prototypeavmask.net
avmask.net 时间:2021-03-25 阅读:()
CRNet:Cross-ReferenceNetworksforFew-ShotSegmentationWeideLiu1,ChiZhang1,GuoshengLin1,FayaoLiu21NanyangTechnologicalUniversity,Singapore2A*Star,SingaporeE-mail:weide001@e.
ntu.
edu.
sg,chi007@e.
ntu.
edu.
sg,gslin@ntu.
edu.
sgAbstractOverthepastfewyears,state-of-the-artimagesegmen-tationalgorithmsarebasedondeepconvolutionalneuralnetworks.
Torenderadeepnetworkwiththeabilitytoun-derstandaconcept,humansneedtocollectalargeamountofpixel-levelannotateddatatotrainthemodels,whichistime-consumingandtedious.
Recently,few-shotsegmenta-tionisproposedtosolvethisproblem.
Few-shotsegmenta-tionaimstolearnasegmentationmodelthatcanbegener-alizedtonovelclasseswithonlyafewtrainingimages.
Inthispaper,weproposeacross-referencenetwork(CRNet)forfew-shotsegmentation.
Unlikepreviousworkswhichonlypredictthemaskinthequeryimage,ourproposedmodelconcurrentlymakepredictionsforboththesupportimageandthequeryimage.
Withacross-referencemecha-nism,ournetworkcanbetterndtheco-occurrentobjectsinthetwoimages,thushelpingthefew-shotsegmentationtask.
Wealsodevelopamaskrenementmoduletorecurrentlyre-nethepredictionoftheforegroundregions.
Forthek-shotlearning,weproposetonetunepartsofnetworkstotakeadvantageofmultiplelabeledsupportimages.
ExperimentsonthePASCALVOC2012datasetshowthatournetworkachievesstate-of-the-artperformance.
1.
IntroductionDeepneuralnetworkshavebeenwidelyappliedtovi-sualunderstandingtasks,e.
g.
,objectiondetection,seman-ticsegmentationandimagecaptioning,sincethehugesuc-cessinImageNetclassicationchallenge[4].
Duetoitsdata-drivingproperty,large-scalelabeleddatasetsareof-tenrequiredtoenablethetrainingofdeepmodels.
How-ever,collectinglabeleddatacanbenotoriouslyexpensiveintaskslikesemanticsegmentation,instancesegmentation,andvideosegmentation.
Moreover,datacollectingisusu-allyforasetofspeciccategories.
KnowledgelearnedinpreviousclassescanhardlybetransferredtounseenclassesCorrespondingauthor:G.
Lin(e-mail:gslin@ntu.
edu.
sg)Figure1.
ComparisonofourproposedCRNetagainstpreviouswork.
Previouswork(upperpart)unilaterallyguidethesegmen-tationofqueryimageswithsupportimages,whileinourCRNet(lowerpart)supportandqueryimagescanguidethesegmentationofeachother.
directly.
Directlynetuningthetrainedmodelsstillneedsalargeamountofnewlabeleddata.
Few-shotlearning,ontheotherhand,isproposedtosolvethisproblem.
Inthefew-shotlearningtasks,modelstrainedonprevioustasksareexpectedtogeneralizetounseentaskswithonlyafewlabeledtrainingimages.
Inthispaper,wetargetatfew-shotimagesegmentation.
Givenanovelobjectcategory,few-shotsegmentationaimstondtheforegroundregionsofthiscategoryonlyseeingafewlabeledexamples.
Manypreviousworksformulatethefew-shotsegmentationtaskasaguidedsegmentationtask.
Theguidanceinformationisextractedfromthelabeledsup-portsetfortheforegroundpredictioninthequeryimage,whichisusuallyachievedbyanunsymmetricaltwo-branchnetworkstructure.
Themodelisoptimizedwiththegroundtruthquerymaskasthesupervision.
Inourwork,wearguethattherolesofqueryandsup-portsetscanbeswitchedinafew-shotsegmentationmodel.
Specically,thesupportimagescanguidethepredictionof4165thequeryset,andconversely,thequeryimagecanalsohelpmakepredictionsofthesupportset.
Inspiredbytheimageco-segmentationliterature[7,12,1],weproposeasymmet-ricCross-ReferenceNetworkthattwoheadsconcurrentlymakepredictionsforboththequeryimageandthesupportimage.
ThedifferenceofthenetworkdesignwithpreviousworksisshowninFig.
1.
Thekeycomponentinournet-workdesignisthecross-referencemodulewhichgeneratesthereinforcedfeaturerepresentationsbycomparingtheco-occurrentfeaturesintwoimages.
Thereinforcedrepresen-tationsareusedforthedownstreamforegroundpredictionsintwoimages.
Inthemeantime,thecross-referencemod-ulealsomakespredictionsofco-occurrentobjectsinthetwoimages.
Thissub-taskprovidesanauxiliarylossinthetrainingphasetofacilitatethetrainingofthecross-referencemodule.
Asthereexistshugevarianceintheobjectappearance,miningforegroundregionsinimagescanbeamulti-stepprocess.
WedevelopaneffectiveMaskRenementModuletoiterativelyreneourpredictions.
Intheinitialprediction,thenetworkisexpectedtolocatehigh-condenceseedre-gions.
Then,thecondencemap,intheformofprobabilitymap,issavedasthecacheinthemoduleandisusedforlaterpredictions.
Weupdatethecacheeverytimewemakeanewprediction.
Afterrunningthemaskrenementmoduleforafewsteps,ourmodelcanbetterpredicttheforegroundre-gions.
Weempiricallydemonstratethatsuchalight-weightmodulecansignicantlyimprovetheperformance.
Whenitcomestothek-shotimagesegmentationwheremorethanonesupportimagesareprovided,previousmeth-odsoftenuse1-shotmodeltomakepredictionswitheachsupportimageindividuallyandfusetheirfeaturesorpre-dictedmasks.
Inourpaper,weproposetonetunepartsofournetworkwiththelabeledsupportexamples.
Asournetworkcanmakepredictionsforbothtwoimageinputsatatime,wecanuseatmostk2imagepairstonetuneournetwork.
Anadvantageofournetuningbasedmethodisthatitcanbenetfromtheincreasingnumberofsupportim-ages,andthusconsistentlyincreasestheaccuracy.
Incom-parison,thefusion-basedmethodscaneasilysaturatewhenmoresupportimagesareprovided.
Inourexperiment,wevalidateourmodelinthe1-shot,5-shot,and10-shotset-tings.
Themaincontributionsofthispaperarelistedasfollows:Weproposeanovelcross-referencenetworkthatcon-currentlymakespredictionsforboththequerysetandthesupportsetinthefew-shotimagesegmentationtask.
Byminingtheco-occurrentfeaturesintwoim-ages,ourproposednetworkcaneffectivelyimprovetheresults.
Wedevelopamaskrenementmodulewithcondencecachethatisabletorecurrentlyrenethepredictedre-sults.
Weproposeanetuningschemefork-shotlearning,whichturnsouttobeaneffectivesolutiontohandlemultiplesupportimages.
ExperimentsonthePASCALVOC2012demonstratethatourmethodsignicantlyoutperformsbaselinere-sultsandachievesnewstate-of-the-artperformanceonthe5-shotsegmentationtask.
2.
RelatedWork2.
1.
FewshotlearningFew-shotlearningaimstolearnamodelwhichcanbeeasilytransferredtonewtaskswithlimitedtrainingdataavailable.
Few-shotlearningiswidelyexploredinimageclassicationtasks.
Previousmethodscanberoughlydi-videdintotwocategoriesbasedonwhetherthemodelneedsnetuningatthetestingtime.
Innon-netunedmethods,parameterslearnedatthetrainingtimearekeptxedatthetestingstage.
Forexample,[19,22,21,24]aremetricbasedapproacheswhereanembeddingencoderandadistancemetricarelearnedtodeterminetheimagepairsimilarity.
Thesemethodshavetheadvantageoffastinferencewith-outfurtherparameteradaptions.
However,whenmultiplesupportimagesareavailable,theperformancecanbecomesaturateeasily.
Innetuningbasedmethods,themodelpa-rametersneedtobeadaptedtothenewtasksforpredictions.
Forexample,in[3],theydemonstratethatbyonlynetun-ingthefullyconnectedlayer,modelslearnedontrainingclassescanyieldstate-of-the-artfew-shotperformanceonnewclasses.
Inourwork,weuseanon-netunedfeed-forwardmodeltohandle1-shotlearningandadoptmodelnetuninginthek-shotsettingtobenetfrommultiplela-beledsupportimages.
Thetaskoffew-shotlearningisalsorelatedtoopensetproblem[20],wherethegoalisonlytodetectdatafromnovelclasses.
2.
2.
SegmentationSemanticsegmentationisafundamentalcomputervisiontaskwhichaimstoclassifyeachpixelintheimage.
State-of-the-artmethodsformulateimagesegmentationasadensepredictiontaskandadoptfullyconvolutionalnetworkstomakepredictions[2,11].
Usually,apre-trainedclassica-tionnetworkisusedasthenetworkbackbonebyremovingthefullyconnectedlayersattheend.
Tomakepixel-leveldensepredictions,encoder-decoderstructures[9,11]areoftenusedtoreconstructhigh-resolutionpredictionmaps.
Typicallyanencodergraduallydownsamplesthefeaturemaps,whichaimstoacquirelargeeld-of-viewandcaptureabstractfeaturerepresentations.
Then,thedecodergrad-uallyrecoversthene-grainedinformation.
Skipconnec-tionsareoftenusedtofusehigh-levelandlow-levelfea-4166turesforbetterpredictions.
Inournetwork,wealsofollowtheencoder-decoderdesignandopttotransfertheguidanceinformationinthelow-resolutionmapsandusedecoderstorecoverdetails.
2.
3.
Few-shotsegmentationFew-shotsegmentationisanaturalextensionoffew-shotclassicationtopixellevels.
SinceShabanetal.
[17]pro-posethistaskforthersttime,manydeeplearning-basedmethodsareproposed.
Mostpreviousworksformulatethefew-shotsegmentationasaguidedsegmentationtask.
Forexample,in[17],thesidebranchtakesthelabeledsupportimageastheinputandregressthenetworkparametersinthemainbranchtomakeforegroundpredictionsforthequeryimage.
In[26],theysharethesamespiritsandproposetofusetheembeddingsofthesupportbranchesintothequerybranchwithadensecomparisonmodule.
