antwww.baidu.jp
www.baidu.jp 时间:2021-05-24 阅读:()
PFP:ParallelFP-GrowthforQueryRecommendationHaoyuanLiGoogleBeijingResearch,Beijing,100084,ChinaYiWangGoogleBeijingResearch,Beijing,100084,ChinaDongZhangGoogleBeijingResearch,Beijing,100084,ChinaMingZhangDept.
ComputerScience,PekingUniversity,Beijing,100071,ChinaEdwardChangGoogleResearch,MountainView,CA94043,USAABSTRACTFrequentitemsetmining(FIM)isausefultoolfordiscov-eringfrequentlyco-occurrentitems.
Sinceitsinception,anumberofsignicantFIMalgorithmshavebeendevelopedtospeedupminingperformance.
Unfortunately,whenthedatasetsizeishuge,boththememoryuseandcomputa-tionalcostcanstillbeprohibitivelyexpensive.
Inthiswork,weproposetoparallelizetheFP-Growthalgorithm(wecallourparallelalgorithmPFP)ondistributedmachines.
PFPpartitionscomputationinsuchawaythateachmachineexecutesanindependentgroupofminingtasks.
Suchparti-tioningeliminatescomputationaldependenciesbetweenma-chines,andtherebycommunicationbetweenthem.
Throughempiricalstudyonalargedatasetof802,939Webpagesand1,021,107tags,wedemonstratethatPFPcanachievevirtu-allylinearspeedup.
Besidesscalability,theempiricalstudydemonstratesthatPFPtobepromisingforsupportingqueryrecommendationforsearchengines.
CategoriesandSubjectDescriptorsH.
3[InformationStorageandRetrieval];H.
4[InformationSystemsApplications]GeneralTermsAlgorithms,Experimentation,HumanFactors,PerformanceKeywordsParallelFP-Growth,DataMining,FrequentItemsetMining1.
INTRODUCTIONInthispaper,weattacktwoproblems.
First,wepar-allelizefrequentitemsetmining(FIM)soastodealwithlarge-scaledata-miningproblems.
Second,weapplyourde-Permissiontomakedigitalorhardcopiesofallorpartofthisworkforpersonalorclassroomuseisgrantedwithoutfeeprovidedthatcopiesarenotmadeordistributedforprotorcommercialadvantageandthatcopiesbearthisnoticeandthefullcitationontherstpage.
Tocopyotherwise,torepublish,topostonserversortoredistributetolists,requirespriorspecicpermissionand/orafee.
ACMRSCopyright200XACMX-XXXXX-XX-X/XX/XX.
.
.
$5.
00.
velopedparallelalgorithmonWebdatatosupportqueryrecommendation(orrelatedsearch).
FIMisausefultoolfordiscoveringfrequentlyco-occurrentitems.
ExistingFIMalgorithmssuchasApriori[9]andFP-Growth[6]canberesourceintensivewhenamineddatasetishuge.
Parallelalgorithmsweredevelopedforreducingmem-oryuseandcomputationalcostoneachmachine.
Earlyeorts(relatedworkispresentedingreaterdetailinSec-tion1.
1)focusedonspeedinguptheApriorialgorithm.
SincetheFP-GrowthalgorithmhasbeenshowntorunmuchfasterthantheApriori,itislogicaltoparallelizetheFP-Growthalgorithmtoenjoyevenfasterspeedup.
RecentworkinparallelizingFP-Growth[10,8]suersfromhighcommuni-cationcost,andhenceconstrainsthepercentageofcompu-tationthatcanbeparallelized.
Inthispaper,weproposeaMapReduceapproach[4]ofparallelFP-Growthalgorithm(wecallourproposedalgorithmPFP),whichintelligentlyshardsalarge-scaleminingtaskintoindependentcompu-tationaltasksandmapsthemontoMapReducejobs.
PFPcanachievenear-linearspeedupwithcapabilityofrestartingfromcomputerfailures.
Theresourceproblemoflarge-scaleFIMcouldbeworkedaroundinaclassicmarket-basketsettingbypruningoutitemsoflowsupport.
Thisisbecauselow-supportitemsetsareusuallyoflittlepracticalvalue,e.
g.
,amerchandisewithlowsupport(oflowconsumerinterest)cannothelpdriveuprevenue.
However,intheWebsearchsetting,thehugenumberoflow-supportqueries,orlong-tailqueries[2],eachmustbemaintainedwithhighsearchquality.
Theimpor-tanceoflow-supportfrequentitemsetsinsearchapplicationsrequiresFIMtoconfrontitsresourcebottleneckshead-on.
Inparticular,thispapershowsthatapost-searchrecom-mendationtoolcalledrelatedsearchcanbenetagreatdealfromourscalableFIMsolution.
Relatedsearchprovidesrelatedqueriestotheuserafteraninitialsearchhasbeencompleted.
Forinstance,aqueryof'apple'maysuggest'orange','iPod'and'iPhone'asalternatequeries.
Relatedsearchcanalsosuggestrelatedsitesofagivensite(seeex-ampleinSection3.
2).
1.
1RelatedWorkSomepreviouseorts[10][7]parallelizedtheFP-Growthalgorithmacrossmultiplethreadsbutwithsharedmemory.
However,toourproblemofprocessinghugedatabases,theseapproachesdonotaddressthebottleneckofhugememoryrequirement.
Figure1:AsimpleexampleofdistributedFP-Growth.
Todistributebothdataandcomputationacrossmultiplecomputers,Pramudionoetal[8]designedadistributedvari-antoftheFP-growthalgorithm,whichrunsoveraclusterofcomputers.
Someveryrecentwork[5][1][3]proposedsolutionstomoredetailedissues,includingcommunicationcost,cacheconsciousness,memory&I/Outilization,anddataplacementstrategies.
TheseapproachesachievegoodscalabilityondozenstohundredsofcomputersusingtheMPIprogrammingmodel.
However,tofurtherimprovethescalabilitytothousandsorevenmorecomputers,wehavetofurtherreducecom-municationoverheadsbetweencomputersandsupportau-tomaticfaultrecovery.
Inparticular,faultrecoverybecomesacriticalprobleminamassivecomputingenvironment,be-causetheprobabilitythatnoneofthethousandsofcomput-erscrashesduringexecutionofataskisclosetozero.
Thedemandsofsustainablespeedupandfaulttolerancerequirehighlyconstrainedandecientcommunicationprotocols.
Inthispaper,weshowthatourproposedsolutionisabletoaddresstheissuesofmemoryuse,faulttolerance,inadditiontomoreeectivelyparallelizingcomputation.
1.
2ContributionSummaryInsummary,thecontributionsofthispaperareasfollows:1.
WeproposePFP,whichshardsalarge-scaleminingtaskintoindependent,paralleltasks.
PPFthenusestheMapReducemodeltotakeadvantageofitsrecov-erymodel.
