算法空间有黄的qq
空间有黄的qq 时间:2021-04-21 阅读:()
第37卷第1期计算机应用研究Vol.
37No.
1录用定稿ApplicationResearchofComputersAcceptedPaper收稿日期:2018-06-28;修回日期:2018-08-24基金项目:国家重点研发计划资助项目(2016YFB0800100);国家自然科学基金面上项目(61572444)作者简介:陈晓杰(1993-),男,河南武陟人,硕士研究生,主要研究方向为信息安全(740248499@qq.
com);周清雷(1962-),男,河南郑州人,教授,博导,博士,主要研究方向为信息安全自动机理论及计算复杂性理论;李斌(1986-),男,河南郑州人,博士研究生,主要研究方向为信息安全高性能计算.
基于多核FPGA的压缩文件密码破译*陈晓杰1,周清雷1,李斌2(1.
郑州大学信息工程学院,郑州450001;2.
信息工程大学数字工程与先进计算国家重点实验室,郑州450001)摘要:目前,破解WinRAR传统方法是使用CPU和GPU,而潜在的密码空间非常大,需要更高性能计算平台才能在有限的时间内找到正确的密码.
因此,采用四核FPGA的硬件平台,实现高效能的WinRAR破解算法.
通过在全流水架构下增加预计算和保留进位加法器结合的方法优化SHA-1算法,提升算法吞吐率;利用状态机的控制优化数据拼接,提升算法并行性;同时,采用异步时钟和多个FIFO缓存读写数据优化算法整体架构,降低算法内部的耦合度.
实验结果表明,最终优化后的算法资源利用率为75%,频率达到200MHz,4bit长度的密码破译速度为每秒102796个,是CPU破解速度的100倍,是GPU的3.
5倍.
关键词:信息安全;密码破译;FPGA;高性能计算;WinRAR中图分类号:TP309.
7doi:10.
19734/j.
issn.
1001-3695.
2018.
06.
0478Passwordrecoveryforcompressedfilebasedonmulti-FPGAChenXiaojie1,ZhouQinglei1,LiBin2(1.
SchoolofInformationEngineering,ZhengzhouUniversity,Zhengzhou450001,China;2.
StateKeyLaboratoryofMathematicalEngineering&AdvancedComputing,InformationEngineeringUniversity,Zhengzhou450001,China)Abstract:Atpresent,thetraditionalmethodofcrackingWinRARistousetheCPUandGPU,butthepotentialpasswordspaceisverylargewhichrequiriesahigherperformancecomputingplatformtofindthecorrectpasswordwithinalimitedtime.
Therefore,thispaperusesthehardwareplatformofmulti-FPGAtoachieveahigh-performanceWinRARcrackalgorithm.
TheSHA-1algorithmwasoptimizedbyaddingpre-calculationandcarrysavingadderunderthefull-pipelinearchitecture,soastoimprovethethroughputofthealgorithm.
Andtheuseofstatemachinecontroltooptimizedatasplicing,toimprovealgorithmparallelism.
Atthesametime,itusedtheasynchronousclockandmultipleFIFObufferstoreadandwritetheoverallstructureofthedataoptimizationalgorithmtoreducethecouplingwithinthealgorithm.
Theexperimentalresultsshowthatthefinaloptimizedresourceutilizationrateis75%andthefrequencyreaches200MHz.
The4-bytepassworddecipheringspeedis102,796persecond,whichis100timesfasterthanCPUand3.
5timesfasterthanGPU.
Keywords:informationsecurity;passwordcracking;FPGA;high-performancecomputing;WinRAR0引言压缩软件WinRAR是一款RAR压缩文件管理器,具有压缩、纠错、加密等多种功能,并且支持多种压缩格式的解压.
其压缩速度快、压缩效率高等多种优势得到了个人、机构、组织等的广泛使用.
WinRAR密码加密使用对称加密算法AES和单向不可逆算法SHA-1,这两种算法在目前的计算能力下能保证很高的安全性.
但是,这也使需要对WinRAR进行快速密码破译的信息安全和计算机取证带来了一定的困难.
目前,破译WinRAR的密码采用字典+穷举的方法,但随着密码长度的增加,可能的空间呈指数倍增长.
近期研究发现用户密码服从Zipf分布,而不是长期假设的均匀分布[1].
这一发现对"用户密码"的研究有很重要的指导意义.
在密码破译中也能够暂时性的缩减密码空间.
文献[2,3,4]中详细研究讨论了"口令猜测算法"及"口令猜测模型",并利用社会工程学等方法获得针对性的信息,从而分析出某些高概率口令的特征,或者针对某一用户的高概率口令.
因此,利用这些高概率口令可以破译很多用户密码,缩减了密码空间,提高破译效率.
虽然密码空间能够缩小很大一部分,但是一个高效能的计算平台对进一步提高破译效率具有很重要的作用.
现有的破解方法主要有依托于CPU平台的密码软件破解,破解速度慢.
基于OpenCL和CUDA架构的GPU平台破解,chinaXiv:201811.
00131v1ChinaXiv合作期刊录用定稿陈晓杰,等:基于多核FPGA的压缩文件密码破译第37卷第1期由于其受到访存的限制,影响了计算性能的提升,而且功耗较高.
因此,需要更高效的计算平台来提高破解的效率.
现场可编程门阵列(fieldprogrammablegatearray,FPGA)经过近30年的发展,已成为实现数字系统的主流平台之一,在以太网交换机传输数据、图像压缩、模板计算的加速等方面都得到了较好的应用[5-7].
将FPGA用于WinRAR的密码解密中,利用流水线并行工作的方式,可实现WinRAR密码破解算法的高效性.
本文的主要工作是基于四核FPGA硬件平台,提出对SHA-1算法关键路径的优化,并通过状态机的控制优化数据拼接.
算法的整体架构采用异步时钟使核心模块运算频率最大化,并使用多个独立时钟双端口BlockRAM实现的FIFO配合全流水线进行数据缓存读写.
最后通过实验,对比不同平台WinRAR破解算法的性能,表明本文优化后的算法性能有明显的提升.
1算法分析WinRAR破解算法主要分为四步,具体流程如下:a)提取特征串.
从压缩文件中提取盐值salt和哈希值digest,用于输入计算.
b)数据拼接和SHA-1运算.
将可能的密码(宽子节)、8Byte的盐值、3Byte的num依次进行拼接.
其中,num表示拼接的次数.
整个解密过程一共需要拼接262145次,每拼接64字节需要进行一次SHA-1运算.
每拼接16384次需要进行一次额外的SHA-1运算,用于获取密钥key和iv值.
c)AES运算.
将digest与key做AES运算,得到aes_r,并将aes_r与iv异或,得到xor_r.
d)比较.
将xor_r和一个固定值进行比较,判断密码是否正确.
算法结构如图1所示.
图1解密算法结构图Fig.
1Decryptionalgorithmstructure在整个算法中计算量最大的就是数据拼接操作和SHA-1运算,并且随着密码长度的增大,需要进行SHA-1运算的次数呈线性增长,计算需要的时间也呈线性增长,如图2所示.
图中以计算一个4位长度密码的时间为基准单位来衡量其他长度密码的计算时间.
从算法分析中可以知道对数据拼接操作和SHA-1的优化对算法的整体性能提升有至关重要的作用.
文献[8]中在GPU平台下在CPU端预先生成一个拼接表,再将此表一部分放到共享内存中,为GPU端进行计算,最终在w8000GPU上破解4位长度密码的性能达到了每秒10100个,比商业破解软件AccentRAR在GPU上快了2倍多.
文献[9]中在GPU平台下通过增加三个数组的方式减少状态跳变和数据链接所需要的时间,再结合GPU本身的优势进行优化,比AccentRAR在CPU上的速度高43到57倍.
文献[10]是基于CUDA架构对整体算法进行优化,提高了性能.
