页面保存网页
保存网页 时间:2021-05-23 阅读:()
ISSN1000-9825,CODENRUXUEWE-mail:jos@iscas.
ac.
cnJournalofSoftware,Vol.
19,No.
2,February2008,pp.
275290http://www.
jos.
org.
cnDOI:10.
3724/SP.
J.
1001.
2008.
00275Tel/Fax:+86-10-625625632008byJournalofSoftware.
Allrightsreserved.
基于页面Block的Web档案采集和存储宋杰+,王大玲,鲍玉斌,申德荣(东北大学信息科学与工程学院,辽宁沈阳100004)CollectingandStoringWebArchiveBasedonPageBlockSONGJie+,WANGDa-Ling,BAOYu-Bin,SHENDe-Rong(SchoolofInformationScienceandEngineering,NortheasternUniversity,Shenyang110004,China)+Correspondingauthor:Phn:+86-24-83687776,E-mail:sy_songjie@163.
net,http://www.
neu.
edu.
cnSongJ,WangDL,BaoYB,ShenDR.
CollectingandstoringWebarchivebasedonpageblock.
JournalofSoftware,2008,19(2):275290.
http://www.
jos.
org.
cn/1000-9825/19/275.
htmAbstract:Inthispaper,thepageblockbasedWebarchivecollectingandstoringapproachisproposed.
Thealgorithmsoflayout-basedpagepartition,extractingtopicfromblock,versioncomparisonandincrementalstorageimplementationareintroducedindetail.
Theprototypesystemisimplementedandtestedtoverifytheproposedapproach.
Theoreticsandexperimentsshowthat,theproposedapproachadaptstheWebarchivemanagementwell,andprovidesavaluabledataresourcetotheWebarchivebasedquery,search,dataminingandknowledgediscoveringapplications.
Keywords:Webarchive;pagepartition,pageblock摘要:提出了基于页面Block对Web页面的采集和存储方式,并详细表述了该方法如何完成基于布局页面分区、Block主题的抽取、版本和差异的比较以及增量存储的方式.
实现了一个Web归档原型系统,并对所提出的算法进行了详细的测试.
理论和实验表明,所提出的基于页面Block的Web档案(Webarchive)采集和存储方法能够很好地适应Web档案的管理方式,并对基于Web档案的查询、搜索、知识发现和数据挖掘等应用提供有利的数据资源.
关键词:Web档案;页面分区;页块中图法分类号:TP393文献标识码:A由于Web搜索的成功,大量Web用户都习惯于通过搜索引擎来检索信息,但是,这种方式仅能检索到当前的网页.
像新闻、Blogs、论坛这样的Web信息在一年内就会消失[1].
由于Web信息的流逝性,如何利用信息技术来搜集、保存和查询逝去的Web信息成为Web领域中一个崭新的课题.
Web历史或Web档案(Webarchives)是一种基于Web的信息服务,它每隔一段时间就从Internet中抓取网页并以快照的形式保存起来,逐渐形成了一个Web历史网页的博物馆.
这些网页不只是被收集和存储起来,还要进行分类和处理,以方便历史浏览和检索.
现有的Web档案的采集主要有两种方式.
一种方式是网页发布商主动地汇缴给Web档案收集者.
这种方式并不普遍,因为网页发布商部署网页的目的并不是为了归档和收藏,这样做会带来额外的成本且不能产生直接SupportedbytheNationalNaturalScienceFoundationofChinaunderGrantNos.
60573090,60673139(国家自然科学基金)Received2007-08-31;Accepted2007-10-19276JournalofSoftware软件学报Vol.
19,No.
2,February2008效益.
此外,在国家之间汇缴Web页面还存在法律问题[2].
另一种方式就是Web档案收集者利用网络爬虫在Internet中采集.
这种采集方式较为常用但难度较大.
传统的收集方式是采集和保存网页的循环,即在一个固定的时间周期中采集所有的网页,并且按照URL地址分类保存起来.
这种方法存在很大的研究空间:首先应该研究页面的转化和处理方式,是直接以单个页面的形式存储还是对页面进行分割和转化后再存储,处理方式取决于Web档案的使用方式;其次,该方法需要一个良好的版本比较机制,如果不进行版本比较,势必导致存储了大量时间不同但内容相同的网页,且版本比较算法必须成功地迅速检测到网页的部分变化,或者是哪些部分变化,是内容的变化,还是背景、格式或是广告信息的变化;最后是网页的存储方式的研究,由于Web历史信息量非常大,以国内的WebInfoMall为例,其规模以平均每天150万个网页的速度扩大,5年已达到了25亿个网页(约1300GB)[3],因此,Web页面存储应该支持增量的存储方式,即只存储变化的部分.
针对上述问题,本文提出了一种基于页面Block的Web档案采集和存储方法.
我们分析了Web档案的使用方式,认为页面应该按照显示和主题分区,这样有利于Web档案搜索、问题回答(QA)或知识发现.
该方法在使用网络爬虫获取页面以后,根据页面的布局特征将页面分为若干个显示和主题相对独立的矩形区域(Block)以及剔除这些区域剩下的页面框架(Layout),按照这些Block进行版本比较和存储并且只存储发生变化的Block.
本研究还实现了一个Web归档系统的原型,并用实验数据说明该方法的正确性和可用性.
本文第1节介绍研究背景.
第2节阐述基于Block的页面采集和处理方式.
第3节介绍原型系统的实现方式和测试结果.
第4节对前人的相关工作进行简要分析.
第5节总结全文并提出下一步的工作.
1研究背景目前,Web归档系统大多选择整个Web页面作为最小的处理和存储单元,即依赖网页整体内容变化来检测新网页,并且以整个网页快照形式存储页面.
这种方式已逐渐不能适应Web的快速发展,因此,我们提出把页面按照一定的算法分为若干个区域,把这些区域作为基本的存储和处理单元.
提出该方法的理由如下:(1)当今的Web页面更新迅速,页面内容丰富多样,很多页面的内容不是由同一主题的大量平文本而是由多个不相关主题的页面区域构成,并且页面的更新也分解成部分区域的更新,因此,以页面区域为最小单位来采集和存储Web档案更符合实际情况,粒度上明显优于以页面为最小单位的采集和存储.
(2)此外,为了方便用户浏览,Web页面中加入了大量与内容无关的元素,比如导航菜单、输入区、装饰性的标题和图片或者站点相关信息,这些元素信息量较少且相对稳定.
如果采用基于整个页面的Web档案采集和存储,则对这些内容无关的元素的处理和存储势必浪费大量的时间和空间,而如果基于页面区域进行采集和存储,就可以适当忽略这些稳定的且内容无关的区域,节省处理和存储代价.
(3)Web档案的意义在于强大的档案资料库的搜索功能.
对于搜索引擎、QA系统或知识发现系统,以Web网页作为独立语义单元的最大问题在于忽略了页面上存在着多个主题,当查询语句分散在各个主题上时,搜索精度就会显著下降.
因此,按照页面区域来采集和存储Web档案,有利于为档案信息搜索和提取而创建主题相关的数据集,并且排除广告、导航等噪音数据,进而降低搜索难度、提高搜索质量.
网页布局是网页的一个重要的内部结构,从网页的布局我们可以分辨内容相关的信息和内容无关的噪音.
我们根据网页布局把网页划分成若干个区域,在Web档案采集和存储过程中,检测网页整体布局的变化或者部分区域的变化,并把变化的部分保存起来,以达到存储Web档案的目的.
为了方便阐述,本文从WebArchive[4]网站选取了java.
net网站的若干历史网页.
图1中,左图是2007年1月2日该网站的某网页快照,右图是该网页5天后(同年1月7日)的网页快照,为了节省篇幅,在不影响算法说明的前提下,我们对页面作了简化处理.
直观上可以看出,这两个网页结构非常相似.
简单分析页面可以看出,有很多区域与内容信息无关,对信息检索没有帮助,而且相对比较稳定.
本页面主要的内容为虚线矩形区域,该区域又分为若干个主题.
我们分析了大量Web历史页面后发现,每个页面总是存在一些频繁更新的区域,而剩下的区域则很少更新.
在本例中,频繁更新的只有虚线矩形区域.
可以看出,在采集周期(5天)内网页发生了变化,如果时间周期缩短为2天,则很有可能得到两个完全相同的页面.
因此,本研究需要解决以下几个问题:(1)如何对采集的网页自动进行版本比较以确定网页是否更新;宋杰等:基于页面Block的Web档案采集和存储277(2)根据直观的页面分区我们发现,只有中央虚线矩形部分发生了变化,那么,如何以一种合理的方式分割页面并找到变化的部分;(3)显然,为了减少存储开销,Web归档系统可以仅存储发生变化的部分,其存储方式也是本文研究的问题之一.
LogininputAreaBannerFooterSiteInformationQueryInputAreaNavigationNavigationContentContentNavigationNavigationWelcomeTitleTopic1Topic2Topic3Topic4Topic5Fig.
1TwoWebhistorysnapshotsasexample图1作为例子的两个历史网页快照2基于Block的页面采集本节将描述Web页面的分区、主题生成、版本比较和存储算法.
首先我们给出页面Block的相关定义.
定义1(Block).
Block是页面中在内容和显示上独立的、闭合的矩形区域.
Web页面可以分割为若干个互不相交的Block,我们把这个过程称为页面分区.
定义2(Block树).
我们递归定义一个Block可以由多个相互不重叠的Block组成,则图2所示的页面可以分解为图3所示的树形结构,称为Block树.
其中,节点Block是整个页面,是最大粒度的Block,而叶子节点则是最小粒度的Block.
CC1CC6CLCR1B1T2CR2T1B2CC2CC3CC4CC5CCCRFig.
2Blockstructureofanexamplepage图2示例页面的Block结构278JournalofSoftware软件学报Vol.
19,No.
2,February2008定义3(分区级别).
分区级别表示该分区算法产生的Block树的最大深度,用Level表示.
由图4可以看出,在任意深度下,所有叶子节点均能组成页面的一种分区策略.
因此,选择合适的分区级别有助于得到最理想的分区结果.
RootT1B2CCLCCCRCC5CC4CC3CR1CR2CC6CC1CC2T2B1Level0Level1Level2Level3Level1Level2Level3Fig.
3Block-Treeofanexamplepage图3示例页面的Block树Fig.
4Partitionresultofdifferentlevel图4不同分区级别的分区结果定义4(Block主题和内容).
设content为Block内容,即Block中存储的HTML文档,topic为Block主题,即从Block内容中查找或抽取出的能够表示Block内容概要的一段文字,则Block可以定义成一个由主题、内容组成的二元组:Block=topic,content.
定义5(Layout).
设Layout为网页的布局,即剔除了Block的网页框架,其中,Block部分使用占位符填充.
Layout是一个完整的网页,主要包括除了Block部分页面框架以外的像BODY这样的一些全局架构标签,或者是Block之间的分割部分.
定义6(Version).
设Version为某个URL地址在某一个时间点的Web历史记录.
Version可以定义成一个由Layout和若干个Block以及元数据信息组成的三元组:Version=Layout,{Block},MetaData.
2.
1页面分区算法页面分区算法的目标是把页面分割为一组不重叠的Block,这种分割算法基于DOM(documentobjectmodel).
一个Web页面经过解析后可以转换为DOM[5].
DOM提供了树形结构的页面模型,因此,我们可以基于DOM来建立Block树[6,7].
我们当然可以借助大量HTML标签来获取布局和位置信息,如P,TABLE,TR,HR,UL等.
然而,由于HTML语法的灵活性,很多Web页面并不完全遵守W3C的HTML规范.
此外,依据DOM的分区只能代表布局结构独立的区域而不能完全代表语义上独立的区域,比如,同一个父节点下面的两个子节点并不一定代表相同的主题.
因此,分区算法不能完全依赖DOM,还需要考虑其他一些因素.
通常,显示上独立的区域一般表示相同的主题,Web中提供了大量可见的元素来划分页面[8],例如字体、颜色、图像、空白,这些都是页面分区算法需要考虑的元素.
页面分区的整个过程如图5所示.
首先,DOM树和一些字体、颜色信息经抽取Block算法抽取出第n级Block(n初始化为1),组成深度为n的Block树,同时保存Layout.