Dongetal.
[5]drawinspirationfromthesuccessofPrototypicalNetwork[19]infew-shotclassications,andproposeadenseprototypelearningwithEuclideandistanceasthemetricforsegmentationtasks.
Similarly,Zhangetal.
[27]proposeacosinesimilarityguidancenetworktoweightfea-turesfortheforegroundpredictionsinthequerybranch.
Therearesomepreviousworksusingrecurrentstructurestorenethesegmentationpredictions[6,26].
Allpreviousmethodsonlyusetheforegroundmaskinthequeryimageasthetrainingsupervision,whileinournetwork,thequerysetandthesupportsetguideeachotherandbothbranchesmakeforegroundpredictionsfortrainingsupervision.
2.
4.
Imageco-segmentationImageco-segmentationisawell-studiedtaskwhichaimstojointlysegmentthecommonobjectsinpairedimages.
Manyapproacheshavebeenproposedtosolvetheobjectco-segmentationproblem.
Rotheretetal.
[15]proposetominimizeanenergyfunctionofahistogrammatchingtermwithanMRFtoenforcesimilarforegroundstatistics.
Ru-binsteinetetal.
[16]capturethesparsityandvisualvari-abilityofthecommonobjectfrompairsofimageswithdensecorrespondences.
Joulinetal.
[7]solvethecommonobjectproblemwithanefcientconvexquadraticapprox-imationofenergywithdiscriminateclustering.
Sincetheprevalenceofdeepneuralnetworks,manydeeplearning-basedmethodshavebeenproposed.
In[12],themodelre-trievescommonobjectproposalswithaSiamesenetwork.
Chenetal.
[1]adoptchannelattentionstoweightfea-turesfortheco-segmentationtask.
Deeplearning-basedapproacheshavesignicantlyoutperformednon-learningbasedmethods.
3.
TaskDenitionFew-shotsegmentationaimstondtheforegroundpix-elsinthetestimagesgivenonlyafewpixel-levelannotatedimages.
Thetrainingandtestingofthemodelareconductedontwodatasetswithnooverlappedcategories.
Atboththetrainingandtestingstages,thelabeledexampleimagesarecalledthesupportset,whichservesasameta-trainingsetandtheunlabeledmeta-testingimageiscalledthequeryset.
Toguaranteeagoodgeneralizationperformanceattesttime,thetrainingandevaluationofthemodelareaccom-plishedbyepisodicallysamplingthesupportsetandthequeryset.
GivenanetworkRθparameterizedbyθ,ineachepisode,werstsampleatargetcategorycfromthedatasetC.
Basedonthesampledclass,wethensamplek+1labeledimages{(x1s,y1s),(x2s,y2s),.
.
.
(xks,yks),(xq,yq)}thatallcontainthesampledcategoryc.
Amongthem,therstklabeledimagesconstitutethesupportsetSandthelastoneisthequerysetQ.
Afterthat,wemakepredictionsonthequeryimagesbyinputtingthesupportsetandthequeryimageintothemodelyq=Rθ(S,xq).
Attrainingtime,welearnthemodelpa-rametersθbyoptimizingthecross-entropylossL(yq,yq),andrepeatsuchproceduresuntilconvergence.
4.
MethodInthissection,weintroducetheproposedcross-referencenetworkforsolvingfew-shotimagesegmenta-tion.
Inthebeginning,wedescribeournetworkinthe1-shotcase.
Afterthat,wedescribeournetuningschemeinthecaseofk-shotlearning.
Ournetworkincludesfourkeymodules:theSiameseencoder,thecross-referencemod-ule,theconditionmodule,andthemaskrenementmodule.
TheoverallarchitectureisshowninFig.
2.
4.
1.
MethodoverviewDifferentfrompreviousexistingfew-shotsegmentationmethods[26,17,5]unilaterallyguidethesegmentationofqueryimageswithsupportimages,ourproposedCRNeten-ablessupportandqueryimagesguidethesegmentationofeachother.
Wearguethattherelationshipbetweensupport-queryimagepairsisvitaltofew-shotsegmentationlearn-ing.
ExperimentsinTable2validatetheeffectivenessofournewarchitecturedesign.
AsshowninFigure2,ourmodellearnstoperformfew-shotsegmentationasfollows:foreveryquery-supportpair,weencodertheimagepairintodeepfeatureswiththeSiameseEncoder,thenapplythecross-referencemoduletomineoutco-occurrentobjectfeatures.
Tofullyutilizetheannotatedmask,theconditionalmodulewillincorporatethecategoryinformationofsupportsetannotationsforforegroundmaskpredictions,ourmaskrenemodulecachesthecondenceregionmapsrecur-rentlyfornalforegroundprediction.
Inthecaseofk-shotlearning,previousworks[27,26,17]onsimplyaveragetheresultsofdifferent1-shotpredictions,whileweadoptanoptimization-basedmethodthatnetunesthemodelto4167Figure2.
ThepipelineofourNetworkarchitecture.
OurNetworkmainlyconsistsofaSiameseencoder,across-referencemodule,acon-ditionmodule,andamaskrenementmodule.
Ournetworkadoptsasymmetricdesign.
TheSiameseencodermapsthequeryandsupportimagesintofeaturerepresentations.
Thecross-referencemoduleminestheco-occurrentfeaturesintwoimagestogeneratereinforcedrepresentations.
Theconditionmodulefusesthecategory-relevantfeaturevectorsintofeaturemapstoemphasizethetargetcategory.
Themaskrenementmodulesavesthecondencemapsofthelastpredictionintothecacheandrecurrentlyrenesthepredictedmasks.
makeuseofmoresupportdata.
Table4demonstratestheadvantagesofourmethodoverpreviousworks.
4.
2.
SiameseencoderTheSiameseencoderisapairofparameter-sharedcon-volutionalneuralnetworksthatencodethequeryimageandthesupportimagetofeaturemaps.
Unlikethemod-elsin[17,14],weuseasharedfeatureencodertoencodethesupportandthequeryimages.
Byembeddingtheim-agesintothesamespace,ourcross-referencemodulecanbettermineco-occurrentfeaturestolocatetheforegroundregions.
Toacquirerepresentativefeatureembeddings,weuseskipconnectionstoutilizemultiple-layerfeatures.
AsisobservedinCNNfeaturevisualizationliterature[26,23],featuresinlowerlayersoftenrelatetolowlevelcueandhigherlayersoftenrelatetosegmentcue,wecombinethelowerlevelfeaturesandhigherlevelfeaturesandpassingtofollowedmodules.
4.
3.
Cross-ReferenceModuleThecross-referencemoduleisdesignedtomineco-occurrentfeaturesintwoimagesandgenerateupdatedrep-resentations.
ThedesignofthemoduleisshowninFig.
3.
GiventwoinputfeaturemapsgeneratedbytheSiameseen-coder,werstuseglobalaveragepoolingtoacquiretheglobalstatisticsinthetwoimages.
Then,thetwofeaturevectorsaresenttoapairoftwo-layerfullyconnected(FC)layers,respectively.
TheSigmoidactivationfunctionat-tachedaftertheFClayertransformsthevectorvaluesintotheimportanceofthechannel,whichisintherangeof[0,1].
Afterthat,thevectorsinthetwobranchesarefusedbyelement-wisemultiplication.
Intuitively,onlythecommonfeaturesinthetwobrancheswillhaveahighactivationinthefusedimportancevector.
Finally,weusethefusedvec-tortoweighttheinputfeaturemapstogeneratereinforcedfeaturerepresentations.
Incomparisontotherawfeatures,thereinforcedfeaturesfocusmoreontheco-occurrentrep-resentations.
Basedonthereinforcedfeaturerepresentations,weadda4168Figure3.
Thecross-referencemodule.
Giventheinputfea-turemapsfromthesupportandthequerysets(Fs,Fq),thecross-referencemodulegeneratesupdatedfeaturerepresentations(Gs,Gq)byinspectingtheco-occurrentfeatures.
headtodirectlypredicttheco-occurrentobjectsinthetwoimagesduringtrainingtime.
Thissub-taskaimstofacil-itatethelearningoftheco-segmentationmoduletominebetterfeaturerepresentationsforthedownstreamtasks.
Togeneratethepredictionsoftheco-occurrentobjectsintwoimages,thereinforcedfeaturemapsinthetwobranchesaresenttoadecodertogeneratethepredictedmaps.
ThedecoderiscomposedofconvolutionallayerfollowedbyaASPP[2]layers,nally,aconvolutionallayergeneratesatwo-channelpredictioncorrespondingtotheforegroundandbackgroundscores.
4.
4.
ConditionModuleTofullyutilizethesupportsetannotations,wedesignaconditionmoduletoefcientlyincorporatethecategoryinformationforforegroundmaskpredictions.
Thecon-ditionmoduletakesthereinforcedfeaturerepresentationsgeneratedbythecross-referencemoduleandacategory-relevantvectorasinputs.
Thecategory-relevantvectoristhefusedfeatureembeddingsofthetargetcategory,whichisachievedbyapplyingforegroundaveragepooling[26]overthecategoryregion.
Asthegoalofthefew-shotsegmen-tationistoonlyndtheforegroundmaskoftheassignedobjectcategory,thetask-relevantvectorservesasacondi-tiontosegmentthetargetcategory.
Toachieveacategory-relevantembedding,previousworksopttolteroutthebackgroundregionsintheinputimages[14,17]orinthefeaturerepresentations[26,27].
Wechoosetodosobothinthefeaturelevelandintheinputimage.
Thecategory-relevantvectorisfusedwiththereinforcedfeaturemapsintheconditionmodulebybilinearlyupsamplingthevectortothesamespatialsizeofthefeaturemapsandconcatenatingthem.
Finally,weaddaresidualconvolutiontoprocesstheconcatenatedfeatures.
Thestructureoftheconditionmod-ulecanbefoundinFig.
4.
Theconditionmodulesinthesupportbranchandthequerybranchhavethesamestruc-tureandsharealltheparameters.
4.
5.
MaskRenementModuleAsisoftenobservedintheweaklysupervisedseman-ticsegmentationliterature[26,8],directlypredictingtheFigure4.
Theconditionmodule.
Ourconditionmodulefusesthecategory-relevantfeaturesintorepresentationsforbetterpredic-tionsofthetargetcategory.
objectmaskscanbedifcult.
Itisacommonprincipletorstlylocateseedregionsandthenrenetheresults.