文献[11]通过对口令空间采用一种基于并行随机搜索的新方法生成字典,提高破解的成功率.
在FPGA平台上,对于SHA-1算法的优化,文献[12,13,14]通过使用保留进位加法器(CarrySaveAdders,CSA)的方式减少关键路径的延时.
文献[15]通过增加P、Q、R三个中间变量进行预计算减少延时.
文献[16]基于循环展开方法的40级流水线提高算法的吞吐率.
文献[17,18]利用循环展开和预计算的方式减少关键路径的长度和循环的轮数,达到高速运行.
图2不同密码长度对应的SHA-1次数及相对时间Fig.
2ThenumberofSHA-1andrelativetime上述研究WinRAR破解性能的提升主要集中在GPU平台,由于GPU要和CPU共享内存,限制了性能的提升,且功耗较高.
对于FPGA平台,SHA-1算法的优化仍然有很大的提升空间.
因此,本文的研究基于低功耗的四核FPGA硬件平台,通过优化数据拼接操作和进一步优化SHA-1算法,提升算法效率.
2算法优化及实现2.
1SHA-1算法优化SHA-1算法自1995年修订发布以来,广泛应用于数字签名、传输层安全、安全电子交易、无线局域网等信息安全领域.
SHA-1加密流程为补位、初始向量值、80轮循环运算、自加运算.
其中80轮运算的作用是更新A、B、C、D、E五个值,并作为最后的输出,每个值32位,一共160位,而A值为,t代表轮数,f是逻辑函数,K是常数,W的值为,S是循环函数.
A值是运算的最长路径,也是整个运算的关键路径.
因此,优化SHA-1算法的关键路径决定了整体的运行效率.
2.
1.
1SHA-1算法优化方法算法的吞吐量与频率、流水线级数成正比[21],因此本文采用预计算与保留进位加法器策略减少关键路径的延时,提高算法的频率,并采用全流水线实现算法,从而能够提高算法的吞吐量.
SHA-1算法核心迭代需要80轮运算,且每轮运算需要上轮运算的结果,运算过程中每轮运算互不干扰.
同时,在进chinaXiv:201811.
00131v1ChinaXiv合作期刊录用定稿陈晓杰,等:基于多核FPGA的压缩文件密码破译第37卷第1期行密码尝试中,每个密码的计算又是相互独立的.
因此,可以采用并行全流水线方法实现,80轮运算需要80个时钟周期,再加上预计算与输出一共82级流水线.
预计算通过增加寄存器G,使关键路径变为两个加法运算和位运算,减少关键路径的延时.
FPGA适合于位运算,而加法运算延时比位运算高,保留进位加法器CSA策略能够减少加法运算,最小化关键路径长度,保证流水吞吐率[19].
CSA运算如下,其中a、b、c为n位二进制数:通过增加位运算来减少加法运算,在关键路径运用保留进位加法器使加法运算变为一个从而来减少延迟.
因此,在全流水线架构下增加预计算和保留进位加法器策略能够降低延时,提高算法效率.
2.
1.
2SHA-1算法优化实现在具体实现算法时,分为三个主要模块协同工作实现全流水线技术,并且在其中引入预计算和保留进位加法器策略.
第一个是W模块用于计算每轮W的值,需要定义如下寄存器数组:这样定义可以节省3840个寄存器资源,其中W_next[i]由W[i]计算得到,i从0到63.
数组赋值及传递如图3所示.
图3数组W实现全流水线的逻辑结构图Fig.
3ArrayWtoachievethefull-pipelinelogicstructure图3中将数组W全部展开,使数据传递的过程更加清晰,输入数据DATA经过80个时钟周期完成W的全部计算.
单个时钟周期内,数组之间并行处理,且相邻数组数据串行传递,从而实现全流水线的计算,提高了时间效率和资源利用率.
第二个是预计算模块.
定义32位宽的寄存器数组G[80],在每轮运算时都预先计算G的值,从而减少关键路径的长度.
80轮运算需要计算80个G的值,且不同数据的值依次传递,实现了数据内的串行,数据间的并行.
第三个模块是数据更新模块,用来更新A、B、C、D、E的值,其中更新A的值是关键,其更新如下:通过使用CSA更新A值,减少了关键路径的延时.
因为每轮运算逻辑函数f不同,这一部分又分为四个小模块,但是功能都相同,且同样需要实现流水线架构.
因此,最终需要实例化80份,以消耗资源换取时间效率最大化.
图4显示了三个模块协同工作实现SHA-1算法的全流水线结构.
图4三个模块实现的全流水架构图Fig.
4Threemodulestoachievethefull-pipelinestructure2.
2基于状态机的数据拼接优化在WinRAR密码解密中,数据拼接需要拼接262145次,且每拼接64字节还要进行SHA-1运算,同时还要保存拼接到的位置,以便于下一次拼接从这个位置开始.
由于拼接次数多、拼接时间长成为了算法效率提升的瓶颈.
SHA-1算法采用82级流水线,数据拼接的数据要输入到SHA-1运算,数据拼接需要在82个时钟周期内完成82组数据的64字节拼接操作.
因此,本文基于状态机的控制,通过增加位宽为8的寄存器数组pwd_array[39:0]、temp_array[63:0]、flag_array[63:0]、final_array[63:0]使数据拼接能够并行处理,实现流水线的数据传递,提升算法的效率.
图5最终的数据拼接方法Fig.
5Thefinaldatalinkmethod在实现中,数组pwd_array用于存储密码,并将密码补位变为2字节的宽字节,且支持密码达到20位.
数组temp_array用于存储盐值和num到相应位置.
数组flag_array用于标记口令所在的位置,初始化均设为0xff,根据状态机来更改数组的值,最后的拼接根据这个值的大小来判断是什么值,并且判断数据所在的位置.
相同密码的temp_array、flag_array值相同,只需赋值一次,可供流水线82个密码共同使用,从而提升时间效率.
数组final_array则存储最后SHA-1运算的输入值.
以密码"1234"为例,在图5中显示了这四个数组是如何赋值的以及如何拼接的,图中的值都是ASCII码16进制显示.
chinaXiv:201811.
00131v1ChinaXiv合作期刊录用定稿陈晓杰,等:基于多核FPGA的压缩文件密码破译第37卷第1期数组的赋值依赖于状态机的控制.
状态机控制着数据拼接的开始,初始化,拼接中的数据赋值,状态的保存及状态的返回.
具体状态控制如下:状态1对数据进行初始化,包括计算密码的长度len1,密码和盐值的长度len2,用于后续判断填充的位置.
状态2控制拼接的开始、结束和重返初始状态.
状态3判断再拼接一轮是否到64字节,如果不超过,则转到状态4.
如果超过,则先将不超过的部分根据len1和len2的大小给数组temp_array、flag_array赋值,并且保存拼接到的位置,同时根据计数器判断给数组final_array赋值用于流水线数据传递计算,再转到状态4.
状态4:根据3状态保存的位置继续下一轮的数组赋值,如果拼够一轮,则返回状态2,拼接次数loop加1,如此循环,状态转换图如图6所示.
图6状态转换图Fig.
6Statetransitiondiagram通过状态的跳变给数组temp_array、flag_array赋值使拼接结构更加清晰,且仅需赋值一次可使流水线计算共同使用,降低了拼接消耗的时间.
通过中间数组flag_array作为标记,间接链接到密码,使数据的拼接能够并行化,降低结构复杂度,实现流水线,提升算法效率.
2.
3整体算法优化为了从FPGA和强大的计算机辅助设计工具的优势中获益,设计师必须遵循一种高效的设计方法.
这种方法基于三个主要原则:控制算法的细化,模块化和最佳的适用性,以及所选择的硬件架构[20].
为了达到这种高效的方法,在整体算法的设计实现时,需要充分利用板卡的LUT与FF资源,使FPGA芯片能够满负荷工作.