EmpiricalstudyshowsthatPFPachievesnear-linearspeedup.
2.
Withthescalabilityofouralgorithm,weareabletomineatag/Webpageatlasfromdel.
icio.
us,aWeb2.
0applicationthatallowsuserstaggingWebpagestheyhavebrowsed.
Ittakes2,500computersonly24minutestominetheatlasconsistingof46,000,000patternsfromasetof802,939URLsand1,021,107tags.
TheminedtagitemsetsandWebpageitemsetsarereadilytosupportqueryrecommendationorrelatedsearch.
2.
PFP:PARALLELFP-GROWTHTomakethispaperself-contained,werstrestatetheproblemofFIM.
WethendeneparametersusedinPF-Growth,anddepictthealgorithm.
StartinginSection2.
2,wepresentourparallelFP-Growthalgorithm,orPFP.
LetI={a1,a2,am}beasetofitems,andatrans-actiondatabaseDBisasetofsubsetsofI,denotedbyDB={T1,T2,Tn},whereeachTiI(1≤i≤n)issaidatransaction.
ThesupportofapatternAI,denotedbysupp(A),isthenumberoftransactionscontainingAinDB.
Aisafrequentpatternifandonlysupp(A)≥ξ,whereξisapredenedminimumsupportthreshold.
GivenDBandξ,theproblemofndingthecompletesetoffrequentpatternsiscalledthefrequentitemsetminingproblem.
2.
1FP-GrowthAlgorithmFP-Growthworksinadivideandconquerway.
Itrequirestwoscansonthedatabase.
FP-Growthrstcomputesalistoffrequentitemssortedbyfrequencyindescendingorder(F-List)duringitsrstdatabasescan.
Initssecondscan,thedatabaseiscompressedintoaFP-tree.
ThenFP-GrowthstartstominetheFP-treeforeachitemwhosesupportislargerthanξbyrecursivelybuildingitsconditionalFP-tree.
ThealgorithmperformsminingrecursivelyonFP-tree.
Theproblemofndingfrequentitemsetsisconvertedtosearch-ingandconstructingtreesrecursively.
Figure1showsasimpleexample.
TheexampleDBhasvetransactionscomposedoflower-casealphabets.
TherststepthatFP-Growthperformsistosortitemsintransac-tionswithinfrequentitemsremoved.
Inthisexample,wesetξ=3andhencekeepalphabetsf,c,a,b,m,p.
Afterthisstep,forexample,T1(therstrowinthegure)isprunedfrom{f,a,c,d,g,i,m,p}to{f,c,a,m,p}.
FP-Growththencompressesthese"pruned"transactionsintoaprextree,whichrootisthemostfrequentitemf.
Eachpathonthetreerepresentsasetoftransactionsthatsharethesameprex;eachnodecorrespondstooneitem.
Eachlevelofthetreecorrespondstooneitem,andanitemlistisformedtolinkalltransactionsthatpossessthatitem.
TheFP-treeisaProcedure:FPGrowth(DB,ξ)DeneandclearF-List:F[];foreachTransactionTiinDBdoforeachItemajinTidoF[ai]++;endendSortF[];DeneandcleartherootofFP-tree:r;foreachTransactionTiinDBdoMakeTiorderedaccordingtoF;CallConstructTree(Ti,r);endforeachitemaiinIdoCallGrowth(r,ai,ξ);endAlgorithm1:FP-GrowthAlgorithmcompressedrepresentationofthetransactions,anditalsoal-lowsquickaccesstoalltransactionsthatshareagivenitem.
Oncethetreehasbeenconstructed,thesubsequentpatternminingcanbeperformed.
However,acompactrepresenta-tiondoesnotreducethepotentialcombinatorialnumberofcandidatepatterns,whichisthebottleneckofFP-Growth.
Algorithm1presentsthepseudocodeofFP-Growth[6].
WecanestimatethetimecomplexityofcomputingF-ListtobeO(DBSize)usingahashingscheme.
However,thecomputationalcostofprocedureGrowth()(thedetailisshowninAlgorithm2)isatleastpolynomial.
TheprocedureFPGrowth()callstherecursiveprocedureGrowth(),wheremultipleconditionalFP-treesaremaintainedinmemoryandhencethebottleneckoftheFP-Growthalgorithm.
FP-Growthfacesthefollowingresourcechallenges:1.
Storage.
ForhugeDB's,thecorrespondingFP-treeisalsohugeandcannottinmainmemory(orevendisks).
ItisthusnecessarytogeneratesomesmallDBstorepresentthecompleteone.
Asaresult,eachnewsmallDBcantintomemoryandgenerateitslocalFP-tree.
2.
Computationdistribution.
AllstepsofFP-Growthcanbeparallelized,andespeciallytherecursivecallstoGrowth().
3.
Costlycommunication.
PreviousparallelFP-GrowthalgorithmspartitionDBintogroupsofsuccessivetrans-actions.
DistributedFP-treescanbeinter-dependent,andhencecanincurfrequentsynchronizationbetweenparallelthreadsofexecution.
4.
Supportvalue.
ThesupportthresholdvalueξplaysanimportantroleinFP-Growth.
Thelargertheξ,thefewerresultpatternsarereturnedandthelowerthecostofcomputationandstorage.
Usually,foralargescaleDB,ξhastobesetlargeenough,ortheFP-treewouldoverowthestorage.
ForWebminingtasks,wetypicallysetξtobeverylowtoobtainlong-tailitemsets.
Thislowsettingmayrequireunacceptablecomputationaltime.
Procedure:Growth(r,a,ξ)ifrcontainsasinglepathZthenforeachcombination(denotedasγ)ofthenodesinZdoGeneratepatternβ=γ∪awithsupport=minimumsupportofnodesinγ;ifβ.
support>ξthenCallOutput(β);endendelseforeachbiinrdoGeneratepatternβ=bi∪awithsupport=bi.
support;ifβ.
support>ξthenCallOutput(β);endConstructβsconditionaldatabase;ConstructβsconditionalFP-treeTreeβ;ifTreeβ=φthenCallGrowth(Treeβ,β,ξ);endendendAlgorithm2:TheFP-GrowthAlgorithm.
Figure2:TheoverallPFPframework,showingvestagesofcomputation.
2.
2PFPOutlineGivenatransactiondatabaseDB,PFPusesthreeMapRe-duce[4]phasestoparallelizePF-Growth.
Figure2depictsthevestepsofPFP.
Step1:Sharding:DividingDBintosuccessivepartsandstoringthepartsonPdierentcomputers.
Suchdi-visionanddistributionofdataiscalledsharding,andeachpartiscalledashard1.
Step2:ParallelCounting(Section2.
3):DoingaMapRe-ducepasstocountthesupportvaluesofallitemsthatappearinDB.
EachmapperinputsoneshardofDB.