Basedonsuchprinciple,wedesignamaskrenementmoduletorenethepredictedmaskstep-by-step.
Ourmotivationisthattheprobabilitymapsinasinglefeed-forwardpredic-tioncanreectwhereisthecondentregioninthemodelprediction.
Basedonthecondentregionsandtheimagefeatures,wecangraduallyoptimizethemaskandndthewholeobjectregions.
AsshowninFig.
5,ourmaskrene-mentmodulehastwoinputs.
Oneisthesavedcondencemapinthecacheandthesecondinputistheconcatenationoftheoutputsfromtheconditionmoduleandthecross-referencemodule.
Fortheinitialprediction,thecacheisinitializedwithazeromask,andthemodulemakespredic-tionssolelybasedontheinputfeaturemaps.
Themodulecacheisupdatedwiththegeneratedprobabilitymapeverytimethemodulemakesanewprediction.
Werunthismod-ulemultipletimestogenerateanalrenedmask.
Themaskrenementmoduleincludesthreemainblocks:thedownsampleblock,theglobalconvolutionblock,andthecombineblock.
TheDownsampleBlockdownsamplesthefeaturemapsbyafactorof2.
Thedownsampledfea-turesarethenupsampledtotheoriginalsizeandfusedwithfeaturesintheoppositebranch.
Theglobalconvolutionblock[13]aimstocapturefeaturesinalargeeld-of-viewwhilecontainingfewparameters.
Itincludestwogroupsof1*7and7*1convolutionalkernels.
Thecombineblockeffectivelyfusesthefeaturebranchandthecachedbranchtogeneraterenedfeaturerepresentations.
4.
6.
FinetuningforK-ShotLearningInthecaseofk-shotlearning,weproposetonetuneournetworktotakeadvantageofmultiplelabeledsupportim-ages.
Asournetworkcanmakepredictionsfortwoimagesatatime,wecanuseatmostk2imagepairstonetuneournetwork.
Attheevaluationstage,werandomlysam-pleanimagepairfromthelabeledsupportsettonetuneourmodel.
WekeeptheparametersintheSiameseencoderxedandonlynetunetherestmodules.
Inourexperiment,wedemonstratethatournetuningbasedmethodscancon-sistentlyimprovetheresultwhenmorelabeledsupportim-agesareavailable,whilethefusion-basedmethodsinprevi-ousworksoftengetsaturatedperformancewhenthenum-berofsupportimagesincreases.
4169Figure5.
Themaskrenementmodule.
Themodulesavesthegeneratedprobabilitymapfromthelaststepintothecacheandrecurrentlyoptimizesthepredictions.
5.
Experiment5.
1.
ImplementationDetailsIntheSiameseencoder,weexploitmulti-levelfeaturesfromtheImageNetpre-trainedResnet-50astheimagerep-resentations.
Weusedilatedconvolutionsandkeepthefea-turemapsafterlayer3andlayer4haveaxedsizeof1/8oftheinputimageandconcatenatethemfornalpredic-tion.
Alltheconvolutionallayersinourproposedmoduleshavethekernelsizeof3*3andgeneratefeaturesof256channels,followedbytheReLUactivationfunction.
Attesttime,werecurrentlyrunthemaskrenementmodulefor5timestorenethepredictedmasks.
Inthecaseofk-shotlearning,wextheSiameseencoderandnetunetherestparameters.
5.
2.
DatasetandEvaluationMetricWeimplementcross-validationexperimentsonthePAS-CALVOC2012datasettovalidateournetworkdesign.
Tocompareourmodelwithpreviousworks,weadoptthesamecategorydivisionsandtestsettingswhicharerstproposedin[17].
Inthecross-validationexperiments,20objectcat-egoriesareevenlydividedinto4folds,withthreefoldsasthetrainingclassesandonefoldasthetestingclasses.
ThecategorydivisionisshowninTable1.
Wereporttheav-erageperformanceover4testingfolds.
Fortheevaluationmetrics,weusethestandardmeanIntersection-over-Union(mIoU)oftheclassesinthetestingfold.
Formorede-tailsaboutthedatasetinformationandtheevaluationmet-ric,pleasereferto[17].
6.
AblationstudyThegoaloftheablationstudyistoinspecteachcompo-nentinournetworkdesign.
OurablationexperimentsareconductedonthePASCALVOCdataset.
Weimplementfoldcategories0aeroplane,bicycle,bird,boat,bottle1bus,car,cat,chair,cow2diningtable,dog,horse,motobike,person3pottedplant,sheep,sofa,train,tv/monitorTable1.
TheclassdivisionofthePASCALVOC2012datasetpro-posedin[17].
ConditionCross-ReferenceModule1-shot36.
343.
349.
1Table2.
Ablationstudyontheconditionmoduleandthecross-referencemodule.
Thecross-referencemodulebringsalargeper-formanceimprovementoverthebaselinemodel(Conditiononly).
Multi-LevelMaskReneMulti-Scale1-shot49.
150.
353.
455.
2Table3.
Ablationexperimentsonthemultiple-levelfeature,multiple-scaleinput,andtheMaskRenemodule.
Everymod-ulebringsperformanceimprovementoverthebaselinemodel.
cross-validation1-shotexperimentsandreporttheaverageperformanceoverthefoursplits.
InTable2,werstinvestigatethecontributionsofourtwoimportantnetworkcomponents:theconditionmod-uleandthecross-referencemodule.
Asshown,therearesignicantperformancedropsifweremoveeithercompo-nentfromthenetwork.
Particularly,ourproposedcross-referencemodulehasahugeimpactonthepredictions.
Our4170Figure6.
OurQualitativeexamplesonthePASCALVOCdataset.
Therstrowisthesupportsetandthesecondrowisthequeryset.
Thethirdrowisourpredictedresultsandthethefourthrowisthegroundtruth.
Evenwhenthequeryimagescontainobjectsfrommultipleclasses,ournetworkcanstillsuccessfullysegmentthetargetcategoryindicatedbythesupportmask.
Method1-shot5-shot10-shotFusion49.
150.
249.
9FinetuneN/A57.
559.
1Finetune+FusionN/A57.
658.
8Table4.
k-shotexperiments.
Wecompareournetuningbasedmethodwiththefusionmethod.
Ourmethodyieldsconsistentper-formanceimprovementwhenthenumberofsupportimagesin-creases.
Forthecaseof1-shot,netuneresultsarenotavailableasCRNetneedsatleasttwoimagestoapplyournetunescheme.
networkcanimprovethecounterpartmodelwithoutcross-referencemodulebymorethan10%.
Toinvestigatehowmuchthescalevarianceoftheob-jectsinuencethenetworkperformance,weadoptamulti-scaletestexperimentinournetwork.
Specically,atthetesttime,weresizethesupportimageandthequeryimageto[0.
75,1.
25]oftheoriginalimagesizeandconducttheinfer-MethodBackbonemIoUIoUOSLM[17]VGG1640.
861.
3co-fcn[14]VGG1641.
160.
9sg-one[27]VGG1646.
363.
1R-DRCN[18]VGG1640.
160.
9PL[5]VGG16-61.
2A-MCG[6]ResNet-50-61.
2CANet[26]ResNet-5055.
466.
2PGNet[25]ResNet-5056.
069.
9CRNetVGG1655.
266.
4CRNetResNet-5055.
766.
8Table5.
Comparisonwiththestate-of-the-artmethodsunderthe1-shotsetting.
Ourproposednetworkachievesstate-of-the-artper-formanceunderbothevaluationmetrics.
ence.
Theoutputpredictedmaskoftheresizedqueryimageisbilinearlyresizedtotheoriginalimagesize.
Wefusethepredictionsunderdifferentimagescales.
AsshowninTa-4171MethodBackbonemIoUIoUOSLM[17]VGG1643.
961.
5co-fcn[14]VGG1641.
460.
2sg-one[27]VGG1647.
165.
9R-DFCN[18]VGG1645.
366.
0PL[5]VGG16-62.
3A-MCG[6]ResNet-50-62.
2CANet[26]ResNet-5057.
169.
6PGNet[25]ResNet5058.
570.
5CRNetVGG1658.
571.
0CRNetResNet5058.
871.
5Table6.
Comparisonwiththestate-of-the-artmethodsunderthe5-shotsetting.
Ourproposednetworkoutperformsallpreviousmethodsandachievesnewstate-of-the-artperformanceunderbothevaluationmetrics.
ble3,multi-scaleinputtestbrings1.
2mIoUscoreimprove-mentinthe1-shotsetting.
WealsoinvestigatethechoicesoffeaturesinthenetworkbackboneinTable3.
Wecom-parethemulti-levelfeatureembeddingswiththefeaturessolelyfromthelastlayer.
Ourmodelwithmulti-levelfea-turesprovidesanimprovementof1.
8mIoUscore.
Thisindicatesthattobetterlocatethecommonobjectsintwoimages,middle-levelfeaturesarealsoimportantandhelp-ful.
Tofurtherinspecttheeffectivenessofthemaskrene-mentmodule,wedesignabaselinemodelthatremovesthecachedbranch.
Inthiscase,themaskrenementblockmakespredictionssolelybasedontheinputfeaturesandweonlyrunthemaskrenementmoduleonce.
AsshowninTable3,ourmaskrenementmodulebrings3.
1mIoUscoreperformanceincreaseoverourbaselinemethod.
Inthek-shotsetting,wecompareournetuningbasedmethodwiththefusion-basedmethodswidelyusedinpre-viousworks.
Forthefusion-basedmethod,wemakeanin-ferencewitheachofthesupportimagesandaveragetheirprobabilitymapsasthenalprediction.
ThecomparisonisshowninTable4.
Inthe5-shotsetting,thenetuningbasedmethodoutperforms1-shotbaselineby8.
4mIoUscore,whichissignicantlysuperiortothefusion-basedmethod.
When10supportimagesareavailable,ournetuningbasedmethodshowsmoreadvantages.
Theperformancecon-tinuesincreasingwhilethefusion-basedmethod'sperfor-mancebeginstodrop.
6.
1.
MSCOCOCOCO2014[10]isachallenginglarge-scaledataset,whichcontains80objectcategories.
Following[26],wechoose40classesfortraining,20classesforvalidationand20classesfortest.
AsshowninTable.
7,theresultsagainvalidatethedesignsinournetwork.
ConditionCross-ReferenceModuleMask-Rene1-shot5-shot43.
344.
