算法ubuntu14.04
ubuntu14.04 时间:2021-04-01 阅读:()
收稿日期:20141113;修回日期:20150104基金项目:国家自然科学基金民航联合基金资助项目(U1233113);国家自然科学青年基金资助项目(61301245,61201414)作者简介:冯兴杰(1969),男,河北邢台人,博士,主要研究方向为数据库、数据仓库、智能信息处理(fxingjie@163.
com);赵杰(1991),男,河北石家庄人,硕士,主要研究方向为云计算、智能信息处理.
基于MapReduce的Hmine算法冯兴杰,赵杰(中国民航大学计算机科学与技术学院,天津300300)摘要:频繁模式挖掘是一种非常有效地从数据中获取知识的方法,但是随着大数据时代的来临,现有算法及其计算环境的运算速度、内外存容量面临严峻挑战.
针对以上问题,紧密结合MapReduce模型提供的高效分布式编程和运行框架,在深入分析Hmine频繁模式挖掘算法的基础上,通过对Hmine算法频繁模式挖掘过程的并行化改进,提出了一种新颖的基于MapReduce模型的Hmine算法(简称MRHmine).
MRHmine算法实现了对Hmine算法在分布式运行环境下的改造,实验表明该算法在面对数据大规模增长的情况下具有良好的性能和扩展性.
关键词:分布式数据挖掘;MapReduce;Hmine;并行化;Hadoop中图分类号:TP301.
6文献标志码:A文章编号:10013695(2016)03075405doi:10.
3969/j.
issn.
10013695.
2016.
03.
026MapReducebasedHminealgorithmFengXingjie,ZhaoJie(CollegeofComputerScience&Technology,CivilAviationUniversityofChina,Tianjin300300,China)Abstract:Frequentpatternminingisaveryeffectiveknowledgeacquisitionmethodfromthedata,butwiththeadventoftheeraofbigdata,theexistingalgorithmanditscomputingenvironmentscomputationspeedandstoragecapacityisfacingseverechallenges.
Fortunately,MapReducemodelprovidesanefficientframeworkfordistributedprogrammingandoperationframework.
BasedondepthanalysisoftheHminealgorithmsandparallelizingHminealgorithms,thispaperproposedanovelMapReducebasedHminealgorithm(itcalltheparallelalgorithmMRHmine).
MRHminealgorithmachievethetransformationofHminealgorithminthedistributedoperationenvironment,experimentalresultsshowthatinthefaceofmassivedatagrowth,MRHminealgorithmhaveagoodperformanceandscalability.
Keywords:distributeddatamining;MapReduce;Hmine;parallelization;Hadoop随着互联网技术的不断进步,特别是大数据时代的来临,如何更加充分地利用这些数据为生产和生活服务成为当前亟待解决的问题.
频繁模式挖掘[1]是数据挖掘和数据分析中重要的研究方向,人们提出了一系列的算法挖掘频繁模式,如Apriori[2]、FPgrowth[3]和Hmine[4].
但是以上算法大多是基于单机的频繁模式挖掘算法,无法直接实现并行化处理,因此这些算法不同程度地受制于计算机硬件性能约束.
相对于需要处理的大数据,现有算法普遍面临传统的计算环境内存过小、运算速度慢、硬盘无法存储数据等一系列问题.
为了解决现有频繁模式挖掘算法面对大数据时出现的问题,需要将算法移植到分布式计算环境.
分布式计算环境是将数据存储、数据分析和计算等建立在网络之上由多个主机构成的集群上的软件计算环境.
分布式计算环境相对于由单机构成的系统,主要区别在于处理问题的规模上,包括数据处理和存储的规模.
分布式计算环境具有资源共享、高透明性、高性价比、高可靠性、高度灵活性的特点,但是也存在分布式计算环境编程较为复杂、节点失效、网络受阻等问题,Google公司提出的MapReduce并行编程模型[5,6]解决了这一问题.
MapReduce模型不仅大大简化了编写分布式程序的难度,而且增强了分布式计算的可靠性.
Apache基金会提供并实现了MapReduce并行编程模型的开源高性能分布式计算环境Hadoop.
为了使传统的数据处理算法满足大数据处理的需求,一个可行的途径是利用MapReduce并行编程模型的优势,对传统算法进行并行化改造以提高算法的伸缩性.
例如文献[7],就是将Apriori算法与MapReduce模型结合;文献[8,9]中将FPgrowth算法与MapReduce模型结合;文献[10,11]则是将eclat算法进行了MapReduce转换.
本文提出了一种新颖的基于MapReduce模型的Hmine算法,基本思路是:首先修改算法流程将算法并行化以充分利用分布式计算环境多节点、高性能的特点;然后按支持度排序分配,在并行化时尽可能地将任务平均分配以达到并行处理的最优效果;最后使用字典转换降低节点间网络通信量以降低处理网络数据时的损耗.
"相关理论与技术""-.
/#01230和4.
155/MapReduce是一种由Google提出的并行编程模型,用于大第33卷第3期2016年3月计算机应用研究ApplicationResearchofComputersVol.
33No.
3Mar.
2016规模数据集的并行运算.
MapReduce则可以帮助用户编写处理海量数据集的并行计算程序,使开发人员把精力集中在编写业务逻辑相关的代码上,无须考虑程序并行运行时底层细节,大大提高了开发效率.
MapReduce将并行编程的复杂过程简化为两个简单的Map和Reduce阶段.
Map阶段解析杂乱无章、互不相关的数据,从每个数据中提取出key和value,即数据的特征;经过MapReduce的Shuffle过程处理,传递给Reduce阶段的就是已经归纳好的数据,在归纳好的数据的基础上就可以进一步处理以得到期望的结果,如图1所示.
MapReduce简单、易于实现且扩展性强.
使用MapReduce可以用多种语言轻松地编写出可以运行在分布式计算环境上的程序,适宜于处理大量的数据集.
同时,MapReduce具有较强的容错性,它将对数据的大规模处理分发给不同的节点并实时监控节点的运行情况.
如果一个或多个节点出现错误,该节点所执行的任务将自动重新分配给其他节点.
Hadoop[12]是由Apache基金会于2005年秋天作为Lucene的子项目Nutch的一部分正式引入的分布式系统开源架构.
Hadoop使用户可以在不了解分布式存储和分布式计算的底层细节情况下,开发出高性能分布式程序.