因此,本文整体算法的设计主要分为上层控制和核心算子两部分.
前者通过控制可以实例化多个核心算子,并且对多个算子的结果进行回收,实现多个算子并行工作,从而提升算法的整体性能.
上层控制又细分为外部接口模块用于从CPU端获取数据,数据管理与分发模块用于将数据提供给多个核心算子.
核心算子分为密码穷举模块、核心运算模块和比较模块.
模块与模块之间使用IPCatalog生成双端口BlockRAM实现的FIFO缓存数据和读写数据.
通过FIFO在模块之间进行数据的传递,降低算法模块之间的耦合度,提升算法的并行性.
同时尽量减少CPU与FPGA的交互,避免速度的差异致使性能的降低.
密码穷举模块实现为掩码字典的方式,在实现时通过上位机传输掩码字典到FPGA的口令穷举模块产生相应的口令.
掩码字典是一种穷举规则,而在规则中可以包含高概率口令,从而通过人为控制优先测试高概率口令,缩减破译的时间.
细粒度模块结构如图7所示.
图7细粒度模块结构图Fig.
7Fine-grainedmodulestructure算法的吞吐量、运行速度与时钟频率是正相关,时钟频率越高,运行效率也越高.
但是频率过高,容易产生时序阻塞问题,致使FPGA布线失败,因此要对时钟频率进行优化.
分析整个算法,可以发现计算量最大、计算最复杂的是SHA-1运算和数据拼接部分,这两个核心运算部分可以设计成一个高频率时钟,加快核心运算速度.
而为这两部分提供数据的上层控制模块和口令穷举模块采用低频率时钟足以满足核心计算需求.
通过将时钟域分离,既能充分利用板卡性能,也能最大化降低时序问题,使算法性能进一步提升.
3实验结果及分析本文实验的硬件平台是在四核FPGA集成加速卡上实现,芯片型号为XILINX公司的XCKU060,其查找表LUT资源是331680,FlipFlops寄存器资源是663360.
软件平台为集设计、仿真、综合、布线、生成于一体的Vivado软件.
通过对算法的不同部分进行相应优化,使最终算法在吞吐量、运行速度、资源利用率等方面有较大的提升.
表1不同文献SHA-1实现性能对比Table1SHA-1performancecomparison对比文献流水线级数最大频率吞吐量文献[12]8243.
08MHz22.
056Gbps文献[13]81272MHz139.
264Gbps文献[14]81303.
3MHz155.
289Gbps文献[15]83123.
3MHz63.
129Gbps文献[16]40163.
7MHz76.
195Gbps文献[17]4150.
7MHz7.
35Gbps本文82470MHz240.
64Gbps本文在实现全流水线架构的基础上通过使用预计算和保留进位加法器对SHA-1算法进行优化,其优化后的性能如表1所示,在表1中同时给出了其他文献实现的性能.
通过对比,可以发现本文优化后的性能在频率上达到470MHz,吞吐量达到了240.
64Gbps,比最高吞吐量的文献[14]还高出了85Gbps,是文献[16]的32倍,性能有了显著提升.
为了更进一步的验证优化后的性能,设计了表2的5种方案在XCKU060上实现.
chinaXiv:201811.
00131v1ChinaXiv合作期刊录用定稿陈晓杰,等:基于多核FPGA的压缩文件密码破译第37卷第1期表2不同优化对比方案Table2Differentoptimizationcomparisonproject方案不同优化方法1不进行任何优化2增加预计算进行优化3增加预计算并且使用CSA,关键路径也使用CSA4不使用预计算,但是在关键路径使用两次CSA5不使用预计算,在关键路径使用CSA5表2中CSA5是对CSA的扩展,其运算如下:5种方案都是在全流水线和全展开的基础上再优化实现,实现结果如表3所示.
表3不同方案资源综合表Table3Differentprojectresourcesintegratedtable对比方案LUT消耗(占比)FF消耗(占比)最大频率111768(3.
55%)19488(2.
94%)340MHz211967(3.
61%)26483(4.
00%)420MHz311355(4.
42%)21290(3.
21%)425MHz414809(4.
46%)20100(3.
03%)415MHz515639(4.
72%)21173(3.
19%)367MHz最终方案9415(2.
84%)21514(3.
24%)470MHz从表中可以看出使用预计算和保留进位加法器结合进行优化与其他类型的优化相比在最高频率方面是最优的,和不进行任何优化相比算法频率提升130MHz.
所有采用预计算的方案与不使用预计算优化相比,其寄存器都有较高消耗.
图8不同密码长度的破解速率Fig.
8Differentpasswordcrackingrate通过对SHA-1算法、数据拼接、以及整体架构优化,并且尽可能的使用芯片资源,最终算法实例化10个核心算子模块,占用资源为75%,实验结果的整体算法优化性能如图8所示.
从图8中可以看出,在不同密码对应的破解速度在多核FPGA板卡上性能是单核的4倍,在密码长度为4的破译速率达到每秒102796个.
通过控制使核与核之间并行运行,且支持多任务.
当有大量的加密文档需要恢复时,在每个核运行不同的任务,通过高概率口令的优先穷举,能够很快恢复出其中大部分的口令.
与其他文献方法对比,如表4所示.
表4不同文献破解算法性能表现Table4Differentresearchalgorithmsperformance对比文献实验平台(型号)速率加速比AccentRARCPU(I7)10001.
00文献8GPU(W8000)1010010.
10文献9GPU(W8000)1777817.
78本文FPGA(XCKU060)102796102.
80以软件AccentRAR的性能作为基准,本文的性能达到了其100倍,比其他文献的方法性能高很多.
Hashcat是一个提供基于OpenCL的开源破解软件的网站,其破解性能好,破解算法多等受到大家的广泛使用,因此本文使用Hashcat在GPU(GTX1080)上作验证对比,比较结果如图9所示.
图9不同密码长度破译性能对比Fig.
9Differentpasswordlengthperformance从图中可以看出本文的性能达到了Hashcat的3.
5倍.
将本文的优化结果与其他文献、软件对比,实验结果表明了本文的方案有较大的性能提升.
4结束语当前RAR口令密码破译主要是在CPU和GPU平台,前者主要的问题是破译速度慢,远远不能满足口令空间的指数级增长,后者由于涉及到访存问题,限制了破译性能,并且功耗较高.
针对这些问题,本文提出了多核FPGA硬件平台破译的方法,在全流水线架构下采用预计算和保留进位加法器策略缩短关键路径来优化SHA-1算法,使SHA-1算法的吞吐量达到了240.
64Gbps.
结合FPGA的低功耗、并行性、时钟频率高等优势对破解算法的数据拼接和整体架构进行优化,使算法最终的频率达到200MHz,破解四位密码长度的性能达到每秒102796个,并通过与其他文献进行对比,表明在多核FPGA的硬件平台,优化算法后实现的性能有明显的提升,也表明了优化算法方法的可行性.
虽然本文提出的方法使破译性能有了很大的提升,但是对于庞大的口令空间,其计算性能仍然很难满足实际的需求,因此,生成高概率密码结合本文的性能才能更大的提高破译的成功率.
而高概率密码则需要结合诸如大数据,统计,人工智能等多方面的知识,而这些将会是破解成功的关键及以后的工作重点.
chinaXiv:201811.
00131v1ChinaXiv合作期刊录用定稿陈晓杰,等:基于多核FPGA的压缩文件密码破译第37卷第1期参考文献:[1]WangDing,JianGaopeng,HuangXinyi,etal.
Zipf'slawinpasswords[J].
IEEETransonInformationForensicsandSecurity,2017,12(11):2776-2791.
[2]MaJ,YangWeining,LuoMin,etal.
Astudyofprobabilisticpasswordmodels[C]//SecurityandPrivacy.
2014:689-704.
[3]DingWang,ZhangZijian,WangPing,etal.
