robot txt在网站中的robots.txt是用来干什么的哦?对网站有什么影响啊?
robots.txt文件是什么,要怎么写?
搜索引擎机器人通过链接抵达互联网上的每个网页,并抓取网页信息。搜索引擎机器人在访问一个网站时,会首先检查该网站的根目录下是否有一个叫做 robots.txt的纯文本文件。当我们的网站有一些内容不想被搜索引擎收录,我们可以通过设置robots.txt文件告知搜索引擎机器人。 如果网站上没有禁止搜索引擎收录的内容,则不用设置robots.txt文件,或设置为空。 从SEO的角度,robots.txt文件是一定要设置的,原因: 网站上经常存在这种情况:不同的链接指向相似的网页内容。这不符合SEO上讲的“网页内容互异性原则”。采用robots.txt文件可以屏蔽掉次要的链接。网站改版或时原来不符合搜索引擎友好的链接需要全部屏蔽掉。采用robots.txt文件删除旧的链接符合搜索引擎友好。一些没有关键词的页面,比如本站的这个页面,屏蔽掉更好。一般情况下,站内的搜索结果页面屏蔽掉更好。 文章地址 /index.php/archives/278转载请保留链接地址如何创建 robots.txt 文件?
下面是一些robots.txt基本的用法:l 禁止所有搜索引擎访问网站的任何部分:
user-agent: *
disallow: /
l 允许所有的robot访问
user-agent: *
disallow:
或者也可以建一个空文件 "/robots.txt" file
l 禁止所有搜索引擎访问网站的几个部分(下例中的cgi-bin、tmp、private目录)
user-agent: *
disallow: /cgi-bin/
disallow: /tmp/
disallow: /private/
l 禁止某个搜索引擎的访问(下例中的badbot)
user-agent: badbot
disallow: /
l 只允许某个搜索引擎的访问(下例中的webcrawler)
user-agent: webcrawler
disallow:
user-agent: *
disallow: /
robots.txt文件有什么必要?
则不用设置robots.txt文件,或设置为空。如何设置robots.txt禁止或只允许搜索引擎抓取特定目录?
蛑辉市聿糠肿ト 注意:网站的robots.txt文件一定要存放在网站的根目录。搜索引擎来网站抓取内容的时候,首先会访问你网站根目录下的一个文本文件robots.txt,搜索引擎机器人通过robots.txt里的说明,来理解该网站是否可以全部抓取,或只允许部分抓取。注意:网站的robots.txt文件一定要存放在网站的根目录。robots.txt文件举例说明 禁止所有搜索引擎访问网站的任何内容 User-agent: * Disallow: / 禁止所有搜索引擎抓取某些特定目录 User-agent: * Disallow: /目录名1/ Disallow: /目录名2/ Disallow: /目录名3/ 允许访问特定目录中的部分url User-agent: * Allow: /158 Allow: /joke 禁止访问网站中所有的动态页面 User-agent: * Disallow: /*?* 仅允许百度抓取网页和gif格式图片,不允许抓取其他格式图片 User-agent: Baiduspider Allow: /*.gif$ Disallow: /*.jpg$ Disallow: /*.jpeg$ Disallow: /*.png$ Disallow: /*.bmp$ 1.屏蔽404页面 Disallow: /404.html 2.屏蔽死链 原来在目录为/158下的所有链接,因为目录地址的改变,现在都变成死链接了,那么我们可以用robots.txt把他屏蔽掉。 Disallow: /158/ 3.屏蔽动态的相似页面 假设以下这两个链接,内容其实差不多。 /XXX?123/123.html我们要屏掉/XXX?123 页面,代码如下: Disallow: /XXX? 4.告诉搜索引擎你的sitemap.xml地址 具体代码如下:robot.txt和robots.txt一样效果吗?