Hadoop具有高可靠性、高扩展性、高效性、高容错性和低成本的特点.
新一代Hadoop最核心的设计是:分布式文件系统HDFS[13]和资源管理系统YARN.
分布式文件系统HDFS提供了Hadoop运算过程中的数据存储、数据备份、数据错误校验等功能.
HDFS具有很高的数据吞吐量,用来存储大规模数据集,设计目标是可以将系统部署在廉价的通用计算机上,并可以为程序提供高速度的数据访问.
资源管理系统YARN是一个通用的资源管理模块,可以对各种应用程序进行资源管理和调度.
YARN不仅支持MapReduce计算框架,还可以支持流式计算框架、图计算框架、内存迭代计算框架等,极大地扩展了Hadoop的使用场景,提高了Hadoop集群的利用效率.
传统的频繁模式挖掘算法传统的频繁模式挖掘算法主要分为两类:a)使用候选产生发现频繁项集,如Apriori.
Apriori使用一种称做逐层搜索的迭代方法,k项集用于探索(k+1)项集[1].
该算法的候选产生—检查方法显著压缩了候选项集的大小,但是当频繁模式非常多或者很长时,该算法需要生成大量候选集并频繁扫描数据.
b)频繁模式增长方法,如FPgrowth.
FPgrowth将挖掘长频繁模式的问题转换为递归地搜索较短模式,然后连接后缀[1].
该算法使用最不频繁的项作为后缀,提供了较好的选择性,使用该算法大大降低了搜索开销.
但是当数据量非常大时,构造基于内存的FP树是非常困难的.
传统频繁模式挖掘算法主要存在两个问题:a)算法需要的内存大小是不可预测的,并且当数据集规模增大时,需要的内存也会随之剧增;b)在很多情况下算法效率是非常低或无法处理的,如密集型数据集、海量数据集.
Hmine算法一定程度上解决了上面提到的问题.
Hmine是一种基于内存、高效的频繁模式挖掘算法,使用新的数据结构HStruct,可以更快地遍历数据.
理论上,Hmine有多项式的空间复杂度,要比使用候选产生发现频繁项集和频繁模式增长方法更加节约空间.
Hmine通过对数据进行分区,每次只挖掘一个分区,最后将结果整合,极大地节约了内存,并能处理更大规模数据集.
实验证明Hmine算法有极好的可扩展性,并且在任何情况下综合性能都优于Apriori和FPgrowth算法.
Hmine算法流程如图2所示.
Hmine是一种基于内存的算法,具有多项式的空间复杂度[4].
在单机环境下运行时,Hmine算法随着数据规模的增大会出现所用数据结构HStruct超出内存的情况,导致算法无法正常运行.
设数据集大小为S,数据集中一次频繁项的个数为L.
Hmine算法根据一次频繁项对数据分区,每次只挖掘一个分区,因此Hmine算法所需内存至少为S*1L.
由公式可知,随着·557·第3期冯兴杰,等:基于MapReduce的Hmine算法数据集的增长,Hmine所需内存也随着呈线性增长.
'基于-.
/#01230的46780算法为了充分利用分布式计算环境的优势,需要对Hmine算法进行改进.
首先将串行Hmine算法并行化;其次平衡数据的分配;最后降低集群节点间通信的损耗.
下面通过一个实例说明基于MapReduce实现的Hmine算法的具体步骤.
假设表1为需要处理的事务集,最小支持度阈值设为2.
表1原始事务集事务ID数据100c,d,e,f,g,i200a,c,d,e,m300a,b,d,e,g,k400a,c,d,ha)使用MapReduce对事务集进行统计得出一次频繁项,在Reduce阶段滤除小于最小支持度阈值的值,由此可得结果{(a,3),(c,3),(d,4),(e,3),(g,2)},(a,3)的意思是a的支持度为3,如表2所示.
表2一次频繁项统计原始数据Map阶段Reduce阶段c,d,e,f,g,i(c,1),(d,1),(e,1),(f,1),(g,1),(i,1)a,c,d,e,m(a,1),(c,1),(d,1),(e,1),(m,1)a,b,d,e,g,k(a,1),(b,1),(d,1),(e,1),(g,1),(k,1)a,c,d,h(a,1),(c,1),(d,1),(h,1)(a,3),(c,3),(d,4),(e,3),(g,2)b)根据步骤a)中得到的一次频繁项集按照支持度从小到大的顺序排序生成字典,通过字典将原始事务集中数据转换为数字,并根据数字去重、排序,如图3所示.
使用字典主要有两个好处:(a)过滤掉非一次频繁项、将数据转换为数字并去重可以减小事务集,显著降低集群节点间网络通信的流量,实验证明对密集型数据集去重和对稀疏型数据集过滤有良好的效果,可以大幅降低数据量;(b)可以将事务更好地分配,在步骤c)中具体描述.
c)在传统Hmine算法中,首先会根据事务的首项数据对事务进行分区,在处理完一个分区的事务集后需要将该分区的事务集重新进行划分,因此每条事务都会经过多次分配.
以事务1、3、4、5为例,在第一次分配时该条事务会按照首项数据1分配给1队列,当1队列中的事务集执行完成之后该条事务就会按照第二项数据3重新分配给3队列,因此该条事务的分配过程如图4所示.
由图4可知,按照一次频繁项集生成的队列划分,事务1、3、4、5将分配三次.
基于单机的Hmine算法由于受到硬件性能的限制,一次处理一个队列的事务集可以大幅度降低对内存的要求.
基于集群的Hadoop分布式计算环境则不存在单机性能限制,可以使用Map/Reduce同时将事务分配、处理,如图5所示.
新方法中每个队列都会一次性得到所需的事务集,使用新方法会比传统方法多占用空间.
如果使用传统方法分配事务,队列占用空间为n,新方法中队列占用空间则为n(n+1)2.
而在新方法中,事务集一次性分配后将不再使用,可以删除以节约空间.
Hadoop将处理的中间结果存储在分布式文件系统HDFS中,可以利用HDFS大容量的优势,以空间换时间.
新的分配方法主要有两点优势:(a)可以极大地简化算法的流程,不必多次重复分配事务,充分利用集群优势,利用空间换时间;(b)当事务为一次性分配时,各个队列事务集一次就已分配好,队列间变得互相独立,不必等上次队列执行完成重新分配事务集后才能开始执行,可以同时对所有队列进行处理,这样串行算法变得可以并行运算,同时每个队列只会获得该队列所需的事务集,空间利用率高.