Targetedonlinepasswordguessing:anunderestimatedthreat[C]//ProcofACMSIGSACConferenceonComputerandCommunicationsSecurity.
NewYork:ACMPress,2016:1242-1254.
[4]王平,汪定,黄欣沂.
口令安全研究进展[J].
计算机研究与发展,2016,53(10):2173-2188.
(WangPing,WangDing,HuangXinyi.
Advancesinpasswordsecurity[J].
JournalofComputerResearchandDevelopment,2016,53(10):2173-2188.
)[5]BitarA,CassidyJ,JergerNE,etal.
EfficientandprogrammableethernetswitchingwithaNoC-enhancedFPGA[C]//Procofthe10thACM//IEEESymposiumonArchitecturesforNetworkingandCommunicationsSystems.
NewYork:ACMPress,2014:89-100.
[6]BayerFM,CintraRJ,EdirisuriyaA,etal.
Adigitalhardwarefastalgorithmandfpga-basedprototypeforanovel16-pointapproximateDCTforimagecompressionapplications[J].
MeasurementScience&Technology,2012,23(11).
[7]WaidyasooriyaHM,TakeiY,TatsumiS,etal.
OpenCL-basedFPGA-platformforstencilcomputationanditsoptimizationmethodology[J].
IEEETransonParallelandDistributedSystems,2017,28(5):1390-1402.
[8]周犇,张云泉,安小景,等.
基于OpenCL的RAR密码暴力破解算法优化[C]//全国高性能计算学术年会论文集.
2014.
(ZhouBen,ZhangYunquan,AnXiaojing,etal.
OptimizationofRARpasswordbrute-forcecrackingbasedonOpenCL[C]//ProcofHigh-PerformanceComputingChina.
2014.
)[9]AnXiaojing,ZhaoHaojun,DingLulu,etal.
OptimizedpasswordrecoveryforencryptedRARonGPUs[C]//ProcofIEEEInternationalConferenceonHighPerformanceComputingandCommunications,InternationalSymposiumonCyberspaceSafetyandSecurity,andInternationalConferenceonEmbeddedSoftwareandSystems.
WashingtonDC:IEEEComputerSociety,2015:591-598.
[10]HuGuang,MaJianhua,HuangBenxiong.
PasswordrecoveryforRARfilesusingCUDA[C]//Procofthe8thIEEEInternationalConferenceonDependable,AutonomicandSecureComputing.
2009:486-490.
[11]GeLiang,WangLianhai.
Researchofpasswordrecoverymethodforrarbasedonparallelrandomsearch[M]//ApplicationsandTechniquesinInformationSecurity.
Berlin:Springer,2014:211-218.
[12]DaiZibin,ZhouNing.
FPGAimplementationofSHA-1algorithm[C]//ProcofInternationalConferenceonAsic.
2003:1321-1324.
[13]李磊,韩文报.
FPGA上SHA-1算法的流水线结构实现[J].
计算机科学,2011,38(7):58-60.
(LiLei,HanWenbao.
ImplenmentationofpipelinestructureonFPGAforSHA-1[J].
ComputerScience,2011,38(7):58-60.
)[14]LiBin,ZhouQinglei,SiXueming.
Mimiccomputingforpasswordrecovery[J].
FutureGenerationComputerSystems,2018.
84:58–77.
[15]黄谆,白国强,陈弘毅.
快速实现SHA-1算法的硬件结构[J].
清华大学学报:自然科学版,2005,45(1):123-125.
(HuangZhun,BaiGuoQiang,ChenHong-Yi.
EfficienthardwarearchitectureforsecurehashalgorithmSHA-1[J].
JournalofTsinghuaUniversity:ScienceandTechnology,2005,45(1):123-125.
)[16]JiangLiehui,WangYuliang,ZhaoQiuxia,etal.
UltrahighthroughputarchitecturesforSHA-1hashalgorithmonFPGA[C]//ProcofInternationalConferenceonComputationalIntelligenceandSoftwareEngineering.
2009:1-4.
[17]KimJW,LeeHU,WonY.
DesignforhighthroughputSHA-1hashfunctiononFPGA[C]//ProcofInternationalConferenceonUbiquitous&FutureNetworks.
2012:403-404.
[18]KakarountasAP,TheodoridisG,LaopoulosT,etal.
High-SpeedFPGAimplementationoftheSHA-1hashfunction[C]//IntelligentDataAcquisitionandAdvancedComputingSystems:TechnologyandApplications.
2007:211-215.
[19]雷元武,窦勇,郭松.
基于FPGA的高精度科学计算加速器研究[J].
计算机学报,2012,35(1):112-122.
(LeiYuanwu,DouYong,GuoSong.
HighprecisionscientificcomputationaccumulatoronFPGA[J].
ChineseJournalofCamputers,2012,35(1):112-122.
)[20]MonmassonE,CirsteaMN.
FPGAdesignmethodologyforindustrialcontrolsystems:areview[J].
IEEETransonIndustrialElectronics,2007,54(4):1824-1842.
[21]谭健,周清雷,斯雪明,等.
全流水架构MD5算法在拟态计算机上的实现及改进[J].
小型微型计算机系统,2017,38(6):1216-1220.
(TanJian,ZhouQinglei,SiXueming,etal.
Implementationandimprovementoffull-pipelineMD5algorithmbasedonmimiccompiter[J].
JournalofChineseComputerSystems,2017,38(6):1216-1220.
)chinaXiv:201811.
00131v1ChinaXiv合作期刊
37No.
1录用定稿ApplicationResearchofComputersAcceptedPaper收稿日期:2018-06-28;修回日期:2018-08-24基金项目:国家重点研发计划资助项目(2016YFB0800100);国家自然科学基金面上项目(61572444)作者简介:陈晓杰(1993-),男,河南武陟人,硕士研究生,主要研究方向为信息安全(740248499@qq.
com);周清雷(1962-),男,河南郑州人,教授,博导,博士,主要研究方向为信息安全自动机理论及计算复杂性理论;李斌(1986-),男,河南郑州人,博士研究生,主要研究方向为信息安全高性能计算.
基于多核FPGA的压缩文件密码破译*陈晓杰1,周清雷1,李斌2(1.
郑州大学信息工程学院,郑州450001;2.
信息工程大学数字工程与先进计算国家重点实验室,郑州450001)摘要:目前,破解WinRAR传统方法是使用CPU和GPU,而潜在的密码空间非常大,需要更高性能计算平台才能在有限的时间内找到正确的密码.
因此,采用四核FPGA的硬件平台,实现高效能的WinRAR破解算法.
通过在全流水架构下增加预计算和保留进位加法器结合的方法优化SHA-1算法,提升算法吞吐率;利用状态机的控制优化数据拼接,提升算法并行性;同时,采用异步时钟和多个FIFO缓存读写数据优化算法整体架构,降低算法内部的耦合度.
实验结果表明,最终优化后的算法资源利用率为75%,频率达到200MHz,4bit长度的密码破译速度为每秒102796个,是CPU破解速度的100倍,是GPU的3.
5倍.
关键词:信息安全;密码破译;FPGA;高性能计算;WinRAR中图分类号:TP309.
7doi:10.
19734/j.
issn.
1001-3695.
2018.
06.
0478Passwordrecoveryforcompressedfilebasedonmulti-FPGAChenXiaojie1,ZhouQinglei1,LiBin2(1.
SchoolofInformationEngineering,ZhengzhouUniversity,Zhengzhou450001,China;2.
StateKeyLaboratoryofMathematicalEngineering&AdvancedComputing,InformationEngineeringUniversity,Zhengzhou450001,China)Abstract:Atpresent,thetraditionalmethodofcrackingWinRARistousetheCPUandGPU,butthepotentialpasswordspaceisverylargewhichrequiriesahigherperformancecomputingplatformtofindthecorrectpasswordwithinalimitedtime.