不一样的效果 robots.txt是搜索引擎爬行某个网站的入口文件 而robot.txt是网站的一个普通页面 两者是不同的。 By 郑义文网站robot.txt如何设置
robots.txt写作语法 首先,我们来看一个robots.txt范例:
# robots.txt file start # Robots.txt file from # All robots will spider the domain User-agent: * Disallow: /security/ Disallow: /admin/ Disallow: /admin.htm # End robots.txt file
有#号的都是注释,方便阅读。 User-agent就是搜索引擎的蜘蛛,后面用了*号,表示对所有的蜘蛛有效。 Disallow就是表示不允许抓取,后面的目录或者文件,表示禁止抓取的范围。
下面,我将列举一些robots.txt的具体用法: 允许所有的robot访问 User-agent: * Disallow: 或者也可以建一个空文件 "/robots.txt"
禁止所有搜索引擎访问网站的任何部分 User-agent: * Disallow: /
禁止所有搜索引擎访问网站的几个部分(下例中的01、02、03目录) User-agent: * Disallow: /01/ Disallow: /02/ Disallow: /03/
禁止某个搜索引擎的访问(下例中的BadBot) User-agent: BadBot Disallow: /
只允许某个搜索引擎的访问(下例中的Crawler) User-agent: Crawler Disallow:
robots.txt文件怎么建立?内容怎么写
大家先了解下robots.txt文件是什么,有什么作用。 搜索引擎爬去我们页面的工具叫做搜索引擎机器人,也生动的叫做“蜘蛛” 蜘蛛在爬去网站页面之前,会先去访问网站根目录下面的一个文件,就是robots.txt。这个文件其实就是给“蜘蛛”的规则,如果没有这个文件,蜘蛛会认为你的网站同意全部抓取网页。 Robots.txr文件是一个纯文本文件,可以告诉蜘蛛哪些页面可以爬取(收录),哪些页面不能爬取。 举个例子:建立一个名为robots.txt的文本文件,然后输入 User-agent: * 星号说明允许所有搜索引擎收录 Disallow: index.php? 表示不允许收录以index.php?前缀的链接,比如index.php?=865 Disallow: /tmp/ 表示不允许收录根目录下的tmp目录,包括目录下的文件,比如tmp/232.html 具体使用方法百度和谷歌都有解释,百度/search/robots.html Robots.txt文件可以帮助我们让搜索引擎删除已收录的页面,大概需要30-50天。如何制作robots.txt?
在网站根目录下创建robots文件 1、禁止所有搜索引擎访问网站的所有部分 User-agent: * Disallow: / 2、禁止百度索引你的网站 User-agent: Baiduspider Disallow: / 3、禁止Google索引你的网站 User-agent: Googlebot Disallow: / 4、禁止除Google外的一切搜索引擎索引你的网站 User-agent: Googlebot Disallow: User-agent: * Disallow: / 5、禁止除百度外的一切搜索引擎索引你的网站 User-agent: Baiduspider Disallow: User-agent: * Disallow: / 6、禁止蜘蛛访问某个目录 (例如禁止admincssimages被索引) User-agent: * Disallow: /css/ Disallow: /admin/ Disallow: /images/ 7、允许访问某个目录中的某些特定网址 User-agent: * Allow: /css/my Allow: /admin/html Allow: /images/index Disallow: /css/ Disallow: /admin/ Disallow: /images/ 在SEO优化过程中,对于蜘蛛的了解和控制至关重要,关于robot.txt希望能够帮助大家写出利于搜索引擎优化的robots.txt文件。怎么用英语介绍自己的机器人最多三句话
为您解答 My robot is very useful. It can help me clean the house and help me with my homework. I like it very much. 我的机器人很有用处。它可以帮忙做房屋清扫,还可以帮我辅导作业。我好喜欢它。robots.txt代码设置什么,如何设置它