步骤b)中按支持度从小到大排序生成字典在并行运算时一项优势就显现出来,即可以把事务更好地分配给各个队列.
由于事务集在使用字典清洗后每条事务中的数据会根据数字从小到大进行排序,所以数字越小位置越靠前,以该数字为队列号的队列得到的事务就越长,如图4、5所示,而事务越长潜在需要执行的次数就越多.
为了平衡各个队列的任务量,需要给队列号小的队列更少个数的事务以抵消长事务带来的影响.
按支持度从小到大排序生成字典,支持度越小的数据经过字典转换得到的数字越小,数据排序后位置越靠前.
这样队列号小的队列得到的事务个数少、事务长;队列号大的队列得到的事务个数多、事务短.
如图6~9所示,按支持度从小到大排序生成字典,可以使分配给各个队列的事务集更加平衡.
如图8所示,在分配完成后,事务集1中的数据将不再使用,可以删除事务集1以减少使用的硬盘空间.
·657·计算机应用研究第33卷d)统计步骤c)分配后各个队列中的事务,滤除小于最小支持度阈值的值,再次执行步骤c)对事务分配、统计,直至队列中所有事务的长度为1为止.
队列1的处理过程如图10所示.
由图10可知,队列1中有两条事务,分别为3、4、5和2、4、5,统计可得{(2,1),(3,1),(4,2),(5,2)}.
由此可知原始事务集中1、2的支持度为1,1、3的支持度为1,1、4的支持度为2,1、5的支持度为2.
统计队列1、4可知,原始事务集中1、4、5的支持度为2.
算法整体流程如图11所示.
*实验与分析为了验证MRHmine算法的效率和扩展性,实验分别从计算节点数量和数据规模两方面进行测试.
*"实验环境与数据实验中分布式计算环境由九台台式电脑组成,其中主节点配置为i73770处理器,4GB内存,1TB硬盘.
计算节点配置为奔腾e2140处理器,1GB内存,250GB硬盘.
电脑间使用百兆交换机连接.
电脑使用32位Ubuntu14.
04操作系统,Hadoop版本为2.
4.
0.
实验中分别使用10GB、20GB、30GB数据运行在4、6、8个运算节点上,在支持度为5%的情况下运行.
为了保证实验的客观性,实验中使用公共数据connect4.
connect4数据集是一种密集型数据集,原数据集包含67557条事务,每条事务有43项数据.
通过随机选取复制原数据集中的数据得到实验所用的数据集.
*'实验结果与分析为了验证算法的正确性,在connect4数据集上与基于内存的Hmine算法的处理结果进行了对比,实验表明两种算法得到的结果一致.
为了验证算法性能,将算法与基于MapReduce的Apriori算法(简称MRApriori)作比较.
为了保证实验结果的正确性,图中的值为算法运行10次的平均值.
第一组实验是10GB数据在4、6、8个运算节点上,在5%的支持度下的时间使用情况.
实验结果如图12所示.
第二组实验是20GB数据在4、6、8个运算节点上,在5%的支持度下的时间使用情况.
实验结果如图13所示.
第三组实验是30GB数据在4、6、8个运算节点上,在5%的支持度下的时间使用情况.
实验结果如图14所示.
算法运行过程中需要存储一些数据,包括字典、每个队列的数据、每个队列的统计结果等.
期间,硬盘空间使用量随着中间结果的变化而不断变化,原始数据在一次性分配进入队列后将删除,算法最后仅存储字典和每个队列的统计结果.
三组实验算法运行中,存储数据所需硬盘空间的最大量如图15所示.
MRHmine算法会将数据集多次分配,与MRApriori算法相比过程更为复杂.
从实验结果可以看出,当数据集较小时,分配数据的任务对性能的影响较为严重.
随着数据集的增大,计算节点的增多,MRHmine算法能够并行处理,更充分利用集群资源的优势将显现出来,处理数据的能力呈类线性增长,具有较高的扩展能力.
与MRApriori算法相比,MRHmine算·757·第3期冯兴杰,等:基于MapReduce的Hmine算法法运行过程中存储中间值所需的空间更大,最大需要占用约为原数据1/5大小的硬盘存储空间.
该算法运行在分布式计算环境中可以通过简单地添加节点来提升处理能力,因此十分适用于处理大规模数据集.
+结束语在大数据时代,传统Hmine算法已无法处理所面对的海量数据.
本文提出了一种基于MapReduce的Hmine算法,通过字典过滤、Hmine算法并行化、任务优化分配等技术,使得Hmine算法可以在分布式计算环境中高效运行.
MRHmine算法虽然较好地解决了海量数据情况下关联规则挖掘的问题,但是也存在中间数据占用较多硬盘空间的问题,加强中间数据管理是下一步的研究内容.
实验表明,MRHmine算法面对大数据集时具有良好的性能和扩展性.
参考文献:[1]HanJiawei,KamberM.
数据挖掘概念与技术[M].
范明,孟小峰,译.
北京:机械工业出版社,2011:1160.
[2]AgrawalR,ImielińskiT,SwamiA.
Miningassociationrulesbetweensetsofitemsinlargedatabases[C]//ProcofACMSIGMODInternationalConferenceonManagementofData.
1993:207216.
[3]HanJiawei,PeiJian,YinYiwen.
Miningfrequentpatternswithoutcandidategeneration[C]//ProcofACMSIGMODInternationalConferenceonManagementofData.
NewYork:ACMPress,2000:112.
[4]HanJiawei,PeiJian,LuHongjun,etal.
HMine:fastandspacepreervingfrequentpatternmininginlargedatabases[J].
IIETransactions,2007,39(6):593605.
[5]DeanJ,GhemawatS.
MapReduce:simplifieddataprocessingonlargeclusters[J].
CommunicationsoftheACM,2008,51(1):107113.
[6]DeanJ,GhemawatS.
MapReduce:aflexibledataprocessingtool[J].
CommunicationsoftheACM,2010,53(1):7277.
[7]LiLingjuan,ZhangMin.
Thestrategyofminingassociationrulebasedoncloudcomputing[C]//ProcofIEEEInternationalConferenceonBusinessComputingandGlobalInformatization.
2011:475478.
[8]LiHaoyuan,WangYi,ZhangDong,etal.
PFP:parallelFPGrowthforqueryrecommendation[C]//ProcofACMConferenceonRecommenderSystems.