然后,判断n是否满足给定的分区级别,如果小于该级别,则依次把Block树中的每个叶子节点Block的内容(content)作为新的DOM,重新抽取Block并组装n+1级Block树,如果某个Block已经无法再分割,则忽略这个Block.
如此反复,直到Block树达到给定分区级别为止.
给定分区级别可以根据经验预先设置,也可以根据历史记录动态调整.
图6给出了图1中例子页面的3次分区算法迭代过程中每次生成的Block树,图中深颜色的节点表示不可再分的Block,在迭代中应该忽略.
宋杰等:基于页面Block的Web档案采集和存储279Extractn-levelblockn=MaxOrisblockatomisticYesNotreatblockasanewnoden=n+1BlocktreeTheleafnodeisblock.
.
.
htmlheadbody.
.
.
DOMtreeVisualInfo.
.
.
.
.
.
.
.
.
.
.
.
.
n=0GeneratelayoutFig.
5Block-Basedpagepartitionalgorithm图5基于Block的页面分区算法RootT1B2CT2B1RootT1B2CCLCCCRT2B1RootT1B2CCLCCCRCR1CR2CC6CC1T2B1.
.
.
Fig.
6Block-Treesgeneratedbythreeoverlapsofpagepartitionalgorithm图6页面分区算法3次迭代产生的Block树抽取n级Block算法是一个递归的过程,其主算法为算法1.
在该算法中,depth不同于分区级别,分区级别是Block树中最终的深度,depth是当前节点在DOM数中的深度.
depth的最大值MaxDepth参照分区级别设置,但二者之间没有必然联系.
算法1.
抽取Block.
Input:pNodeisDOM,depthisdepthofpNodeinDOMtree;Output:抽取的Block.
ExtractBlock(pNode,depth)1Ifdepth>MaxDepth2Return;3End;3IfIsBlock(pNode)==True4SavepNodeasaBlockintoBlockpool;5Else6ForeachchildofpNode7ExtractBlock(child,depth+1);8End;9End;Block抽取算法的关键在于,遍历DOM树时,如何判断一个节点是否是一个Block,即IsBlock算法.
在描述IsBlock算法之前首先定义以下几个函数.
设node为DOM树中的某一个节点,则:280JournalofSoftware软件学报Vol.
19,No.
2,February2008inode.
properties表示取当前节点的属性,如bgcolor,font,width和height分别表示背景颜色、字体、宽度和高度.
node.
tag表示当前节点的HTML标签.
node.
type表示节点的类别.
我们把HTML标签分为布局标签、格式标签和功能标签3类,布局标签多数与网页的布局有关,如TABLE,TD,TR,HR,P等;格式标签多与文字、图片等页面元素的格式有关,如B,BIG,EM,FONT,I,STRONG,U,DIV等;功能标签多数是显示特定的非文本元素,如FORM,A,INPUT,IMG,BUTTON等.
Schema,.
.
Format,.
Function,.
nodetagnodetypenodetagnodetag∈=∈∈布局标签格式标签功能标签.
node.
subNode表示当前节点的子节点集合,该集合的长度用node.
subNode.
length表示.
下面的Rule1~Rule11是判断一个节点是否是Block所依次遵循的法则.
Rule1.
如果当前节点没有子节点或子节点大小均为0,则该节点不是Block.
否则Rule2.
如果当前节点是Function节点,则该节点不是Block.
否则Rule3.
如果当前节点是Format节点,则该节点不是Block.
否则Rule4.
如果当前节点只有1个子节点,则该节点不是Block.
否则Rule5.
如果当前节点的尺寸小于标签的给定最小值,则该节点不是Block.
否则Rule6.
如果当前节点的颜色与子节点颜色不同,则该节点不是Block.
否则Rule7.
如果当前节点是Schema节点,且子节点中没有Format或Function节点,则该节点不是Block.
否则Rule8.
如果当前节点是Schema节点,且子节点只包含Format或Function节点,则该节点是Block.
否则Rule9.
如果当前节点是Schema节点,且子节点中的Schema节点递归满足Rule8或Rule9,则该节点是Block.
否则Rule10.
如果当前节点的前一个兄弟节点是Block,则该节点是Block.
否则Rule11.
该节点不是Block.
根据Rule1~Rule11,我们重新考虑图2所示的例子.
如图6和图7所示,如果设分区级别为3,那么,首先抽取深度为1的Block树,T1,T2,C,B1,B2很容易被抽取出来.
第2轮抽取深度为2的Block树,由于T1,T2,B1,B2都已经是最小粒度,无法再分割,所以考虑继续分割C,C的第1个子节点TD有24个DIV子标签,DIV子标签多是链接标签,TD符合Rule8,抽取名为CL的Block.
根据Rule10很容易得到CC和CR这两个Block.
最后抽取级别为3的Block.
根据Rule2和Rule3,可以判断CL无法进一步分割.
CC可以分割为CC1~CC6,CR可以分割为CR1~CR6.
2.
2主题生成算法为了便于对Block进行检索、分类和管理,我们提供了一种简单的方法为每一个Block生成一句主题文字.
主题生成算法要求具有唯一性,即相同的内容抽取的主题相同,但主题相同对应的内容则不一定相同.
通常可以采用两种算法生成主题:一种是通过字体、颜色和位置等信息查找主题;另一种是利用数据挖掘的方法抽取主题.
在介绍这两种方法之前,首先对一些操作进行定义.
由Block定义可知,Block中包含的content也是一段HTML文档,包含着文字和格式信息,我们不难把content中每个含有文字的Format标签抽取出来.
如果用T表示这些Format标签的集合,设有n个Format标签,每个标签ti(1≤i≤n)又可以分为格式信息formati和文字信息texti,设Format是所有format的集合,Text是所有text的集合,那么,集合T可以表示为Format集合和Text集合组成的二元组.
{|11.
iiiiTtinFormatTexttformatttextformattextin宋杰等:基于页面Block的Web档案采集和存储281tabledivtablehtmlheadbodytrtdtdtddivdivdivppppppptabletabletable.
.
.
pCC1CC6CLCR1B1T2CR2T1B2CC2CC3CC4CC5CCCRT1T2CB1B2CLCCCRCR1CR2CC1CC2CC3CC4CC5CC6Fig.
7DOMstructureandcorrespondingBlockstructureofexamplepage图7示例页面的DOM结构和对应的Block结构定义7(长度函数).
以参数texti为例,length(texti)返回texti中单词的个数,或者以参数Text为例:1()(niilengthTextlengthtext==∑)).
1)查找Topic在大多数Web页的Block中已经存在一个主题,它以较大的字体、显著的位置或者不同的颜色来显示.
这种情况下,主题生成算法的重点就是如何找到一个已存在的主题.
主题topic的查找步骤如下:步骤1:遍历集合Text并找到一段文字texti,其对应的formati是集合Format中字体最大或者位置独立且靠前的,或者颜色与其他不同的;步骤2:如果θ是主题中的单词数目最大限定值,那么,,(.
(),()iiiitextlengthtexttopictrimtextlengthtextθθ≤=>这里,trim(texti)是一个能够将一个段落缩减到只含θ个单词的函数.
算法2给出了trim(texti)函数:算法2.
裁减内容.
Input:textiasaparagraph,astoplistfileS,wordnumberthresholdθ.
Output:AsetTWconsistingofallwordsoftopicphrase.
trim(texti)1Deletestopwordsfromtextiaccordingtostoplist;2TW={};3Forj=1toθStep14wordj=wordoftextiwhichindexisj;5IfwordjTW6PutwordjintoTW;7End;8End;9ReturnTW;282JournalofSoftware软件学报Vol.
19,No.
2,February2008在算法2中,第1行采用stoplist[9]进行了预处理.
2)抽取主题在一些Block中,有些主题没有用特殊的格式突显出来,甚至根本没有主题.
在这种情况下,主题生成算法的重点是如何从现有的文字中抽取出一个主题.
许多Web挖掘研究提供了抽取Web页面主题的算法,这些算法可能适用于含有大量文字的Block.
但是,对于文字量很少的Block来说,数据挖掘算法很难有意义.
抽取主题的算法如下:设δ为一个区间,表示适合Web挖掘算法的最小单词数,texti∈Text(1≤i≤n),则(),().
(),()iiiitrimtextlengthtexttopicextracttextlengthtextδδε7)PutwordjintoTW;8)End;9)End;10)ReturnTW;在算法3中,1~2行是用stoplist[9]和stemming[10]对text进行预处理.
这里,Text是整个Block中包含的文字,texti是每个Block中每个标签包含的文字(texti∈Text),wordj是texti文字中的一个单词,tf(texti,wordj)是wordj在文档texti出现的绝对频率[11].
2.
3页面比较算法页面比较算法用来比较新采集的页面和上一个版本的差异.
当采集到一个新版本的页面快照(version)时,需要对其进行分区处理,获得其所有Block和Layout,然后与最近一次历史Version进行版本比较,找出差异的部分存储,如果新、旧页面完全一致,则表示页面没有更新,本次采集无效.
设α和β为Web历史采集的两个连续的时间点(α保存网页的整体框架.
Layout代表了一种网页的布局,存储的是除了Block部分以外的页面框架.
由于网页的Layout很少发生变化,大量Version都对应一个Layout.
Label:Label是Block的分类信息,表明了Block中内容的类别,为以后的历史搜索、知识发现和数据挖掘提供信息.
以第2.
3节中α和β的两个连续的时间点(α<β)为例,算法4描述了vβ的存储处理算法.
算法4.
存储采集的页面.
Store()1Boolflag=false;2IfByteEqual(lα,lβ)==True3Foreachbα,bβinbsαandbsβ,4Ifbα!
=bβ5Savebβandbβ'sLabel6flag=true;7End8End9End10Else11Savelβ;12flag=true;284JournalofSoftware软件学报Vol.
19,No.
2,February200813Foreachbβinbsβ,14Savebβandbβ'sLabel15End16End17Ifflag==true18Savevβandvβ'sVersionMataData19constructallrelationships20End算法首先判断Layout是否相等:如果相等,则存储差异的Block;如果不等,则存储全部的Layout;然后,存储分类信息和元数据;最后,建立各个部分之间的关系.
对于图2给出的例子,我们第2次采集只需要存储CC2~CC6这5个Block.
2.
5总体流程本文第2节介绍了基于页面Block的Web档案采集和存储的核心算法,当网络爬虫采集到页面以后,首先根据当前的URL地址查找最近的一个Version:如果不存在该URL地址,说明这是一个新的页面,则按照系统默认的分区级别抽取Block和Layout,给每个Block抽取主题,存储图8中表述的每个结构;如果找到当前URL最近的Version记录,则根据该Version的分区级别抽取当前页面的Block和Layout,然后根据算法4描述的过程存储采集的网页.
Web归档系统还可以利用大量的历史信息来指导自身,比如利用某个网页的历史分区方式和经常变化的Block来指导网页分区.
如图2给出的例子,如果网页频繁变化的是CC2~CC6这5个Block,我们可以设置分区级别为2级,这样,CC2和CC6就合为一个Block,简化了版本比较(但是,这种合并只是从采集存储角度来进行,并非一定有利于Web档案的应用).
此外,网站的更新频率一般是有规律的,根据文献[16]提出的思想,我们可以通过同一URL的各个Version之间的间隔来推断最佳的采集频率,减少采集不到网页变化的可能性.
3原型系统和实验分析为了证明本文提出的基于页面Block的Web档案管理方法的正确性和有效性,我们设计了一个原型系统Block-basedWebArchivePrototype(BWAP),并且对其进行了详细的测试.
首先,我们采用软件测试的方法对系统进行测试;依据现有的知识,我们没有发现同类工作的运行性能数据,因此没有进行性能比较,而只是在测试中对系统性能作了定性的衡量.
相对于性能因素而言,本研究更关心的是系统的精确度,因此,我们组织了一个实验对系统的精确度加以验证.
3.
1原型系统结构图9说明了BWAP的主要构件以及它们之间的关系,图中箭头的方向是主要数据的流动方向,采用的例子是本文第2节反复提及的示例.
上标α表示当前采集的页面版本,β表示该URL的Web档案信息中最近的一个版本.
由图中可以看出,采集的页面最终保存CC2~CC6这5个Block和相关元数据到Web档案库中.
图中相关组件的功能如下:PageCache:页面缓存用来缓存Crawler获取的页面,使采集和页面处理可以异步进行,降低耦合度.