robots.txt必须放置在一个站点的根目录下,而且文件名必须全部小写。robots.txt文件的格式 User-agent: 定义搜索引擎的类型 Disallow: 定义禁止搜索引擎收录的地址 Allow: 定义允许搜索引擎收录的地址 我们常用的搜索引擎类型有: (User-agent区分大小写) google蜘蛛:Googlebot 百度蜘蛛:Baiduspider yahoo蜘蛛:Yahoo!slurp alexa蜘蛛:ia_archiver bing蜘蛛:MSNbot altavista蜘蛛:scooter lycos蜘蛛:lycos_spider_(t-rex) alltheweb蜘蛛:fast-webcrawler inktomi蜘蛛: slurp Soso蜘蛛:Sosospider Google Adsense蜘蛛:Mediapartners-Google 有道蜘蛛:YoudaoBot robots.txt文件的写法 User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符 Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录 Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录 Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录 Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。 Disallow: /*?* 禁止访问网站中所有的动态页面 Disallow: /jpg$ 禁止抓取网页所有的.jpg格式的图片 Disallow:/ab/adc.html 禁止爬去ab文件夹下面的adc.html文件。 Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录 Allow: /tmp 这里定义是允许爬寻tmp的整个目录 Allow: .htm$ 仅允许访问以".htm"为后缀的URL。 Allow: .gif$ 允许抓取网页和gif格式图片 robots.txt文件用法举例 例1. 禁止所有搜索引擎访问网站的任何部分 User-agent: * Disallow: / 实例分析:淘宝网的 Robots.txt文件 User-agent: Baiduspider Disallow: / User-agent: baiduspider Disallow: / 很显然淘宝不允许百度的机器人访问其网站下其所有的目录。 例2. 允许所有的robot访问 (或者也可以建一个空文件 “/robots.txt” file) User-agent: * Allow: 例3. 禁止某个搜索引擎的访问 User-agent: BadBot Disallow: / 例4. 允许某个搜索引擎的访问 User-agent: Baiduspider allow:/ 例5.一个简单例子 在这个例子中,该网站有三个目录对搜索引擎的访问做了限制,即搜索引擎不会访问这三个目录。 需要注意的是对每一个目录必须分开声明,而不要写成 “Disallow: /cgi-bin/ /tmp/”。 User-agent:后的*具有特殊的含义,代表“any robot”,所以在该文件中不能有“Disallow: /tmp/*” or “Disallow:*.gif”这样的记录出现。 User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /~joe/ Robot特殊参数: 允许 Googlebot: 如果您要拦截除 Googlebot 以外的所有漫游器不能访问您的网页,可以使用下列语法: User-agent: Disallow: / User-agent: Googlebot Disallow: Googlebot 跟随指向它自己的行,而不是指向所有漫游器的行。 “Allow”扩展名: Googlebot 可识别称为“Allow”的 robots.txt 标准扩展名。其他搜索引擎的漫游器可能无法识别此扩展名,因此请使用您感兴趣的其他搜索引擎进行查找。“Allow”行的作用原理完全与“Disallow”行一样。只需列出您要允许的目录或页面即可。 您也可以同时使用“Disallow”和“Allow”。例如,要拦截子目录中某个页面之外的其他所有页面,可以使用下列条目: User-agent: Googlebot Disallow: /folder1/ Allow: /folder1/myfile.html 这些条目将拦截 folder1 目录内除 myfile.html 之外的所有页面。 如果您要拦截 Googlebot 并允许 Google 的另一个漫游器(如 Googlebot-Mobile),可使用”Allow”规则允许该漫游器的访问。例如: User-agent: Googlebot Disallow: / User-agent: Googlebot-Mobile Allow: 使用 * 号匹配字符序列: 您可使用星号 (*) 来匹配字符序列。