Therefore,thispaperusesthehardwareplatformofmulti-FPGAtoachieveahigh-performanceWinRARcrackalgorithm.
TheSHA-1algorithmwasoptimizedbyaddingpre-calculationandcarrysavingadderunderthefull-pipelinearchitecture,soastoimprovethethroughputofthealgorithm.
Andtheuseofstatemachinecontroltooptimizedatasplicing,toimprovealgorithmparallelism.
Atthesametime,itusedtheasynchronousclockandmultipleFIFObufferstoreadandwritetheoverallstructureofthedataoptimizationalgorithmtoreducethecouplingwithinthealgorithm.
Theexperimentalresultsshowthatthefinaloptimizedresourceutilizationrateis75%andthefrequencyreaches200MHz.
The4-bytepassworddecipheringspeedis102,796persecond,whichis100timesfasterthanCPUand3.
5timesfasterthanGPU.
Keywords:informationsecurity;passwordcracking;FPGA;high-performancecomputing;WinRAR0引言压缩软件WinRAR是一款RAR压缩文件管理器,具有压缩、纠错、加密等多种功能,并且支持多种压缩格式的解压.
其压缩速度快、压缩效率高等多种优势得到了个人、机构、组织等的广泛使用.
WinRAR密码加密使用对称加密算法AES和单向不可逆算法SHA-1,这两种算法在目前的计算能力下能保证很高的安全性.
但是,这也使需要对WinRAR进行快速密码破译的信息安全和计算机取证带来了一定的困难.
目前,破译WinRAR的密码采用字典+穷举的方法,但随着密码长度的增加,可能的空间呈指数倍增长.
近期研究发现用户密码服从Zipf分布,而不是长期假设的均匀分布[1].
这一发现对"用户密码"的研究有很重要的指导意义.
在密码破译中也能够暂时性的缩减密码空间.
文献[2,3,4]中详细研究讨论了"口令猜测算法"及"口令猜测模型",并利用社会工程学等方法获得针对性的信息,从而分析出某些高概率口令的特征,或者针对某一用户的高概率口令.
因此,利用这些高概率口令可以破译很多用户密码,缩减了密码空间,提高破译效率.
虽然密码空间能够缩小很大一部分,但是一个高效能的计算平台对进一步提高破译效率具有很重要的作用.
现有的破解方法主要有依托于CPU平台的密码软件破解,破解速度慢.
基于OpenCL和CUDA架构的GPU平台破解,chinaXiv:201811.
00131v1ChinaXiv合作期刊录用定稿陈晓杰,等:基于多核FPGA的压缩文件密码破译第37卷第1期由于其受到访存的限制,影响了计算性能的提升,而且功耗较高.
因此,需要更高效的计算平台来提高破解的效率.
现场可编程门阵列(fieldprogrammablegatearray,FPGA)经过近30年的发展,已成为实现数字系统的主流平台之一,在以太网交换机传输数据、图像压缩、模板计算的加速等方面都得到了较好的应用[5-7].
将FPGA用于WinRAR的密码解密中,利用流水线并行工作的方式,可实现WinRAR密码破解算法的高效性.
本文的主要工作是基于四核FPGA硬件平台,提出对SHA-1算法关键路径的优化,并通过状态机的控制优化数据拼接.
算法的整体架构采用异步时钟使核心模块运算频率最大化,并使用多个独立时钟双端口BlockRAM实现的FIFO配合全流水线进行数据缓存读写.
最后通过实验,对比不同平台WinRAR破解算法的性能,表明本文优化后的算法性能有明显的提升.
1算法分析WinRAR破解算法主要分为四步,具体流程如下:a)提取特征串.
从压缩文件中提取盐值salt和哈希值digest,用于输入计算.
b)数据拼接和SHA-1运算.
将可能的密码(宽子节)、8Byte的盐值、3Byte的num依次进行拼接.
其中,num表示拼接的次数.
整个解密过程一共需要拼接262145次,每拼接64字节需要进行一次SHA-1运算.
每拼接16384次需要进行一次额外的SHA-1运算,用于获取密钥key和iv值.
c)AES运算.
将digest与key做AES运算,得到aes_r,并将aes_r与iv异或,得到xor_r.
d)比较.
将xor_r和一个固定值进行比较,判断密码是否正确.
算法结构如图1所示.
图1解密算法结构图Fig.
1Decryptionalgorithmstructure在整个算法中计算量最大的就是数据拼接操作和SHA-1运算,并且随着密码长度的增大,需要进行SHA-1运算的次数呈线性增长,计算需要的时间也呈线性增长,如图2所示.
图中以计算一个4位长度密码的时间为基准单位来衡量其他长度密码的计算时间.
从算法分析中可以知道对数据拼接操作和SHA-1的优化对算法的整体性能提升有至关重要的作用.
文献[8]中在GPU平台下在CPU端预先生成一个拼接表,再将此表一部分放到共享内存中,为GPU端进行计算,最终在w8000GPU上破解4位长度密码的性能达到了每秒10100个,比商业破解软件AccentRAR在GPU上快了2倍多.
文献[9]中在GPU平台下通过增加三个数组的方式减少状态跳变和数据链接所需要的时间,再结合GPU本身的优势进行优化,比AccentRAR在CPU上的速度高43到57倍.
文献[10]是基于CUDA架构对整体算法进行优化,提高了性能.
文献[11]通过对口令空间采用一种基于并行随机搜索的新方法生成字典,提高破解的成功率.
在FPGA平台上,对于SHA-1算法的优化,文献[12,13,14]通过使用保留进位加法器(CarrySaveAdders,CSA)的方式减少关键路径的延时.
文献[15]通过增加P、Q、R三个中间变量进行预计算减少延时.
文献[16]基于循环展开方法的40级流水线提高算法的吞吐率.
文献[17,18]利用循环展开和预计算的方式减少关键路径的长度和循环的轮数,达到高速运行.
图2不同密码长度对应的SHA-1次数及相对时间Fig.
2ThenumberofSHA-1andrelativetime上述研究WinRAR破解性能的提升主要集中在GPU平台,由于GPU要和CPU共享内存,限制了性能的提升,且功耗较高.
对于FPGA平台,SHA-1算法的优化仍然有很大的提升空间.
因此,本文的研究基于低功耗的四核FPGA硬件平台,通过优化数据拼接操作和进一步优化SHA-1算法,提升算法效率.
2算法优化及实现2.
1SHA-1算法优化SHA-1算法自1995年修订发布以来,广泛应用于数字签名、传输层安全、安全电子交易、无线局域网等信息安全领域.
SHA-1加密流程为补位、初始向量值、80轮循环运算、自加运算.
其中80轮运算的作用是更新A、B、C、D、E五个值,并作为最后的输出,每个值32位,一共160位,而A值为,t代表轮数,f是逻辑函数,K是常数,W的值为,S是循环函数.
A值是运算的最长路径,也是整个运算的关键路径.
因此,优化SHA-1算法的关键路径决定了整体的运行效率.
2.
1.
1SHA-1算法优化方法算法的吞吐量与频率、流水线级数成正比[21],因此本文采用预计算与保留进位加法器策略减少关键路径的延时,提高算法的频率,并采用全流水线实现算法,从而能够提高算法的吞吐量.
SHA-1算法核心迭代需要80轮运算,且每轮运算需要上轮运算的结果,运算过程中每轮运算互不干扰.
同时,在进chinaXiv:201811.
00131v1ChinaXiv合作期刊录用定稿陈晓杰,等:基于多核FPGA的压缩文件密码破译第37卷第1期行密码尝试中,每个密码的计算又是相互独立的.
因此,可以采用并行全流水线方法实现,80轮运算需要80个时钟周期,再加上预计算与输出一共82级流水线.
预计算通过增加寄存器G,使关键路径变为两个加法运算和位运算,减少关键路径的延时.