2008:107114.
[9]ZhouLe,ZhongZhiyong,ChangJin,etal.
BalancedparallelFPgrowthwithMapReduce[C]//ProcofIEEEYouthConferenceonInformationComputingandTelecommunications.
2010:243246.
[10]MoensS,AksehirliE,GoethalsB.
FrequentItemsetminingforbigdata[C]//ProcofIEEEInternationalConferenceonBigData.
2013:111118.
[11]ZhengXiaofeng,WangShu.
StudyonthemethodofroadtransportmanagementinformationdataminingbasedonpruningeclatalgorithmandMapReduce[J].
ProcediaSocialandBehavioralSciences,2014,138:757766.
[12]ApacheHadoop[EB/OL].
(20140815).
http://hadoop.
apache.
org/.
[13]BorthakurD.
Thehadoopdistributedfilesystem:architectureanddesign[J].
HadoopProjectWebsite,2007,11:21.
(上接第753页)[3]ChenCL,GuoYide.
Mobilerobotlocalizationbydeadreckoning[C]//ProcofIEEEInternationalSymposiumonNextGenerationElectronics.
2013:565568.
[4]王殿君.
双目视觉在移动机器人定位中的应用[J].
中国机械工程,2013,24(9):11551158.
[5]孙风池,黄亚楼,康叶伟.
基于视觉的移动机器人同时定位与建图研究进展[J].
控制理论与应用,2010,27(4):488494.
[6]何琼,何永义,冯肖维.
基于激光传感器的多移动机器人位姿测量系统[J].
机电一体化,2011(2):4751.
[7]KimSJ,KimBK.
Dynamicultrasonichybridlocalizationsystemforindoormobilerobots[J].
IEEETransonIndustrialElectronics,2013,60(10):45624573.
[8]周帆,江维,李树全,等.
基于粒子滤波的移动物体定位和追踪算法[J].
软件学报,2013,24(9):21962213.
[9]宋宇,孙富春,李庆玲.
移动机器人的改进无迹粒子滤波蒙特卡罗定位算法[J].
自动化学报,2010,36(6):851857.
[10]KimTG,ChoiHT,KoNY.
Localizationofarobotusingparticlefilterwithrangeandbearinginformation[C]//Procofthe10thInternationalConferenceonUbiquitousRobotsandAmbientIntelligence.
2013:368370.
[11]MyungH,LeeHK,ChoiK,etal.
MobilerobotlocalizationwithgyroscopeandconstrainedKalmanfilter[J].
InternationalJournalofControl,AutomationandSystems,2010,8(3):667676.
[12]曹春萍,罗玲莉.
基于卡尔曼滤波算法的室内无线定位系统[J].
计算机系统应用,2011,20(11):7679.
[13]王晓娟,王宣银.
基于模糊卡尔曼滤波的移动机器人定位研究[J].
计算机工程与应用,2011,47(2):204206.
[14]谭志,张卉.
无线传感器网络RSSI定位算法的研究与改进[J].
北京邮电大学学报,2013,36(3):8892.
[15]ChenJing,LiGengmin,ZhangXuejun,etal.
AnefficientalgorithmforindoorlocationbasedonRFID[C]//ProcofInternationalConferenceonWirelessCommunicationsandSignalProcessing.
2011:14.
[16]LongHua,LuJ,XuQiang,etal.
AnewRSSIbasedcentroidlocalizationalgorithmbyuseofvirtualreferencetags[C]//Procofthe3rdInternationalConferenceonAdvancedCommunicationsandComputation.
2013:122128.
[17]王殿君,兰云峰,任福君,等.
基于有源RFID的室内移动机器人定位系统[J].
清华大学学报:自然科学版,2010,50(5):673676.
[18]胡斐,赵治国.
基于MATLAB的非线性方程组遗传解法[J].
计算机时代,2010(3):4445.
[19]LimHS,ChoiBS,LeeJM.
AnefficientlocalizationalgorithmformobilerobotsbasedonRFIDsystem[C]//ProcofInternationalJointConferenceonSICEICASE.
2006:59455950.
[20]谈宇奇,王雪,刘长.
物联网室内运动目标协作信息融合跟踪方法[J].
仪器仪表学报,2013,34(2):352358.
·857·计算机应用研究第33卷
com);赵杰(1991),男,河北石家庄人,硕士,主要研究方向为云计算、智能信息处理.
基于MapReduce的Hmine算法冯兴杰,赵杰(中国民航大学计算机科学与技术学院,天津300300)摘要:频繁模式挖掘是一种非常有效地从数据中获取知识的方法,但是随着大数据时代的来临,现有算法及其计算环境的运算速度、内外存容量面临严峻挑战.
针对以上问题,紧密结合MapReduce模型提供的高效分布式编程和运行框架,在深入分析Hmine频繁模式挖掘算法的基础上,通过对Hmine算法频繁模式挖掘过程的并行化改进,提出了一种新颖的基于MapReduce模型的Hmine算法(简称MRHmine).
MRHmine算法实现了对Hmine算法在分布式运行环境下的改造,实验表明该算法在面对数据大规模增长的情况下具有良好的性能和扩展性.
关键词:分布式数据挖掘;MapReduce;Hmine;并行化;Hadoop中图分类号:TP301.
6文献标志码:A文章编号:10013695(2016)03075405doi:10.
3969/j.
issn.
10013695.
2016.
03.
026MapReducebasedHminealgorithmFengXingjie,ZhaoJie(CollegeofComputerScience&Technology,CivilAviationUniversityofChina,Tianjin300300,China)Abstract:Frequentpatternminingisaveryeffectiveknowledgeacquisitionmethodfromthedata,butwiththeadventoftheeraofbigdata,theexistingalgorithmanditscomputingenvironmentscomputationspeedandstoragecapacityisfacingseverechallenges.
Fortunately,MapReducemodelprovidesanefficientframeworkfordistributedprogrammingandoperationframework.
BasedondepthanalysisoftheHminealgorithmsandparallelizingHminealgorithms,thispaperproposedanovelMapReducebasedHminealgorithm(itcalltheparallelalgorithmMRHmine).
MRHminealgorithmachievethetransformationofHminealgorithminthedistributedoperationenvironment,experimentalresultsshowthatinthefaceofmassivedatagrowth,MRHminealgorithmhaveagoodperformanceandscalability.