例如,要拦截对所有以 private 开头的子目录的访问,可使用下列条目: User-Agent: Googlebot Disallow: /private*/ 要拦截对所有包含问号 (?) 的网址的访问,可使用下列条目: User-agent: * Disallow: /*?* 使用 $ 匹配网址的结束字符 您可使用 $ 字符指定与网址的结束字符进行匹配。例如,要拦截以 .asp 结尾的网址,可使用下列条目: User-agent: Googlebot Disallow: /*.asp$ 您可将此模式匹配与 Allow 指令配合使用。例如,如果 ? 表示一个会话 ID,您可排除所有包含该 ID 的网址,确保 Googlebot 不会抓取重复的网页。但是,以 ? 结尾的网址可能是您要包含的网页版本。在此情况下,可对 robots.txt 文件进行如下设置: User-agent: * Allow: /*?$ Disallow: /*? Disallow: / *? 一行将拦截包含 ? 的网址(具体而言,它将拦截所有以您的域名开头、后接任意字符串,然后是问号 (?),而后又是任意字符串的网址)。 Allow: /*?$ 一行将允许包含任何以 ? 结尾的网址(具体而言,它将允许包含所有以您的域名开头、后接任意字符串,然后是问号 (?),问号之后没有任何字符的网址)。 Robots Meta标签 Robots.txt文件主要是限制整个站点或者目录的搜索引擎访问情况,而Robots Meta标签则主要是针对一个个具体的页面。和其他的META标签(如使用的语言、页面的描述、关键词等)一样,Robots Meta标签也是放在页面中,专门用来告诉搜索引擎ROBOTS如何抓取该页的内容。 Robots Meta标签中没有大小写之分,name=”Robots”表示所有的搜索引擎,可以针对某个具体搜索引擎写为name=”BaiduSpider”。content部分有四个指令选项:index、noindex、follow、nofollow,指令间以“,”分隔。 index指令告诉搜索机器人抓取该页面; follow指令表示搜索机器人可以沿着该页面上的链接继续抓取下去; Robots Meta标签的缺省值是index和follow,只有inktomi除外,对于它,缺省值是index、nofollow。 需要注意的是: 上述的robots.txt和Robots Meta标签限制搜索引擎机器人(ROBOTS)抓取站点内容的办法只是一种规则,需要搜索引擎机器人的配合才行,并不是每个ROBOTS都遵守的。 目前看来,绝大多数的搜索引擎机器人都遵守robots.txt的规则,而对于RobotsMETA标签,目前支持的并不多,但是正在逐渐增加,如著名搜索引擎GOOGLE就完全支持,而且GOOGLE还增加了一个指令“archive”,可以限制GOOGLE是否保留网页快照。robot.txt的使用技巧
每当用户试图访问某个不存在的URL时,服务器都会在日志中记录404错误(无法找到文件)。每当搜索蜘蛛来寻找并不存在的robots.txt文件时,服务器也将在日志中记录一条404错误,所以你应该在网站中添加一个robots.txt。 网站管理员必须使搜索引擎机器人程序远离服务器上的某些目录,以保证服务器性能。比如:大多数网站服务器都有程序储存在“cgi-bin”目录下,因此在robots.txt文件中加入“Disallow: /cgi-bin”是个好主意,这样能够避免所有程序文件都被蜘蛛索引,以达到节省服务器资源的效果。 一般网站中不需要蜘蛛抓取的文件有:后台管理文件、程序脚本、附件、数据库文件、编码文件、样式表文件、模板文件、导航图片和背景图片等等。 下面是VeryCMS里的robots.txt文件: User-agent: * Disallow: /admin/ 后台管理文件 Disallow: /require/程序文件 Disallow: /attachment/ 附件 Disallow: /images/ 图片 Disallow: /data/数据库文件 Disallow: /template/ 模板文件 Disallow: /css/ 样式表文件 Disallow: /lang/ 编码文件 Disallow: /script/脚本文件 Disallow: /js/js文件 如果你的网站是动态网页,并且你为这些动态网页创建了静态副本,以供搜索蜘蛛更容易抓取。那么你需要在robots.txt文件里设置避免动态网页被蜘蛛索引,以保证这些网页不会被视为是网站重复的内容。 robots.txt文件里还可以直接包括在sitemap文件的链接。就像这样: Sitemap: /sitemap.xml 目 前对此表示支持的搜索引擎公司有Google, Yahoo, Ask and MSN。而中文搜索引擎公司,显然不在这个圈子内。这样做的好处就是,站长不用到每个搜索引擎的站长工具或者相似的站长部分,去提交自己的sitemap文件,搜索引擎的蜘蛛自己就会抓取robots.txt文件,读取其中的sitemap路径,接着抓取其中相链接的网页。 合理使用robots.txt文件还能避免访问时出错。比如,不能让搜索者直接进入购物车页面。因为没有理由使购物车被收录,所以你可以在robots.txt文件里设置来阻止搜索者直接进入购物车页面。请问robots.txt这个文件怎么用