FPGA适合于位运算,而加法运算延时比位运算高,保留进位加法器CSA策略能够减少加法运算,最小化关键路径长度,保证流水吞吐率[19].
CSA运算如下,其中a、b、c为n位二进制数:通过增加位运算来减少加法运算,在关键路径运用保留进位加法器使加法运算变为一个从而来减少延迟.
因此,在全流水线架构下增加预计算和保留进位加法器策略能够降低延时,提高算法效率.
2.
1.
2SHA-1算法优化实现在具体实现算法时,分为三个主要模块协同工作实现全流水线技术,并且在其中引入预计算和保留进位加法器策略.
第一个是W模块用于计算每轮W的值,需要定义如下寄存器数组:这样定义可以节省3840个寄存器资源,其中W_next[i]由W[i]计算得到,i从0到63.
数组赋值及传递如图3所示.
图3数组W实现全流水线的逻辑结构图Fig.
3ArrayWtoachievethefull-pipelinelogicstructure图3中将数组W全部展开,使数据传递的过程更加清晰,输入数据DATA经过80个时钟周期完成W的全部计算.
单个时钟周期内,数组之间并行处理,且相邻数组数据串行传递,从而实现全流水线的计算,提高了时间效率和资源利用率.
第二个是预计算模块.
定义32位宽的寄存器数组G[80],在每轮运算时都预先计算G的值,从而减少关键路径的长度.
80轮运算需要计算80个G的值,且不同数据的值依次传递,实现了数据内的串行,数据间的并行.
第三个模块是数据更新模块,用来更新A、B、C、D、E的值,其中更新A的值是关键,其更新如下:通过使用CSA更新A值,减少了关键路径的延时.
因为每轮运算逻辑函数f不同,这一部分又分为四个小模块,但是功能都相同,且同样需要实现流水线架构.
因此,最终需要实例化80份,以消耗资源换取时间效率最大化.
图4显示了三个模块协同工作实现SHA-1算法的全流水线结构.
图4三个模块实现的全流水架构图Fig.
4Threemodulestoachievethefull-pipelinestructure2.
2基于状态机的数据拼接优化在WinRAR密码解密中,数据拼接需要拼接262145次,且每拼接64字节还要进行SHA-1运算,同时还要保存拼接到的位置,以便于下一次拼接从这个位置开始.
由于拼接次数多、拼接时间长成为了算法效率提升的瓶颈.
SHA-1算法采用82级流水线,数据拼接的数据要输入到SHA-1运算,数据拼接需要在82个时钟周期内完成82组数据的64字节拼接操作.
因此,本文基于状态机的控制,通过增加位宽为8的寄存器数组pwd_array[39:0]、temp_array[63:0]、flag_array[63:0]、final_array[63:0]使数据拼接能够并行处理,实现流水线的数据传递,提升算法的效率.
图5最终的数据拼接方法Fig.
5Thefinaldatalinkmethod在实现中,数组pwd_array用于存储密码,并将密码补位变为2字节的宽字节,且支持密码达到20位.
数组temp_array用于存储盐值和num到相应位置.
数组flag_array用于标记口令所在的位置,初始化均设为0xff,根据状态机来更改数组的值,最后的拼接根据这个值的大小来判断是什么值,并且判断数据所在的位置.
相同密码的temp_array、flag_array值相同,只需赋值一次,可供流水线82个密码共同使用,从而提升时间效率.
数组final_array则存储最后SHA-1运算的输入值.
以密码"1234"为例,在图5中显示了这四个数组是如何赋值的以及如何拼接的,图中的值都是ASCII码16进制显示.
chinaXiv:201811.
00131v1ChinaXiv合作期刊录用定稿陈晓杰,等:基于多核FPGA的压缩文件密码破译第37卷第1期数组的赋值依赖于状态机的控制.
状态机控制着数据拼接的开始,初始化,拼接中的数据赋值,状态的保存及状态的返回.
具体状态控制如下:状态1对数据进行初始化,包括计算密码的长度len1,密码和盐值的长度len2,用于后续判断填充的位置.
状态2控制拼接的开始、结束和重返初始状态.
状态3判断再拼接一轮是否到64字节,如果不超过,则转到状态4.
如果超过,则先将不超过的部分根据len1和len2的大小给数组temp_array、flag_array赋值,并且保存拼接到的位置,同时根据计数器判断给数组final_array赋值用于流水线数据传递计算,再转到状态4.
状态4:根据3状态保存的位置继续下一轮的数组赋值,如果拼够一轮,则返回状态2,拼接次数loop加1,如此循环,状态转换图如图6所示.
图6状态转换图Fig.
6Statetransitiondiagram通过状态的跳变给数组temp_array、flag_array赋值使拼接结构更加清晰,且仅需赋值一次可使流水线计算共同使用,降低了拼接消耗的时间.
通过中间数组flag_array作为标记,间接链接到密码,使数据的拼接能够并行化,降低结构复杂度,实现流水线,提升算法效率.
2.
3整体算法优化为了从FPGA和强大的计算机辅助设计工具的优势中获益,设计师必须遵循一种高效的设计方法.
这种方法基于三个主要原则:控制算法的细化,模块化和最佳的适用性,以及所选择的硬件架构[20].
为了达到这种高效的方法,在整体算法的设计实现时,需要充分利用板卡的LUT与FF资源,使FPGA芯片能够满负荷工作.
因此,本文整体算法的设计主要分为上层控制和核心算子两部分.
前者通过控制可以实例化多个核心算子,并且对多个算子的结果进行回收,实现多个算子并行工作,从而提升算法的整体性能.
上层控制又细分为外部接口模块用于从CPU端获取数据,数据管理与分发模块用于将数据提供给多个核心算子.
核心算子分为密码穷举模块、核心运算模块和比较模块.
模块与模块之间使用IPCatalog生成双端口BlockRAM实现的FIFO缓存数据和读写数据.
通过FIFO在模块之间进行数据的传递,降低算法模块之间的耦合度,提升算法的并行性.
同时尽量减少CPU与FPGA的交互,避免速度的差异致使性能的降低.
密码穷举模块实现为掩码字典的方式,在实现时通过上位机传输掩码字典到FPGA的口令穷举模块产生相应的口令.
掩码字典是一种穷举规则,而在规则中可以包含高概率口令,从而通过人为控制优先测试高概率口令,缩减破译的时间.
细粒度模块结构如图7所示.
图7细粒度模块结构图Fig.
7Fine-grainedmodulestructure算法的吞吐量、运行速度与时钟频率是正相关,时钟频率越高,运行效率也越高.
但是频率过高,容易产生时序阻塞问题,致使FPGA布线失败,因此要对时钟频率进行优化.
分析整个算法,可以发现计算量最大、计算最复杂的是SHA-1运算和数据拼接部分,这两个核心运算部分可以设计成一个高频率时钟,加快核心运算速度.
而为这两部分提供数据的上层控制模块和口令穷举模块采用低频率时钟足以满足核心计算需求.
通过将时钟域分离,既能充分利用板卡性能,也能最大化降低时序问题,使算法性能进一步提升.
3实验结果及分析本文实验的硬件平台是在四核FPGA集成加速卡上实现,芯片型号为XILINX公司的XCKU060,其查找表LUT资源是331680,FlipFlops寄存器资源是663360.
软件平台为集设计、仿真、综合、布线、生成于一体的Vivado软件.
通过对算法的不同部分进行相应优化,使最终算法在吞吐量、运行速度、资源利用率等方面有较大的提升.
表1不同文献SHA-1实现性能对比Table1SHA-1performancecomparison对比文献流水线级数最大频率吞吐量文献[12]8243.
08MHz22.
056Gbps文献[13]81272MHz139.
264Gbps文献[14]81303.
3MHz155.
289Gbps文献[15]83123.
3MHz63.
129Gbps文献[16]40163.
7MHz76.
195Gbps文献[17]4150.
7MHz7.