Keywords:distributeddatamining;MapReduce;Hmine;parallelization;Hadoop随着互联网技术的不断进步,特别是大数据时代的来临,如何更加充分地利用这些数据为生产和生活服务成为当前亟待解决的问题.
频繁模式挖掘[1]是数据挖掘和数据分析中重要的研究方向,人们提出了一系列的算法挖掘频繁模式,如Apriori[2]、FPgrowth[3]和Hmine[4].
但是以上算法大多是基于单机的频繁模式挖掘算法,无法直接实现并行化处理,因此这些算法不同程度地受制于计算机硬件性能约束.
相对于需要处理的大数据,现有算法普遍面临传统的计算环境内存过小、运算速度慢、硬盘无法存储数据等一系列问题.
为了解决现有频繁模式挖掘算法面对大数据时出现的问题,需要将算法移植到分布式计算环境.
分布式计算环境是将数据存储、数据分析和计算等建立在网络之上由多个主机构成的集群上的软件计算环境.
分布式计算环境相对于由单机构成的系统,主要区别在于处理问题的规模上,包括数据处理和存储的规模.
分布式计算环境具有资源共享、高透明性、高性价比、高可靠性、高度灵活性的特点,但是也存在分布式计算环境编程较为复杂、节点失效、网络受阻等问题,Google公司提出的MapReduce并行编程模型[5,6]解决了这一问题.
MapReduce模型不仅大大简化了编写分布式程序的难度,而且增强了分布式计算的可靠性.
Apache基金会提供并实现了MapReduce并行编程模型的开源高性能分布式计算环境Hadoop.
为了使传统的数据处理算法满足大数据处理的需求,一个可行的途径是利用MapReduce并行编程模型的优势,对传统算法进行并行化改造以提高算法的伸缩性.
例如文献[7],就是将Apriori算法与MapReduce模型结合;文献[8,9]中将FPgrowth算法与MapReduce模型结合;文献[10,11]则是将eclat算法进行了MapReduce转换.
本文提出了一种新颖的基于MapReduce模型的Hmine算法,基本思路是:首先修改算法流程将算法并行化以充分利用分布式计算环境多节点、高性能的特点;然后按支持度排序分配,在并行化时尽可能地将任务平均分配以达到并行处理的最优效果;最后使用字典转换降低节点间网络通信量以降低处理网络数据时的损耗.
"相关理论与技术""-.
/#01230和4.
155/MapReduce是一种由Google提出的并行编程模型,用于大第33卷第3期2016年3月计算机应用研究ApplicationResearchofComputersVol.
33No.
3Mar.
2016规模数据集的并行运算.
MapReduce则可以帮助用户编写处理海量数据集的并行计算程序,使开发人员把精力集中在编写业务逻辑相关的代码上,无须考虑程序并行运行时底层细节,大大提高了开发效率.
MapReduce将并行编程的复杂过程简化为两个简单的Map和Reduce阶段.
Map阶段解析杂乱无章、互不相关的数据,从每个数据中提取出key和value,即数据的特征;经过MapReduce的Shuffle过程处理,传递给Reduce阶段的就是已经归纳好的数据,在归纳好的数据的基础上就可以进一步处理以得到期望的结果,如图1所示.
MapReduce简单、易于实现且扩展性强.
使用MapReduce可以用多种语言轻松地编写出可以运行在分布式计算环境上的程序,适宜于处理大量的数据集.
同时,MapReduce具有较强的容错性,它将对数据的大规模处理分发给不同的节点并实时监控节点的运行情况.
如果一个或多个节点出现错误,该节点所执行的任务将自动重新分配给其他节点.
Hadoop[12]是由Apache基金会于2005年秋天作为Lucene的子项目Nutch的一部分正式引入的分布式系统开源架构.
Hadoop使用户可以在不了解分布式存储和分布式计算的底层细节情况下,开发出高性能分布式程序.
Hadoop具有高可靠性、高扩展性、高效性、高容错性和低成本的特点.
新一代Hadoop最核心的设计是:分布式文件系统HDFS[13]和资源管理系统YARN.
分布式文件系统HDFS提供了Hadoop运算过程中的数据存储、数据备份、数据错误校验等功能.
HDFS具有很高的数据吞吐量,用来存储大规模数据集,设计目标是可以将系统部署在廉价的通用计算机上,并可以为程序提供高速度的数据访问.
资源管理系统YARN是一个通用的资源管理模块,可以对各种应用程序进行资源管理和调度.
YARN不仅支持MapReduce计算框架,还可以支持流式计算框架、图计算框架、内存迭代计算框架等,极大地扩展了Hadoop的使用场景,提高了Hadoop集群的利用效率.
传统的频繁模式挖掘算法传统的频繁模式挖掘算法主要分为两类:a)使用候选产生发现频繁项集,如Apriori.
Apriori使用一种称做逐层搜索的迭代方法,k项集用于探索(k+1)项集[1].
该算法的候选产生—检查方法显著压缩了候选项集的大小,但是当频繁模式非常多或者很长时,该算法需要生成大量候选集并频繁扫描数据.
b)频繁模式增长方法,如FPgrowth.
FPgrowth将挖掘长频繁模式的问题转换为递归地搜索较短模式,然后连接后缀[1].
该算法使用最不频繁的项作为后缀,提供了较好的选择性,使用该算法大大降低了搜索开销.
但是当数据量非常大时,构造基于内存的FP树是非常困难的.
传统频繁模式挖掘算法主要存在两个问题:a)算法需要的内存大小是不可预测的,并且当数据集规模增大时,需要的内存也会随之剧增;b)在很多情况下算法效率是非常低或无法处理的,如密集型数据集、海量数据集.
Hmine算法一定程度上解决了上面提到的问题.
Hmine是一种基于内存、高效的频繁模式挖掘算法,使用新的数据结构HStruct,可以更快地遍历数据.
理论上,Hmine有多项式的空间复杂度,要比使用候选产生发现频繁项集和频繁模式增长方法更加节约空间.
Hmine通过对数据进行分区,每次只挖掘一个分区,最后将结果整合,极大地节约了内存,并能处理更大规模数据集.
实验证明Hmine算法有极好的可扩展性,并且在任何情况下综合性能都优于Apriori和FPgrowth算法.
Hmine算法流程如图2所示.
Hmine是一种基于内存的算法,具有多项式的空间复杂度[4].
在单机环境下运行时,Hmine算法随着数据规模的增大会出现所用数据结构HStruct超出内存的情况,导致算法无法正常运行.