例1. 禁止所有搜索引擎访问网站的任何部分 User-agent: * Disallow: / 例2. 允许所有的robot访问 (或者也可以建一个空文件 "/robots.txt") User-agent: * Disallow: 或者 User-agent: * Allow: / 例3. 仅禁止baiduspider访问您的网站 User-agent: baiduspider Disallow: / 例4. 仅允许baiduspider访问您的网站 User-agent: baiduspider Disallow: User-agent: * Disallow: / 例5.禁止spider访问特定目录 在这个例子中,该网站有三个目录对搜索引擎的访问做了限制,即robot不会访问这三个目录。需要注意的是对每一个目录必须分开声明,而不能写成 "Disallow: /cgi-bin/ /tmp/"。 User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /~joe/ 例6. 允许访问特定目录中的部分url User-agent: * Allow: /cgi-bin/see Allow: /tmp/hi Allow: /~joe/look Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /~joe/ 例7. 使用"*"限制访问url 禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。 User-agent: * Disallow: /cgi-bin/*.htm 例8. 使用"$"限制访问url 仅允许访问以".htm"为后缀的URL。 User-agent: * Allow: .htm$ Disallow: / 例9. 禁止访问网站中所有的动态页面 User-agent: * Disallow: /*?*robot.txt作用是什么?
搜索引擎通过一种程序robot(又称spider),自动访问互联网上的网页并获取网页信 息。您可以在您的网站中创建一个纯文本文件robots.txt,在这个文件中声明该网站中不想被robot 访问的部分,这样,该网站的部分或全部内容就可以不被搜索引擎收录了,或者指定搜 索引擎只收录指定的内容。网站中的robots.txt文件有什么作用
原发布者:飞瑞敖 Robots.txt文件是什么有什么用1、Robots.txt文件是什么????首先SEO博客要和大家弄清楚robots.txt的概念问题,带有txt后缀的文件是纯文本文档,robots是机器人的意思,也就是说,robots.txt文件是给搜索引擎蜘蛛看的纯文本文件。它告诉搜索引擎哪些网页允许抓取、索引并在搜索结果中显示,哪些网页是被禁止抓取的。搜索引擎蜘蛛来访问你的网站页面的,首先会查看网站根目录下是否有robots.txt文件,robots.txt文件就是起到这个作用的。????我们都知道淘宝网是屏蔽百度的,靠的就是robots.txt文件。文件是这样书写的:User-agent:BaiduspiderDisallow:/User-agent:baiduspiderDisallow:/2.robots.txt的作用?????通过设置屏蔽搜索引擎,使之不必要页面被收录,可以大大降低抓取页面所占用的网站带宽,大型网站尤为明显了。设置robots.txt文件可以指定某个搜索引擎不去索引不想被收录的URL,比如我们通过url重写将动态URL静态化为永久固定链接,就可以通过robots.txt设置权限,阻止某些搜索引擎索引那些动态网址,网站重复页面将减少,有利于SEO优化。3.robots.txt怎么写?????下面以WordPress博客来作举例。如robots.txt文件里写入以下代码:User-agent:*Disallow:Allow:/????robots.txt写法中应该注意的几点。????1、robots.txt必须上传到网站根名录下,不能放在子目录下;?????2、robots.txt,Disallow等必须注意大小写,不能变化;????3robots.txt有什么作用
robots.txt是与百度蜘蛛对话的文件,可以有效的屏蔽一些你不想要百度蜘蛛进行爬取的文件以及网页,这个设置与否要看个人网站和个人需求了。例如我的网站,其中有个论坛,我就把所有动态网页都禁止爬行收录了,还有一些会员的注册信息、个人档案的都给屏蔽了!robots.txt问题
