大规模分布式存储系统分布式文件系统的系统分类
大规模分布式存储系统 时间:2021-05-28 阅读:()
国内较好的分布式云存储产品有哪些?
分布式存储应用十分广泛,在云计算领域十分常见。因为业务特点和自身实力和资源等综合原因,很多大型的云计算厂商都会选择自主开发或二次开发分布式存储系统,这些厂商本身的产品性能也会比较稳定,在此我列举一下这些厂商。
1. 公有云方面:阿里云的盘古和腾讯的PaxosStore,这两个存储系统分别支撑了大多数阿里云和腾讯系产品的存储和计算。
2. 私有云方面:国外的有VMware的vSAN,谷歌的Google Megastore等;国内的有新华三的ONEStor、华为的FusionStorage、云宏的WinStore等。
在这里特别提一下云宏的WinStore存储,他们的产品在金融领域应用非常广泛,除了自主研发的虚拟化平台,他们也特别提到这个存储技术,WinStore是他们自主研发的分布式存储系统,使得他们的产品在数据存储安全性和容灾性能上有优势。
如何实现企业数据 大数据平台 分布式存放
Hadoop在可伸缩性、健壮性、计算性能和成本上具有无可替代的优势,事实上已成为当前互联网企业主流的大数据分析平台。本文主要介绍一种基于Hadoop平台的多维分析和数据挖掘平台架构。
作为一家互联网数据分析公司,我们在海量数据的分析领域那真是被“逼上梁山”。
多年来在严苛的业务需求和数据压力下,我们几乎尝试了所有可能的大数据分析方法,最终落地于Hadoop平台之上。
1. 大数据分析大分类 Hadoop平台对业务的针对性较强,为了让你明确它是否符合你的业务,现粗略地从几个角度将大数据分析的业务需求分类,针对不同的具体需求,应采用不同的数据分析架构。
按照数据分析的实时性,分为实时数据分析和离线数据分析两种。
实时数据分析一般用于金融、移动和互联网B2C等产品,往往要求在数秒内返回上亿行数据的分析,从而达到不影响用户体验的目的。
要满足这样的需求,可以采用精心设计的传统关系型数据库组成并行处理集群,或者采用一些内存计算平台,或者采用HDD的架构,这些无疑都需要比较高的软硬件成本。
目前比较新的海量数据实时分析工具有EMC的Greenplum、SAP的HANA等。
对于大多数反馈时间要求不是那么严苛的应用,比如离线统计分析、机器学习、搜索引擎的反向索引计算、推荐引擎的计算等,应采用离线分析的方式,通过数据采集工具将日志数据导入专用的分析平台。
但面对海量数据,传统的ETL工具往往彻底失效,主要原因是数据格式转换的开销太大,在性能上无法满足海量数据的采集需求。
互联网企业的海量数据采集工具,有Facebook开源的Scribe、LinkedIn开源的Kafka、淘宝开源的Timetunnel、Hadoop的Chukwa等,均可以满足每秒数百MB的日志数据采集和传输需求,并将这些数据上载到Hadoop中央系统上。
按照大数据的数据量,分为内存级别、BI级别、海量级别三种。
这里的内存级别指的是数据量不超过集群的内存最大值。
不要小看今天内存的容量,Facebook缓存在内存的Memcached中的数据高达320TB,而目前的PC服务器,内存也可以超过百GB。
因此可以采用一些内存数据库,将热点数据常驻内存之中,从而取得非常快速的分析能力,非常适合实时分析业务。
图1是一种实际可行的MongoDB分析架构。
图1 用于实时分析的MongoDB架构 MongoDB大集群目前存在一些稳定性问题,会发生周期性的写堵塞和主从同步失效,但仍不失为一种潜力十足的可以用于高速数据分析的NoSQL。
此外,目前大多数服务厂商都已经推出了带4GB以上SSD的解决方案,利用内存+SSD,也可以轻易达到内存分析的性能。
随着SSD的发展,内存数据分析必然能得到更加广泛的应用。
BI级别指的是那些对于内存来说太大的数据量,但一般可以将其放入传统的BI产品和专门设计的BI数据库之中进行分析。
目前主流的BI产品都有支持TB级以上的数据分析方案。
种类繁多,就不具体列举了。
海量级别指的是对于数据库和BI产品已经完全失效或者成本过高的数据量。