Thisstepimplicitlydiscoverstheitems'vocabularyI,whichisusuallyunknownforahugeDB.
TheresultisstoredinF-list.
Step3:GroupingItems:Dividingallthe|I|itemsonF-ListintoQgroups.
Thelistofgroupsiscalledgrouplist(G-list),whereeachgroupisgivenauniquegroup-id(gid).
AsF-listandG-listarebothsmallandthetimecomplexityisO(|I|),thisstepcancompleteonasinglecomputerinfewseconds.
Step4:ParallelFP-Growth(Section2.
4):ThekeystepofPFP.
ThissteptakesoneMapReducepass,wherethemapstageandreducestageperformdierentimpor-tantfunctions:Mapper–Generatinggroup-dependenttransactions:EachmapperinstanceisfedwithashardofDBgeneratedinStep1.
Beforeitprocessestransactionsintheshardonebyone,itreadstheG-list.
Withthemapperalgo-rithmdetailedinSection2.
4,itoutputsoneormorekey-valuepairs,whereeachkeyisagroup-idanditscorrespondingvalueisageneratedgroup-dependenttransaction.
Reducer–FP-Growthongroup-dependentshards:Whenallmapperinstanceshavenishedtheirwork,foreachgroup-id,theMapReduceinfrastructureautomaticallygroupsallcorrespondinggroup-dependenttransactionsintoashardofgroup-dependenttransactions.
Eachreducerinstanceisassignedtoprocessoneormoregroup-dependentshardonebyone.
Foreachshard,thereducerinstancebuildsalocalFP-treeandgrowthitsconditionalFP-treesrecursively.
Duringtherecursiveprocess,itmayoutputdiscoveredpatterns.
Step5:Aggregating(Section2.
5):AggregatingtheresultsgeneratedinStep4asournalresult.
AlgorithmsofthemapperandreduceraredescribedindetailinSection2.
5.
2.
3ParallelCountingCountingisaclassicalapplicationofMapReduce.
Be-causethemapperisfedwithshardsofDB,itsinputkey-valuepairwouldbelikekey,value=Ti,whereTiDBisatransaction.
Foreachitem,sayaj∈Ti,themapperoutputsakey-valuepairkey=aj,value=1.
Afterallmapperinstanceshavenished,foreachkeygeneratedbythemappers,theMapReduceinfrastructurecollectsthesetofcorrespondingvalues(hereitisasetof1MapReduceprovidesconvenientsoftwaretoolsforshard-ing.
Procedure:Mapper(key,value=Ti)foreachitemaiinTidoCallOutput(ai,1);endProcedure:Reducer(key=ai,value=S(ai))C←0;foreachitem1inTidoC←C+1;endCallOutput(null,ai+C);Algorithm3:TheParallelCountingAlgorithm1's),sayS(key),andfeedthereducerswithkey-valuepairskey,S(key).
Thereducerthussimplyoutputskey=null,value=key+sum(S(key)).
Itisnotdiculttoseethatkeyisanitemandvalueissupp(key).
Algorithm3presentsthepseudocodeofthersttwosteps:shardingandparallelcounting.
ThespacecomplexityofthisalgorithmisO(DBSize/P)andthetimecomplexityisO(DBSize/P).
2.
4ParallelFP-GrowthThisstepisthekeyinourPFPalgorithm.
OursolutionistoconverttransactionsinDBintosomenewdatabasesofgroup-dependenttransactionssothatlocalFP-treesbuiltfromdierentgroup-dependenttransactionsareindependentduringtherecursiveconditionalFP-treeconstructingpro-cess.
WedividethisstepintoMapperpartandReducerpartindetails.
Algorithm4presentsthepseudocodeofstep4,Paral-lelFP-Growth.
ThespacecomplexityofthisalgorithmisO(Max(NewDBSize))foreachmachine.
2.
4.
1GeneratingTransactionsforGroup-dependentDatabasesWheneachmapperinstancestarts,itloadstheG-listgen-eratedinStep3.
NotethatG-listisusuallysmallandcanbeheldinmemory.
Inparticular,themapperreadsandorganizesG-listasahashmap,whichmapseachitemontoitscorrespondinggroup-id.
Becauseinthisstep,amapperinstanceisalsofedwithashardofDB,theinputpairshouldbeintheformofkey,value=Ti.
ForeachTi,themapperperformsthefollowingtwosteps:1.
Foreachitemaj∈Ti,substituteajbycorrespondinggroup-id.
2.
Foreachgroup-id,saygid,ifitappearsinTi,locateitsright-mostappearance,sayL,andoutputakey-valuepairkey=gid,value={Ti[1].
.
.
Ti[L]}.
Afterallmapperinstanceshavecompleted,foreachdis-tinctvalueofkey,theMapReduceinfrastructurecollectscorrespondinggroup-dependenttransactionsasvaluevalue,andfeedreducersbykey-valuepairkey=key,value.
Herevalueisagroupofgroup-dependenttransactionscor-respondingtothesamegroup-id,andissaidagroup-dependentshard.
Notably,thisalgorithmmakesuseofaconceptintroducedin[6],patternendingat.
.
.
,toensurethatifagroup,forexample{a,c}or{b,e},isapattern,thissupportofthisProcedure:Mapper(key,value=Ti)LoadG-List;GenerateHashTableHfromG-List;a[]←Split(Ti);forj=|Ti|1to0doHashNum←getHashNum(H,a[j]);ifHashNum=NullthenDeleteallpairswhichhashvalueisHashNuminH;CallOutput(HashNum,a[0]+a[1]a[j]);endendProcedure:Reducer(key=gid,value=DBgid)LoadG-List;nowGroup←G-Listgid;LocalFPtree←clear;foreachTiinDB(gid)doCallinsertbuildfptree(LocalFPtree,Ti);endforeachaiinnowGroupdoDeneandclearasizeKmaxheap:HP;CallTopKFPGrowth(LocalFPtree,ai,HP);foreachviinHPdoCallOutput(null,vi+supp(vi));endendAlgorithm4:TheParallelFP-GrowthAlgorithmpatterncanbecountedonlywithinthegroup-dependentshardwithkey=gid,butdoesnotrelyonanyothershards.
2.
4.
2FP-GrowthonGroup-dependentShardsInthisstep,eachreducerinstancereadsandprocessespairsintheformofkey=gid,value=DB(gid)onebyone,whereeachDB(gid)isagroup-dependentshard.
ForeachDB(gid),thereducerconstructsthelocalFP-treeandrecursivelybuildsitsconditionalsub-treessimilartothetraditionalFP-Growthalgorithm.
Duringthisrecursiveprocess,itoutputsfoundpatterns.
TheonlydierencefromtraditionalFP-Growthalgorithmisthat,thepatternsarenotoutputdirectly,butintoamax-heapindexedbythesupportvalueofthefoundpattern.