ThreadController:线程控制器,可以多线程地同时对多个页面执行处理和存储.
PageProcessor:页面处理器,用来分割页面,获取Blocks和Layout.
TopicGenerator:主题生成器,为每个Block查找或抽取主题.
MetaDataGenerator:元数据生成器,根据用户设置的元数据生成各种元数据.
StoreAgent:存储代理,完成Layout,Blocks和元数据的存储工作.
VersionManager:版本管理器,完成基于Block的页面版本比较(见第2.
3节).
宋杰等:基于页面Block的Web档案采集和存储285LevelManager:分区级别管理器,能够选择、查找历史或适当地调整每个网页的分区级别.
Query&StorageProxy:Web存档库的查询和存储代理.
PagecacheUserInternetCrawlerTopicgeneratorPageprocessorQueryproxyVersionmanagerStorageproxyLevelmanagerThreadcontrollerMetaDatageneratorMetaDataruleRepositoryStoreAgentAllmeta-dataMeta-DataruleBWAPFig.
9OverviewofBWAP图9BWAP总体结构当Crawler获取了页面并存入PageCache以后,ThreadController启动一个线程来处理pageα.
首先处理pageα的是PageProcessor,这时,LevelManager根据pageα的URL,通过QueryProxy在Repository中查找合适的分区级别;然后,PageProcessor根据分区级别把pageα分割成layoutα和blocksα;blocksα通过TopicGenerator生成主题后,与layoutα一同转到VersionManage模块进行版本比较;VersionManage通过QueryProxy在Repository中找到layoutβ和blocksβ后,按照第2.
3节中的比较算法进行版本比较;最后,MetaDataGenerator根据管理员输入的元数据生成规则和pageα相关信息生成相关元数据,并与版本比较结果(有差异的Blocks)一同由StoreAgent通过StorageProxy存入Repository.
整个系统的时序图如图10所示.
Fig.
10SequencediagramofBWAP图10BWAP时序图PageαblockαPageαPageαlayoutβblockβlevelβCC2~CC6layoutαblockαPageprocessorThreadcontrollerTopicgeneratorLevelmanagerStoreAgentVersionmanagerQuery&storageproxyMetaDatageneratorQueryReturnFindPartitionReturnGeneratetopicReturntopicCompareversionReturndifferentQuerythelatestversionReturnGeneratemetadataReturnallmetadataStoreStorelayoutβblockβblockαlevelβlevelβlevelβlayoutαblockα286JournalofSoftware软件学报Vol.
19,No.
2,February20083.
2系统测试为了说明BWAP的功能完整性,我们为BWAP设计了详尽的测试.
BWAP通过了很多严格的测试用例,本节列出了部分测试用例和测试结果,它们涵盖以下几个方面:功能测试:保证BWAP可以在各种输入数据集下完成既定的功能逻辑;白盒测试:对BWAP中每一个构件以及构件内部的特定代码块进行测试;性能测试:在各种条件下,对系统处理和响应时间进行测试;集成测试:主要是测试BWAP内部构件的集成性以及与其他构件或框架的兼容性.
表1列出了部分测试用例和测试结果.
Table1Testcasesandtestresults表1测试用例和测试结果CategoryTestcaseResultTestthesystemcandealwiththepageswhoselayoutschangefrequently.
SuccessTestthesystemcandealwiththepageswhichhavetinychange.
SuccessTestthesystemcandealwiththepageswhosestructuresareabnormallycomplex.
SuccessTestthesystemcandealwiththepageswhosestructuresareabnormallysimple.
SuccessTestthesystemcandealwiththepageswhichincludemanyscripts.
SuccessTestthesystemcandealwiththepageswhichincludetextmostly.
FailureTestthesystemcandealwiththepageswhichincludealotofblanks.
SuccessTestthesystemcandealwiththefragmentarypages.
SuccessTestthesystemcandealwiththepageswhichcontainlotsofimages.
SuccessTestthesystemcandealwiththepagesbygreatpartitionlevel.
SuccessTestthesystemcandealwiththepagesbysmallpartitionlevel.
SuccessFunctionaltestingTestthesystemcandealwiththepagesbyunstablepartitionlevel.
SuccessWalkthroughthecodeandreviewitforsuchqualitiesaslogic,adherencetodevelopmentstandardsandbestpractices,andreadablecomments.
DoneRunthecodeagainstacode-coveragetooltomakesurethatalltheavailablecodeisbeingtested.
DoneWhiteboxtestingPerformmemoryprofilingofthecodetomakesurethatobjectsarecorrectlyreleasedandgarbageiscollected.
DoneTesttoseeifsystemprocessingpagestakesmuchprolongedmuchmoretimethancrawlercollectionpages.
NoTesttoseeifstoringtakesmuchprolongedtimethanprocessing.
NoTesttheperformanceofeachcomponenttofindbottleneck.
NoneTestperformancebydealingwithseveralthousandspagesonetime.
GoodTestperformancewhenprocessandstorepageswhichhavemanyimages.
BetterTestperformancewhenprocessandstorelargepages.
GoodPerformancetestingTestperformancewhenprocessandstorepageswithlimitedmemory.
NormalTesttheserverrunningatWindows,Linux,andUnixsystem.
SuccessTesttheframeworkcanintegratingwithkeycomponentsofJ2EEsuchasJTAandJAAS.
PartlysuccessIntegrationtestingTesttheframeworkcanrunningwithvariousdatabasesuchasOracle,SQLServerandDB2.
Success表1所列结果表明:BWAP在各种条件和数据环境下均能准确地完成分割页面、定位变化的页面区域、生成主题关键字、比较版本以及增量存储等功能;BWAP通过了代码走查、评审、内存泄漏检测和代码覆盖软件的逻辑覆盖测试;BWAP在高并发或大数据量的测试下运行性能良好;BWAP能够在各种平台下运行,并且不依赖特定的数据库种类.
3.
3实验分析基于页面Block的Web档案的采集和存储算法中最关键的一步就是定位页面发生变化的区域.
以图1为例,如果采用观察的方法,则能很准确地确定变化的最小区域(虚线矩形).
如果采用算法处理,若分区级别设为1,则得到C区是变化的区域;若分区级别设为2,则得到CC区是变化的区域;若分区级别设为3,则得到CC2~CC6这5个区域是变化的区域(如图2和图3所示).
因此,算法的判断与人的判断存在一定的差异.
检验算法是否、合理准确的最好办法是手工验证.
因此,我们首先选择了200对来自于文献[4]的历史网页,每对网页的采集时间非常接近,并且这些网页分属于不同的主题,以确保网页结构广泛、多样.
首先,我们通过BWAP把每对网页中时间较早的一个置入Web档案库中,然后再装入时间较晚的一个.
我们收集BWAP报告的后一个页面的分区结果和变宋杰等:基于页面Block的Web档案采集和存储287化的Block,同时,我们选择4位志愿者分别来检查这些结果,并且以Perfect,Good,Normal,Bad这4个级别给以评价.
图11和图12给出了评价结果.
0%10%20%30%40%50%60%PerfectGoodNormalBadRankPercentUser1User2User3User4Perfect41%Good45%Normal13%Bad1%Fig.
11Testresultsofeachuser图11每个用户的测试结果Fig.
12Averageproportionofeachrank图12每个级别的平均比例从图11的平滑曲线可以看出,4位志愿者的评价结果非常相似,这是由于每人评价的数据集是相同的,都是算法处理这200个页面的结果;由于从优到劣只分出4个级别,曲线特征并不明显,但仍可以看出,除了User3以外,其他曲线近似于一种正态分布,峰值位于Good级别,这些都表明算法的准确性和合理性.
从图12可以看出,这800次评价中结果是Perfect和Good的占86%,仅有1%为Bad.
我们考察了评价为Normal以下的约14%的页面发现,导致算法不精确的原因是多方面的:一些是浏览器和开源HTML解析工具的客观原因,主观原因及算法不足之处主要是无法区分那些用图片、Flash和文字来分割的区域,因此,该算法还有很大的提升空间.
尽管如此,不足1%的Bad评价率已经证明该算法的正确性.
此外,在这800次评价中并没有发现算法不能识别的页面变化.
少量的页面分区不合理可能会对存储带来负面影响,但不会影响对Web页面的变化的采集和保存.
4相关工作WebArchive属于一种新兴的技术.
根据澳大利亚国家图书馆在2003年的统计,仅有16个国家拥有完整的国内Web归档系统[17].
对Web档案的处理也处于发展阶段.
我们在研究Web档案处理成果的同时,也参考了大量Web领域相关的工作.
首先是Web归档系统的实现技术.
前人在Web归档系统的实现技术上作了大量研究.
TheInternetArchive是Web归档系统的先锋,它通过一个叫做Heritrix的开源爬虫实现对页面的抓取[18].
文献[19,20]描述了实现一个Web归档系统的系统结构和相关标准,并且实现了一个名为Tomba的原型系统.
本文学习了它的很多思想以及实现方式,尤其在Web页面的存储结构设计上借鉴了很多.
文献[21]实现了NWA工具集来访问NordicWebArchive并进行查询搜索.
此外,本研究也广泛参考了各国[2226]的Web归档系统的实现技术.
这些文献大多是在介绍Web档案的管理技术,或者在总体结构、存储和使用手段上进行研究.
与此不同的是,本研究主要提出基于页面Block来管理Web档案,是对传统Web档案管理方法的一种改进.
其次是Web页面的分区技术.
在传统的文本处理中,通常使用固定长度的段落或者窗口(window)来分割页面[27,28].
一个固定长度的段落包含一定数目的连续单词.
对Web文档来说,如果移除HTML标签和属性,则可以使用这种办法来分割页面.
固定长度的分割虽然精简并具有高性能,但也损失了大量HTML信息,不宜用作Web档案页面的分割算法.
此外,有许多学者考虑到运用HTML标签来分割页面,这些标签包括P,TABLE,UL等.
文献[29]在一个Web查询处理系统中利用这些标签对页面进行了分割.
文献[30]只把TABLE标签和TABLE标签内的所有子标签分为1个内容块,这显然忽略了大量信息,只使用TABLE标签是远远不够的.
文献[31,32]288JournalofSoftware软件学报Vol.
19,No.
2,February2008用一些像P,TABLE和UL这样的简单标签将网页分割成若干区域,并进一步进行转化和抽取摘要,然而,它们只是考虑标签类别而忽视了格式、样式等信息.
此外,文献[33]对页面分解算法作出了大量评论,但没有涉及到技术细节.
文献[34]对Web页面分区作了透彻的分析,并提出依赖可视化元素来分割页面的VIPS算法.
该研究工作对我们有很大的启发,然而VIPS算法过于复杂,不宜用于Web归档系统.
相比之下,本文提出的算法比较简单.
另外,这些工作均未把网页分区技术运用到Web历史档案信息处理领域.
尽管这些方法还都存在不足,但对本文的页面分区算法仍有很大的帮助.
本文也参考了一些Web存储技术[35,36]和Web挖掘以及主题抽取技术[37,38].
这些技术并非是针对Web档案的采集和处理,或者属于一些底层的存储技术.
我们借鉴了其思想,并灵活运用到Web档案的处理上.
5结论与展望本文描述了基于页面Block的Web档案的采集和存储方法,文中详细阐述了对页面进行分区、主题抽取、版本比较和增量存储这一过程中每个步骤的算法.
本文提出的基于页面Block的管理思路将便于Web档案的管理,并对基于Web档案的查询、搜索、知识发现和数据挖掘应用提供丰富的数据资源.
本研究的主要贡献有以下几点:提出基于页面Block的Web档案的管理方式;描述了页面分割算法、主题生成算法、页面比较算法和增量存储算法;实现了一个Web归档原型系统BWAP并用实验数据来验证算法的正确性.
本研究还处于初步阶段.
进一步的工作主要包括两个方向:一是进一步完善分区算法,包括能够适应页面在不改变总体布局的情况下增减Block的数目,Block的Label信息的生成以及通过历史分区信息自动学习、调整、优化的分区算法;二是如何利用Block资源完成基于Block的历史搜索、问答系统和历史知识发现.
References:[1]NtoulasA,ChoJ,OlstonC.
What'snewontheWebTheevolutionoftheWebfromasearchengineperspective.
In:ChenYR,KovácsL,LawrenceS,eds.
Proc.
ofthe13thInt'lConf.
onWorldWideWeb.