35Gbps本文82470MHz240.
64Gbps本文在实现全流水线架构的基础上通过使用预计算和保留进位加法器对SHA-1算法进行优化,其优化后的性能如表1所示,在表1中同时给出了其他文献实现的性能.
通过对比,可以发现本文优化后的性能在频率上达到470MHz,吞吐量达到了240.
64Gbps,比最高吞吐量的文献[14]还高出了85Gbps,是文献[16]的32倍,性能有了显著提升.
为了更进一步的验证优化后的性能,设计了表2的5种方案在XCKU060上实现.
chinaXiv:201811.
00131v1ChinaXiv合作期刊录用定稿陈晓杰,等:基于多核FPGA的压缩文件密码破译第37卷第1期表2不同优化对比方案Table2Differentoptimizationcomparisonproject方案不同优化方法1不进行任何优化2增加预计算进行优化3增加预计算并且使用CSA,关键路径也使用CSA4不使用预计算,但是在关键路径使用两次CSA5不使用预计算,在关键路径使用CSA5表2中CSA5是对CSA的扩展,其运算如下:5种方案都是在全流水线和全展开的基础上再优化实现,实现结果如表3所示.
表3不同方案资源综合表Table3Differentprojectresourcesintegratedtable对比方案LUT消耗(占比)FF消耗(占比)最大频率111768(3.
55%)19488(2.
94%)340MHz211967(3.
61%)26483(4.
00%)420MHz311355(4.
42%)21290(3.
21%)425MHz414809(4.
46%)20100(3.
03%)415MHz515639(4.
72%)21173(3.
19%)367MHz最终方案9415(2.
84%)21514(3.
24%)470MHz从表中可以看出使用预计算和保留进位加法器结合进行优化与其他类型的优化相比在最高频率方面是最优的,和不进行任何优化相比算法频率提升130MHz.
所有采用预计算的方案与不使用预计算优化相比,其寄存器都有较高消耗.
图8不同密码长度的破解速率Fig.
8Differentpasswordcrackingrate通过对SHA-1算法、数据拼接、以及整体架构优化,并且尽可能的使用芯片资源,最终算法实例化10个核心算子模块,占用资源为75%,实验结果的整体算法优化性能如图8所示.
从图8中可以看出,在不同密码对应的破解速度在多核FPGA板卡上性能是单核的4倍,在密码长度为4的破译速率达到每秒102796个.
通过控制使核与核之间并行运行,且支持多任务.
当有大量的加密文档需要恢复时,在每个核运行不同的任务,通过高概率口令的优先穷举,能够很快恢复出其中大部分的口令.
与其他文献方法对比,如表4所示.
表4不同文献破解算法性能表现Table4Differentresearchalgorithmsperformance对比文献实验平台(型号)速率加速比AccentRARCPU(I7)10001.
00文献8GPU(W8000)1010010.
10文献9GPU(W8000)1777817.
78本文FPGA(XCKU060)102796102.
80以软件AccentRAR的性能作为基准,本文的性能达到了其100倍,比其他文献的方法性能高很多.
Hashcat是一个提供基于OpenCL的开源破解软件的网站,其破解性能好,破解算法多等受到大家的广泛使用,因此本文使用Hashcat在GPU(GTX1080)上作验证对比,比较结果如图9所示.
图9不同密码长度破译性能对比Fig.
9Differentpasswordlengthperformance从图中可以看出本文的性能达到了Hashcat的3.
5倍.
将本文的优化结果与其他文献、软件对比,实验结果表明了本文的方案有较大的性能提升.
4结束语当前RAR口令密码破译主要是在CPU和GPU平台,前者主要的问题是破译速度慢,远远不能满足口令空间的指数级增长,后者由于涉及到访存问题,限制了破译性能,并且功耗较高.
针对这些问题,本文提出了多核FPGA硬件平台破译的方法,在全流水线架构下采用预计算和保留进位加法器策略缩短关键路径来优化SHA-1算法,使SHA-1算法的吞吐量达到了240.
64Gbps.
结合FPGA的低功耗、并行性、时钟频率高等优势对破解算法的数据拼接和整体架构进行优化,使算法最终的频率达到200MHz,破解四位密码长度的性能达到每秒102796个,并通过与其他文献进行对比,表明在多核FPGA的硬件平台,优化算法后实现的性能有明显的提升,也表明了优化算法方法的可行性.
虽然本文提出的方法使破译性能有了很大的提升,但是对于庞大的口令空间,其计算性能仍然很难满足实际的需求,因此,生成高概率密码结合本文的性能才能更大的提高破译的成功率.
而高概率密码则需要结合诸如大数据,统计,人工智能等多方面的知识,而这些将会是破解成功的关键及以后的工作重点.
chinaXiv:201811.
00131v1ChinaXiv合作期刊录用定稿陈晓杰,等:基于多核FPGA的压缩文件密码破译第37卷第1期参考文献:[1]WangDing,JianGaopeng,HuangXinyi,etal.
Zipf'slawinpasswords[J].
IEEETransonInformationForensicsandSecurity,2017,12(11):2776-2791.
[2]MaJ,YangWeining,LuoMin,etal.
Astudyofprobabilisticpasswordmodels[C]//SecurityandPrivacy.
2014:689-704.
[3]DingWang,ZhangZijian,WangPing,etal.
Targetedonlinepasswordguessing:anunderestimatedthreat[C]//ProcofACMSIGSACConferenceonComputerandCommunicationsSecurity.
NewYork:ACMPress,2016:1242-1254.
[4]王平,汪定,黄欣沂.
口令安全研究进展[J].
计算机研究与发展,2016,53(10):2173-2188.
(WangPing,WangDing,HuangXinyi.
Advancesinpasswordsecurity[J].
JournalofComputerResearchandDevelopment,2016,53(10):2173-2188.
)[5]BitarA,CassidyJ,JergerNE,etal.
EfficientandprogrammableethernetswitchingwithaNoC-enhancedFPGA[C]//Procofthe10thACM//IEEESymposiumonArchitecturesforNetworkingandCommunicationsSystems.
NewYork:ACMPress,2014:89-100.
[6]BayerFM,CintraRJ,EdirisuriyaA,etal.
Adigitalhardwarefastalgorithmandfpga-basedprototypeforanovel16-pointapproximateDCTforimagecompressionapplications[J].
MeasurementScience&Technology,2012,23(11).
[7]WaidyasooriyaHM,TakeiY,TatsumiS,etal.
OpenCL-basedFPGA-platformforstencilcomputationanditsoptimizationmethodology[J].
IEEETransonParallelandDistributedSystems,2017,28(5):1390-1402.
[8]周犇,张云泉,安小景,等.
基于OpenCL的RAR密码暴力破解算法优化[C]//全国高性能计算学术年会论文集.
2014.
(ZhouBen,ZhangYunquan,AnXiaojing,etal.
OptimizationofRARpasswordbrute-forcecrackingbasedonOpenCL[C]//ProcofHigh-PerformanceComputingChina.
2014.
)[9]AnXiaojing,ZhaoHaojun,DingLulu,etal.
OptimizedpasswordrecoveryforencryptedRARonGPUs[C]//ProcofIEEEInternationalConferenceonHighPerformanceComputingandCommunications,InternationalSymposiumonCyberspaceSafetyandSecurity,andInternationalConferenceonEmbeddedSoftwareandSystems.
WashingtonDC:IEEEComputerSociety,2015:591-598.
[10]HuGuang,MaJianhua,HuangBenxiong.
PasswordrecoveryforRARfilesusingCUDA[C]//Procofthe8thIEEEInternationalConferenceonDependable,AutonomicandSecureComputing.
2009:486-490.
[11]GeLiang,WangLianhai.
Researchofpasswordrecoverymethodforrarbasedonparallelrandomsearch[M]//ApplicationsandTechniquesinInformationSecurity.