So,foreachDB(gid),thereducermaintainsKmostlysupportedpatterns,whereKisthesizeofthemax-heapHP.
AfterthelocalrecursiveFP-Growthprocess,thereduceroutputseverypattern,v,inthemax-heapaspairsintheformofkey=null,value=v+supp(v)2.
5AggregatingTheaggregatingstepreadsfromtheoutputfromStep4.
Foreachitem,itoutputscorrespondingtop-Kmostlysup-portedpatterns.
Inparticular,themapperisfedwithpairsintheformofkey=null,value=v+supp(v).
Foreachaj∈v,itoutputsapairkey=aj,value=v+supp(v).
BecauseoftheautomaticcollectionfunctionoftheMapRe-duceinfrastructure,thereducerisfedwithpairsintheformofkey=aj,value=V(aj),whereV(aj)denotesthesetoftransitionsincludingitemaj.
ThereducerjustselectsfromS(aj)thetop-Kmostlysupportedpatternsandout-putsthem.
Procedure:Mapper(key,value=v+supp(v))foreachitemaiinvdoCallOutput(ai,v+supp(v));endProcedure:Reducer(key=ai,value=S(v+supp(v)))DeneandclearasizeKmaxheap:HP;foreachpatternvinv+supp(v)doif|HP|www.
baidu.
jp,andwww.
namaan.
net)arerelatedtoWebsearchenginesusedinJapan.
Figure7:Java-basedMiningUIdistributedenvironment.
InICPADS,2006.
[6]JiaweiHan,JianPei,andYiwenYin.
Miningfrequentpatternswithoutcandidategeneration.
InSIGMOD,2000.
[7]LiLiu,EricLi,YiminZhang,andZhizhongTang.
Optimizationoffrequentitemsetminingonmultiple-coreprocessor.
InVLDB,2007.
[8]IkoPramudionoandMasaruKitsuregawa.
Parallelfp-growthonpccluster.
InPAKDD,2003.
[9]AgrawalRakeshandRamakrishnanSrikant.
Fastalgorithmsforminingassociationrules.
InProc.
20thInt.
Conf.
VeryLargeDataBases,VLDB,1994.
[10]OsmarR.
Za¨ane,MohammadEl-Hajj,andPaulLu.
Fastparallelassociationruleminingwithoutcandidacygeneration.
InICDM,2001.
WebpagesDescriptionSupportwww.
openmoko.
orgCellphonesoftware2607www.
grandcentral.
comdownloadrelatedwebwww.
zyb.
comsites.
www.
simpy.
comFoursocial242www.
furl.
netbookmarkingserviceswww.
connotea.
orgwebsites,includingdel.
icio.
usdel.
ici.
os.
Thelastwww.
masternewmedia.
org/neoneisanarticleitws/2006/12/01/socialbookmdiscussthis.
arkingservicesandtools.
htmwww.
troovy.
comFiveonlinemaps.
240www.
agr.
comhttp://outside.
inwww.
wayfaring.
comhttp://ickrvision.
commail.
google.
com/mailWebsitesrelatedto204www.
google.
com/igGMailservice.
gdisk.
sourceforge.
netwww.
netvibes.
comwww.
trovando.
itSixfancysearch151www.
kartoo.
comengines.
www.
snap.
comwww.
clusty.
comwww.
aldaily.
comwww.
quintura.
comwwwl.
meebo.
comIntegratedinstant112www.
ebuddy.
commessagesoftwarewww.
plugoo.
comwebsites.
www.
easyhotel.
comTravelingagencyweb109www.
hostelz.
comsites.
www.
couchsurng.
comwww.
tripadvisor.
comwww.
kayak.
comwww.
easyjet.
com/it/prenotaItaliantraveling98www.
ryanair.
com/site/ITagencywebsites.
www.
edreams.
itwww.
expedia.
itwww.
volagratis.
com/vg1www.
skyscanner.
netwww.
google.
com/codesearchThreecodesearchweb98www.
koders.
comsitesandtwoarticleswww.
bigbold.
com/snippetstalkingaboutcodewww.
gotapi.
comsearch.
0xcc.
net/blog/archives/000043.
htmlwww.
google.
co.
jpFourJapaneseweb36www.
livedoor.
comsearchengines.
www.
baidu.
jpwww.
namaan.
netwww.
operator11.
comTV,mediastreaming34www.
joost.
comrelatedwebsites.
www.
keepvid.
comwww.
getdemocracy.
comwww.
masternewmedia.
orgwww.
technorati.
comFromthesewebsites,17www.
listible.
comyoucangetrelevantwww.
popurls.
comresourcequickly.
www.
trobar.
org/prosodyAllwebsitesare9librarianchick.
pbwiki.
comaboutliterature.
www.
quotationspage.
comwww.
visuwords.
comFigure5:Examplesofminingtag-tagsandwebpage-webpagesrelationships.
ComputerScience,PekingUniversity,Beijing,100071,ChinaEdwardChangGoogleResearch,MountainView,CA94043,USAABSTRACTFrequentitemsetmining(FIM)isausefultoolfordiscov-eringfrequentlyco-occurrentitems.
Sinceitsinception,anumberofsignicantFIMalgorithmshavebeendevelopedtospeedupminingperformance.
Unfortunately,whenthedatasetsizeishuge,boththememoryuseandcomputa-tionalcostcanstillbeprohibitivelyexpensive.
Inthiswork,weproposetoparallelizetheFP-Growthalgorithm(wecallourparallelalgorithmPFP)ondistributedmachines.
PFPpartitionscomputationinsuchawaythateachmachineexecutesanindependentgroupofminingtasks.
Suchparti-tioningeliminatescomputationaldependenciesbetweenma-chines,andtherebycommunicationbetweenthem.
Throughempiricalstudyonalargedatasetof802,939Webpagesand1,021,107tags,wedemonstratethatPFPcanachievevirtu-allylinearspeedup.
Besidesscalability,theempiricalstudydemonstratesthatPFPtobepromisingforsupportingqueryrecommendationforsearchengines.
CategoriesandSubjectDescriptorsH.
3[InformationStorageandRetrieval];H.
4[InformationSystemsApplications]GeneralTermsAlgorithms,Experimentation,HumanFactors,PerformanceKeywordsParallelFP-Growth,DataMining,FrequentItemsetMining1.
INTRODUCTIONInthispaper,weattacktwoproblems.
First,wepar-allelizefrequentitemsetmining(FIM)soastodealwithlarge-scaledata-miningproblems.
Second,weapplyourde-Permissiontomakedigitalorhardcopiesofallorpartofthisworkforpersonalorclassroomuseisgrantedwithoutfeeprovidedthatcopiesarenotmadeordistributedforprotorcommercialadvantageandthatcopiesbearthisnoticeandthefullcitationontherstpage.
