荐
-
汇通物流请大家千万不要使用汇通快递!!淘宝门户淘宝社区怎么进?openeuler电脑上显示openser是什么意思?安徽汽车网在安徽那个市的二手车最好?mathplayerjavascript 如何判断document.body.innerHTML是否为空22zizi.com福利彩双色球22号开奖号22zizi.comwww 地址 didi22怎么打不开了,还有好看的吗>comrawtoolsTF卡被写保护了怎么办?seo优化工具SEO优化工具哪个好用点啊?se9999se.comexol.smtown.com