038.
542.
744.
945.
645.
847.
2Table7.
Ablationstudyontheconditionmodulecross-referencemoduleandMask-renemoduleondatasetMSCOCO.
6.
2.
ComparisonwiththeState-of-the-ArtResultsWecompareournetworkwithstate-of-the-artmethodsonthePASCALVOC2012dataset.
Table5showstheper-formanceofdifferentmethodsinthe1-shotsetting.
WeuseIoUtodenotetheevaluationmetricproposedin[14].
ThedifferencebetweenthetwometricsisthattheIoUmetricalsoincorporatesthebackgroundintotheIntersection-over-Unioncomputationandignorestheimagecategory.
5-ShotExperiments.
Thecomparisonof5-shotseg-mentationresultsundertwoevaluationmetricsisshowninTable6.
Ourmethodachievesnewstate-of-the-artperfor-manceunderbothevaluationmetrics.
7.
ConclusionInthispaper,wehavepresentedanovelcross-referencenetworkforfew-shotsegmentation.
Unlikepreviousworkunilaterallyguidingthesegmentationofqueryimageswithsupportimages,ourtwo-headdesignconcurrentlymakespredictionsinboththequeryimageandthesupportimagetohelpthenetworkbetterlocatethetargetcategory.
Wedevelopamaskrenementmodulewithacachemecha-nismwhichcaneffectivelyimprovethepredictionperfor-mance.
Inthek-shotsetting,ournetuningbasedmethodcantakeadvantageofmoreannotateddataandsignicantlyimprovestheperformance.
ExtensiveablationexperimentsonPASCALVOC2012datasetvalidatetheeffectivenessofourdesign.
Ourmodelachievesstate-of-the-artperfor-manceonthePASCALVOC2012dataset.
AcknowledgementsThisresearchissupportedbytheNationalResearchFoundationSingaporeunderitsAISingaporeProgramme(AwardNumber:AISG-RP-2018-003)andtheMOETier-1researchgrants:RG126/17(S)andRG22/19(S).
Thisre-searchisalsopartlysupportedbytheDelta-NTUCorporateLabwithfundingsupportfromDeltaElectronicsInc.
andtheNationalResearchFoundation(NRF)Singapore.
References[1]HongChen,YifeiHuang,andHidekiNakayama.
Semanticawareattentionbaseddeepobjectco-segmentation.
arXivpreprintarXiv:1810.
06859,2018.
2,3[2]Liang-ChiehChen,GeorgePapandreou,IasonasKokkinos,KevinMurphy,andAlanLYuille.
Deeplab:Semanticimage4172segmentationwithdeepconvolutionalnets,atrousconvolu-tion,andfullyconnectedcrfs.
IEEEtransactionsonpatternanalysisandmachineintelligence,40(4):834–848,2018.
2,5[3]Wei-YuChen,Yen-ChengLiu,ZsoltKira,Yu-ChiangWang,andJia-BinHuang.
Acloserlookatfew-shotclassication.
InInternationalConferenceonLearningRepresentations,2019.
2[4]JiaDeng,WeiDong,RichardSocher,Li-JiaLi,KaiLi,andLiFei-Fei.
Imagenet:Alarge-scalehierarchicalimagedatabase.
InCVPR,pages248–255,2009.
1[5]NanqingDongandEricXing.
Few-shotsemanticsegmenta-tionwithprototypelearning.
InBMVC,2018.
3,7,8[6]TaoHu,PengwanYang,ChiliangZhang,GangYu,YadongMu,andCeesGMSnoek.
Attention-basedmulti-contextguidingforfew-shotsemanticsegmentation.
2019.
3,7,8[7]ArmandJoulin,FrancisBach,andJeanPonce.
Multi-classcosegmentation.
In2012IEEEConferenceonComputerVi-sionandPatternRecognition,pages542–549.
IEEE,2012.
2,3[8]AlexanderKolesnikovandChristophHLampert.
Seed,ex-pandandconstrain:Threeprinciplesforweakly-supervisedimagesegmentation.
InEuropeanConferenceonComputerVision,pages695–711.
Springer,2016.
5[9]GuoshengLin,AntonMilan,ChunhuaShen,andIanDReid.
Renenet:Multi-pathrenementnetworksforhigh-resolutionsemanticsegmentation.
InCVPR,volume1,page5,2017.
2[10]Tsung-YiLin,MichaelMaire,SergeBelongie,JamesHays,PietroPerona,DevaRamanan,PiotrDollar,andCLawrenceZitnick.
Microsoftcoco:Commonobjectsincontext.
InECCV,pages740–755,2014.
8[11]JonathanLong,EvanShelhamer,andTrevorDarrell.
Fullyconvolutionalnetworksforsemanticsegmentation.
InPro-ceedingsoftheIEEEconferenceoncomputervisionandpat-ternrecognition,pages3431–3440,2015.
2[12]PreranaMukherjee,BrejeshLall,andSnehithLattupally.
Objectcosegmentationusingdeepsiamesenetwork.
arXivpreprintarXiv:1803.
02555,2018.
2,3[13]ChaoPeng,XiangyuZhang,GangYu,GuimingLuo,andJianSun.
Largekernelmatters–improvesemanticsegmen-tationbyglobalconvolutionalnetwork.
InProceedingsoftheIEEEconferenceoncomputervisionandpatternrecog-nition,pages4353–4361,2017.
5[14]KateRakelly,EvanShelhamer,TrevorDarrell,AlyoshaEfros,andSergeyLevine.
Conditionalnetworksforfew-shotsemanticsegmentation.
InICLRWorkshop,2018.
4,5,7,8[15]CarstenRother,TomMinka,AndrewBlake,andVladimirKolmogorov.
Cosegmentationofimagepairsbyhistogrammatching-incorporatingaglobalconstraintintomrfs.
In2006IEEEComputerSocietyConferenceonComputerVi-sionandPatternRecognition(CVPR'06),volume1,pages993–1000.
IEEE,2006.
3[16]MichaelRubinstein,ArmandJoulin,JohannesKopf,andCeLiu.
Unsupervisedjointobjectdiscoveryandsegmentationininternetimages.
InProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition,pages1939–1946,2013.
3[17]AmirrezaShaban,ShrayBansal,ZhenLiu,IrfanEssa,andByronBoots.
One-shotlearningforsemanticsegmentation.
arXivpreprintarXiv:1709.
03410,2017.
3,4,5,6,7,8[18]MennatullahSiamandBorisOreshkin.
Adaptivemaskedweightimprintingforfew-shotsegmentation.
arXivpreprintarXiv:1902.
11123,2019.
7,8[19]JakeSnell,KevinSwersky,andRichardZemel.
Prototypicalnetworksforfew-shotlearning.
InNIPS,2017.
2,3[20]XinSun,ZhenningYang,ChiZhang,GuohaoPeng,andKeck-VoonLing.
Conditionalgaussiandistributionlearningforopensetrecognition,2020.
2[21]OriolVinyals,CharlesBlundell,TimothyLillicrap,DaanWierstra,etal.
Matchingnetworksforoneshotlearning.
InAdvancesinneuralinformationprocessingsystems,pages3630–3638,2016.
2[22]FloodSungYongxinYang,LiZhang,TaoXiang,PhilipHSTorr,andTimothyMHospedales.
Learningtocompare:Re-lationnetworkforfew-shotlearning.
InCVPR,2018.
2[23]JasonYosinski,JeffClune,AnhNguyen,ThomasFuchs,andHodLipson.
Understandingneuralnetworksthroughdeepvisualization.
arXivpreprintarXiv:1506.
06579,2015.
4[24]ChiZhang,YujunCai,GuoshengLin,andChunhuaShen.
Deepemd:Few-shotimageclassicationwithdifferentiableearthmover'sdistanceandstructuredclassiers,2020.
2[25]ChiZhang,GuoshengLin,FayaoLiu,JiushuangGuo,QingyaoWu,andRuiYao.
Pyramidgraphnetworkswithconnectionattentionsforregion-basedone-shotsemanticsegmentation.
InProceedingsoftheIEEEInternationalConferenceonComputerVision,pages9587–9595,2019.
7,8[26]ChiZhang,GuoshengLin,FayaoLiu,RuiYao,andChunhuaShen.
Canet:Class-agnosticsegmentationnetworkswithit-erativerenementandattentivefew-shotlearning.
InPro-ceedingsoftheIEEEConferenceonComputerVisionandPatternRecognition,pages5217–5226,2019.
3,4,5,7,8[27]XiaolinZhang,YunchaoWei,YiYang,andThomasHuang.
Sg-one:Similarityguidancenetworkforone-shotsemanticsegmentation.
arXivpreprintarXiv:1810.
09091,2018.
3,5,7,84173
ntu.
edu.
sg,chi007@e.
ntu.
edu.
sg,gslin@ntu.
edu.
sgAbstractOverthepastfewyears,state-of-the-artimagesegmen-tationalgorithmsarebasedondeepconvolutionalneuralnetworks.
Torenderadeepnetworkwiththeabilitytoun-derstandaconcept,humansneedtocollectalargeamountofpixel-levelannotateddatatotrainthemodels,whichistime-consumingandtedious.
Recently,few-shotsegmenta-tionisproposedtosolvethisproblem.
Few-shotsegmenta-tionaimstolearnasegmentationmodelthatcanbegener-alizedtonovelclasseswithonlyafewtrainingimages.
Inthispaper,weproposeacross-referencenetwork(CRNet)forfew-shotsegmentation.
Unlikepreviousworkswhichonlypredictthemaskinthequeryimage,ourproposedmodelconcurrentlymakepredictionsforboththesupportimageandthequeryimage.
Withacross-referencemecha-nism,ournetworkcanbetterndtheco-occurrentobjectsinthetwoimages,thushelpingthefew-shotsegmentationtask.
Wealsodevelopamaskrenementmoduletorecurrentlyre-nethepredictionoftheforegroundregions.
Forthek-shotlearning,weproposetonetunepartsofnetworkstotakeadvantageofmultiplelabeledsupportimages.
ExperimentsonthePASCALVOC2012datasetshowthatournetworkachievesstate-of-the-artperformance.
1.
IntroductionDeepneuralnetworkshavebeenwidelyappliedtovi-sualunderstandingtasks,e.
g.
,objectiondetection,seman-ticsegmentationandimagecaptioning,sincethehugesuc-cessinImageNetclassicationchallenge[4].