Tocopyotherwise,torepublish,topostonserversortoredistributetolists,requirespriorspecicpermissionand/orafee.
ACMRSCopyright200XACMX-XXXXX-XX-X/XX/XX.
.
.
$5.
00.
velopedparallelalgorithmonWebdatatosupportqueryrecommendation(orrelatedsearch).
FIMisausefultoolfordiscoveringfrequentlyco-occurrentitems.
ExistingFIMalgorithmssuchasApriori[9]andFP-Growth[6]canberesourceintensivewhenamineddatasetishuge.
Parallelalgorithmsweredevelopedforreducingmem-oryuseandcomputationalcostoneachmachine.
Earlyeorts(relatedworkispresentedingreaterdetailinSec-tion1.
1)focusedonspeedinguptheApriorialgorithm.
SincetheFP-GrowthalgorithmhasbeenshowntorunmuchfasterthantheApriori,itislogicaltoparallelizetheFP-Growthalgorithmtoenjoyevenfasterspeedup.
RecentworkinparallelizingFP-Growth[10,8]suersfromhighcommuni-cationcost,andhenceconstrainsthepercentageofcompu-tationthatcanbeparallelized.
Inthispaper,weproposeaMapReduceapproach[4]ofparallelFP-Growthalgorithm(wecallourproposedalgorithmPFP),whichintelligentlyshardsalarge-scaleminingtaskintoindependentcompu-tationaltasksandmapsthemontoMapReducejobs.
PFPcanachievenear-linearspeedupwithcapabilityofrestartingfromcomputerfailures.
Theresourceproblemoflarge-scaleFIMcouldbeworkedaroundinaclassicmarket-basketsettingbypruningoutitemsoflowsupport.
Thisisbecauselow-supportitemsetsareusuallyoflittlepracticalvalue,e.
g.
,amerchandisewithlowsupport(oflowconsumerinterest)cannothelpdriveuprevenue.
However,intheWebsearchsetting,thehugenumberoflow-supportqueries,orlong-tailqueries[2],eachmustbemaintainedwithhighsearchquality.
Theimpor-tanceoflow-supportfrequentitemsetsinsearchapplicationsrequiresFIMtoconfrontitsresourcebottleneckshead-on.
Inparticular,thispapershowsthatapost-searchrecom-mendationtoolcalledrelatedsearchcanbenetagreatdealfromourscalableFIMsolution.
Relatedsearchprovidesrelatedqueriestotheuserafteraninitialsearchhasbeencompleted.
Forinstance,aqueryof'apple'maysuggest'orange','iPod'and'iPhone'asalternatequeries.
Relatedsearchcanalsosuggestrelatedsitesofagivensite(seeex-ampleinSection3.
2).
1.
1RelatedWorkSomepreviouseorts[10][7]parallelizedtheFP-Growthalgorithmacrossmultiplethreadsbutwithsharedmemory.
However,toourproblemofprocessinghugedatabases,theseapproachesdonotaddressthebottleneckofhugememoryrequirement.
Figure1:AsimpleexampleofdistributedFP-Growth.
Todistributebothdataandcomputationacrossmultiplecomputers,Pramudionoetal[8]designedadistributedvari-antoftheFP-growthalgorithm,whichrunsoveraclusterofcomputers.
Someveryrecentwork[5][1][3]proposedsolutionstomoredetailedissues,includingcommunicationcost,cacheconsciousness,memory&I/Outilization,anddataplacementstrategies.
TheseapproachesachievegoodscalabilityondozenstohundredsofcomputersusingtheMPIprogrammingmodel.
However,tofurtherimprovethescalabilitytothousandsorevenmorecomputers,wehavetofurtherreducecom-municationoverheadsbetweencomputersandsupportau-tomaticfaultrecovery.
Inparticular,faultrecoverybecomesacriticalprobleminamassivecomputingenvironment,be-causetheprobabilitythatnoneofthethousandsofcomput-erscrashesduringexecutionofataskisclosetozero.
Thedemandsofsustainablespeedupandfaulttolerancerequirehighlyconstrainedandecientcommunicationprotocols.
Inthispaper,weshowthatourproposedsolutionisabletoaddresstheissuesofmemoryuse,faulttolerance,inadditiontomoreeectivelyparallelizingcomputation.
1.
2ContributionSummaryInsummary,thecontributionsofthispaperareasfollows:1.
WeproposePFP,whichshardsalarge-scaleminingtaskintoindependent,paralleltasks.
PPFthenusestheMapReducemodeltotakeadvantageofitsrecov-erymodel.
EmpiricalstudyshowsthatPFPachievesnear-linearspeedup.
2.
Withthescalabilityofouralgorithm,weareabletomineatag/Webpageatlasfromdel.
icio.
us,aWeb2.
0applicationthatallowsuserstaggingWebpagestheyhavebrowsed.
Ittakes2,500computersonly24minutestominetheatlasconsistingof46,000,000patternsfromasetof802,939URLsand1,021,107tags.
TheminedtagitemsetsandWebpageitemsetsarereadilytosupportqueryrecommendationorrelatedsearch.
2.
PFP:PARALLELFP-GROWTHTomakethispaperself-contained,werstrestatetheproblemofFIM.
WethendeneparametersusedinPF-Growth,anddepictthealgorithm.
StartinginSection2.
2,wepresentourparallelFP-Growthalgorithm,orPFP.
LetI={a1,a2,am}beasetofitems,andatrans-actiondatabaseDBisasetofsubsetsofI,denotedbyDB={T1,T2,Tn},whereeachTiI(1≤i≤n)issaidatransaction.
ThesupportofapatternAI,denotedbysupp(A),isthenumberoftransactionscontainingAinDB.
Aisafrequentpatternifandonlysupp(A)≥ξ,whereξisapredenedminimumsupportthreshold.
GivenDBandξ,theproblemofndingthecompletesetoffrequentpatternsiscalledthefrequentitemsetminingproblem.
2.
1FP-GrowthAlgorithmFP-Growthworksinadivideandconquerway.
Itrequirestwoscansonthedatabase.
FP-Growthrstcomputesalistoffrequentitemssortedbyfrequencyindescendingorder(F-List)duringitsrstdatabasescan.
Initssecondscan,thedatabaseiscompressedintoaFP-tree.
ThenFP-GrowthstartstominetheFP-treeforeachitemwhosesupportislargerthanξbyrecursivelybuildingitsconditionalFP-tree.
ThealgorithmperformsminingrecursivelyonFP-tree.
Theproblemofndingfrequentitemsetsisconvertedtosearch-ingandconstructingtreesrecursively.
Figure1showsasimpleexample.
TheexampleDBhasvetransactionscomposedoflower-casealphabets.
TherststepthatFP-Growthperformsistosortitemsintransac-tionswithinfrequentitemsremoved.
Inthisexample,wesetξ=3andhencekeepalphabetsf,c,a,b,m,p.