NewYork:ACMPress,2004.
112.
[2]NationalLiberarayofAustralia.
Padi-Webarchiving.
2006.
http://www.
nla.
gov.
au/padi/topics/92.
html[3]WebInfoMall.
2006(inChinese).
http://www.
infomall.
cn/[4]InternetarchiveWayBackmachine.
http://www.
archive.
org/Web/Web.
php[5]GuptaS,KaiserG,StolfoS.
ExtractingcontexttoimproveaccuracyforHTMLcontentextraction.
In:EllisA,TatsuyaH,eds.
Proc.
ofthe14thInt'lConf.
onWorldWideWeb—SpecialInterestTracksandPosters.
NewYork:ACMPress,2005.
11141115.
[6]LinSH,HoJM.
DiscoveringinformativecontentblocksfromWebdocuments.
In:HandD,KeimD,eds.
Proc.
ofthe8thACMSIGKDDInt'lConf.
onKnowledgeDiscoveryandDataMining.
NewYork:ACMPress,2002.
588593.
[7]WongWC,FuAW.
FindingstructureandcharacteristicsofWebdocumentsforclassification.
In:GunopulosD,RastogiR,eds.
Proc.
oftheACMSIGMODWorkshoponResearchIssuesinDataMiningandKnowledgeDiscovery.
NewYork:ACMPress,2000.
96105.
[8]YangYD,ZhangHJ.
HTMLpageanalysisbasedonvisualcues.
In:AntonacopoulosA,GatosB,eds.
Proc.
ofthe6thInt'lConf.
onDocumentAnalysisandRecognition.
Washington:IEEEComputerSociety,2001.
859864.
[9]http://www.
dcs.
gla.
ac.
uk/idom/ir_resources/linguistic_utils/stop_words[10]http://www.
dcs.
gla.
ac.
uk/idom/ir_resources/linguistic_utils/porter.
c[11]KantrowitzM,MohitB,MittalV.
StemminganditseffectsonTFIDFranking.
In:NicholasJ,PeterI,Mun-KewL,eds.
Proc.
ofthe23rdAnnualInt'lACMSIGIRConf.
onResearchandDevelopmentinInformationRetrieval.
NewYork:ACMPress,2000.
357359.
[12]MacDonaldJ.
Versionedfilearchiving,compression,anddistribution.
UCBerkeley,1999.
http://www.
cs.
berkeley.
edu/~jmacd/[13]BerlinerB.
CVSII:Parallelizingsoftwaredevelopment.
In:Proc.
oftheUSENIXWinter1990TechnicalConf.
Berkeley:USENIXAssociation,1990.
341352.
宋杰等:基于页面Block的Web档案采集和存储289[14]GomesD,CamposJP,SilvaMJ.
Versus:AWebrepository.
2003.
http://xldb.
fc.
ul.
pt/referencias[15]GomesD,LSantosA,SilvaMJ.
ManagingduplicatesinaWebarchive.
In:LiebrockLM,ed.
Proc.
ofthe21stAnnualACMSymp.
onAppliedComputing.
NewYork:ACMPress,2006.
818825.
[16]ChoJ,Garcia-MolinaH.
Estimatingfrequencyofchange.
ACMTrans.
onInternetTechnology(TOIT),2003,3(3):256290.
[17]PhillipsM.
PANDORA,Australia'sWebarchive,andthedigitalarchivingsystemthatsupportsit.
DigiCULT.
info,2003,(6):2430.
http://www.
nla.
gov.
au/nla/staffpaper/2003/mphillips1.
html[18]HalseJE,MohrG,SigurdssonK,StackM,JackP.
Heritrixdeveloperdocumentation.
2005.
http://crawler.
archive.
org/articles/developer_manual/index.
html[19]GomesD,FreitasS,SilvaMJ.
DesignandselectioncriteriaforanationalWebarchive.
In:ThanosC,GonzaloJ,eds.
Proc.
ofthe10thEuropeanConf.
ofResearchandAdvancedTechnologyforDigitalLibraries(ECDL).
Berlin,Heidelberg:Springer-Verlag,2006.
196207.
[20]SilvaMJ.
SearchingandarchivingtheWebwithtumba!
.
In:Proc.
ofthe4thConf.
onAssociationPortugalofSystemandInformation(CAPSI).
2003.
http://xldb.
fc.
ul.
pt/data/Publications_attach/tumba-search+archive-capsi-final.
pdf[21]HallgrimssonD,BangS.
NordicWebarchive.
In:MichaelD,ed.
Proc.
ofthe3rdECDLWorkshoponWebArchives.
2003.
http://bibnum.
bnf.
fr/ECDL/2003/proceedings.
phpf=ecdl2003[22]NationalDietLibrary(Japan).
Webarchivingproject.
2007.
http://warp.
ndl.
go.
jp[23]UKWebarchivingconsortium.
2006.
http://info.
Webarchive.
org.
uk[24]TheLibraryofCongress.
MinervaWebarchivingproject.
2006.
http://lcWeb2.
loc.
gov/cocoon/minerva/html/minerva-home.
html[25]McCownF.
DynamicWebfileformattransformationswithgrace.
In:Proc.
ofthe5thInt'lWebArchivingWorkshopandDigitalPreservation(IWAW2005).
2005.
2223.
http://www.
iwaw.
net/05/papers/iwaw05-mccown2.
pdf[26]LamposC,EirinakiM,JevtuchovaD,VazirgiannisM.
ArchivingthegreekWeb.
In:Proc.
ofthe4thInt'lWebArchivingWorkshop(IWAW2004).
2004.
http://www.
iwaw.
net/04/Lampos.
pdf[27]CallanJ.
Passage-Levelevidenceindocumentretrieval.
In:CroftBW,RijsbergenV,eds.
Proc.
ofthe7thAnnualInt'lACMSIGIRConf.
onResearchandDevelopmentinInformationRetrieval.
NewYork:ACMPress,1994.
302310.
[28]KaszkielM,ZobelJ.
Effectiverankingwitharbitrarypassages.
JournaloftheAmericanSocietyforInformationScience,2001,52(4):344364.
[29]DiaoYL,LuHJ,ChenST,TianZP.
TowardlearningbasedWebqueryprocessing.
In:AbbadiAE,BrodieML,ChakravarthyS,DayalU,KamelN,SchlageterG,WhangKY,eds.
Proc.
ofthe26thInt'lConf.
onVeryLargeDataBases.
SanFransisco:MorganKaufmannPublishers,2000.
317328.
[30]LiSH,HoJM.
DiscoveringinformativecontentblocksfromWebdocuments.
In:HandD,KeimD,NgR,eds.
Proc.
ofthe8thACMSIGKDDInt'lConf.
onKnowledgeDiscoveryandDatamining.
NewYork:ACMPress,2002.
588593.
[31]KaasinenE,AaltonenM,KolariJ,MelakoskiS,LaakkoT.
TwoapproachestobringingInternetservicestoWAPdevices.
ComputerNetworks:TheInt'lJournalofComputerandTelecommunicationsNetworking,2000,33(1-6):231246.
[32]BuyukkoktenO,GarciaH,PaepcheA.
Accordionsummarizationforend-gamebrowsingonPDAsandcellularphones.
In:RossonMB,GilmoreDJ,eds.
Proc.
oftheSIG-CHIonHumanFactorsinComputingSystems.
NewYork:ACMPress,2001.
[33]RahmanA,AlamH,HartonoR.
ContentextractionfromHTMLdocuments.
In:HuJY,ed.
Proc.
ofthe1stInt'lWorkshoponWebDocumentAnalysis(WDA2001).
NewYork:ACMPress,2001.
310.
[34]CaiD,YuS,WenJR,MaWY.
ExtractingcontentstructureforWebpagesbasedonvisualrepresentation.
In:ZhouXF,ZhangYC,OrlowskaME,eds.
Proc.
ofthe5thAsiaPacificWebConf.
Berlin,Heidelberg:Springer-Verlag,2003.
406417.
[35]BurnerM,KahleB.
WWWarchivefileformatspecification.
AlexaInternetInc.
,1996.
http://pages.
alexa.
com/company/arcformat.
html[36]GomesD,SantosAL,SilvaMJ.
Webstore:Amanagerforincrementalstorageofcontents.
TechnicalReport,DI/FCULTR04–15,Lisbon:UniversityofLisbon,2004.
[37]SekiguchiY,KawashimaH,OkudaH,OkuM.
TopicdetectionfromBlogdocumentsusingusers'interests.
In:AbererK,HaraT,eds.
Proc.
ofthe7thInt'lConf.
onMobileDataManagement(MDM2006).
Washington:IEEEComputerSociety,2006.
108111.
290JournalofSoftware软件学报Vol.
19,No.
2,February2008[38]WangXY,XiongFY,LingB,ZhouA.
Asimilarity-basedalgorithmfortopicexplorationanddistillation.
JournalofSoftware,2003,14(9):15781585(inChinesewithEnglishabstract).
http://www.
jos.
org.
cn/1000-9825/14/1578.
htm附中文参考文献:[3]中国Web信息博物馆.
2006.
http://www.
infomall.
cn/[38]王晓宇,熊方,凌波,周傲英.
一种基于相似度分析的主题提取和发现算法.
软件学报,2003,14(9):15781585.
http://www.
jos.
org.
cn/1000-9825/14/1578.
htm宋杰(1980-),男,安徽淮北人,博士生,主要研究领域为Web数据仓库,软件工程.
鲍玉斌(1968-),男,博士,副教授,CCF高级会员,主要研究领域为Web数据仓库.
王大玲(1962-),女,博士,教授,CCF高级会员,主要研究领域为Web挖掘.
申德荣(1962-),女,博士,教授,CCF高级会员,主要研究领域为Web服务.
第5届智能CAD与数字娱乐学术会议征文通知由中国图象图形学会计算机动画与数字娱乐专业委员会、中国人工智能学会智能CAD与数字艺术专业委员会、以及中国工程图学学会国际联络工作委员会联合主办,大连大学承办的第5届智能CAD与数字娱乐学术会议,将于2008年7月22日在美丽的海滨城市大连举行.
一、征文内容(主要包括,但不限于)·智能CAD·数字艺术·计算机动画·虚拟现实·网络游戏·可视化技术·模式识别·人机交互·计算机图形学·图像处理·信息融合·多媒体技术·计算机视觉·人工智能·数字内容管理·交互式玩具·E-Home·运动捕获动画·数字博物馆·人脸表情跟踪与识别二、论文格式及注意事项论文相关要求请登陆会议网站:http://202.
199.
159.
247/cide2008/电子投稿,请将WORD格式的文件发到:xpwei@dlu.
edu.
cn,投稿时务必在电子邮件正文中留下通讯作者的详细通讯地址、邮政编码、电话,以便联系.
三、重要日期截稿日期:2008年3月31日录用日期:2008年4月30日修改稿接收及注册截止日期:2008年5月31日四、联系方式联系人及联系电话:张强(0411-87403733)电子信箱:zhangq30@gmail.
com
ac.
cnJournalofSoftware,Vol.
19,No.
2,February2008,pp.
275290http://www.
jos.
org.
cnDOI:10.
3724/SP.
J.
1001.
2008.
00275Tel/Fax:+86-10-625625632008byJournalofSoftware.
Allrightsreserved.
基于页面Block的Web档案采集和存储宋杰+,王大玲,鲍玉斌,申德荣(东北大学信息科学与工程学院,辽宁沈阳100004)CollectingandStoringWebArchiveBasedonPageBlockSONGJie+,WANGDa-Ling,BAOYu-Bin,SHENDe-Rong(SchoolofInformationScienceandEngineering,NortheasternUniversity,Shenyang110004,China)+Correspondingauthor:Phn:+86-24-83687776,E-mail:sy_songjie@163.
net,http://www.
neu.
edu.
cnSongJ,WangDL,BaoYB,ShenDR.
CollectingandstoringWebarchivebasedonpageblock.
JournalofSoftware,2008,19(2):275290.
http://www.
jos.
org.
cn/1000-9825/19/275.
htmAbstract:Inthispaper,thepageblockbasedWebarchivecollectingandstoringapproachisproposed.
Thealgorithmsoflayout-basedpagepartition,extractingtopicfromblock,versioncomparisonandincrementalstorageimplementationareintroducedindetail.