Duetoitsdata-drivingproperty,large-scalelabeleddatasetsareof-tenrequiredtoenablethetrainingofdeepmodels.
How-ever,collectinglabeleddatacanbenotoriouslyexpensiveintaskslikesemanticsegmentation,instancesegmentation,andvideosegmentation.
Moreover,datacollectingisusu-allyforasetofspeciccategories.
KnowledgelearnedinpreviousclassescanhardlybetransferredtounseenclassesCorrespondingauthor:G.
Lin(e-mail:gslin@ntu.
edu.
sg)Figure1.
ComparisonofourproposedCRNetagainstpreviouswork.
Previouswork(upperpart)unilaterallyguidethesegmen-tationofqueryimageswithsupportimages,whileinourCRNet(lowerpart)supportandqueryimagescanguidethesegmentationofeachother.
directly.
Directlynetuningthetrainedmodelsstillneedsalargeamountofnewlabeleddata.
Few-shotlearning,ontheotherhand,isproposedtosolvethisproblem.
Inthefew-shotlearningtasks,modelstrainedonprevioustasksareexpectedtogeneralizetounseentaskswithonlyafewlabeledtrainingimages.
Inthispaper,wetargetatfew-shotimagesegmentation.
Givenanovelobjectcategory,few-shotsegmentationaimstondtheforegroundregionsofthiscategoryonlyseeingafewlabeledexamples.
Manypreviousworksformulatethefew-shotsegmentationtaskasaguidedsegmentationtask.
Theguidanceinformationisextractedfromthelabeledsup-portsetfortheforegroundpredictioninthequeryimage,whichisusuallyachievedbyanunsymmetricaltwo-branchnetworkstructure.
Themodelisoptimizedwiththegroundtruthquerymaskasthesupervision.
Inourwork,wearguethattherolesofqueryandsup-portsetscanbeswitchedinafew-shotsegmentationmodel.
Specically,thesupportimagescanguidethepredictionof4165thequeryset,andconversely,thequeryimagecanalsohelpmakepredictionsofthesupportset.
Inspiredbytheimageco-segmentationliterature[7,12,1],weproposeasymmet-ricCross-ReferenceNetworkthattwoheadsconcurrentlymakepredictionsforboththequeryimageandthesupportimage.
ThedifferenceofthenetworkdesignwithpreviousworksisshowninFig.
1.
Thekeycomponentinournet-workdesignisthecross-referencemodulewhichgeneratesthereinforcedfeaturerepresentationsbycomparingtheco-occurrentfeaturesintwoimages.
Thereinforcedrepresen-tationsareusedforthedownstreamforegroundpredictionsintwoimages.
Inthemeantime,thecross-referencemod-ulealsomakespredictionsofco-occurrentobjectsinthetwoimages.
Thissub-taskprovidesanauxiliarylossinthetrainingphasetofacilitatethetrainingofthecross-referencemodule.
Asthereexistshugevarianceintheobjectappearance,miningforegroundregionsinimagescanbeamulti-stepprocess.
WedevelopaneffectiveMaskRenementModuletoiterativelyreneourpredictions.
Intheinitialprediction,thenetworkisexpectedtolocatehigh-condenceseedre-gions.
Then,thecondencemap,intheformofprobabilitymap,issavedasthecacheinthemoduleandisusedforlaterpredictions.
Weupdatethecacheeverytimewemakeanewprediction.
Afterrunningthemaskrenementmoduleforafewsteps,ourmodelcanbetterpredicttheforegroundre-gions.
Weempiricallydemonstratethatsuchalight-weightmodulecansignicantlyimprovetheperformance.
Whenitcomestothek-shotimagesegmentationwheremorethanonesupportimagesareprovided,previousmeth-odsoftenuse1-shotmodeltomakepredictionswitheachsupportimageindividuallyandfusetheirfeaturesorpre-dictedmasks.
Inourpaper,weproposetonetunepartsofournetworkwiththelabeledsupportexamples.
Asournetworkcanmakepredictionsforbothtwoimageinputsatatime,wecanuseatmostk2imagepairstonetuneournetwork.
Anadvantageofournetuningbasedmethodisthatitcanbenetfromtheincreasingnumberofsupportim-ages,andthusconsistentlyincreasestheaccuracy.
Incom-parison,thefusion-basedmethodscaneasilysaturatewhenmoresupportimagesareprovided.
Inourexperiment,wevalidateourmodelinthe1-shot,5-shot,and10-shotset-tings.
Themaincontributionsofthispaperarelistedasfollows:Weproposeanovelcross-referencenetworkthatcon-currentlymakespredictionsforboththequerysetandthesupportsetinthefew-shotimagesegmentationtask.
Byminingtheco-occurrentfeaturesintwoim-ages,ourproposednetworkcaneffectivelyimprovetheresults.
Wedevelopamaskrenementmodulewithcondencecachethatisabletorecurrentlyrenethepredictedre-sults.
Weproposeanetuningschemefork-shotlearning,whichturnsouttobeaneffectivesolutiontohandlemultiplesupportimages.
ExperimentsonthePASCALVOC2012demonstratethatourmethodsignicantlyoutperformsbaselinere-sultsandachievesnewstate-of-the-artperformanceonthe5-shotsegmentationtask.
2.
RelatedWork2.
1.
FewshotlearningFew-shotlearningaimstolearnamodelwhichcanbeeasilytransferredtonewtaskswithlimitedtrainingdataavailable.
Few-shotlearningiswidelyexploredinimageclassicationtasks.
Previousmethodscanberoughlydi-videdintotwocategoriesbasedonwhetherthemodelneedsnetuningatthetestingtime.
Innon-netunedmethods,parameterslearnedatthetrainingtimearekeptxedatthetestingstage.
Forexample,[19,22,21,24]aremetricbasedapproacheswhereanembeddingencoderandadistancemetricarelearnedtodeterminetheimagepairsimilarity.
Thesemethodshavetheadvantageoffastinferencewith-outfurtherparameteradaptions.
However,whenmultiplesupportimagesareavailable,theperformancecanbecomesaturateeasily.
Innetuningbasedmethods,themodelpa-rametersneedtobeadaptedtothenewtasksforpredictions.
Forexample,in[3],theydemonstratethatbyonlynetun-ingthefullyconnectedlayer,modelslearnedontrainingclassescanyieldstate-of-the-artfew-shotperformanceonnewclasses.
Inourwork,weuseanon-netunedfeed-forwardmodeltohandle1-shotlearningandadoptmodelnetuninginthek-shotsettingtobenetfrommultiplela-beledsupportimages.
Thetaskoffew-shotlearningisalsorelatedtoopensetproblem[20],wherethegoalisonlytodetectdatafromnovelclasses.
2.
2.
SegmentationSemanticsegmentationisafundamentalcomputervisiontaskwhichaimstoclassifyeachpixelintheimage.
State-of-the-artmethodsformulateimagesegmentationasadensepredictiontaskandadoptfullyconvolutionalnetworkstomakepredictions[2,11].
Usually,apre-trainedclassica-tionnetworkisusedasthenetworkbackbonebyremovingthefullyconnectedlayersattheend.
Tomakepixel-leveldensepredictions,encoder-decoderstructures[9,11]areoftenusedtoreconstructhigh-resolutionpredictionmaps.
Typicallyanencodergraduallydownsamplesthefeaturemaps,whichaimstoacquirelargeeld-of-viewandcaptureabstractfeaturerepresentations.
Then,thedecodergrad-uallyrecoversthene-grainedinformation.
Skipconnec-tionsareoftenusedtofusehigh-levelandlow-levelfea-4166turesforbetterpredictions.
Inournetwork,wealsofollowtheencoder-decoderdesignandopttotransfertheguidanceinformationinthelow-resolutionmapsandusedecoderstorecoverdetails.
2.
3.
Few-shotsegmentationFew-shotsegmentationisanaturalextensionoffew-shotclassicationtopixellevels.
SinceShabanetal.
[17]pro-posethistaskforthersttime,manydeeplearning-basedmethodsareproposed.
Mostpreviousworksformulatethefew-shotsegmentationasaguidedsegmentationtask.
Forexample,in[17],thesidebranchtakesthelabeledsupportimageastheinputandregressthenetworkparametersinthemainbranchtomakeforegroundpredictionsforthequeryimage.
In[26],theysharethesamespiritsandproposetofusetheembeddingsofthesupportbranchesintothequerybranchwithadensecomparisonmodule.
Dongetal.
[5]drawinspirationfromthesuccessofPrototypicalNetwork[19]infew-shotclassications,andproposeadenseprototypelearningwithEuclideandistanceasthemetricforsegmentationtasks.
Similarly,Zhangetal.
[27]proposeacosinesimilarityguidancenetworktoweightfea-turesfortheforegroundpredictionsinthequerybranch.
Therearesomepreviousworksusingrecurrentstructurestorenethesegmentationpredictions[6,26].
Allpreviousmethodsonlyusetheforegroundmaskinthequeryimageasthetrainingsupervision,whileinournetwork,thequerysetandthesupportsetguideeachotherandbothbranchesmakeforegroundpredictionsfortrainingsupervision.
2.
4.
Imageco-segmentationImageco-segmentationisawell-studiedtaskwhichaimstojointlysegmentthecommonobjectsinpairedimages.
Manyapproacheshavebeenproposedtosolvetheobjectco-segmentationproblem.
Rotheretetal.
[15]proposetominimizeanenergyfunctionofahistogrammatchingtermwithanMRFtoenforcesimilarforegroundstatistics.
Ru-binsteinetetal.
[16]capturethesparsityandvisualvari-abilityofthecommonobjectfrompairsofimageswithdensecorrespondences.
Joulinetal.
[7]solvethecommonobjectproblemwithanefcientconvexquadraticapprox-imationofenergywithdiscriminateclustering.
Sincetheprevalenceofdeepneuralnetworks,manydeeplearning-basedmethodshavebeenproposed.
In[12],themodelre-trievescommonobjectproposalswithaSiamesenetwork.
Chenetal.
[1]adoptchannelattentionstoweightfea-turesfortheco-segmentationtask.
Deeplearning-basedapproacheshavesignicantlyoutperformednon-learningbasedmethods.
3.
TaskDenitionFew-shotsegmentationaimstondtheforegroundpix-elsinthetestimagesgivenonlyafewpixel-levelannotatedimages.
Thetrainingandtestingofthemodelareconductedontwodatasetswithnooverlappedcategories.