Afterthisstep,forexample,T1(therstrowinthegure)isprunedfrom{f,a,c,d,g,i,m,p}to{f,c,a,m,p}.
FP-Growththencompressesthese"pruned"transactionsintoaprextree,whichrootisthemostfrequentitemf.
Eachpathonthetreerepresentsasetoftransactionsthatsharethesameprex;eachnodecorrespondstooneitem.
Eachlevelofthetreecorrespondstooneitem,andanitemlistisformedtolinkalltransactionsthatpossessthatitem.
TheFP-treeisaProcedure:FPGrowth(DB,ξ)DeneandclearF-List:F[];foreachTransactionTiinDBdoforeachItemajinTidoF[ai]++;endendSortF[];DeneandcleartherootofFP-tree:r;foreachTransactionTiinDBdoMakeTiorderedaccordingtoF;CallConstructTree(Ti,r);endforeachitemaiinIdoCallGrowth(r,ai,ξ);endAlgorithm1:FP-GrowthAlgorithmcompressedrepresentationofthetransactions,anditalsoal-lowsquickaccesstoalltransactionsthatshareagivenitem.
Oncethetreehasbeenconstructed,thesubsequentpatternminingcanbeperformed.
However,acompactrepresenta-tiondoesnotreducethepotentialcombinatorialnumberofcandidatepatterns,whichisthebottleneckofFP-Growth.
Algorithm1presentsthepseudocodeofFP-Growth[6].
WecanestimatethetimecomplexityofcomputingF-ListtobeO(DBSize)usingahashingscheme.
However,thecomputationalcostofprocedureGrowth()(thedetailisshowninAlgorithm2)isatleastpolynomial.
TheprocedureFPGrowth()callstherecursiveprocedureGrowth(),wheremultipleconditionalFP-treesaremaintainedinmemoryandhencethebottleneckoftheFP-Growthalgorithm.
FP-Growthfacesthefollowingresourcechallenges:1.
Storage.
ForhugeDB's,thecorrespondingFP-treeisalsohugeandcannottinmainmemory(orevendisks).
ItisthusnecessarytogeneratesomesmallDBstorepresentthecompleteone.
Asaresult,eachnewsmallDBcantintomemoryandgenerateitslocalFP-tree.
2.
Computationdistribution.
AllstepsofFP-Growthcanbeparallelized,andespeciallytherecursivecallstoGrowth().
3.
Costlycommunication.
PreviousparallelFP-GrowthalgorithmspartitionDBintogroupsofsuccessivetrans-actions.
DistributedFP-treescanbeinter-dependent,andhencecanincurfrequentsynchronizationbetweenparallelthreadsofexecution.
4.
Supportvalue.
ThesupportthresholdvalueξplaysanimportantroleinFP-Growth.
Thelargertheξ,thefewerresultpatternsarereturnedandthelowerthecostofcomputationandstorage.
Usually,foralargescaleDB,ξhastobesetlargeenough,ortheFP-treewouldoverowthestorage.
ForWebminingtasks,wetypicallysetξtobeverylowtoobtainlong-tailitemsets.
Thislowsettingmayrequireunacceptablecomputationaltime.
Procedure:Growth(r,a,ξ)ifrcontainsasinglepathZthenforeachcombination(denotedasγ)ofthenodesinZdoGeneratepatternβ=γ∪awithsupport=minimumsupportofnodesinγ;ifβ.
support>ξthenCallOutput(β);endendelseforeachbiinrdoGeneratepatternβ=bi∪awithsupport=bi.
support;ifβ.
support>ξthenCallOutput(β);endConstructβsconditionaldatabase;ConstructβsconditionalFP-treeTreeβ;ifTreeβ=φthenCallGrowth(Treeβ,β,ξ);endendendAlgorithm2:TheFP-GrowthAlgorithm.
Figure2:TheoverallPFPframework,showingvestagesofcomputation.
2.
2PFPOutlineGivenatransactiondatabaseDB,PFPusesthreeMapRe-duce[4]phasestoparallelizePF-Growth.
Figure2depictsthevestepsofPFP.
Step1:Sharding:DividingDBintosuccessivepartsandstoringthepartsonPdierentcomputers.
Suchdi-visionanddistributionofdataiscalledsharding,andeachpartiscalledashard1.
Step2:ParallelCounting(Section2.
3):DoingaMapRe-ducepasstocountthesupportvaluesofallitemsthatappearinDB.
EachmapperinputsoneshardofDB.
Thisstepimplicitlydiscoverstheitems'vocabularyI,whichisusuallyunknownforahugeDB.
TheresultisstoredinF-list.
Step3:GroupingItems:Dividingallthe|I|itemsonF-ListintoQgroups.
Thelistofgroupsiscalledgrouplist(G-list),whereeachgroupisgivenauniquegroup-id(gid).
AsF-listandG-listarebothsmallandthetimecomplexityisO(|I|),thisstepcancompleteonasinglecomputerinfewseconds.
Step4:ParallelFP-Growth(Section2.
4):ThekeystepofPFP.
ThissteptakesoneMapReducepass,wherethemapstageandreducestageperformdierentimpor-tantfunctions:Mapper–Generatinggroup-dependenttransactions:EachmapperinstanceisfedwithashardofDBgeneratedinStep1.
Beforeitprocessestransactionsintheshardonebyone,itreadstheG-list.
Withthemapperalgo-rithmdetailedinSection2.
4,itoutputsoneormorekey-valuepairs,whereeachkeyisagroup-idanditscorrespondingvalueisageneratedgroup-dependenttransaction.
Reducer–FP-Growthongroup-dependentshards:Whenallmapperinstanceshavenishedtheirwork,foreachgroup-id,theMapReduceinfrastructureautomaticallygroupsallcorrespondinggroup-dependenttransactionsintoashardofgroup-dependenttransactions.
Eachreducerinstanceisassignedtoprocessoneormoregroup-dependentshardonebyone.
Foreachshard,thereducerinstancebuildsalocalFP-treeandgrowthitsconditionalFP-treesrecursively.
Duringtherecursiveprocess,itmayoutputdiscoveredpatterns.
Step5:Aggregating(Section2.
5):AggregatingtheresultsgeneratedinStep4asournalresult.
AlgorithmsofthemapperandreduceraredescribedindetailinSection2.
5.
2.
3ParallelCountingCountingisaclassicalapplicationofMapReduce.
Be-causethemapperisfedwithshardsofDB,itsinputkey-valuepairwouldbelikekey,value=Ti,whereTiDBisatransaction.
Foreachitem,sayaj∈Ti,themapperoutputsakey-valuepairkey=aj,value=1.
Afterallmapperinstanceshavenished,foreachkeygeneratedbythemappers,theMapReduceinfrastructurecollectsthesetofcorrespondingvalues(hereitisasetof1MapReduceprovidesconvenientsoftwaretoolsforshard-ing.
