聚类分析法什么是聚类分析与数据挖掘?
聚类分析法 时间:2021-07-28 阅读:()
聚类分析的思想是什么
聚类分析指将物理或抽象对象的集合分组成为由类似的对象组成的多个类的分析过程。它是一种重要的人类行为。
聚类与分类的不同在于,聚类所要求划分的类是未知的。
聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
聚类分析的目标就是在相似的基础上收集数据来分类。
聚类源于很多领域,包括数学,计算机科学,统计学,生物学和经济学。
在不同的应用领域,很多聚类技术都得到了发展,这些技术方法被用作描述数据,衡量不同数据源间的相似性,以及把数据源分类到不同的簇中。
从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。
传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。
采用k-均值、k-中心点等算法的聚类分析工具已被加入到许多著名的统计分析软件包中,如SPSS、SAS等。
从机器学习的角度讲,簇相当于隐藏模式。
聚类是搜索簇的无监督学习过程。
与分类不同,无监督学习不依赖预先定义的类或带类标记的训练实例,需要由聚类学习算法自动确定标记,而分类学习的实例或数据对象有类别标记。
聚类是观察式学习,而不是示例式的学习。
从实际应用的角度看,聚类分析是数据挖掘的主要任务之一。
而且聚类能够作为一个独立的工具获得数据的分布状况,观察每一簇数据的特征,集中对特定的聚簇集合作进一步地分析。
聚类分析还可以作为其他算法(如分类和定性归纳算法)的预处理步骤。
聚类分析的区别
聚类与分类的不同在于,聚类所要求划分的类是未知的。聚类是将数据分类到不同的类或者簇这样的一个过程,所以同一个簇中的对象有很大的相似性,而不同簇间的对象有很大的相异性。
从统计学的观点看,聚类分析是通过数据建模简化数据的一种方法。
传统的统计聚类分析方法包括系统聚类法、分解法、加入法、动态聚类法、有序样品聚类、有重叠聚类和模糊聚类等。
采用k-均值、k-中心点等算法的聚类分析工具已被加入到许多著名的统计分析软件包中,如SPSS、SAS等。
从机器学习的角度讲,簇相当于隐藏模式。
聚类是搜索簇的无监督学习过程。
与分类不同,无监督学习不依赖预先定义的类或带类标记的训练实例,需要由聚类学习算法自动确定标记,而分类学习的实例或数据对象有类别标记。
聚类是观察式学习,而不是示例式的学习。
聚类分析是一种探索性的分析,在分类的过程中,人们不必事先给出一个分类的标准,聚类分析能够从样本数据出发,自动进行分类。
聚类分析所使用方法的不同,常常会得到不同的结论。
不同研究者对于同一组数据进行聚类分析,所得到的聚类数未必一致。
从实际应用的角度看,聚类分析是数据挖掘的主要任务之一。
而且聚类能够作为一个独立的工具获得数据的分布状况,观察每一簇数据的特征,集中对特定的聚簇集合作进一步地分析。
聚类分析还可以作为其他算法(e68a84e8a2ad62616964757a686964616f31333339666666如分类和定性归纳算法)的预处理步骤。
聚类分析与判别分析有什么区别与联系?
1.聚类分析与判别分析的区别与联系 都是研究分类的,在进行聚类分析前,对总体到底有几种类型不知道(研究分几类较为合适需从计算中加以调整)。判别分析则是在总体类型划分已知,对当前新样本判断它们属于哪个总体。
如我们对研究的多元数据的特征不熟悉,当然要进行聚类分析,才能考虑判别分析问题。
2.聚类分析分两种:Q型聚类(对样本的聚类),P型聚类(对变量的聚类) 聚类分析需要注意的是,一般小样本数据可以用系统聚类法,大样本数据一般用快速聚类法(K均值聚类法)。
需要根据统计量判断分几类比较合适,一般用R平方统计、伪F统计量等。
如用前者时,可以从R平方的变换看n个样品分成几类比较合适,如分为5类时,R平方为0.9,当分为四类时,其值减小较快,如R平方为0.4,则认为分五类比较合适。
另外,不同的分类方法产生的分类结果可能不同,要结合实际情况选出最优的分类方法。
3.判别分析 有Fisher判别,Bayes判别和逐步判别。
一般用Fisher判别即可,要考虑概率及误判损失最小的用Bayes判别,但变量较多时,一般先进行逐步判别筛选出有统计意义的变量,再结合实际情况选择用哪种判别方法。
聚类分析,方法解决数据,请高手指教
用聚类分析应该不能达到要求,聚类分析只是对变量或个案进行分类,比如将你的N个变量分成3类,告诉你哪个变量应该属于哪类。但是就算你知道哪个变量已经属于哪类,你怎么知道它和你的被解释变量,即融资行为选择的关系呢? 所以我认为,可以考虑这样来做(仅供参考): 因为你说变量很多,而且变量之间存在联系,那么可以考虑先做个因子分析,将你的N个变量变成少数几个因子,譬如3个因子,F1、F2和F3,然后将这3个因子和你的被解释变量融资行为选择,做个线性回归,这样可以消除直接用原始N个变量去建回归模型带来的多重共线性问题。
至于SPSS怎么操作,最好找本参考书,步骤过多,还是好好看看再做吧。
什么是聚类分析与数据挖掘?