Theprototypesystemisimplementedandtestedtoverifytheproposedapproach.
Theoreticsandexperimentsshowthat,theproposedapproachadaptstheWebarchivemanagementwell,andprovidesavaluabledataresourcetotheWebarchivebasedquery,search,dataminingandknowledgediscoveringapplications.
Keywords:Webarchive;pagepartition,pageblock摘要:提出了基于页面Block对Web页面的采集和存储方式,并详细表述了该方法如何完成基于布局页面分区、Block主题的抽取、版本和差异的比较以及增量存储的方式.
实现了一个Web归档原型系统,并对所提出的算法进行了详细的测试.
理论和实验表明,所提出的基于页面Block的Web档案(Webarchive)采集和存储方法能够很好地适应Web档案的管理方式,并对基于Web档案的查询、搜索、知识发现和数据挖掘等应用提供有利的数据资源.
关键词:Web档案;页面分区;页块中图法分类号:TP393文献标识码:A由于Web搜索的成功,大量Web用户都习惯于通过搜索引擎来检索信息,但是,这种方式仅能检索到当前的网页.
像新闻、Blogs、论坛这样的Web信息在一年内就会消失[1].
由于Web信息的流逝性,如何利用信息技术来搜集、保存和查询逝去的Web信息成为Web领域中一个崭新的课题.
Web历史或Web档案(Webarchives)是一种基于Web的信息服务,它每隔一段时间就从Internet中抓取网页并以快照的形式保存起来,逐渐形成了一个Web历史网页的博物馆.
这些网页不只是被收集和存储起来,还要进行分类和处理,以方便历史浏览和检索.
现有的Web档案的采集主要有两种方式.
一种方式是网页发布商主动地汇缴给Web档案收集者.
这种方式并不普遍,因为网页发布商部署网页的目的并不是为了归档和收藏,这样做会带来额外的成本且不能产生直接SupportedbytheNationalNaturalScienceFoundationofChinaunderGrantNos.
60573090,60673139(国家自然科学基金)Received2007-08-31;Accepted2007-10-19276JournalofSoftware软件学报Vol.
19,No.
2,February2008效益.
此外,在国家之间汇缴Web页面还存在法律问题[2].
另一种方式就是Web档案收集者利用网络爬虫在Internet中采集.
这种采集方式较为常用但难度较大.
传统的收集方式是采集和保存网页的循环,即在一个固定的时间周期中采集所有的网页,并且按照URL地址分类保存起来.
这种方法存在很大的研究空间:首先应该研究页面的转化和处理方式,是直接以单个页面的形式存储还是对页面进行分割和转化后再存储,处理方式取决于Web档案的使用方式;其次,该方法需要一个良好的版本比较机制,如果不进行版本比较,势必导致存储了大量时间不同但内容相同的网页,且版本比较算法必须成功地迅速检测到网页的部分变化,或者是哪些部分变化,是内容的变化,还是背景、格式或是广告信息的变化;最后是网页的存储方式的研究,由于Web历史信息量非常大,以国内的WebInfoMall为例,其规模以平均每天150万个网页的速度扩大,5年已达到了25亿个网页(约1300GB)[3],因此,Web页面存储应该支持增量的存储方式,即只存储变化的部分.
针对上述问题,本文提出了一种基于页面Block的Web档案采集和存储方法.
我们分析了Web档案的使用方式,认为页面应该按照显示和主题分区,这样有利于Web档案搜索、问题回答(QA)或知识发现.
该方法在使用网络爬虫获取页面以后,根据页面的布局特征将页面分为若干个显示和主题相对独立的矩形区域(Block)以及剔除这些区域剩下的页面框架(Layout),按照这些Block进行版本比较和存储并且只存储发生变化的Block.
本研究还实现了一个Web归档系统的原型,并用实验数据说明该方法的正确性和可用性.
本文第1节介绍研究背景.
第2节阐述基于Block的页面采集和处理方式.
第3节介绍原型系统的实现方式和测试结果.
第4节对前人的相关工作进行简要分析.
第5节总结全文并提出下一步的工作.
1研究背景目前,Web归档系统大多选择整个Web页面作为最小的处理和存储单元,即依赖网页整体内容变化来检测新网页,并且以整个网页快照形式存储页面.
这种方式已逐渐不能适应Web的快速发展,因此,我们提出把页面按照一定的算法分为若干个区域,把这些区域作为基本的存储和处理单元.
提出该方法的理由如下:(1)当今的Web页面更新迅速,页面内容丰富多样,很多页面的内容不是由同一主题的大量平文本而是由多个不相关主题的页面区域构成,并且页面的更新也分解成部分区域的更新,因此,以页面区域为最小单位来采集和存储Web档案更符合实际情况,粒度上明显优于以页面为最小单位的采集和存储.
(2)此外,为了方便用户浏览,Web页面中加入了大量与内容无关的元素,比如导航菜单、输入区、装饰性的标题和图片或者站点相关信息,这些元素信息量较少且相对稳定.
如果采用基于整个页面的Web档案采集和存储,则对这些内容无关的元素的处理和存储势必浪费大量的时间和空间,而如果基于页面区域进行采集和存储,就可以适当忽略这些稳定的且内容无关的区域,节省处理和存储代价.
(3)Web档案的意义在于强大的档案资料库的搜索功能.
对于搜索引擎、QA系统或知识发现系统,以Web网页作为独立语义单元的最大问题在于忽略了页面上存在着多个主题,当查询语句分散在各个主题上时,搜索精度就会显著下降.
因此,按照页面区域来采集和存储Web档案,有利于为档案信息搜索和提取而创建主题相关的数据集,并且排除广告、导航等噪音数据,进而降低搜索难度、提高搜索质量.
网页布局是网页的一个重要的内部结构,从网页的布局我们可以分辨内容相关的信息和内容无关的噪音.
我们根据网页布局把网页划分成若干个区域,在Web档案采集和存储过程中,检测网页整体布局的变化或者部分区域的变化,并把变化的部分保存起来,以达到存储Web档案的目的.
为了方便阐述,本文从WebArchive[4]网站选取了java.
net网站的若干历史网页.
图1中,左图是2007年1月2日该网站的某网页快照,右图是该网页5天后(同年1月7日)的网页快照,为了节省篇幅,在不影响算法说明的前提下,我们对页面作了简化处理.
直观上可以看出,这两个网页结构非常相似.
简单分析页面可以看出,有很多区域与内容信息无关,对信息检索没有帮助,而且相对比较稳定.
本页面主要的内容为虚线矩形区域,该区域又分为若干个主题.
我们分析了大量Web历史页面后发现,每个页面总是存在一些频繁更新的区域,而剩下的区域则很少更新.
在本例中,频繁更新的只有虚线矩形区域.
可以看出,在采集周期(5天)内网页发生了变化,如果时间周期缩短为2天,则很有可能得到两个完全相同的页面.
因此,本研究需要解决以下几个问题:(1)如何对采集的网页自动进行版本比较以确定网页是否更新;宋杰等:基于页面Block的Web档案采集和存储277(2)根据直观的页面分区我们发现,只有中央虚线矩形部分发生了变化,那么,如何以一种合理的方式分割页面并找到变化的部分;(3)显然,为了减少存储开销,Web归档系统可以仅存储发生变化的部分,其存储方式也是本文研究的问题之一.
LogininputAreaBannerFooterSiteInformationQueryInputAreaNavigationNavigationContentContentNavigationNavigationWelcomeTitleTopic1Topic2Topic3Topic4Topic5Fig.
1TwoWebhistorysnapshotsasexample图1作为例子的两个历史网页快照2基于Block的页面采集本节将描述Web页面的分区、主题生成、版本比较和存储算法.
首先我们给出页面Block的相关定义.
定义1(Block).
Block是页面中在内容和显示上独立的、闭合的矩形区域.
Web页面可以分割为若干个互不相交的Block,我们把这个过程称为页面分区.
定义2(Block树).
我们递归定义一个Block可以由多个相互不重叠的Block组成,则图2所示的页面可以分解为图3所示的树形结构,称为Block树.
其中,节点Block是整个页面,是最大粒度的Block,而叶子节点则是最小粒度的Block.
CC1CC6CLCR1B1T2CR2T1B2CC2CC3CC4CC5CCCRFig.
2Blockstructureofanexamplepage图2示例页面的Block结构278JournalofSoftware软件学报Vol.
19,No.
2,February2008定义3(分区级别).
分区级别表示该分区算法产生的Block树的最大深度,用Level表示.
由图4可以看出,在任意深度下,所有叶子节点均能组成页面的一种分区策略.
因此,选择合适的分区级别有助于得到最理想的分区结果.
RootT1B2CCLCCCRCC5CC4CC3CR1CR2CC6CC1CC2T2B1Level0Level1Level2Level3Level1Level2Level3Fig.
3Block-Treeofanexamplepage图3示例页面的Block树Fig.
4Partitionresultofdifferentlevel图4不同分区级别的分区结果定义4(Block主题和内容).
设content为Block内容,即Block中存储的HTML文档,topic为Block主题,即从Block内容中查找或抽取出的能够表示Block内容概要的一段文字,则Block可以定义成一个由主题、内容组成的二元组:Block=topic,content.
定义5(Layout).
设Layout为网页的布局,即剔除了Block的网页框架,其中,Block部分使用占位符填充.
Layout是一个完整的网页,主要包括除了Block部分页面框架以外的像BODY这样的一些全局架构标签,或者是Block之间的分割部分.
定义6(Version).
设Version为某个URL地址在某一个时间点的Web历史记录.
Version可以定义成一个由Layout和若干个Block以及元数据信息组成的三元组:Version=Layout,{Block},MetaData.
2.
1页面分区算法页面分区算法的目标是把页面分割为一组不重叠的Block,这种分割算法基于DOM(documentobjectmodel).
一个Web页面经过解析后可以转换为DOM[5].
DOM提供了树形结构的页面模型,因此,我们可以基于DOM来建立Block树[6,7].
我们当然可以借助大量HTML标签来获取布局和位置信息,如P,TABLE,TR,HR,UL等.
然而,由于HTML语法的灵活性,很多Web页面并不完全遵守W3C的HTML规范.
此外,依据DOM的分区只能代表布局结构独立的区域而不能完全代表语义上独立的区域,比如,同一个父节点下面的两个子节点并不一定代表相同的主题.
因此,分区算法不能完全依赖DOM,还需要考虑其他一些因素.
通常,显示上独立的区域一般表示相同的主题,Web中提供了大量可见的元素来划分页面[8],例如字体、颜色、图像、空白,这些都是页面分区算法需要考虑的元素.
页面分区的整个过程如图5所示.
首先,DOM树和一些字体、颜色信息经抽取Block算法抽取出第n级Block(n初始化为1),组成深度为n的Block树,同时保存Layout.
然后,判断n是否满足给定的分区级别,如果小于该级别,则依次把Block树中的每个叶子节点Block的内容(content)作为新的DOM,重新抽取Block并组装n+1级Block树,如果某个Block已经无法再分割,则忽略这个Block.
如此反复,直到Block树达到给定分区级别为止.
给定分区级别可以根据经验预先设置,也可以根据历史记录动态调整.
图6给出了图1中例子页面的3次分区算法迭代过程中每次生成的Block树,图中深颜色的节点表示不可再分的Block,在迭代中应该忽略.
宋杰等:基于页面Block的Web档案采集和存储279Extractn-levelblockn=MaxOrisblockatomisticYesNotreatblockasanewnoden=n+1BlocktreeTheleafnodeisblock.
.
.
htmlheadbody.
.
.
DOMtreeVisualInfo.
.
.
.
.
.
.
.
.
.
.
.
.
n=0GeneratelayoutFig.
5Block-Basedpagepartitionalgorithm图5基于Block的页面分区算法RootT1B2CT2B1RootT1B2CCLCCCRT2B1RootT1B2CCLCCCRCR1CR2CC6CC1T2B1.
.
.
Fig.
6Block-Treesgeneratedbythreeoverlapsofpagepartitionalgorithm图6页面分区算法3次迭代产生的Block树抽取n级Block算法是一个递归的过程,其主算法为算法1.
在该算法中,depth不同于分区级别,分区级别是Block树中最终的深度,depth是当前节点在DOM数中的深度.
depth的最大值MaxDepth参照分区级别设置,但二者之间没有必然联系.
算法1.
抽取Block.