Procedure:Mapper(key,value=Ti)foreachitemaiinTidoCallOutput(ai,1);endProcedure:Reducer(key=ai,value=S(ai))C←0;foreachitem1inTidoC←C+1;endCallOutput(null,ai+C);Algorithm3:TheParallelCountingAlgorithm1's),sayS(key),andfeedthereducerswithkey-valuepairskey,S(key).
Thereducerthussimplyoutputskey=null,value=key+sum(S(key)).
Itisnotdiculttoseethatkeyisanitemandvalueissupp(key).
Algorithm3presentsthepseudocodeofthersttwosteps:shardingandparallelcounting.
ThespacecomplexityofthisalgorithmisO(DBSize/P)andthetimecomplexityisO(DBSize/P).
2.
4ParallelFP-GrowthThisstepisthekeyinourPFPalgorithm.
OursolutionistoconverttransactionsinDBintosomenewdatabasesofgroup-dependenttransactionssothatlocalFP-treesbuiltfromdierentgroup-dependenttransactionsareindependentduringtherecursiveconditionalFP-treeconstructingpro-cess.
WedividethisstepintoMapperpartandReducerpartindetails.
Algorithm4presentsthepseudocodeofstep4,Paral-lelFP-Growth.
ThespacecomplexityofthisalgorithmisO(Max(NewDBSize))foreachmachine.
2.
4.
1GeneratingTransactionsforGroup-dependentDatabasesWheneachmapperinstancestarts,itloadstheG-listgen-eratedinStep3.
NotethatG-listisusuallysmallandcanbeheldinmemory.
Inparticular,themapperreadsandorganizesG-listasahashmap,whichmapseachitemontoitscorrespondinggroup-id.
Becauseinthisstep,amapperinstanceisalsofedwithashardofDB,theinputpairshouldbeintheformofkey,value=Ti.
ForeachTi,themapperperformsthefollowingtwosteps:1.
Foreachitemaj∈Ti,substituteajbycorrespondinggroup-id.
2.
Foreachgroup-id,saygid,ifitappearsinTi,locateitsright-mostappearance,sayL,andoutputakey-valuepairkey=gid,value={Ti[1].
.
.
Ti[L]}.
Afterallmapperinstanceshavecompleted,foreachdis-tinctvalueofkey,theMapReduceinfrastructurecollectscorrespondinggroup-dependenttransactionsasvaluevalue,andfeedreducersbykey-valuepairkey=key,value.
Herevalueisagroupofgroup-dependenttransactionscor-respondingtothesamegroup-id,andissaidagroup-dependentshard.
Notably,thisalgorithmmakesuseofaconceptintroducedin[6],patternendingat.
.
.
,toensurethatifagroup,forexample{a,c}or{b,e},isapattern,thissupportofthisProcedure:Mapper(key,value=Ti)LoadG-List;GenerateHashTableHfromG-List;a[]←Split(Ti);forj=|Ti|1to0doHashNum←getHashNum(H,a[j]);ifHashNum=NullthenDeleteallpairswhichhashvalueisHashNuminH;CallOutput(HashNum,a[0]+a[1]a[j]);endendProcedure:Reducer(key=gid,value=DBgid)LoadG-List;nowGroup←G-Listgid;LocalFPtree←clear;foreachTiinDB(gid)doCallinsertbuildfptree(LocalFPtree,Ti);endforeachaiinnowGroupdoDeneandclearasizeKmaxheap:HP;CallTopKFPGrowth(LocalFPtree,ai,HP);foreachviinHPdoCallOutput(null,vi+supp(vi));endendAlgorithm4:TheParallelFP-GrowthAlgorithmpatterncanbecountedonlywithinthegroup-dependentshardwithkey=gid,butdoesnotrelyonanyothershards.
2.
4.
2FP-GrowthonGroup-dependentShardsInthisstep,eachreducerinstancereadsandprocessespairsintheformofkey=gid,value=DB(gid)onebyone,whereeachDB(gid)isagroup-dependentshard.
ForeachDB(gid),thereducerconstructsthelocalFP-treeandrecursivelybuildsitsconditionalsub-treessimilartothetraditionalFP-Growthalgorithm.
Duringthisrecursiveprocess,itoutputsfoundpatterns.
TheonlydierencefromtraditionalFP-Growthalgorithmisthat,thepatternsarenotoutputdirectly,butintoamax-heapindexedbythesupportvalueofthefoundpattern.
So,foreachDB(gid),thereducermaintainsKmostlysupportedpatterns,whereKisthesizeofthemax-heapHP.
AfterthelocalrecursiveFP-Growthprocess,thereduceroutputseverypattern,v,inthemax-heapaspairsintheformofkey=null,value=v+supp(v)2.
5AggregatingTheaggregatingstepreadsfromtheoutputfromStep4.
Foreachitem,itoutputscorrespondingtop-Kmostlysup-portedpatterns.
Inparticular,themapperisfedwithpairsintheformofkey=null,value=v+supp(v).
Foreachaj∈v,itoutputsapairkey=aj,value=v+supp(v).
BecauseoftheautomaticcollectionfunctionoftheMapRe-duceinfrastructure,thereducerisfedwithpairsintheformofkey=aj,value=V(aj),whereV(aj)denotesthesetoftransitionsincludingitemaj.
ThereducerjustselectsfromS(aj)thetop-Kmostlysupportedpatternsandout-putsthem.
Procedure:Mapper(key,value=v+supp(v))foreachitemaiinvdoCallOutput(ai,v+supp(v));endProcedure:Reducer(key=ai,value=S(v+supp(v)))DeneandclearasizeKmaxheap:HP;foreachpatternvinv+supp(v)doif|HP|www.
baidu.
jp,andwww.
namaan.
net)arerelatedtoWebsearchenginesusedinJapan.
Figure7:Java-basedMiningUIdistributedenvironment.
InICPADS,2006.
[6]JiaweiHan,JianPei,andYiwenYin.
Miningfrequentpatternswithoutcandidategeneration.
InSIGMOD,2000.
[7]LiLiu,EricLi,YiminZhang,andZhizhongTang.
Optimizationoffrequentitemsetminingonmultiple-coreprocessor.
InVLDB,2007.
[8]IkoPramudionoandMasaruKitsuregawa.
Parallelfp-growthonpccluster.
InPAKDD,2003.
[9]AgrawalRakeshandRamakrishnanSrikant.
Fastalgorithmsforminingassociationrules.
InProc.
20thInt.
Conf.
VeryLargeDataBases,VLDB,1994.
[10]OsmarR.
Za¨ane,MohammadEl-Hajj,andPaulLu.
Fastparallelassociationruleminingwithoutcandidacygeneration.
InICDM,2001.