Berlin:Springer,2014:211-218.
[12]DaiZibin,ZhouNing.
FPGAimplementationofSHA-1algorithm[C]//ProcofInternationalConferenceonAsic.
2003:1321-1324.
[13]李磊,韩文报.
FPGA上SHA-1算法的流水线结构实现[J].
计算机科学,2011,38(7):58-60.
(LiLei,HanWenbao.
ImplenmentationofpipelinestructureonFPGAforSHA-1[J].
ComputerScience,2011,38(7):58-60.
)[14]LiBin,ZhouQinglei,SiXueming.
Mimiccomputingforpasswordrecovery[J].
FutureGenerationComputerSystems,2018.
84:58–77.
[15]黄谆,白国强,陈弘毅.
快速实现SHA-1算法的硬件结构[J].
清华大学学报:自然科学版,2005,45(1):123-125.
(HuangZhun,BaiGuoQiang,ChenHong-Yi.
EfficienthardwarearchitectureforsecurehashalgorithmSHA-1[J].
JournalofTsinghuaUniversity:ScienceandTechnology,2005,45(1):123-125.
)[16]JiangLiehui,WangYuliang,ZhaoQiuxia,etal.
UltrahighthroughputarchitecturesforSHA-1hashalgorithmonFPGA[C]//ProcofInternationalConferenceonComputationalIntelligenceandSoftwareEngineering.
2009:1-4.
[17]KimJW,LeeHU,WonY.
DesignforhighthroughputSHA-1hashfunctiononFPGA[C]//ProcofInternationalConferenceonUbiquitous&FutureNetworks.
2012:403-404.
[18]KakarountasAP,TheodoridisG,LaopoulosT,etal.
High-SpeedFPGAimplementationoftheSHA-1hashfunction[C]//IntelligentDataAcquisitionandAdvancedComputingSystems:TechnologyandApplications.
2007:211-215.
[19]雷元武,窦勇,郭松.
基于FPGA的高精度科学计算加速器研究[J].
计算机学报,2012,35(1):112-122.
(LeiYuanwu,DouYong,GuoSong.
HighprecisionscientificcomputationaccumulatoronFPGA[J].
ChineseJournalofCamputers,2012,35(1):112-122.
)[20]MonmassonE,CirsteaMN.
FPGAdesignmethodologyforindustrialcontrolsystems:areview[J].
IEEETransonIndustrialElectronics,2007,54(4):1824-1842.
[21]谭健,周清雷,斯雪明,等.
全流水架构MD5算法在拟态计算机上的实现及改进[J].
小型微型计算机系统,2017,38(6):1216-1220.
(TanJian,ZhouQinglei,SiXueming,etal.
Implementationandimprovementoffull-pipelineMD5algorithmbasedonmimiccompiter[J].
JournalofChineseComputerSystems,2017,38(6):1216-1220.
)chinaXiv:201811.
00131v1ChinaXiv合作期刊
- 算法空间有黄的qq相关文档
- "捐款日期","捐款单位(个人)名称","捐款金额(元)","类型",
- 博士空间有黄的qq
- 雪原投稿邮箱地址542300639@qq·com
- 项目空间有黄的qq
- 派出所空间有黄的qq
- 蛋鸡空间有黄的qq
HostYun(月18元),CN2直连香港大带宽VPS 50M带宽起
对于如今的云服务商的竞争着实很激烈,我们可以看到国内国外服务商的各种内卷,使得我们很多个人服务商压力还是比较大的。我们看到这几年的服务商变动还是比较大的,很多新服务商坚持不超过三个月,有的是多个品牌同步进行然后分别的跑路赚一波走人。对于我们用户来说,便宜的服务商固然可以试试,但是如果是不确定的,建议月付或者主力业务尽量的还是注意备份。HostYun 最近几个月还是比较活跃的,在前面也有多次介绍到商...
HostYun 新上美国CN2 GIA VPS 月15元
HostYun 商家以前是玩具主机商,这两年好像发展还挺迅速的,有点在要做点事情的味道。在前面也有多次介绍到HostYun商家新增的多款机房方案,价格相对还是比较便宜的。到目前为止,我们可以看到商家提供的VPS主机包括KVM和XEN架构,数据中心可选日本、韩国、香港和美国的多个地区机房,电信双程CN2 GIA线路,香港和日本机房,均为国内直连线路。近期,HostYun上线低价版美国CN2 GIA ...
Spinservers美国圣何塞服务器$111/月流量10TB
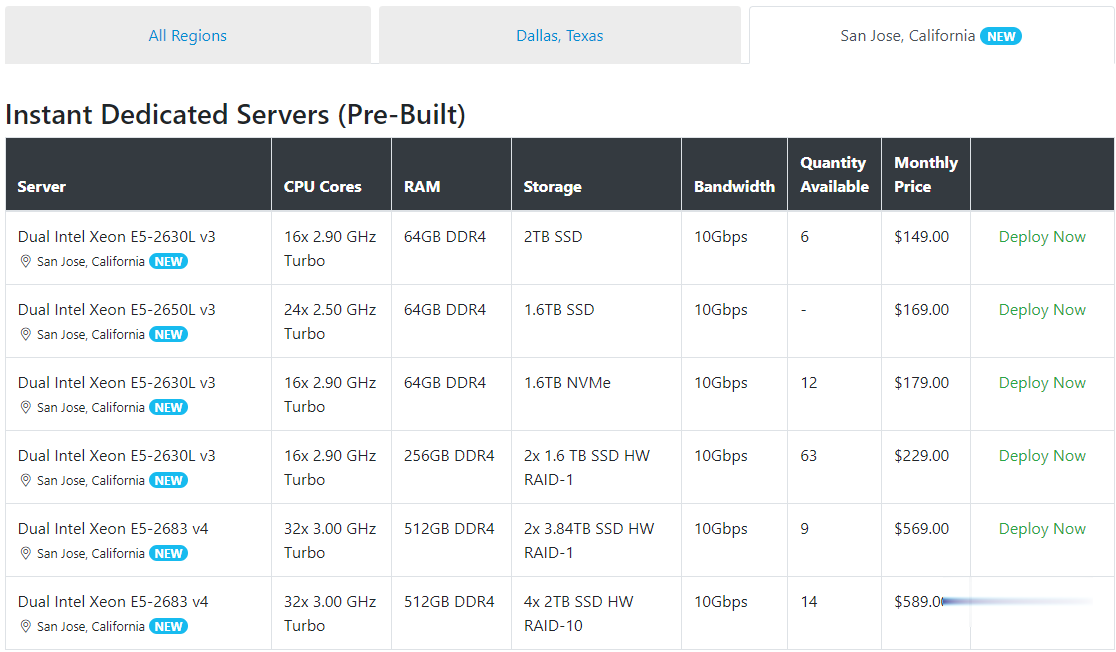
Spinservers是Majestic Hosting Solutions,LLC旗下站点,主营美国独立服务器租用和Hybrid Dedicated等,数据中心位于美国德克萨斯州达拉斯和加利福尼亚圣何塞机房。TheServerStore.com,自 1994 年以来,它是一家成熟的企业 IT 设备供应商,专门从事二手服务器和工作站业务,在德克萨斯州拥有 40,000 平方英尺的仓库,库存中始终有...
空间有黄的qq为你推荐
-
themesgoogle企业建网站什么企业需要建网站?filezillaserver怎么用FileZilla Server 0.9.27 绿色汉化版软件?企业电子邮局企业邮箱怎么使用?支付宝调整还款日月底30号用花呗到时候下个月什么时候还款?my.qq.commy.qq.com,QQ用户上不去?什么是支付宝支付宝是什么意思?flashfxp下载怎样用FlashFXP从服务器下载到电脑上?360防火墙在哪里怎么查找到360防火墙在自己电脑里的位置?并且关闭掉大飞资讯手机出现热点资讯怎么关闭