Input:pNodeisDOM,depthisdepthofpNodeinDOMtree;Output:抽取的Block.
ExtractBlock(pNode,depth)1Ifdepth>MaxDepth2Return;3End;3IfIsBlock(pNode)==True4SavepNodeasaBlockintoBlockpool;5Else6ForeachchildofpNode7ExtractBlock(child,depth+1);8End;9End;Block抽取算法的关键在于,遍历DOM树时,如何判断一个节点是否是一个Block,即IsBlock算法.
在描述IsBlock算法之前首先定义以下几个函数.
设node为DOM树中的某一个节点,则:280JournalofSoftware软件学报Vol.
19,No.
2,February2008inode.
properties表示取当前节点的属性,如bgcolor,font,width和height分别表示背景颜色、字体、宽度和高度.
node.
tag表示当前节点的HTML标签.
node.
type表示节点的类别.
我们把HTML标签分为布局标签、格式标签和功能标签3类,布局标签多数与网页的布局有关,如TABLE,TD,TR,HR,P等;格式标签多与文字、图片等页面元素的格式有关,如B,BIG,EM,FONT,I,STRONG,U,DIV等;功能标签多数是显示特定的非文本元素,如FORM,A,INPUT,IMG,BUTTON等.
Schema,.
.
Format,.
Function,.
nodetagnodetypenodetagnodetag∈=∈∈布局标签格式标签功能标签.
node.
subNode表示当前节点的子节点集合,该集合的长度用node.
subNode.
length表示.
下面的Rule1~Rule11是判断一个节点是否是Block所依次遵循的法则.
Rule1.
如果当前节点没有子节点或子节点大小均为0,则该节点不是Block.
否则Rule2.
如果当前节点是Function节点,则该节点不是Block.
否则Rule3.
如果当前节点是Format节点,则该节点不是Block.
否则Rule4.
如果当前节点只有1个子节点,则该节点不是Block.
否则Rule5.
如果当前节点的尺寸小于标签的给定最小值,则该节点不是Block.
否则Rule6.
如果当前节点的颜色与子节点颜色不同,则该节点不是Block.
否则Rule7.
如果当前节点是Schema节点,且子节点中没有Format或Function节点,则该节点不是Block.
否则Rule8.
如果当前节点是Schema节点,且子节点只包含Format或Function节点,则该节点是Block.
否则Rule9.
如果当前节点是Schema节点,且子节点中的Schema节点递归满足Rule8或Rule9,则该节点是Block.
否则Rule10.
如果当前节点的前一个兄弟节点是Block,则该节点是Block.
否则Rule11.
该节点不是Block.
根据Rule1~Rule11,我们重新考虑图2所示的例子.
如图6和图7所示,如果设分区级别为3,那么,首先抽取深度为1的Block树,T1,T2,C,B1,B2很容易被抽取出来.
第2轮抽取深度为2的Block树,由于T1,T2,B1,B2都已经是最小粒度,无法再分割,所以考虑继续分割C,C的第1个子节点TD有24个DIV子标签,DIV子标签多是链接标签,TD符合Rule8,抽取名为CL的Block.
根据Rule10很容易得到CC和CR这两个Block.
最后抽取级别为3的Block.
根据Rule2和Rule3,可以判断CL无法进一步分割.
CC可以分割为CC1~CC6,CR可以分割为CR1~CR6.
2.
2主题生成算法为了便于对Block进行检索、分类和管理,我们提供了一种简单的方法为每一个Block生成一句主题文字.
主题生成算法要求具有唯一性,即相同的内容抽取的主题相同,但主题相同对应的内容则不一定相同.
通常可以采用两种算法生成主题:一种是通过字体、颜色和位置等信息查找主题;另一种是利用数据挖掘的方法抽取主题.
在介绍这两种方法之前,首先对一些操作进行定义.
由Block定义可知,Block中包含的content也是一段HTML文档,包含着文字和格式信息,我们不难把content中每个含有文字的Format标签抽取出来.
如果用T表示这些Format标签的集合,设有n个Format标签,每个标签ti(1≤i≤n)又可以分为格式信息formati和文字信息texti,设Format是所有format的集合,Text是所有text的集合,那么,集合T可以表示为Format集合和Text集合组成的二元组.
{|11.
iiiiTtinFormatTexttformatttextformattextin宋杰等:基于页面Block的Web档案采集和存储281tabledivtablehtmlheadbodytrtdtdtddivdivdivppppppptabletabletable.
.
.
pCC1CC6CLCR1B1T2CR2T1B2CC2CC3CC4CC5CCCRT1T2CB1B2CLCCCRCR1CR2CC1CC2CC3CC4CC5CC6Fig.
7DOMstructureandcorrespondingBlockstructureofexamplepage图7示例页面的DOM结构和对应的Block结构定义7(长度函数).
以参数texti为例,length(texti)返回texti中单词的个数,或者以参数Text为例:1()(niilengthTextlengthtext==∑)).
1)查找Topic在大多数Web页的Block中已经存在一个主题,它以较大的字体、显著的位置或者不同的颜色来显示.
这种情况下,主题生成算法的重点就是如何找到一个已存在的主题.
主题topic的查找步骤如下:步骤1:遍历集合Text并找到一段文字texti,其对应的formati是集合Format中字体最大或者位置独立且靠前的,或者颜色与其他不同的;步骤2:如果θ是主题中的单词数目最大限定值,那么,,(.
(),()iiiitextlengthtexttopictrimtextlengthtextθθ≤=>这里,trim(texti)是一个能够将一个段落缩减到只含θ个单词的函数.
算法2给出了trim(texti)函数:算法2.
裁减内容.
Input:textiasaparagraph,astoplistfileS,wordnumberthresholdθ.
Output:AsetTWconsistingofallwordsoftopicphrase.
trim(texti)1Deletestopwordsfromtextiaccordingtostoplist;2TW={};3Forj=1toθStep14wordj=wordoftextiwhichindexisj;5IfwordjTW6PutwordjintoTW;7End;8End;9ReturnTW;282JournalofSoftware软件学报Vol.
19,No.
2,February2008在算法2中,第1行采用stoplist[9]进行了预处理.
2)抽取主题在一些Block中,有些主题没有用特殊的格式突显出来,甚至根本没有主题.
在这种情况下,主题生成算法的重点是如何从现有的文字中抽取出一个主题.
许多Web挖掘研究提供了抽取Web页面主题的算法,这些算法可能适用于含有大量文字的Block.
但是,对于文字量很少的Block来说,数据挖掘算法很难有意义.
抽取主题的算法如下:设δ为一个区间,表示适合Web挖掘算法的最小单词数,texti∈Text(1≤i≤n),则(),().
(),()iiiitrimtextlengthtexttopicextracttextlengthtextδδε7)PutwordjintoTW;8)End;9)End;10)ReturnTW;在算法3中,1~2行是用stoplist[9]和stemming[10]对text进行预处理.
这里,Text是整个Block中包含的文字,texti是每个Block中每个标签包含的文字(texti∈Text),wordj是texti文字中的一个单词,tf(texti,wordj)是wordj在文档texti出现的绝对频率[11].
2.
3页面比较算法页面比较算法用来比较新采集的页面和上一个版本的差异.
当采集到一个新版本的页面快照(version)时,需要对其进行分区处理,获得其所有Block和Layout,然后与最近一次历史Version进行版本比较,找出差异的部分存储,如果新、旧页面完全一致,则表示页面没有更新,本次采集无效.
设α和β为Web历史采集的两个连续的时间点(α保存网页的整体框架.
Layout代表了一种网页的布局,存储的是除了Block部分以外的页面框架.
由于网页的Layout很少发生变化,大量Version都对应一个Layout.
Label:Label是Block的分类信息,表明了Block中内容的类别,为以后的历史搜索、知识发现和数据挖掘提供信息.
以第2.
3节中α和β的两个连续的时间点(α<β)为例,算法4描述了vβ的存储处理算法.
算法4.
存储采集的页面.
Store()1Boolflag=false;2IfByteEqual(lα,lβ)==True3Foreachbα,bβinbsαandbsβ,4Ifbα!
=bβ5Savebβandbβ'sLabel6flag=true;7End8End9End10Else11Savelβ;12flag=true;284JournalofSoftware软件学报Vol.
19,No.
2,February200813Foreachbβinbsβ,14Savebβandbβ'sLabel15End16End17Ifflag==true18Savevβandvβ'sVersionMataData19constructallrelationships20End算法首先判断Layout是否相等:如果相等,则存储差异的Block;如果不等,则存储全部的Layout;然后,存储分类信息和元数据;最后,建立各个部分之间的关系.
对于图2给出的例子,我们第2次采集只需要存储CC2~CC6这5个Block.
2.
5总体流程本文第2节介绍了基于页面Block的Web档案采集和存储的核心算法,当网络爬虫采集到页面以后,首先根据当前的URL地址查找最近的一个Version:如果不存在该URL地址,说明这是一个新的页面,则按照系统默认的分区级别抽取Block和Layout,给每个Block抽取主题,存储图8中表述的每个结构;如果找到当前URL最近的Version记录,则根据该Version的分区级别抽取当前页面的Block和Layout,然后根据算法4描述的过程存储采集的网页.
Web归档系统还可以利用大量的历史信息来指导自身,比如利用某个网页的历史分区方式和经常变化的Block来指导网页分区.
如图2给出的例子,如果网页频繁变化的是CC2~CC6这5个Block,我们可以设置分区级别为2级,这样,CC2和CC6就合为一个Block,简化了版本比较(但是,这种合并只是从采集存储角度来进行,并非一定有利于Web档案的应用).
此外,网站的更新频率一般是有规律的,根据文献[16]提出的思想,我们可以通过同一URL的各个Version之间的间隔来推断最佳的采集频率,减少采集不到网页变化的可能性.
3原型系统和实验分析为了证明本文提出的基于页面Block的Web档案管理方法的正确性和有效性,我们设计了一个原型系统Block-basedWebArchivePrototype(BWAP),并且对其进行了详细的测试.
首先,我们采用软件测试的方法对系统进行测试;依据现有的知识,我们没有发现同类工作的运行性能数据,因此没有进行性能比较,而只是在测试中对系统性能作了定性的衡量.
相对于性能因素而言,本研究更关心的是系统的精确度,因此,我们组织了一个实验对系统的精确度加以验证.
3.
1原型系统结构图9说明了BWAP的主要构件以及它们之间的关系,图中箭头的方向是主要数据的流动方向,采用的例子是本文第2节反复提及的示例.
上标α表示当前采集的页面版本,β表示该URL的Web档案信息中最近的一个版本.
由图中可以看出,采集的页面最终保存CC2~CC6这5个Block和相关元数据到Web档案库中.
图中相关组件的功能如下:PageCache:页面缓存用来缓存Crawler获取的页面,使采集和页面处理可以异步进行,降低耦合度.
ThreadController:线程控制器,可以多线程地同时对多个页面执行处理和存储.
PageProcessor:页面处理器,用来分割页面,获取Blocks和Layout.
TopicGenerator:主题生成器,为每个Block查找或抽取主题.
MetaDataGenerator:元数据生成器,根据用户设置的元数据生成各种元数据.
StoreAgent:存储代理,完成Layout,Blocks和元数据的存储工作.
VersionManager:版本管理器,完成基于Block的页面版本比较(见第2.
3节).
宋杰等:基于页面Block的Web档案采集和存储285LevelManager:分区级别管理器,能够选择、查找历史或适当地调整每个网页的分区级别.
Query&StorageProxy:Web存档库的查询和存储代理.
PagecacheUserInternetCrawlerTopicgeneratorPageprocessorQueryproxyVersionmanagerStorageproxyLevelmanagerThreadcontrollerMetaDatageneratorMetaDataruleRepositoryStoreAgentAllmeta-dataMeta-DataruleBWAPFig.
9OverviewofBWAP图9BWAP总体结构当Crawler获取了页面并存入PageCache以后,ThreadController启动一个线程来处理pageα.
首先处理pageα的是PageProcessor,这时,LevelManager根据pageα的URL,通过QueryProxy在Repository中查找合适的分区级别;然后,PageProcessor根据分区级别把pageα分割成layoutα和blocksα;blocksα通过TopicGenerator生成主题后,与layoutα一同转到VersionManage模块进行版本比较;VersionManage通过QueryProxy在Repository中找到layoutβ和blocksβ后,按照第2.