Atboththetrainingandtestingstages,thelabeledexampleimagesarecalledthesupportset,whichservesasameta-trainingsetandtheunlabeledmeta-testingimageiscalledthequeryset.
Toguaranteeagoodgeneralizationperformanceattesttime,thetrainingandevaluationofthemodelareaccom-plishedbyepisodicallysamplingthesupportsetandthequeryset.
GivenanetworkRθparameterizedbyθ,ineachepisode,werstsampleatargetcategorycfromthedatasetC.
Basedonthesampledclass,wethensamplek+1labeledimages{(x1s,y1s),(x2s,y2s),.
.
.
(xks,yks),(xq,yq)}thatallcontainthesampledcategoryc.
Amongthem,therstklabeledimagesconstitutethesupportsetSandthelastoneisthequerysetQ.
Afterthat,wemakepredictionsonthequeryimagesbyinputtingthesupportsetandthequeryimageintothemodelyq=Rθ(S,xq).
Attrainingtime,welearnthemodelpa-rametersθbyoptimizingthecross-entropylossL(yq,yq),andrepeatsuchproceduresuntilconvergence.
4.
MethodInthissection,weintroducetheproposedcross-referencenetworkforsolvingfew-shotimagesegmenta-tion.
Inthebeginning,wedescribeournetworkinthe1-shotcase.
Afterthat,wedescribeournetuningschemeinthecaseofk-shotlearning.
Ournetworkincludesfourkeymodules:theSiameseencoder,thecross-referencemod-ule,theconditionmodule,andthemaskrenementmodule.
TheoverallarchitectureisshowninFig.
2.
4.
1.
MethodoverviewDifferentfrompreviousexistingfew-shotsegmentationmethods[26,17,5]unilaterallyguidethesegmentationofqueryimageswithsupportimages,ourproposedCRNeten-ablessupportandqueryimagesguidethesegmentationofeachother.
Wearguethattherelationshipbetweensupport-queryimagepairsisvitaltofew-shotsegmentationlearn-ing.
ExperimentsinTable2validatetheeffectivenessofournewarchitecturedesign.
AsshowninFigure2,ourmodellearnstoperformfew-shotsegmentationasfollows:foreveryquery-supportpair,weencodertheimagepairintodeepfeatureswiththeSiameseEncoder,thenapplythecross-referencemoduletomineoutco-occurrentobjectfeatures.
Tofullyutilizetheannotatedmask,theconditionalmodulewillincorporatethecategoryinformationofsupportsetannotationsforforegroundmaskpredictions,ourmaskrenemodulecachesthecondenceregionmapsrecur-rentlyfornalforegroundprediction.
Inthecaseofk-shotlearning,previousworks[27,26,17]onsimplyaveragetheresultsofdifferent1-shotpredictions,whileweadoptanoptimization-basedmethodthatnetunesthemodelto4167Figure2.
ThepipelineofourNetworkarchitecture.
OurNetworkmainlyconsistsofaSiameseencoder,across-referencemodule,acon-ditionmodule,andamaskrenementmodule.
Ournetworkadoptsasymmetricdesign.
TheSiameseencodermapsthequeryandsupportimagesintofeaturerepresentations.
Thecross-referencemoduleminestheco-occurrentfeaturesintwoimagestogeneratereinforcedrepresentations.
Theconditionmodulefusesthecategory-relevantfeaturevectorsintofeaturemapstoemphasizethetargetcategory.
Themaskrenementmodulesavesthecondencemapsofthelastpredictionintothecacheandrecurrentlyrenesthepredictedmasks.
makeuseofmoresupportdata.
Table4demonstratestheadvantagesofourmethodoverpreviousworks.
4.
2.
SiameseencoderTheSiameseencoderisapairofparameter-sharedcon-volutionalneuralnetworksthatencodethequeryimageandthesupportimagetofeaturemaps.
Unlikethemod-elsin[17,14],weuseasharedfeatureencodertoencodethesupportandthequeryimages.
Byembeddingtheim-agesintothesamespace,ourcross-referencemodulecanbettermineco-occurrentfeaturestolocatetheforegroundregions.
Toacquirerepresentativefeatureembeddings,weuseskipconnectionstoutilizemultiple-layerfeatures.
AsisobservedinCNNfeaturevisualizationliterature[26,23],featuresinlowerlayersoftenrelatetolowlevelcueandhigherlayersoftenrelatetosegmentcue,wecombinethelowerlevelfeaturesandhigherlevelfeaturesandpassingtofollowedmodules.
4.
3.
Cross-ReferenceModuleThecross-referencemoduleisdesignedtomineco-occurrentfeaturesintwoimagesandgenerateupdatedrep-resentations.
ThedesignofthemoduleisshowninFig.
3.
GiventwoinputfeaturemapsgeneratedbytheSiameseen-coder,werstuseglobalaveragepoolingtoacquiretheglobalstatisticsinthetwoimages.
Then,thetwofeaturevectorsaresenttoapairoftwo-layerfullyconnected(FC)layers,respectively.
TheSigmoidactivationfunctionat-tachedaftertheFClayertransformsthevectorvaluesintotheimportanceofthechannel,whichisintherangeof[0,1].
Afterthat,thevectorsinthetwobranchesarefusedbyelement-wisemultiplication.
Intuitively,onlythecommonfeaturesinthetwobrancheswillhaveahighactivationinthefusedimportancevector.
Finally,weusethefusedvec-tortoweighttheinputfeaturemapstogeneratereinforcedfeaturerepresentations.
Incomparisontotherawfeatures,thereinforcedfeaturesfocusmoreontheco-occurrentrep-resentations.
Basedonthereinforcedfeaturerepresentations,weadda4168Figure3.
Thecross-referencemodule.
Giventheinputfea-turemapsfromthesupportandthequerysets(Fs,Fq),thecross-referencemodulegeneratesupdatedfeaturerepresentations(Gs,Gq)byinspectingtheco-occurrentfeatures.
headtodirectlypredicttheco-occurrentobjectsinthetwoimagesduringtrainingtime.
Thissub-taskaimstofacil-itatethelearningoftheco-segmentationmoduletominebetterfeaturerepresentationsforthedownstreamtasks.
Togeneratethepredictionsoftheco-occurrentobjectsintwoimages,thereinforcedfeaturemapsinthetwobranchesaresenttoadecodertogeneratethepredictedmaps.
ThedecoderiscomposedofconvolutionallayerfollowedbyaASPP[2]layers,nally,aconvolutionallayergeneratesatwo-channelpredictioncorrespondingtotheforegroundandbackgroundscores.
4.
4.
ConditionModuleTofullyutilizethesupportsetannotations,wedesignaconditionmoduletoefcientlyincorporatethecategoryinformationforforegroundmaskpredictions.
Thecon-ditionmoduletakesthereinforcedfeaturerepresentationsgeneratedbythecross-referencemoduleandacategory-relevantvectorasinputs.
Thecategory-relevantvectoristhefusedfeatureembeddingsofthetargetcategory,whichisachievedbyapplyingforegroundaveragepooling[26]overthecategoryregion.
Asthegoalofthefew-shotsegmen-tationistoonlyndtheforegroundmaskoftheassignedobjectcategory,thetask-relevantvectorservesasacondi-tiontosegmentthetargetcategory.
Toachieveacategory-relevantembedding,previousworksopttolteroutthebackgroundregionsintheinputimages[14,17]orinthefeaturerepresentations[26,27].
Wechoosetodosobothinthefeaturelevelandintheinputimage.
Thecategory-relevantvectorisfusedwiththereinforcedfeaturemapsintheconditionmodulebybilinearlyupsamplingthevectortothesamespatialsizeofthefeaturemapsandconcatenatingthem.
Finally,weaddaresidualconvolutiontoprocesstheconcatenatedfeatures.
Thestructureoftheconditionmod-ulecanbefoundinFig.
4.
Theconditionmodulesinthesupportbranchandthequerybranchhavethesamestruc-tureandsharealltheparameters.
4.
5.
MaskRenementModuleAsisoftenobservedintheweaklysupervisedseman-ticsegmentationliterature[26,8],directlypredictingtheFigure4.
Theconditionmodule.
Ourconditionmodulefusesthecategory-relevantfeaturesintorepresentationsforbetterpredic-tionsofthetargetcategory.
objectmaskscanbedifcult.
Itisacommonprincipletorstlylocateseedregionsandthenrenetheresults.
Basedonsuchprinciple,wedesignamaskrenementmoduletorenethepredictedmaskstep-by-step.
Ourmotivationisthattheprobabilitymapsinasinglefeed-forwardpredic-tioncanreectwhereisthecondentregioninthemodelprediction.
Basedonthecondentregionsandtheimagefeatures,wecangraduallyoptimizethemaskandndthewholeobjectregions.
AsshowninFig.
5,ourmaskrene-mentmodulehastwoinputs.
Oneisthesavedcondencemapinthecacheandthesecondinputistheconcatenationoftheoutputsfromtheconditionmoduleandthecross-referencemodule.
Fortheinitialprediction,thecacheisinitializedwithazeromask,andthemodulemakespredic-tionssolelybasedontheinputfeaturemaps.
Themodulecacheisupdatedwiththegeneratedprobabilitymapeverytimethemodulemakesanewprediction.
Werunthismod-ulemultipletimestogenerateanalrenedmask.
Themaskrenementmoduleincludesthreemainblocks:thedownsampleblock,theglobalconvolutionblock,andthecombineblock.
TheDownsampleBlockdownsamplesthefeaturemapsbyafactorof2.
Thedownsampledfea-turesarethenupsampledtotheoriginalsizeandfusedwithfeaturesintheoppositebranch.
Theglobalconvolutionblock[13]aimstocapturefeaturesinalargeeld-of-viewwhilecontainingfewparameters.
Itincludestwogroupsof1*7and7*1convolutionalkernels.
Thecombineblockeffectivelyfusesthefeaturebranchandthecachedbranchtogeneraterenedfeaturerepresentations.
4.
6.
FinetuningforK-ShotLearningInthecaseofk-shotlearning,weproposetonetuneournetworktotakeadvantageofmultiplelabeledsupportim-ages.
Asournetworkcanmakepredictionsfortwoimagesatatime,wecanuseatmostk2imagepairstonetuneournetwork.
Attheevaluationstage,werandomlysam-pleanimagepairfromthelabeledsupportsettonetuneourmodel.