聚类分析是数据挖掘中的一种,聚类就是把具有相似特性的个体聚在一起,形成一个类。类内的个体属性最接近,类间的属性最不相似。
常用的聚类算法有C—mean。
- 聚类分析法什么是聚类分析与数据挖掘?相关文档
- 聚类分析法k-均值聚类分析法是什么意思
- 聚类分析法如何运用聚类分析法?
- 聚类分析法什么叫聚类分析
印象云七夕促销,所有机器7折销售,美国CERA低至18元/月 年付217元!
印象云,成立于2019年3月的商家,公司注册于中国香港,国人运行。目前主要从事美国CERA机房高防VPS以及香港三网CN2直连VPS和美国洛杉矶GIA三网线路服务器销售。印象云香港三网CN2机房,主要是CN2直连大陆,超低延迟!对于美国CERA机房应该不陌生,主要是做高防服务器产品的,并且此机房对中国大陆支持比较友好,印象云美国高防VPS服务器去程是163直连、三网回程CN2优化,单IP默认给20...
酷番云78元台湾精品CN2 2核 1G 60G SSD硬盘
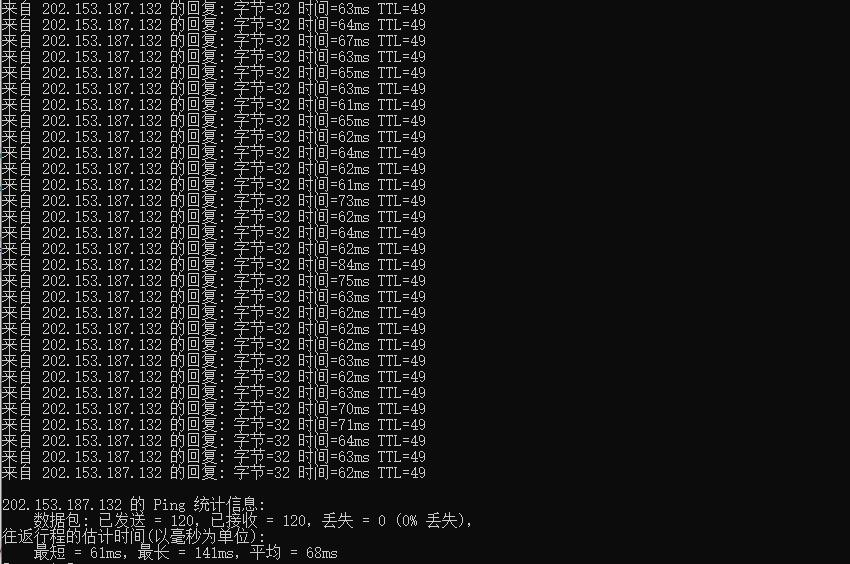
酷番云怎么样?酷番云就不讲太多了,介绍过很多次,老牌商家完事,最近有不少小伙伴,一直问我台湾VPS,比较难找好的商家,台湾VPS本来就比较少,也介绍了不少商家,线路都不是很好,有些需求支持Windows是比较少的,这里我们就给大家测评下 酷番云的台湾VPS,支持多个版本Linux和Windows操作系统,提供了CN2线路,并且还是原生IP,更惊喜的是提供的是无限流量。有需求的可以试试。可以看到回程...
HostKvm5.95美元起,香港、韩国可选
HostKvm发布了夏季特别促销活动,针对香港国际/韩国机房VPS主机提供7折优惠码,其他机房全场8折,优惠后2GB内存套餐月付仅5.95美元起。这是一家成立于2013年的国外主机服务商,主要提供基于KVM架构的VPS主机,可选数据中心包括日本、新加坡、韩国、美国、中国香港等多个地区机房,均为国内直连或优化线路,延迟较低,适合建站或者远程办公等。下面分享几款香港VPS和韩国VPS的配置和价格信息。...
聚类分析法为你推荐
-
达内学院成都达内学校在什么地方?linksys无线路由器设置linksys无线路由器为什么进不了设置菜单安卓系统软件删除安卓手机怎么卸载已经安装的各类软件?创业好项目论坛谁能提供点真实可靠的,网络创业赚钱项目?prepare的用法prepare和prepare for的区别魔兽世界密保卡怎么取消WOW密保卡罗振宇2017跨年演讲“时间的朋友”跨年演讲办了多少场,分别是什么主题?如何修改手机ip安卓手机怎么改ip地址如何修改手机ip手机如何更改ip地址?是不是和电脑一样更改ip地址呢?新浪短网址链接生成新浪微博怎么发图文带短连接连接到自己的网站?