robots.txt文件的格式 "robots.txt"文件包含一条或更多的记录,这些记录通过空行分开(以CR,CR/NL, or NL作为结束符),每一条记录的格式如下所示: "<field>:<optionalspace><value><optionalspace>"。 在该文件中可以使用#进行注解,具体使用方法和UNIX中的惯例一样。该文件中的记录通常以一行或多行User-agent开始,后面加上若干Disallow和Allow行,详细情况如下: User-agent: 该项的值用于描述搜索引擎robot的名字。在"robots.txt"文件中,如果有多条User-agent记录说明有多个robot会受到"robots.txt"的限制,对该文件来说,至少要有一条User-agent记录。如果该项的值设为*,则对任何robot均有效,在"robots.txt"文件中,"User-agent:*"这样的记录只能有一条。如果在"robots.txt"文件中,加入"User-agent:SomeBot"和若干Disallow、Allow行,那么名为"SomeBot"只受到"User-agent:SomeBot"后面的Disallow和Allow行的限制。 Disallow: 该项的值用于描述不希望被访问的一组URL,这个值可以是一条完整的路径,也可以是路径的非空前缀,以Disallow项的值开头的URL不会被robot访问。例如"Disallow:/help"禁止robot访问/help.html、/helpabc.html、/help/index.html,而"Disallow:/help/"则允许robot访问/help.html、/helpabc.html,不能访问/help/index.html。"Disallow:"说明允许robot访问该网站的所有url,在"/robots.txt"文件中,至少要有一条Disallow记录。如果"/robots.txt"不存在或者为空文件,则对于所有的搜索引擎robot,该网站都是开放的。 Allow: 该项的值用于描述希望被访问的一组URL,与Disallow项相似,这个值可以是一条完整的路径,也可以是路径的前缀,以Allow项的值开头的URL是允许robot访问的。例如"Allow:/hibaidu"允许robot访问/hibaidu.htm、/.html、/.html。一个网站的所有URL默认是Allow的,所以Allow通常与Disallow搭配使用,实现允许访问一部分网页同时禁止访问其它所有URL的功能。 需要特别注意的是Disallow与Allow行的顺序是有意义的,robot会根据第一个匹配成功的Allow或Disallow行确定是否访问某个URL。 使用"*"和"$": Baiduspider支持使用通配符"*"和"$"来模糊匹配url。 "$" 匹配行结束符。 "*" 匹配0或多个任意字符。robots.txt是什么,有什么用
robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。Robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。 当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。 robots.txt必须放置在一个站点的根目录下,而且文件名必须全部小写。如何设置robots.txt禁止或只允许搜索引擎抓取特定目录?
网站的robots.txt文件一定要存放在网站的根目录。搜索引擎来网站抓取内容的时候,首先会访问你网站根目录下的一个文本文件robots.txt,搜索引擎机器人通过robots.txt里的说明,来理解该网站是否可以全部抓取,或只允许部分抓取。注意:网站的robots.txt文件一定要存放在网站的根目录。robots.txt文件举例说明 禁止所有搜索引擎访问网站的任何内容 User-agent: * Disallow: / 禁止所有搜索引擎抓取某些特定目录 User-agent: * Disallow: /目录名1/ Disallow: /目录名2/ Disallow: /目录名3/ 允许访问特定目录中的部分url User-agent: * Allow: /158 Allow: /joke 禁止访问网站中所有的动态页面 User-agent: * Disallow: /*?* 仅允许百度抓取网页和gif格式图片,不允许抓取其他格式图片 User-agent: Baiduspider Allow: /*.gif$ Disallow: /*.jpg$ Disallow: /*.jpeg$ Disallow: /*.png$ Disallow: /*.bmp$ 1.屏蔽404页面 Disallow: /404.html 2.屏蔽死链 原来在目录为/158下的所有链接,因为目录地址的改变,现在都变成死链接了,那么我们可以用robots.txt把他屏蔽掉。 Disallow: /158/ 3.屏蔽动态的相似页面 假设以下这两个链接,内容其实差不多。 /XXX?123/123.html我们要屏掉/XXX?123 页面,代码如下: Disallow: /XXX? 4.告诉搜索引擎你的sitemap.xml地址Robots.txt是什么?