设数据集大小为S,数据集中一次频繁项的个数为L.
Hmine算法根据一次频繁项对数据分区,每次只挖掘一个分区,因此Hmine算法所需内存至少为S*1L.
由公式可知,随着·557·第3期冯兴杰,等:基于MapReduce的Hmine算法数据集的增长,Hmine所需内存也随着呈线性增长.
'基于-.
/#01230的46780算法为了充分利用分布式计算环境的优势,需要对Hmine算法进行改进.
首先将串行Hmine算法并行化;其次平衡数据的分配;最后降低集群节点间通信的损耗.
下面通过一个实例说明基于MapReduce实现的Hmine算法的具体步骤.
假设表1为需要处理的事务集,最小支持度阈值设为2.
表1原始事务集事务ID数据100c,d,e,f,g,i200a,c,d,e,m300a,b,d,e,g,k400a,c,d,ha)使用MapReduce对事务集进行统计得出一次频繁项,在Reduce阶段滤除小于最小支持度阈值的值,由此可得结果{(a,3),(c,3),(d,4),(e,3),(g,2)},(a,3)的意思是a的支持度为3,如表2所示.
表2一次频繁项统计原始数据Map阶段Reduce阶段c,d,e,f,g,i(c,1),(d,1),(e,1),(f,1),(g,1),(i,1)a,c,d,e,m(a,1),(c,1),(d,1),(e,1),(m,1)a,b,d,e,g,k(a,1),(b,1),(d,1),(e,1),(g,1),(k,1)a,c,d,h(a,1),(c,1),(d,1),(h,1)(a,3),(c,3),(d,4),(e,3),(g,2)b)根据步骤a)中得到的一次频繁项集按照支持度从小到大的顺序排序生成字典,通过字典将原始事务集中数据转换为数字,并根据数字去重、排序,如图3所示.
使用字典主要有两个好处:(a)过滤掉非一次频繁项、将数据转换为数字并去重可以减小事务集,显著降低集群节点间网络通信的流量,实验证明对密集型数据集去重和对稀疏型数据集过滤有良好的效果,可以大幅降低数据量;(b)可以将事务更好地分配,在步骤c)中具体描述.
c)在传统Hmine算法中,首先会根据事务的首项数据对事务进行分区,在处理完一个分区的事务集后需要将该分区的事务集重新进行划分,因此每条事务都会经过多次分配.
以事务1、3、4、5为例,在第一次分配时该条事务会按照首项数据1分配给1队列,当1队列中的事务集执行完成之后该条事务就会按照第二项数据3重新分配给3队列,因此该条事务的分配过程如图4所示.
由图4可知,按照一次频繁项集生成的队列划分,事务1、3、4、5将分配三次.
基于单机的Hmine算法由于受到硬件性能的限制,一次处理一个队列的事务集可以大幅度降低对内存的要求.
基于集群的Hadoop分布式计算环境则不存在单机性能限制,可以使用Map/Reduce同时将事务分配、处理,如图5所示.
新方法中每个队列都会一次性得到所需的事务集,使用新方法会比传统方法多占用空间.
如果使用传统方法分配事务,队列占用空间为n,新方法中队列占用空间则为n(n+1)2.
而在新方法中,事务集一次性分配后将不再使用,可以删除以节约空间.
Hadoop将处理的中间结果存储在分布式文件系统HDFS中,可以利用HDFS大容量的优势,以空间换时间.
新的分配方法主要有两点优势:(a)可以极大地简化算法的流程,不必多次重复分配事务,充分利用集群优势,利用空间换时间;(b)当事务为一次性分配时,各个队列事务集一次就已分配好,队列间变得互相独立,不必等上次队列执行完成重新分配事务集后才能开始执行,可以同时对所有队列进行处理,这样串行算法变得可以并行运算,同时每个队列只会获得该队列所需的事务集,空间利用率高.
步骤b)中按支持度从小到大排序生成字典在并行运算时一项优势就显现出来,即可以把事务更好地分配给各个队列.
由于事务集在使用字典清洗后每条事务中的数据会根据数字从小到大进行排序,所以数字越小位置越靠前,以该数字为队列号的队列得到的事务就越长,如图4、5所示,而事务越长潜在需要执行的次数就越多.
为了平衡各个队列的任务量,需要给队列号小的队列更少个数的事务以抵消长事务带来的影响.
按支持度从小到大排序生成字典,支持度越小的数据经过字典转换得到的数字越小,数据排序后位置越靠前.
这样队列号小的队列得到的事务个数少、事务长;队列号大的队列得到的事务个数多、事务短.
如图6~9所示,按支持度从小到大排序生成字典,可以使分配给各个队列的事务集更加平衡.
如图8所示,在分配完成后,事务集1中的数据将不再使用,可以删除事务集1以减少使用的硬盘空间.
·657·计算机应用研究第33卷d)统计步骤c)分配后各个队列中的事务,滤除小于最小支持度阈值的值,再次执行步骤c)对事务分配、统计,直至队列中所有事务的长度为1为止.
队列1的处理过程如图10所示.
由图10可知,队列1中有两条事务,分别为3、4、5和2、4、5,统计可得{(2,1),(3,1),(4,2),(5,2)}.
由此可知原始事务集中1、2的支持度为1,1、3的支持度为1,1、4的支持度为2,1、5的支持度为2.
统计队列1、4可知,原始事务集中1、4、5的支持度为2.
算法整体流程如图11所示.
*实验与分析为了验证MRHmine算法的效率和扩展性,实验分别从计算节点数量和数据规模两方面进行测试.
*"实验环境与数据实验中分布式计算环境由九台台式电脑组成,其中主节点配置为i73770处理器,4GB内存,1TB硬盘.
计算节点配置为奔腾e2140处理器,1GB内存,250GB硬盘.
电脑间使用百兆交换机连接.
电脑使用32位Ubuntu14.
04操作系统,Hadoop版本为2.
4.
0.
实验中分别使用10GB、20GB、30GB数据运行在4、6、8个运算节点上,在支持度为5%的情况下运行.
为了保证实验的客观性,实验中使用公共数据connect4.
connect4数据集是一种密集型数据集,原数据集包含67557条事务,每条事务有43项数据.
通过随机选取复制原数据集中的数据得到实验所用的数据集.
*'实验结果与分析为了验证算法的正确性,在connect4数据集上与基于内存的Hmine算法的处理结果进行了对比,实验表明两种算法得到的结果一致.