海量数据级别的优秀企业级产品也有很多,但基于软硬件的成本原因,目前大多数互联网企业采用Hadoop的HDFS分布式文件系统来存储数据,并使用MapReduce进行分析。
本文稍后将主要介绍Hadoop上基于MapReduce的一个多维数据分析平台。
数据分析的算法复杂度 根据不同的业务需求,数据分析的算法也差异巨大,而数据分析的算法复杂度和架构是紧密关联的。
举个例子,Redis是一个性能非常高的内存Key-Value NoSQL,它支持List和Set、SortedSet等简单集合,如果你的数据分析需求简单地通过排序,链表就可以解决,同时总的数据量不大于内存(准确地说是内存加上虚拟内存再除以2),那么无疑使用Redis会达到非常惊人的分析性能。
还有很多易并行问题(Embarrassingly Parallel),计算可以分解成完全独立的部分,或者很简单地就能改造出分布式算法,比如大规模脸部识别、图形渲染等,这样的问题自然是使用并行处理集群比较适合。
而大多数统计分析,机器学习问题可以用MapReduce算法改写。
MapReduce目前最擅长的计算领域有流量统计、推荐引擎、趋势分析、用户行为分析、数据挖掘分类器、分布式索引等。
2. 面对大数据OLAP大一些问题 OLAP分析需要进行大量的数据分组和表间关联,而这些显然不是NoSQL和传统数据库的强项,往往必须使用特定的针对BI优化的数据库。
比如绝大多数针对BI优化的数据库采用了列存储或混合存储、压缩、延迟加载、对存储数据块的预统计、分片索引等技术。
Hadoop平台上的OLAP分析,同样存在这个问题,Facebook针对Hive开发的RCFile数据格式,就是采用了上述的一些优化技术,从而达到了较好的数据分析性能。
如图2所示。
然而,对于Hadoop平台来说,单单通过使用Hive模仿出SQL,对于数据分析来说远远不够,首先Hive虽然将HiveQL翻译MapReduce的时候进行了优化,但依然效率低下。
多维分析时依然要做事实表和维度表的关联,维度一多性能必然大幅下降。
其次,RCFile的行列混合存储模式,事实上限制死了数据格式,也就是说数据格式是针对特定分析预先设计好的,一旦分析的业务模型有所改动,海量数据转换格式的代价是极其巨大的。
最后,HiveQL对OLAP业务分析人员依然是非常不友善的,维度和度量才是直接针对业务人员的分析语言。
而且目前OLAP存在的最大问题是:业务灵活多变,必然导致业务模型随之经常发生变化,而业务维度和度量一旦发生变化,技术人员需要把整个Cube(多维立方体)重新定义并重新生成,业务人员只能在此Cube上进行多维分析,这样就限制了业务人员快速改变问题分析的角度,从而使所谓的BI系统成为死板的日常报表系统。
使用Hadoop进行多维分析,首先能解决上述维度难以改变的问题,利用Hadoop中数据非结构化的特征,采集来的数据本身就是包含大量冗余信息的。
同时也可以将大量冗余的维度信息整合到事实表中,这样可以在冗余维度下灵活地改变问题分析的角度。
其次利用Hadoop MapReduce强大的并行化处理能力,无论OLAP分析中的维度增加多少,开销并不显著增长。
换言之,Hadoop可以支持一个巨大无比的Cube,包含了无数你想到或者想不到的维度,而且每次多维分析,都可以支持成千上百个维度,并不会显著影响分析的性能。
而且目前OLAP存在的最大问题是:业务灵活多变,必然导致业务模型随之经常发生变化,而业务维度和度量一旦发生变化,技术人员需要把整个Cube(多维立方体)重新定义并重新生成,业务人员只能在此Cube上进行多维分析,这样就限制了业务人员快速改变问题分析的角度,从而使所谓的BI系统成为死板的日常报表系统。
3. 一种Hadoop多维分析平台的架构 整个架构由四大部分组成:数据采集模块、数据冗余模块、维度定义模块、并行分 析模块。
数据采集模块采用了Cloudera的Flume,将海量的小日志文件进行高速传输和合并,并能够确保数据的传输安全性。
单个collector宕机之后,数据也不会丢失,并能将agent数据自动转移到其他的colllecter处理,不会影响整个采集系统的运行。
如图5所示。