3节中的比较算法进行版本比较;最后,MetaDataGenerator根据管理员输入的元数据生成规则和pageα相关信息生成相关元数据,并与版本比较结果(有差异的Blocks)一同由StoreAgent通过StorageProxy存入Repository.
整个系统的时序图如图10所示.
Fig.
10SequencediagramofBWAP图10BWAP时序图PageαblockαPageαPageαlayoutβblockβlevelβCC2~CC6layoutαblockαPageprocessorThreadcontrollerTopicgeneratorLevelmanagerStoreAgentVersionmanagerQuery&storageproxyMetaDatageneratorQueryReturnFindPartitionReturnGeneratetopicReturntopicCompareversionReturndifferentQuerythelatestversionReturnGeneratemetadataReturnallmetadataStoreStorelayoutβblockβblockαlevelβlevelβlevelβlayoutαblockα286JournalofSoftware软件学报Vol.
19,No.
2,February20083.
2系统测试为了说明BWAP的功能完整性,我们为BWAP设计了详尽的测试.
BWAP通过了很多严格的测试用例,本节列出了部分测试用例和测试结果,它们涵盖以下几个方面:功能测试:保证BWAP可以在各种输入数据集下完成既定的功能逻辑;白盒测试:对BWAP中每一个构件以及构件内部的特定代码块进行测试;性能测试:在各种条件下,对系统处理和响应时间进行测试;集成测试:主要是测试BWAP内部构件的集成性以及与其他构件或框架的兼容性.
表1列出了部分测试用例和测试结果.
Table1Testcasesandtestresults表1测试用例和测试结果CategoryTestcaseResultTestthesystemcandealwiththepageswhoselayoutschangefrequently.
SuccessTestthesystemcandealwiththepageswhichhavetinychange.
SuccessTestthesystemcandealwiththepageswhosestructuresareabnormallycomplex.
SuccessTestthesystemcandealwiththepageswhosestructuresareabnormallysimple.
SuccessTestthesystemcandealwiththepageswhichincludemanyscripts.
SuccessTestthesystemcandealwiththepageswhichincludetextmostly.
FailureTestthesystemcandealwiththepageswhichincludealotofblanks.
SuccessTestthesystemcandealwiththefragmentarypages.
SuccessTestthesystemcandealwiththepageswhichcontainlotsofimages.
SuccessTestthesystemcandealwiththepagesbygreatpartitionlevel.
SuccessTestthesystemcandealwiththepagesbysmallpartitionlevel.
SuccessFunctionaltestingTestthesystemcandealwiththepagesbyunstablepartitionlevel.
SuccessWalkthroughthecodeandreviewitforsuchqualitiesaslogic,adherencetodevelopmentstandardsandbestpractices,andreadablecomments.
DoneRunthecodeagainstacode-coveragetooltomakesurethatalltheavailablecodeisbeingtested.
DoneWhiteboxtestingPerformmemoryprofilingofthecodetomakesurethatobjectsarecorrectlyreleasedandgarbageiscollected.
DoneTesttoseeifsystemprocessingpagestakesmuchprolongedmuchmoretimethancrawlercollectionpages.
NoTesttoseeifstoringtakesmuchprolongedtimethanprocessing.
NoTesttheperformanceofeachcomponenttofindbottleneck.
NoneTestperformancebydealingwithseveralthousandspagesonetime.
GoodTestperformancewhenprocessandstorepageswhichhavemanyimages.
BetterTestperformancewhenprocessandstorelargepages.
GoodPerformancetestingTestperformancewhenprocessandstorepageswithlimitedmemory.
NormalTesttheserverrunningatWindows,Linux,andUnixsystem.
SuccessTesttheframeworkcanintegratingwithkeycomponentsofJ2EEsuchasJTAandJAAS.
PartlysuccessIntegrationtestingTesttheframeworkcanrunningwithvariousdatabasesuchasOracle,SQLServerandDB2.
Success表1所列结果表明:BWAP在各种条件和数据环境下均能准确地完成分割页面、定位变化的页面区域、生成主题关键字、比较版本以及增量存储等功能;BWAP通过了代码走查、评审、内存泄漏检测和代码覆盖软件的逻辑覆盖测试;BWAP在高并发或大数据量的测试下运行性能良好;BWAP能够在各种平台下运行,并且不依赖特定的数据库种类.
3.
3实验分析基于页面Block的Web档案的采集和存储算法中最关键的一步就是定位页面发生变化的区域.
以图1为例,如果采用观察的方法,则能很准确地确定变化的最小区域(虚线矩形).
如果采用算法处理,若分区级别设为1,则得到C区是变化的区域;若分区级别设为2,则得到CC区是变化的区域;若分区级别设为3,则得到CC2~CC6这5个区域是变化的区域(如图2和图3所示).
因此,算法的判断与人的判断存在一定的差异.
检验算法是否、合理准确的最好办法是手工验证.
因此,我们首先选择了200对来自于文献[4]的历史网页,每对网页的采集时间非常接近,并且这些网页分属于不同的主题,以确保网页结构广泛、多样.
首先,我们通过BWAP把每对网页中时间较早的一个置入Web档案库中,然后再装入时间较晚的一个.
我们收集BWAP报告的后一个页面的分区结果和变宋杰等:基于页面Block的Web档案采集和存储287化的Block,同时,我们选择4位志愿者分别来检查这些结果,并且以Perfect,Good,Normal,Bad这4个级别给以评价.
图11和图12给出了评价结果.
0%10%20%30%40%50%60%PerfectGoodNormalBadRankPercentUser1User2User3User4Perfect41%Good45%Normal13%Bad1%Fig.
11Testresultsofeachuser图11每个用户的测试结果Fig.
12Averageproportionofeachrank图12每个级别的平均比例从图11的平滑曲线可以看出,4位志愿者的评价结果非常相似,这是由于每人评价的数据集是相同的,都是算法处理这200个页面的结果;由于从优到劣只分出4个级别,曲线特征并不明显,但仍可以看出,除了User3以外,其他曲线近似于一种正态分布,峰值位于Good级别,这些都表明算法的准确性和合理性.
从图12可以看出,这800次评价中结果是Perfect和Good的占86%,仅有1%为Bad.
我们考察了评价为Normal以下的约14%的页面发现,导致算法不精确的原因是多方面的:一些是浏览器和开源HTML解析工具的客观原因,主观原因及算法不足之处主要是无法区分那些用图片、Flash和文字来分割的区域,因此,该算法还有很大的提升空间.
尽管如此,不足1%的Bad评价率已经证明该算法的正确性.
此外,在这800次评价中并没有发现算法不能识别的页面变化.
少量的页面分区不合理可能会对存储带来负面影响,但不会影响对Web页面的变化的采集和保存.
4相关工作WebArchive属于一种新兴的技术.
根据澳大利亚国家图书馆在2003年的统计,仅有16个国家拥有完整的国内Web归档系统[17].
对Web档案的处理也处于发展阶段.
我们在研究Web档案处理成果的同时,也参考了大量Web领域相关的工作.
首先是Web归档系统的实现技术.
前人在Web归档系统的实现技术上作了大量研究.
TheInternetArchive是Web归档系统的先锋,它通过一个叫做Heritrix的开源爬虫实现对页面的抓取[18].
文献[19,20]描述了实现一个Web归档系统的系统结构和相关标准,并且实现了一个名为Tomba的原型系统.
本文学习了它的很多思想以及实现方式,尤其在Web页面的存储结构设计上借鉴了很多.
文献[21]实现了NWA工具集来访问NordicWebArchive并进行查询搜索.
此外,本研究也广泛参考了各国[2226]的Web归档系统的实现技术.
这些文献大多是在介绍Web档案的管理技术,或者在总体结构、存储和使用手段上进行研究.
与此不同的是,本研究主要提出基于页面Block来管理Web档案,是对传统Web档案管理方法的一种改进.
其次是Web页面的分区技术.
在传统的文本处理中,通常使用固定长度的段落或者窗口(window)来分割页面[27,28].
一个固定长度的段落包含一定数目的连续单词.
对Web文档来说,如果移除HTML标签和属性,则可以使用这种办法来分割页面.
固定长度的分割虽然精简并具有高性能,但也损失了大量HTML信息,不宜用作Web档案页面的分割算法.
此外,有许多学者考虑到运用HTML标签来分割页面,这些标签包括P,TABLE,UL等.
文献[29]在一个Web查询处理系统中利用这些标签对页面进行了分割.
文献[30]只把TABLE标签和TABLE标签内的所有子标签分为1个内容块,这显然忽略了大量信息,只使用TABLE标签是远远不够的.
文献[31,32]288JournalofSoftware软件学报Vol.
19,No.
2,February2008用一些像P,TABLE和UL这样的简单标签将网页分割成若干区域,并进一步进行转化和抽取摘要,然而,它们只是考虑标签类别而忽视了格式、样式等信息.
此外,文献[33]对页面分解算法作出了大量评论,但没有涉及到技术细节.
文献[34]对Web页面分区作了透彻的分析,并提出依赖可视化元素来分割页面的VIPS算法.
该研究工作对我们有很大的启发,然而VIPS算法过于复杂,不宜用于Web归档系统.
相比之下,本文提出的算法比较简单.
另外,这些工作均未把网页分区技术运用到Web历史档案信息处理领域.
尽管这些方法还都存在不足,但对本文的页面分区算法仍有很大的帮助.
本文也参考了一些Web存储技术[35,36]和Web挖掘以及主题抽取技术[37,38].
这些技术并非是针对Web档案的采集和处理,或者属于一些底层的存储技术.
我们借鉴了其思想,并灵活运用到Web档案的处理上.
5结论与展望本文描述了基于页面Block的Web档案的采集和存储方法,文中详细阐述了对页面进行分区、主题抽取、版本比较和增量存储这一过程中每个步骤的算法.
本文提出的基于页面Block的管理思路将便于Web档案的管理,并对基于Web档案的查询、搜索、知识发现和数据挖掘应用提供丰富的数据资源.
本研究的主要贡献有以下几点:提出基于页面Block的Web档案的管理方式;描述了页面分割算法、主题生成算法、页面比较算法和增量存储算法;实现了一个Web归档原型系统BWAP并用实验数据来验证算法的正确性.
本研究还处于初步阶段.
进一步的工作主要包括两个方向:一是进一步完善分区算法,包括能够适应页面在不改变总体布局的情况下增减Block的数目,Block的Label信息的生成以及通过历史分区信息自动学习、调整、优化的分区算法;二是如何利用Block资源完成基于Block的历史搜索、问答系统和历史知识发现.
References:[1]NtoulasA,ChoJ,OlstonC.
What'snewontheWebTheevolutionoftheWebfromasearchengineperspective.
In:ChenYR,KovácsL,LawrenceS,eds.
Proc.
ofthe13thInt'lConf.
onWorldWideWeb.
NewYork:ACMPress,2004.
112.
[2]NationalLiberarayofAustralia.
Padi-Webarchiving.
2006.
http://www.
nla.
gov.
au/padi/topics/92.
html[3]WebInfoMall.
2006(inChinese).
http://www.
infomall.
cn/[4]InternetarchiveWayBackmachine.
http://www.
archive.
org/Web/Web.
php[5]GuptaS,KaiserG,StolfoS.
ExtractingcontexttoimproveaccuracyforHTMLcontentextraction.
In:EllisA,TatsuyaH,eds.
Proc.
ofthe14thInt'lConf.
onWorldWideWeb—SpecialInterestTracksandPosters.
NewYork:ACMPress,2005.
11141115.
[6]LinSH,HoJM.
DiscoveringinformativecontentblocksfromWebdocuments.
In:HandD,KeimD,eds.
Proc.
ofthe8thACMSIGKDDInt'lConf.
onKnowledgeDiscoveryandDataMining.
NewYork:ACMPress,2002.
588593.
[7]WongWC,FuAW.
FindingstructureandcharacteristicsofWebdocumentsforclassification.
In:GunopulosD,RastogiR,eds.
Proc.
oftheACMSIGMODWorkshoponResearchIssuesinDataMiningandKnowledgeDiscovery.
NewYork:ACMPress,2000.
96105.
[8]YangYD,ZhangHJ.
HTMLpageanalysisbasedonvisualcues.
In:AntonacopoulosA,GatosB,eds.