为了验证算法性能,将算法与基于MapReduce的Apriori算法(简称MRApriori)作比较.
为了保证实验结果的正确性,图中的值为算法运行10次的平均值.
第一组实验是10GB数据在4、6、8个运算节点上,在5%的支持度下的时间使用情况.
实验结果如图12所示.
第二组实验是20GB数据在4、6、8个运算节点上,在5%的支持度下的时间使用情况.
实验结果如图13所示.
第三组实验是30GB数据在4、6、8个运算节点上,在5%的支持度下的时间使用情况.
实验结果如图14所示.
算法运行过程中需要存储一些数据,包括字典、每个队列的数据、每个队列的统计结果等.
期间,硬盘空间使用量随着中间结果的变化而不断变化,原始数据在一次性分配进入队列后将删除,算法最后仅存储字典和每个队列的统计结果.
三组实验算法运行中,存储数据所需硬盘空间的最大量如图15所示.
MRHmine算法会将数据集多次分配,与MRApriori算法相比过程更为复杂.
从实验结果可以看出,当数据集较小时,分配数据的任务对性能的影响较为严重.
随着数据集的增大,计算节点的增多,MRHmine算法能够并行处理,更充分利用集群资源的优势将显现出来,处理数据的能力呈类线性增长,具有较高的扩展能力.
与MRApriori算法相比,MRHmine算·757·第3期冯兴杰,等:基于MapReduce的Hmine算法法运行过程中存储中间值所需的空间更大,最大需要占用约为原数据1/5大小的硬盘存储空间.
该算法运行在分布式计算环境中可以通过简单地添加节点来提升处理能力,因此十分适用于处理大规模数据集.
+结束语在大数据时代,传统Hmine算法已无法处理所面对的海量数据.
本文提出了一种基于MapReduce的Hmine算法,通过字典过滤、Hmine算法并行化、任务优化分配等技术,使得Hmine算法可以在分布式计算环境中高效运行.
MRHmine算法虽然较好地解决了海量数据情况下关联规则挖掘的问题,但是也存在中间数据占用较多硬盘空间的问题,加强中间数据管理是下一步的研究内容.
实验表明,MRHmine算法面对大数据集时具有良好的性能和扩展性.
参考文献:[1]HanJiawei,KamberM.
数据挖掘概念与技术[M].
范明,孟小峰,译.
北京:机械工业出版社,2011:1160.
[2]AgrawalR,ImielińskiT,SwamiA.
Miningassociationrulesbetweensetsofitemsinlargedatabases[C]//ProcofACMSIGMODInternationalConferenceonManagementofData.
1993:207216.
[3]HanJiawei,PeiJian,YinYiwen.
Miningfrequentpatternswithoutcandidategeneration[C]//ProcofACMSIGMODInternationalConferenceonManagementofData.
NewYork:ACMPress,2000:112.
[4]HanJiawei,PeiJian,LuHongjun,etal.
HMine:fastandspacepreervingfrequentpatternmininginlargedatabases[J].
IIETransactions,2007,39(6):593605.
[5]DeanJ,GhemawatS.
MapReduce:simplifieddataprocessingonlargeclusters[J].
CommunicationsoftheACM,2008,51(1):107113.
[6]DeanJ,GhemawatS.
MapReduce:aflexibledataprocessingtool[J].
CommunicationsoftheACM,2010,53(1):7277.
[7]LiLingjuan,ZhangMin.
Thestrategyofminingassociationrulebasedoncloudcomputing[C]//ProcofIEEEInternationalConferenceonBusinessComputingandGlobalInformatization.
2011:475478.
[8]LiHaoyuan,WangYi,ZhangDong,etal.
PFP:parallelFPGrowthforqueryrecommendation[C]//ProcofACMConferenceonRecommenderSystems.
2008:107114.
[9]ZhouLe,ZhongZhiyong,ChangJin,etal.
BalancedparallelFPgrowthwithMapReduce[C]//ProcofIEEEYouthConferenceonInformationComputingandTelecommunications.
2010:243246.
[10]MoensS,AksehirliE,GoethalsB.
FrequentItemsetminingforbigdata[C]//ProcofIEEEInternationalConferenceonBigData.
2013:111118.
[11]ZhengXiaofeng,WangShu.
StudyonthemethodofroadtransportmanagementinformationdataminingbasedonpruningeclatalgorithmandMapReduce[J].
ProcediaSocialandBehavioralSciences,2014,138:757766.
[12]ApacheHadoop[EB/OL].
(20140815).
http://hadoop.
apache.
org/.
[13]BorthakurD.
Thehadoopdistributedfilesystem:architectureanddesign[J].
HadoopProjectWebsite,2007,11:21.
(上接第753页)[3]ChenCL,GuoYide.
Mobilerobotlocalizationbydeadreckoning[C]//ProcofIEEEInternationalSymposiumonNextGenerationElectronics.
2013:565568.
[4]王殿君.
双目视觉在移动机器人定位中的应用[J].
中国机械工程,2013,24(9):11551158.
[5]孙风池,黄亚楼,康叶伟.
基于视觉的移动机器人同时定位与建图研究进展[J].
控制理论与应用,2010,27(4):488494.
[6]何琼,何永义,冯肖维.
基于激光传感器的多移动机器人位姿测量系统[J].
机电一体化,2011(2):4751.
[7]KimSJ,KimBK.
Dynamicultrasonichybridlocalizationsystemforindoormobilerobots[J].
IEEETransonIndustrialElectronics,2013,60(10):45624573.
[8]周帆,江维,李树全,等.
基于粒子滤波的移动物体定位和追踪算法[J].
软件学报,2013,24(9):21962213.
[9]宋宇,孙富春,李庆玲.
移动机器人的改进无迹粒子滤波蒙特卡罗定位算法[J].
自动化学报,2010,36(6):851857.
[10]KimTG,ChoiHT,KoNY.
Localizationofarobotusingparticlefilterwithrangeandbearinginformation[C]//Procofthe10thInternationalConferenceonUbiquitousRobotsandAmbientIntelligence.
2013:368370.
[11]MyungH,LeeHK,ChoiK,etal.
MobilerobotlocalizationwithgyroscopeandconstrainedKalmanfilter[J].
InternationalJournalofControl,AutomationandSystems,2010,8(3):667676.
[12]曹春萍,罗玲莉.