Robots.txt 是个纯文本文件,当一个搜索robot访问一个站点时,他首先爬行来检查该站点根目录下是否存在robot.txt,如果存在,根据文件内容来确定访问范围,如果没有(为Null),搜索robot就沿着链接抓取。如何查看他网站的robot.txt文件
网站后面加上robots.txt 例如 /robots.txt 这样就可以查询到网站的tobot.txt文件了。特别需要注意的是,后面跟的是robots.txt,不要少了 “s”在网站中的robots.txt是用来干什么的哦?对网站有什么影响啊?
本文我们将看一看机器人拒绝标准(Robots Exclusion Standard),这听起来像是科幻小说里的内容,其实它是一个用于阻止搜索引擎者蜘蛛(spider)或机器人(robots)访问网站内容的一个工具。 Robots.txt是一个纯文本文件,通过该文件可以控制搜索引擎蜘蛛(spider)访问网站的内容,必须将其放在网站的根目录才可以正常使用,且文件名应该为小写,比如“/robots.txt”,即使您的网站没有设置对搜索引擎访问的限制,最好也能放一个空白的robots.txt文件在网站根目录下。 创建一个Robots.txt 如果不希望任何机器人(robots)或者蜘蛛(spider)索引网站,可以在Robots.txt里键入如下规则: User-agent: * Disallow: / 在这个例子中,"*"是个通配符,表示此规则被应用到所有的搜索引擎(Search Engine),此通配符是 一个特殊的符号表示一切内容,一个典型的用法:如果键入 “d*ng” ,则计算机可以解释为: “ding”,"dang","dong","dung","dzing" 等更多的内容会符合。 Disallow表示不允许被搜索引擎访问的网页文件或者目录,对它的设置正确与否非常重要,如果设置 不当,也许会对网站造成极大的损失。 如果允许搜索引擎蜘蛛(spider)访问网站的全部内容,则设置方法如下: User-agent: * Disallow: 以上设置方法中,User-agent仍然是使用通配符*表示所有搜索引擎蜘蛛,Disallow为空表示允许搜索 引擎蜘蛛访问网站所有的文件,即不对搜索引擎做任何限制,完全敞开了让蜘蛛们任意访问。 如果让所有搜索引擎机器人不访问和索引网站根目录下的images目录,则可以使用如下写法: User-agent: * Disallow: /images/ 上面的例子表示让所有搜索引擎蜘蛛远离/images/目录及目录下所有的文件。注意/images/后的“/” ,如果是/images的话,则比如/images.html , /images/index.html都不允许搜索引擎蜘蛛访问。 如果不允许搜索引擎蜘蛛访问指定的一个文件,则设置方法如下: User-agent: * Disallow: /images/biggorillaonatricycle.jpg 这时搜索引擎蜘蛛会扫描访问除了images目录下biggorillaonatricycle.jpg的所有文件,但是如果其 它目录比如imagestwo下有biggorillaonatricycle.jpg这张图片的话,那么搜索引擎蜘蛛一样会访问 到,因此我们可以使用如下设置方法: User-agent: * Disallow: /images/biggorillaonatricycle.jpg Disallow: /imagestwo/biggorillaonatricycle.jpg 下面的设置方法也不错: User-agent: * Disallow: /images/ Disallow: /imagestwo/ Disallow: /aboutus/ 上面例子告诉搜索引擎蜘蛛忽视指定的三个目录,但是也可以同时指定目录和文件: User-agent: * Disallow: /images/ Disallow: /imagestwo/ Disallow: /aboutus/wearereallyevil.html 限制指定的搜索引擎蜘蛛(spider)/机器人(Robots) 之前说到如何限制搜索引擎蜘蛛访问网站文件,下面开始如何限制指定的搜索引擎蜘蛛访问网站文件 。 