WekeeptheparametersintheSiameseencoderxedandonlynetunetherestmodules.
Inourexperiment,wedemonstratethatournetuningbasedmethodscancon-sistentlyimprovetheresultwhenmorelabeledsupportim-agesareavailable,whilethefusion-basedmethodsinprevi-ousworksoftengetsaturatedperformancewhenthenum-berofsupportimagesincreases.
4169Figure5.
Themaskrenementmodule.
Themodulesavesthegeneratedprobabilitymapfromthelaststepintothecacheandrecurrentlyoptimizesthepredictions.
5.
Experiment5.
1.
ImplementationDetailsIntheSiameseencoder,weexploitmulti-levelfeaturesfromtheImageNetpre-trainedResnet-50astheimagerep-resentations.
Weusedilatedconvolutionsandkeepthefea-turemapsafterlayer3andlayer4haveaxedsizeof1/8oftheinputimageandconcatenatethemfornalpredic-tion.
Alltheconvolutionallayersinourproposedmoduleshavethekernelsizeof3*3andgeneratefeaturesof256channels,followedbytheReLUactivationfunction.
Attesttime,werecurrentlyrunthemaskrenementmodulefor5timestorenethepredictedmasks.
Inthecaseofk-shotlearning,wextheSiameseencoderandnetunetherestparameters.
5.
2.
DatasetandEvaluationMetricWeimplementcross-validationexperimentsonthePAS-CALVOC2012datasettovalidateournetworkdesign.
Tocompareourmodelwithpreviousworks,weadoptthesamecategorydivisionsandtestsettingswhicharerstproposedin[17].
Inthecross-validationexperiments,20objectcat-egoriesareevenlydividedinto4folds,withthreefoldsasthetrainingclassesandonefoldasthetestingclasses.
ThecategorydivisionisshowninTable1.
Wereporttheav-erageperformanceover4testingfolds.
Fortheevaluationmetrics,weusethestandardmeanIntersection-over-Union(mIoU)oftheclassesinthetestingfold.
Formorede-tailsaboutthedatasetinformationandtheevaluationmet-ric,pleasereferto[17].
6.
AblationstudyThegoaloftheablationstudyistoinspecteachcompo-nentinournetworkdesign.
OurablationexperimentsareconductedonthePASCALVOCdataset.
Weimplementfoldcategories0aeroplane,bicycle,bird,boat,bottle1bus,car,cat,chair,cow2diningtable,dog,horse,motobike,person3pottedplant,sheep,sofa,train,tv/monitorTable1.
TheclassdivisionofthePASCALVOC2012datasetpro-posedin[17].
ConditionCross-ReferenceModule1-shot36.
343.
349.
1Table2.
Ablationstudyontheconditionmoduleandthecross-referencemodule.
Thecross-referencemodulebringsalargeper-formanceimprovementoverthebaselinemodel(Conditiononly).
Multi-LevelMaskReneMulti-Scale1-shot49.
150.
353.
455.
2Table3.
Ablationexperimentsonthemultiple-levelfeature,multiple-scaleinput,andtheMaskRenemodule.
Everymod-ulebringsperformanceimprovementoverthebaselinemodel.
cross-validation1-shotexperimentsandreporttheaverageperformanceoverthefoursplits.
InTable2,werstinvestigatethecontributionsofourtwoimportantnetworkcomponents:theconditionmod-uleandthecross-referencemodule.
Asshown,therearesignicantperformancedropsifweremoveeithercompo-nentfromthenetwork.
Particularly,ourproposedcross-referencemodulehasahugeimpactonthepredictions.
Our4170Figure6.
OurQualitativeexamplesonthePASCALVOCdataset.
Therstrowisthesupportsetandthesecondrowisthequeryset.
Thethirdrowisourpredictedresultsandthethefourthrowisthegroundtruth.
Evenwhenthequeryimagescontainobjectsfrommultipleclasses,ournetworkcanstillsuccessfullysegmentthetargetcategoryindicatedbythesupportmask.
Method1-shot5-shot10-shotFusion49.
150.
249.
9FinetuneN/A57.
559.
1Finetune+FusionN/A57.
658.
8Table4.
k-shotexperiments.
Wecompareournetuningbasedmethodwiththefusionmethod.
Ourmethodyieldsconsistentper-formanceimprovementwhenthenumberofsupportimagesin-creases.
Forthecaseof1-shot,netuneresultsarenotavailableasCRNetneedsatleasttwoimagestoapplyournetunescheme.
networkcanimprovethecounterpartmodelwithoutcross-referencemodulebymorethan10%.
Toinvestigatehowmuchthescalevarianceoftheob-jectsinuencethenetworkperformance,weadoptamulti-scaletestexperimentinournetwork.
Specically,atthetesttime,weresizethesupportimageandthequeryimageto[0.
75,1.
25]oftheoriginalimagesizeandconducttheinfer-MethodBackbonemIoUIoUOSLM[17]VGG1640.
861.
3co-fcn[14]VGG1641.
160.
9sg-one[27]VGG1646.
363.
1R-DRCN[18]VGG1640.
160.
9PL[5]VGG16-61.
2A-MCG[6]ResNet-50-61.
2CANet[26]ResNet-5055.
466.
2PGNet[25]ResNet-5056.
069.
9CRNetVGG1655.
266.
4CRNetResNet-5055.
766.
8Table5.
Comparisonwiththestate-of-the-artmethodsunderthe1-shotsetting.
Ourproposednetworkachievesstate-of-the-artper-formanceunderbothevaluationmetrics.
ence.
Theoutputpredictedmaskoftheresizedqueryimageisbilinearlyresizedtotheoriginalimagesize.
Wefusethepredictionsunderdifferentimagescales.
AsshowninTa-4171MethodBackbonemIoUIoUOSLM[17]VGG1643.
961.
5co-fcn[14]VGG1641.
460.
2sg-one[27]VGG1647.
165.
9R-DFCN[18]VGG1645.
366.
0PL[5]VGG16-62.
3A-MCG[6]ResNet-50-62.
2CANet[26]ResNet-5057.
169.
6PGNet[25]ResNet5058.
570.
5CRNetVGG1658.
571.
0CRNetResNet5058.
871.
5Table6.
Comparisonwiththestate-of-the-artmethodsunderthe5-shotsetting.
Ourproposednetworkoutperformsallpreviousmethodsandachievesnewstate-of-the-artperformanceunderbothevaluationmetrics.
ble3,multi-scaleinputtestbrings1.
2mIoUscoreimprove-mentinthe1-shotsetting.
WealsoinvestigatethechoicesoffeaturesinthenetworkbackboneinTable3.
Wecom-parethemulti-levelfeatureembeddingswiththefeaturessolelyfromthelastlayer.
Ourmodelwithmulti-levelfea-turesprovidesanimprovementof1.
8mIoUscore.
Thisindicatesthattobetterlocatethecommonobjectsintwoimages,middle-levelfeaturesarealsoimportantandhelp-ful.
Tofurtherinspecttheeffectivenessofthemaskrene-mentmodule,wedesignabaselinemodelthatremovesthecachedbranch.
Inthiscase,themaskrenementblockmakespredictionssolelybasedontheinputfeaturesandweonlyrunthemaskrenementmoduleonce.
AsshowninTable3,ourmaskrenementmodulebrings3.
1mIoUscoreperformanceincreaseoverourbaselinemethod.
Inthek-shotsetting,wecompareournetuningbasedmethodwiththefusion-basedmethodswidelyusedinpre-viousworks.
Forthefusion-basedmethod,wemakeanin-ferencewitheachofthesupportimagesandaveragetheirprobabilitymapsasthenalprediction.
ThecomparisonisshowninTable4.
Inthe5-shotsetting,thenetuningbasedmethodoutperforms1-shotbaselineby8.
4mIoUscore,whichissignicantlysuperiortothefusion-basedmethod.
When10supportimagesareavailable,ournetuningbasedmethodshowsmoreadvantages.
Theperformancecon-tinuesincreasingwhilethefusion-basedmethod'sperfor-mancebeginstodrop.
6.
1.
MSCOCOCOCO2014[10]isachallenginglarge-scaledataset,whichcontains80objectcategories.
Following[26],wechoose40classesfortraining,20classesforvalidationand20classesfortest.
AsshowninTable.
7,theresultsagainvalidatethedesignsinournetwork.
ConditionCross-ReferenceModuleMask-Rene1-shot5-shot43.
344.
038.
542.
744.
945.
645.
847.
2Table7.
Ablationstudyontheconditionmodulecross-referencemoduleandMask-renemoduleondatasetMSCOCO.
6.
2.
ComparisonwiththeState-of-the-ArtResultsWecompareournetworkwithstate-of-the-artmethodsonthePASCALVOC2012dataset.
Table5showstheper-formanceofdifferentmethodsinthe1-shotsetting.
WeuseIoUtodenotetheevaluationmetricproposedin[14].
ThedifferencebetweenthetwometricsisthattheIoUmetricalsoincorporatesthebackgroundintotheIntersection-over-Unioncomputationandignorestheimagecategory.
5-ShotExperiments.
Thecomparisonof5-shotseg-mentationresultsundertwoevaluationmetricsisshowninTable6.
Ourmethodachievesnewstate-of-the-artperfor-manceunderbothevaluationmetrics.
7.
ConclusionInthispaper,wehavepresentedanovelcross-referencenetworkforfew-shotsegmentation.
Unlikepreviousworkunilaterallyguidingthesegmentationofqueryimageswithsupportimages,ourtwo-headdesignconcurrentlymakespredictionsinboththequeryimageandthesupportimagetohelpthenetworkbetterlocatethetargetcategory.
Wedevelopamaskrenementmodulewithacachemecha-nismwhichcaneffectivelyimprovethepredictionperfor-mance.
Inthek-shotsetting,ournetuningbasedmethodcantakeadvantageofmoreannotateddataandsignicantlyimprovestheperformance.
ExtensiveablationexperimentsonPASCALVOC2012datasetvalidatetheeffectivenessofourdesign.
Ourmodelachievesstate-of-the-artperfor-manceonthePASCALVOC2012dataset.
AcknowledgementsThisresearchissupportedbytheNationalResearchFoundationSingaporeunderitsAISingaporeProgramme(AwardNumber:AISG-RP-2018-003)andtheMOETier-1researchgrants:RG126/17(S)andRG22/19(S).