基于卡尔曼滤波算法的室内无线定位系统[J].
计算机系统应用,2011,20(11):7679.
[13]王晓娟,王宣银.
基于模糊卡尔曼滤波的移动机器人定位研究[J].
计算机工程与应用,2011,47(2):204206.
[14]谭志,张卉.
无线传感器网络RSSI定位算法的研究与改进[J].
北京邮电大学学报,2013,36(3):8892.
[15]ChenJing,LiGengmin,ZhangXuejun,etal.
AnefficientalgorithmforindoorlocationbasedonRFID[C]//ProcofInternationalConferenceonWirelessCommunicationsandSignalProcessing.
2011:14.
[16]LongHua,LuJ,XuQiang,etal.
AnewRSSIbasedcentroidlocalizationalgorithmbyuseofvirtualreferencetags[C]//Procofthe3rdInternationalConferenceonAdvancedCommunicationsandComputation.
2013:122128.
[17]王殿君,兰云峰,任福君,等.
基于有源RFID的室内移动机器人定位系统[J].
清华大学学报:自然科学版,2010,50(5):673676.
[18]胡斐,赵治国.
基于MATLAB的非线性方程组遗传解法[J].
计算机时代,2010(3):4445.
[19]LimHS,ChoiBS,LeeJM.
AnefficientlocalizationalgorithmformobilerobotsbasedonRFIDsystem[C]//ProcofInternationalJointConferenceonSICEICASE.
2006:59455950.
[20]谈宇奇,王雪,刘长.
物联网室内运动目标协作信息融合跟踪方法[J].
仪器仪表学报,2013,34(2):352358.
·857·计算机应用研究第33卷
- 算法ubuntu14.04相关文档
- 检测ubuntu14.04
- 节点ubuntu14.04
- SAFETYubuntu14.04
- 短语ubuntu14.04
- timesubuntu14.04
- 地图ubuntu14.04
美国cera机房 2核4G 19.9元/月 宿主机 E5 2696v2x2 512G
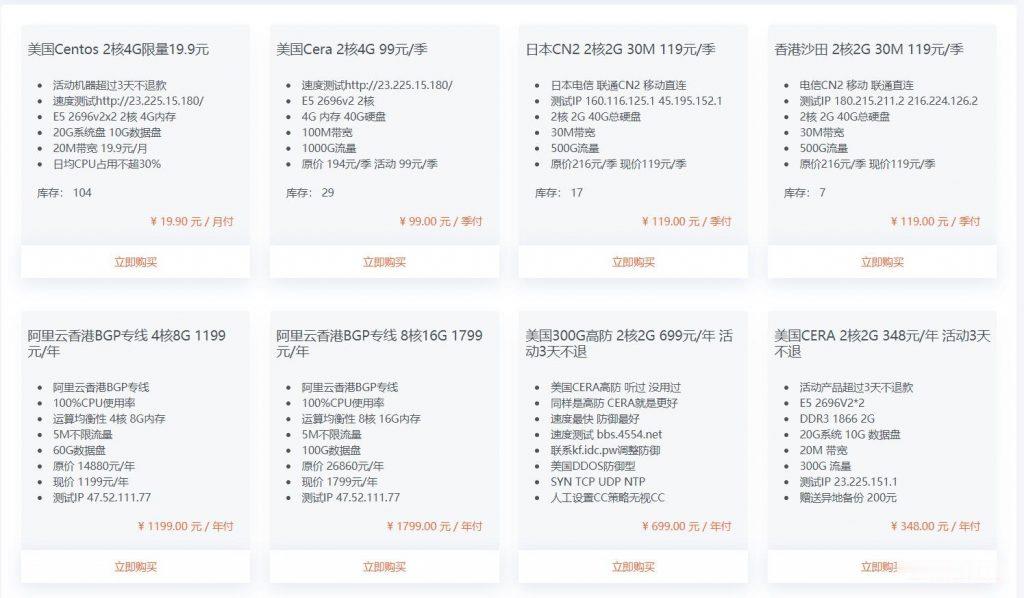
美国特价云服务器 2核4G 19.9元杭州王小玉网络科技有限公司成立于2020是拥有IDC ISP资质的正规公司,这次推荐的美国云服务器也是商家主打产品,有点在于稳定 速度 数据安全。企业级数据安全保障,支持异地灾备,数据安全系数达到了100%安全级别,是国内唯一一家美国云服务器拥有这个安全级别的商家。E5 2696v2x2 2核 4G内存 20G系统盘 10G数据盘 20M带宽 100G流量 1...
Virmach($7.2/年)特价机器发放
在八月份的时候有分享到 Virmach 暑期的促销活动有低至年付12美元的便宜VPS主机,这不开学季商家又发布五款年付VPS主机方案,而且是有可以选择七个数据中心。如果我们有需要低价年付便宜VPS主机的可以选择,且最低年付7.2美元(这款目前已经缺货)。这里需要注意的,这次发布的几款便宜年付方案,会在2021年9月30日或者2022年4月39日,分两个时间段会将INTEL CPU迁移至AMD CP...

Megalayer优化带宽和VPS主机主机方案策略 15M CN2优化带宽和30M全向带宽
Megalayer 商家主营业务是以独立服务器和站群服务器的,后来也陆续的有新增香港、菲律宾数据中心的VPS主机产品。由于其线路的丰富,还是深受一些用户喜欢的,有CN2优化直连线路,有全向国际线路,以及针对欧美的国际线路。这次有看到商家也有新增美国机房的VPS主机,也有包括15M带宽CN2优化带宽以及30M带宽的全向线路。Megalayer 商家提供的美国机房VPS产品,提供的配置方案也是比较多,...
ubuntu14.04为你推荐
-
太空国家世界上第一个把人类送入太空的国家是firetrap你们知道的有多少运动品牌的服饰?18comic.fun黑色禁药http://www.lovecomic.cn/attachment/Fid_18/18_4_00d3b0cb502ea74.jpg这幅画名字叫什么?rawtoolsRAW是什么衣服牌子haole018.comhttp://www.haoledy.com/view/32092.html 轩辕剑天之痕11、12集在线观看同一服务器网站一个服务器能运行多少个网站www.haole012.com012.qq.com是真的吗www.44ri.comwww.yydcsjw.comqq530.com求教:如何下载http://www.qq530.com/ 上的音乐www.544qq.COM跪求:天时达T092怎么下载QQ