如果想告诉某一个搜索引擎蜘蛛忽视网站的所有目录和文件,则使用如下设置方法: User-agent: Google-Bot Disallow: / Google-Bot表示为Google的搜索引擎蜘蛛/机器人 slurp 表示为Yahoo的搜索引擎蜘蛛/机器人 当然也可以告诉一个指定的搜索引擎蜘蛛,忽视网站的一个指定目录和文件,设置方法如下: User-agent: Google-Bot Disallow: /images/ Disallow: /secrets/globaldomination.html User-agent: slurp Disallow: /images/ Disallow: /secrets/globaldomination.html Disallow: /tmp/ User-agent: slurp Disallow: /images/ Disallow: /secrets/globaldomination.html User-agent: Google-Bot Disallow: /images/ Disallow: /secrets/globaldomination.html Disallow: /cgi-bin/ 参考资料:/index.php/archives/9/ 来自:
- robot txt在网站中的robots.txt是用来干什么的哦?对网站有什么影响啊?相关文档
创梦网络-四川一手资源高防大带宽云服务器,物理机租用,机柜资源,自建防火墙,雅安最高单机700G防护,四川联通1G大带宽8.3W/年,无视UDP攻击,免费防CC
? ? ? ?创梦网络怎么样,创梦网络公司位于四川省达州市,属于四川本地企业,资质齐全,IDC/ISP均有,从创梦网络这边租的服务器均可以****,属于一手资源,高防机柜、大带宽、高防IP业务,另外创梦网络近期还会上线四川联通大带宽,四川联通高防IP,一手整CIP段,四川电信,联通高防机柜,CN2专线相关业务。成都优化线路,机柜租用、服务器云服务器租用,适合建站做游戏,不须要在套CDN,全国访问快...

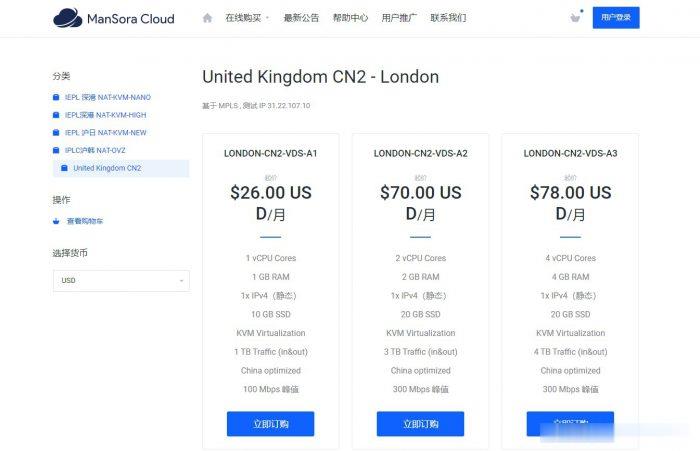
ManSora:英国CN2 VPS,1核/1GB内存/10GB SSD/1TB流量/100Mbps/KVM,$18.2/月
mansora怎么样?mansora是一家国人商家,主要提供沪韩IEPL、沪日IEPL、深港IEPL等专线VPS。现在新推出了英国CN2 KVM VPS,线路为AS4809 AS9929,可解锁 Netflix,并有永久8折优惠。英国CN2 VPS,$18.2/月/1GB内存/10GB SSD空间/1TB流量/100Mbps端口/KVM,有需要的可以关注一下。点击进入:mansora官方网站地址m...
CloudCone中国春节优惠活动限定指定注册时间年付VPS主机$13.5
CloudCone 商家产品还是比较有特点的,支持随时的删除机器按时间计费模式,类似什么熟悉的Vultr、Linode、DO等服务商,但是也有不足之处就在于机房太少。商家的活动也是经常有的,比如这次中国春节期间商家也是有提供活动,比如有限定指定时间段之前注册的用户可以享受年付优惠VPS主机,比如年付13.5美元。1、CloudCone新年礼物限定款仅限2019年注册优惠购买,活动开始时间:1月31...

-
快速网怎样能让女人迅速达到性高潮?色空间求图像处理中颜色空间的介绍,越详细越好查杀木马怎样手动查杀木马解码器有什么用视频编码器和视频解码器有什么不同上海网络维护公司上海博好网络科技有限公司的介绍企业电子邮箱注册电子邮箱怎么注册信息发布管理系统信息发布系统的功能有哪些?qq空间播放器代码qq空间免费播放器代码垂直型网站水平型、垂直型、综合型电子商务网站的主要特征是什么?公司注册如何办理我想注册一家公司,怎么注册?