WebpagesDescriptionSupportwww.
openmoko.
orgCellphonesoftware2607www.
grandcentral.
comdownloadrelatedwebwww.
zyb.
comsites.
www.
simpy.
comFoursocial242www.
furl.
netbookmarkingserviceswww.
connotea.
orgwebsites,includingdel.
icio.
usdel.
ici.
os.
Thelastwww.
masternewmedia.
org/neoneisanarticleitws/2006/12/01/socialbookmdiscussthis.
arkingservicesandtools.
htmwww.
troovy.
comFiveonlinemaps.
240www.
agr.
comhttp://outside.
inwww.
wayfaring.
comhttp://ickrvision.
commail.
google.
com/mailWebsitesrelatedto204www.
google.
com/igGMailservice.
gdisk.
sourceforge.
netwww.
netvibes.
comwww.
trovando.
itSixfancysearch151www.
kartoo.
comengines.
www.
snap.
comwww.
clusty.
comwww.
aldaily.
comwww.
quintura.
comwwwl.
meebo.
comIntegratedinstant112www.
ebuddy.
commessagesoftwarewww.
plugoo.
comwebsites.
www.
easyhotel.
comTravelingagencyweb109www.
hostelz.
comsites.
www.
couchsurng.
comwww.
tripadvisor.
comwww.
kayak.
comwww.
easyjet.
com/it/prenotaItaliantraveling98www.
ryanair.
com/site/ITagencywebsites.
www.
edreams.
itwww.
expedia.
itwww.
volagratis.
com/vg1www.
skyscanner.
netwww.
google.
com/codesearchThreecodesearchweb98www.
koders.
comsitesandtwoarticleswww.
bigbold.
com/snippetstalkingaboutcodewww.
gotapi.
comsearch.
0xcc.
net/blog/archives/000043.
htmlwww.
google.
co.
jpFourJapaneseweb36www.
livedoor.
comsearchengines.
www.
baidu.
jpwww.
namaan.
netwww.
operator11.
comTV,mediastreaming34www.
joost.
comrelatedwebsites.
www.
keepvid.
comwww.
getdemocracy.
comwww.
masternewmedia.
orgwww.
technorati.
comFromthesewebsites,17www.
listible.
comyoucangetrelevantwww.
popurls.
comresourcequickly.
www.
trobar.
org/prosodyAllwebsitesare9librarianchick.
pbwiki.
comaboutliterature.
www.
quotationspage.
comwww.
visuwords.
comFigure5:Examplesofminingtag-tagsandwebpage-webpagesrelationships.
- antwww.baidu.jp相关文档
- 互联网www
- www.baidu.jp日本视频怎样看
- www.baidu.jp谁能推荐几个日本的资源网站、搜索引擎、音乐软件?
- www.baidu.jpbaidu 百度
- preloadedbaidu
RAKsmart美国洛杉矶独立服务器 E3-1230 16GB内存 限时促销月$76
RAKsmart 商家我们应该较多的熟悉的,主营独立服务器和站群服务器业务。从去年开始有陆续的新增多个机房,包含韩国、日本、中国香港等。虽然他们家也有VPS主机,但是好像不是特别的重视,价格上特价的时候也是比较便宜的1.99美元月付(年中活动有促销)。不过他们的重点还是独立服务器,毕竟在这个产业中利润率较大。正如上面的Megalayer商家的美国服务器活动,这个同学有需要独立服务器,这里我一并整理...
pigyun25元/月,香港云服务器仅起;韩国云服务器,美国CUVIP
pigyun怎么样?PIGYun成立于2019年,2021是PIGYun为用户提供稳定服务的第三年,期待我们携手共进、互利共赢。PIGYun为您提供:香港CN2线路、韩国CN2线路、美西CUVIP-9929线路优质IaaS服务。月付另有通用循环优惠码:PIGYun,获取8折循环优惠(永久有效)。目前,PIGYun提供的香港cn2云服务器仅29元/月起;韩国cn2云服务器仅22元/月起;美国CUVI...

简单测评v5.net的美国cn2云服务器:电信双程cn2+联通AS9929+移动直连
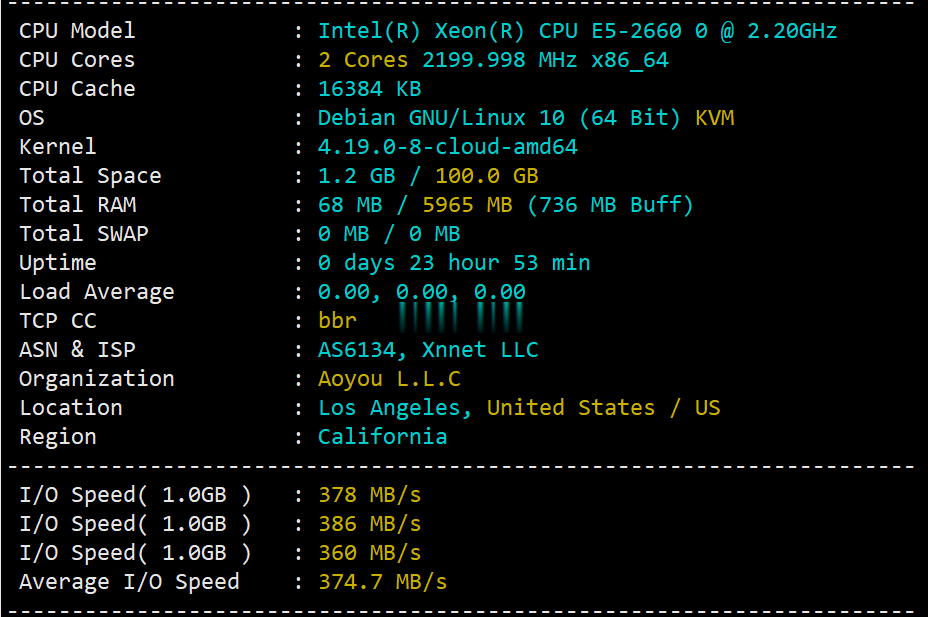
v5.net一直做独立服务器这块儿的,自从推出云服务器(VPS)以来站长一直还没有关注过,在网友的提醒下弄了个6G内存、2核、100G SSD的美国云服务器来写测评,主机测评给大家趟雷,让你知道v5.net的美国云服务器效果怎么样。本次测评数据仅供参考,有兴趣的还是亲自测试吧! 官方网站:https://v5.net/cloud.html 从显示来看CPU是e5-2660(2.2GHz主频),...
www.baidu.jp为你推荐
韩国空间 60g硬盘 密码泄露 seovip dropbox网盘 私有云存储 ftp教程 服务器硬件防火墙 什么是web服务器 全能空间 日本代理ip privatetracker 腾讯云平台 碳云 cdn加速 winserver2008r2 ping值 weblogic部署 时间同步服务器 服务器操作系统 更多