Proc.
ofthe6thInt'lConf.
onDocumentAnalysisandRecognition.
Washington:IEEEComputerSociety,2001.
859864.
[9]http://www.
dcs.
gla.
ac.
uk/idom/ir_resources/linguistic_utils/stop_words[10]http://www.
dcs.
gla.
ac.
uk/idom/ir_resources/linguistic_utils/porter.
c[11]KantrowitzM,MohitB,MittalV.
StemminganditseffectsonTFIDFranking.
In:NicholasJ,PeterI,Mun-KewL,eds.
Proc.
ofthe23rdAnnualInt'lACMSIGIRConf.
onResearchandDevelopmentinInformationRetrieval.
NewYork:ACMPress,2000.
357359.
[12]MacDonaldJ.
Versionedfilearchiving,compression,anddistribution.
UCBerkeley,1999.
http://www.
cs.
berkeley.
edu/~jmacd/[13]BerlinerB.
CVSII:Parallelizingsoftwaredevelopment.
In:Proc.
oftheUSENIXWinter1990TechnicalConf.
Berkeley:USENIXAssociation,1990.
341352.
宋杰等:基于页面Block的Web档案采集和存储289[14]GomesD,CamposJP,SilvaMJ.
Versus:AWebrepository.
2003.
http://xldb.
fc.
ul.
pt/referencias[15]GomesD,LSantosA,SilvaMJ.
ManagingduplicatesinaWebarchive.
In:LiebrockLM,ed.
Proc.
ofthe21stAnnualACMSymp.
onAppliedComputing.
NewYork:ACMPress,2006.
818825.
[16]ChoJ,Garcia-MolinaH.
Estimatingfrequencyofchange.
ACMTrans.
onInternetTechnology(TOIT),2003,3(3):256290.
[17]PhillipsM.
PANDORA,Australia'sWebarchive,andthedigitalarchivingsystemthatsupportsit.
DigiCULT.
info,2003,(6):2430.
http://www.
nla.
gov.
au/nla/staffpaper/2003/mphillips1.
html[18]HalseJE,MohrG,SigurdssonK,StackM,JackP.
Heritrixdeveloperdocumentation.
2005.
http://crawler.
archive.
org/articles/developer_manual/index.
html[19]GomesD,FreitasS,SilvaMJ.
DesignandselectioncriteriaforanationalWebarchive.
In:ThanosC,GonzaloJ,eds.
Proc.
ofthe10thEuropeanConf.
ofResearchandAdvancedTechnologyforDigitalLibraries(ECDL).
Berlin,Heidelberg:Springer-Verlag,2006.
196207.
[20]SilvaMJ.
SearchingandarchivingtheWebwithtumba!
.
In:Proc.
ofthe4thConf.
onAssociationPortugalofSystemandInformation(CAPSI).
2003.
http://xldb.
fc.
ul.
pt/data/Publications_attach/tumba-search+archive-capsi-final.
pdf[21]HallgrimssonD,BangS.
NordicWebarchive.
In:MichaelD,ed.
Proc.
ofthe3rdECDLWorkshoponWebArchives.
2003.
http://bibnum.
bnf.
fr/ECDL/2003/proceedings.
phpf=ecdl2003[22]NationalDietLibrary(Japan).
Webarchivingproject.
2007.
http://warp.
ndl.
go.
jp[23]UKWebarchivingconsortium.
2006.
http://info.
Webarchive.
org.
uk[24]TheLibraryofCongress.
MinervaWebarchivingproject.
2006.
http://lcWeb2.
loc.
gov/cocoon/minerva/html/minerva-home.
html[25]McCownF.
DynamicWebfileformattransformationswithgrace.
In:Proc.
ofthe5thInt'lWebArchivingWorkshopandDigitalPreservation(IWAW2005).
2005.
2223.
http://www.
iwaw.
net/05/papers/iwaw05-mccown2.
pdf[26]LamposC,EirinakiM,JevtuchovaD,VazirgiannisM.
ArchivingthegreekWeb.
In:Proc.
ofthe4thInt'lWebArchivingWorkshop(IWAW2004).
2004.
http://www.
iwaw.
net/04/Lampos.
pdf[27]CallanJ.
Passage-Levelevidenceindocumentretrieval.
In:CroftBW,RijsbergenV,eds.
Proc.
ofthe7thAnnualInt'lACMSIGIRConf.
onResearchandDevelopmentinInformationRetrieval.
NewYork:ACMPress,1994.
302310.
[28]KaszkielM,ZobelJ.
Effectiverankingwitharbitrarypassages.
JournaloftheAmericanSocietyforInformationScience,2001,52(4):344364.
[29]DiaoYL,LuHJ,ChenST,TianZP.
TowardlearningbasedWebqueryprocessing.
In:AbbadiAE,BrodieML,ChakravarthyS,DayalU,KamelN,SchlageterG,WhangKY,eds.
Proc.
ofthe26thInt'lConf.
onVeryLargeDataBases.
SanFransisco:MorganKaufmannPublishers,2000.
317328.
[30]LiSH,HoJM.
DiscoveringinformativecontentblocksfromWebdocuments.
In:HandD,KeimD,NgR,eds.
Proc.
ofthe8thACMSIGKDDInt'lConf.
onKnowledgeDiscoveryandDatamining.
NewYork:ACMPress,2002.
588593.
[31]KaasinenE,AaltonenM,KolariJ,MelakoskiS,LaakkoT.
TwoapproachestobringingInternetservicestoWAPdevices.
ComputerNetworks:TheInt'lJournalofComputerandTelecommunicationsNetworking,2000,33(1-6):231246.
[32]BuyukkoktenO,GarciaH,PaepcheA.
Accordionsummarizationforend-gamebrowsingonPDAsandcellularphones.
In:RossonMB,GilmoreDJ,eds.
Proc.
oftheSIG-CHIonHumanFactorsinComputingSystems.
NewYork:ACMPress,2001.
[33]RahmanA,AlamH,HartonoR.
ContentextractionfromHTMLdocuments.
In:HuJY,ed.
Proc.
ofthe1stInt'lWorkshoponWebDocumentAnalysis(WDA2001).
NewYork:ACMPress,2001.
310.
[34]CaiD,YuS,WenJR,MaWY.
ExtractingcontentstructureforWebpagesbasedonvisualrepresentation.
In:ZhouXF,ZhangYC,OrlowskaME,eds.
Proc.
ofthe5thAsiaPacificWebConf.
Berlin,Heidelberg:Springer-Verlag,2003.
406417.
[35]BurnerM,KahleB.
WWWarchivefileformatspecification.
AlexaInternetInc.
,1996.
http://pages.
alexa.
com/company/arcformat.
html[36]GomesD,SantosAL,SilvaMJ.
Webstore:Amanagerforincrementalstorageofcontents.
TechnicalReport,DI/FCULTR04–15,Lisbon:UniversityofLisbon,2004.
[37]SekiguchiY,KawashimaH,OkudaH,OkuM.
TopicdetectionfromBlogdocumentsusingusers'interests.
In:AbererK,HaraT,eds.
Proc.
ofthe7thInt'lConf.
onMobileDataManagement(MDM2006).
Washington:IEEEComputerSociety,2006.
108111.
290JournalofSoftware软件学报Vol.
19,No.
2,February2008[38]WangXY,XiongFY,LingB,ZhouA.
Asimilarity-basedalgorithmfortopicexplorationanddistillation.
JournalofSoftware,2003,14(9):15781585(inChinesewithEnglishabstract).
http://www.
jos.
org.
cn/1000-9825/14/1578.
htm附中文参考文献:[3]中国Web信息博物馆.
2006.
http://www.
infomall.
cn/[38]王晓宇,熊方,凌波,周傲英.
一种基于相似度分析的主题提取和发现算法.
软件学报,2003,14(9):15781585.
http://www.
jos.
org.
cn/1000-9825/14/1578.
htm宋杰(1980-),男,安徽淮北人,博士生,主要研究领域为Web数据仓库,软件工程.
鲍玉斌(1968-),男,博士,副教授,CCF高级会员,主要研究领域为Web数据仓库.
王大玲(1962-),女,博士,教授,CCF高级会员,主要研究领域为Web挖掘.
申德荣(1962-),女,博士,教授,CCF高级会员,主要研究领域为Web服务.
第5届智能CAD与数字娱乐学术会议征文通知由中国图象图形学会计算机动画与数字娱乐专业委员会、中国人工智能学会智能CAD与数字艺术专业委员会、以及中国工程图学学会国际联络工作委员会联合主办,大连大学承办的第5届智能CAD与数字娱乐学术会议,将于2008年7月22日在美丽的海滨城市大连举行.
一、征文内容(主要包括,但不限于)·智能CAD·数字艺术·计算机动画·虚拟现实·网络游戏·可视化技术·模式识别·人机交互·计算机图形学·图像处理·信息融合·多媒体技术·计算机视觉·人工智能·数字内容管理·交互式玩具·E-Home·运动捕获动画·数字博物馆·人脸表情跟踪与识别二、论文格式及注意事项论文相关要求请登陆会议网站:http://202.
199.
159.
247/cide2008/电子投稿,请将WORD格式的文件发到:xpwei@dlu.
edu.
cn,投稿时务必在电子邮件正文中留下通讯作者的详细通讯地址、邮政编码、电话,以便联系.
三、重要日期截稿日期:2008年3月31日录用日期:2008年4月30日修改稿接收及注册截止日期:2008年5月31日四、联系方式联系人及联系电话:张强(0411-87403733)电子信箱:zhangq30@gmail.
com
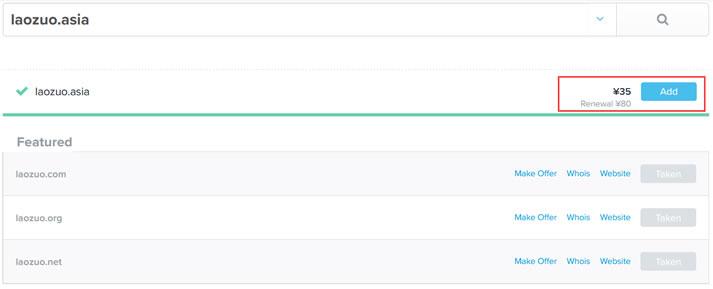
.asia域名是否适合做个人网站及.asia域名注册和续费成本
今天看到群里的老秦同学在布局自己的网站项目,这个同学还是比较奇怪的,他就喜欢用这些奇怪的域名。比如前几天看到有用.in域名,个人网站他用的.me域名不奇怪,这个还是常见的。今天看到他在做的一个范文网站的域名,居然用的是 .asia 后缀。问到其理由,是有不错好记的前缀。这里简单的搜索到.ASIA域名的新注册价格是有促销的,大约35元首年左右,续费大约是80元左右,这个成本算的话,比COM域名还贵。...
Spinservers:美国独立服务器(圣何塞),$111/月
spinservers是Majestic Hosting Solutions,LLC旗下站点,主营美国独立服务器租用和Hybrid Dedicated等,spinservers这次提供的大硬盘、大内存服务器很多人很喜欢。TheServerStore自1994年以来,它是一家成熟的企业 IT 设备供应商,专门从事二手服务器和工作站业务,在德克萨斯州拥有40,000 平方英尺的仓库,库存中始终有数千台...
HostKvm5.95美元起,香港、韩国可选
HostKvm发布了夏季特别促销活动,针对香港国际/韩国机房VPS主机提供7折优惠码,其他机房全场8折,优惠后2GB内存套餐月付仅5.95美元起。这是一家成立于2013年的国外主机服务商,主要提供基于KVM架构的VPS主机,可选数据中心包括日本、新加坡、韩国、美国、中国香港等多个地区机房,均为国内直连或优化线路,延迟较低,适合建站或者远程办公等。下面分享几款香港VPS和韩国VPS的配置和价格信息。...
保存网页为你推荐
-
互联网周鸿祎solutionssb支持ipadnetbios端口netbios ssn是什么意思?traceroute网络管理工具traceroute是什么程序fusionchartsfusioncharts怎么生成图片至excelwin7如何关闭445端口如何判断445端口是否关闭xp系统关闭445端口xp中,如何关闭掉一些没有用的端口,请高手解答?googleadsenceGoogle AdSense 帐户状态是什么意思!morphvoxpro怎么用MorphVOX Pro变声器声音怎样调试