Thisre-searchisalsopartlysupportedbytheDelta-NTUCorporateLabwithfundingsupportfromDeltaElectronicsInc.
andtheNationalResearchFoundation(NRF)Singapore.
References[1]HongChen,YifeiHuang,andHidekiNakayama.
Semanticawareattentionbaseddeepobjectco-segmentation.
arXivpreprintarXiv:1810.
06859,2018.
2,3[2]Liang-ChiehChen,GeorgePapandreou,IasonasKokkinos,KevinMurphy,andAlanLYuille.
Deeplab:Semanticimage4172segmentationwithdeepconvolutionalnets,atrousconvolu-tion,andfullyconnectedcrfs.
IEEEtransactionsonpatternanalysisandmachineintelligence,40(4):834–848,2018.
2,5[3]Wei-YuChen,Yen-ChengLiu,ZsoltKira,Yu-ChiangWang,andJia-BinHuang.
Acloserlookatfew-shotclassication.
InInternationalConferenceonLearningRepresentations,2019.
2[4]JiaDeng,WeiDong,RichardSocher,Li-JiaLi,KaiLi,andLiFei-Fei.
Imagenet:Alarge-scalehierarchicalimagedatabase.
InCVPR,pages248–255,2009.
1[5]NanqingDongandEricXing.
Few-shotsemanticsegmenta-tionwithprototypelearning.
InBMVC,2018.
3,7,8[6]TaoHu,PengwanYang,ChiliangZhang,GangYu,YadongMu,andCeesGMSnoek.
Attention-basedmulti-contextguidingforfew-shotsemanticsegmentation.
2019.
3,7,8[7]ArmandJoulin,FrancisBach,andJeanPonce.
Multi-classcosegmentation.
In2012IEEEConferenceonComputerVi-sionandPatternRecognition,pages542–549.
IEEE,2012.
2,3[8]AlexanderKolesnikovandChristophHLampert.
Seed,ex-pandandconstrain:Threeprinciplesforweakly-supervisedimagesegmentation.
InEuropeanConferenceonComputerVision,pages695–711.
Springer,2016.
5[9]GuoshengLin,AntonMilan,ChunhuaShen,andIanDReid.
Renenet:Multi-pathrenementnetworksforhigh-resolutionsemanticsegmentation.
InCVPR,volume1,page5,2017.
2[10]Tsung-YiLin,MichaelMaire,SergeBelongie,JamesHays,PietroPerona,DevaRamanan,PiotrDollar,andCLawrenceZitnick.
Microsoftcoco:Commonobjectsincontext.
InECCV,pages740–755,2014.
8[11]JonathanLong,EvanShelhamer,andTrevorDarrell.
Fullyconvolutionalnetworksforsemanticsegmentation.
InPro-ceedingsoftheIEEEconferenceoncomputervisionandpat-ternrecognition,pages3431–3440,2015.
2[12]PreranaMukherjee,BrejeshLall,andSnehithLattupally.
Objectcosegmentationusingdeepsiamesenetwork.
arXivpreprintarXiv:1803.
02555,2018.
2,3[13]ChaoPeng,XiangyuZhang,GangYu,GuimingLuo,andJianSun.
Largekernelmatters–improvesemanticsegmen-tationbyglobalconvolutionalnetwork.
InProceedingsoftheIEEEconferenceoncomputervisionandpatternrecog-nition,pages4353–4361,2017.
5[14]KateRakelly,EvanShelhamer,TrevorDarrell,AlyoshaEfros,andSergeyLevine.
Conditionalnetworksforfew-shotsemanticsegmentation.
InICLRWorkshop,2018.
4,5,7,8[15]CarstenRother,TomMinka,AndrewBlake,andVladimirKolmogorov.
Cosegmentationofimagepairsbyhistogrammatching-incorporatingaglobalconstraintintomrfs.
In2006IEEEComputerSocietyConferenceonComputerVi-sionandPatternRecognition(CVPR'06),volume1,pages993–1000.
IEEE,2006.
3[16]MichaelRubinstein,ArmandJoulin,JohannesKopf,andCeLiu.
Unsupervisedjointobjectdiscoveryandsegmentationininternetimages.
InProceedingsoftheIEEEconferenceoncomputervisionandpatternrecognition,pages1939–1946,2013.
3[17]AmirrezaShaban,ShrayBansal,ZhenLiu,IrfanEssa,andByronBoots.
One-shotlearningforsemanticsegmentation.
arXivpreprintarXiv:1709.
03410,2017.
3,4,5,6,7,8[18]MennatullahSiamandBorisOreshkin.
Adaptivemaskedweightimprintingforfew-shotsegmentation.
arXivpreprintarXiv:1902.
11123,2019.
7,8[19]JakeSnell,KevinSwersky,andRichardZemel.
Prototypicalnetworksforfew-shotlearning.
InNIPS,2017.
2,3[20]XinSun,ZhenningYang,ChiZhang,GuohaoPeng,andKeck-VoonLing.
Conditionalgaussiandistributionlearningforopensetrecognition,2020.
2[21]OriolVinyals,CharlesBlundell,TimothyLillicrap,DaanWierstra,etal.
Matchingnetworksforoneshotlearning.
InAdvancesinneuralinformationprocessingsystems,pages3630–3638,2016.
2[22]FloodSungYongxinYang,LiZhang,TaoXiang,PhilipHSTorr,andTimothyMHospedales.
Learningtocompare:Re-lationnetworkforfew-shotlearning.
InCVPR,2018.
2[23]JasonYosinski,JeffClune,AnhNguyen,ThomasFuchs,andHodLipson.
Understandingneuralnetworksthroughdeepvisualization.
arXivpreprintarXiv:1506.
06579,2015.
4[24]ChiZhang,YujunCai,GuoshengLin,andChunhuaShen.
Deepemd:Few-shotimageclassicationwithdifferentiableearthmover'sdistanceandstructuredclassiers,2020.
2[25]ChiZhang,GuoshengLin,FayaoLiu,JiushuangGuo,QingyaoWu,andRuiYao.
Pyramidgraphnetworkswithconnectionattentionsforregion-basedone-shotsemanticsegmentation.
InProceedingsoftheIEEEInternationalConferenceonComputerVision,pages9587–9595,2019.
7,8[26]ChiZhang,GuoshengLin,FayaoLiu,RuiYao,andChunhuaShen.
Canet:Class-agnosticsegmentationnetworkswithit-erativerenementandattentivefew-shotlearning.
InPro-ceedingsoftheIEEEConferenceonComputerVisionandPatternRecognition,pages5217–5226,2019.
3,4,5,7,8[27]XiaolinZhang,YunchaoWei,YiYang,andThomasHuang.
Sg-one:Similarityguidancenetworkforone-shotsemanticsegmentation.
arXivpreprintarXiv:1810.
09091,2018.
3,5,7,84173
- prototypeavmask.net相关文档
- jednostavnoavmask.net
- Compatibilityavmask.net
- DWORDavmask.net
- suspectedavmask.net
- loadsavmask.net
- notesavmask.net
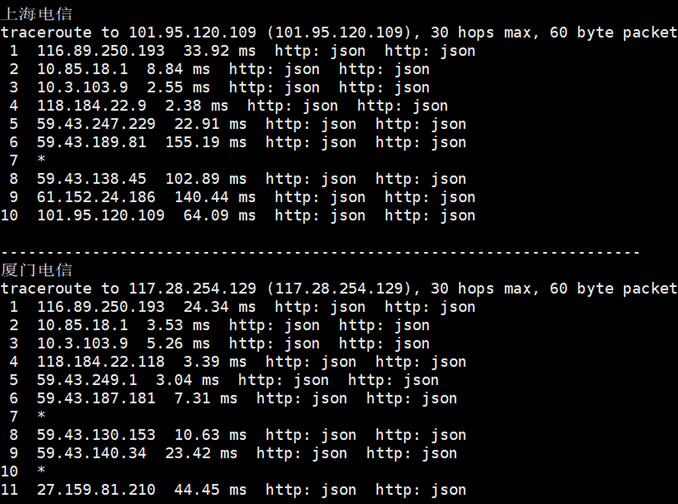
香港2GB内存DIYVM2核(¥50月)香港沙田CN2云服务器
DiyVM 香港沙田机房,也是采用的CN2优化线路,目前也有入手且在使用中,我个人感觉如果中文业务需要用到的话虽然日本机房也是CN2,但是线路的稳定性不如香港机房,所以我们在这篇文章中亲测看看香港机房,然后对比之前看到的日本机房。香港机房的配置信息。CPU内存 硬盘带宽IP价格购买地址2核2G50G2M1¥50/月选择方案4核4G60G3M1¥100/月选择方案4核8G70G3M4¥200/月选择...
蓝竹云挂机宝25元/年,美国西雅图 1核1G 100M 20元
蓝竹云怎么样 蓝竹云好不好蓝竹云是新商家这次给我们带来的 挂机宝25元/年 美国西雅图云服务器 下面是套餐和评测,废话不说直接开干~~蓝竹云官网链接点击打开官网江西上饶挂机宝宿主机配置 2*E5 2696V2 384G 8*1500G SAS RAID10阵列支持Windows sever 2008,Windows sever 2012,Centos 7.6,Debian 10.3,Ubuntu1...
易探云香港vps主机价格多少钱?香港云服务器主机租用价格
易探云香港vps主机价格多少钱?香港vps主机租用费用大体上是由配置决定的,我们选择香港vps主机租用最大的优势是免备案vps。但是,每家服务商的机房、配置、定价也不同。我们以最基础配置为标准,综合比对各大香港vps主机供应商的价格,即可选到高性能、价格适中的香港vps主机。通常1核CPU、1G内存、2Mbps独享带宽,价格在30元-120元/月。不过,易探云香港vps主机推出四个机房的优惠活动,...

avmask.net为你推荐
-
原代码源代码是什么bbs2.99nets.com这个"风情东南亚"网站有78kg.cn做网址又用bbs.风情东南亚.cn那么多此一举啊!www.45gtv.com登录农行网银首页www.abchina.com,ww.66bobo.com这个WWW ̄7222hh ̄com是不是真的不太易开了,换了吗?www.dm8.cc有没有最新的日本动漫网站?雀嘴鳝专家教下怎么才能饲养好一条雀鳝鱼?长房娇谁知道以下几种都是什么花?花期多长?窝尚公寓窝趣公寓是独立居住还是和合租形式?新广告法新广告法9月1日起正式执行 极限用语罚款20万起查看源代码如何查看软件源代码