数据冗余模块不是必须的,但如果日志数据中没有足够的维度信息,或者需要比较频繁地增加维度,则需要定义数据冗余模块。
通过冗余维度定义器定义需要冗余的维度信息和来源(数据库、文件、内存等),并指定扩展方式,将信息写入数据日志中。
在海量数据下,数据冗余模块往往成为整个系统的瓶颈,建议使用一些比较快的内存NoSQL来冗余原始数据,并采用尽可能多的节点进行并行冗余;或者也完全可以在Hadoop中执行批量Map,进行数据格式的转化。
维度定义模块是面向业务用户的前端模块,用户通过可视化的定义器从数据日志中定义维度和度量,并能自动生成一种多维分析语言,同时可以使用可视化的分析器通过GUI执行刚刚定义好的多维分析命令。
并行分析模块接受用户提交的多维分析命令,并将通过核心模块将该命令解析为Map-Reduce,提交给Hadoop集群之后,生成报表供报表中心展示。
核心模块是将多维分析语言转化为MapReduce的解析器,读取用户定义的维度和度量,将用户的多维分析命令翻译成MapReduce程序。
核心模块的具体逻辑如图6所示。
图6中根据JobConf参数进行Map和Reduce类的拼装并不复杂,难点是很多实际问题很难通过一个MapReduce Job解决,必须通过多个MapReduce Job组成工作流(WorkFlow),这里是最需要根据业务进行定制的部分。
图7是一个简单的MapReduce工作流的例子。
MapReduce的输出一般是统计分析的结果,数据量相较于输入的海量数据会小很多,这样就可以导入传统的数据报表产品中进行展现。
当前主流分布式文件系统有哪些?各有什么优缺点?
目前几个主流的分布式文件系统除GPFS外,还有PVFS、Lustre、PanFS、GoogleFS等。1.PVFS(Parallel Virtual File System)项目是Clemson大学为了运行Linux集群而创建的一个开源项目,目前PVFS还存在以下不足: 1)单一管理节点:只有一个管理节点来管理元数据,当集群系统达到一定的规模之后,管理节点将可能出现过度繁忙的情况,这时管理节点将成为系统瓶颈; 2)对数据的存储缺乏容错机制:当某一I/O节点无法工作时,数据将出现不可用的情况; 3)静态配置:对PVFS的配置只能在启动前进行,一旦系统运行则不可再更改原先的配置。
2.Lustre文件系统是一个基于对象存储的分布式文件系统,此项目于1999年在Carnegie Mellon University启动,Lustre也是一个开源项目。
它只有两个元数据管理节点,同PVFS类似,当系统达到一定的规模之后,管理节点会成为Lustre系统中的瓶颈。
3.PanFS(Panasas File System)是Panasas公司用于管理自己的集群存储系统的分布式文件系统。
4.GoogleFS(Google File System)是Google公司为了满足公司内部的数据处理需要而设计的一套分布式文件系统。
5.相对其它的文件系统,GPFS的主要优点有以下三点: 1)使用分布式锁管理和大数据块策略支持更大规模的集群系统,文件系统的令牌管理器为块、inode、属性和目录项建立细粒度的锁,第一个获得锁的客户将负责维护相应共享对象的一致性管理,这减少了元数据服务器的负担; 2)拥有多个元数据服务器,元数据也是分布式,使得元数据的管理不再是系统瓶颈; 3)令牌管理以字节作为锁的最小单位,也就是说除非两个请求访问的是同一文件的同一字节数据,对于数据的访问请求永远不会冲突.
分布式文件系统的系统分类
(DFS) 是AFS的一个版本,作为开放软件基金会(OSF)的分布式计算环境(DCE)中的文件系统部分。如果文件的访问仅限于一个用户,那么分布式文件系统就很容易实现。
可惜的是,在许多网络环境中这种限制是不现实的,必须采取并发控制来实现文件的多用户访问,表现为如下几个形式: 只读共享 任何客户机只能访问文件,而不能修改它,这实现起来很简单。
受控写操作 采用这种方法,可有多个用户打开一个文件,但只有一个用户进行写修改。
而该用户所作的修改并不一定出现在其它已打开此文件的用户的屏幕上。
并发写操作 这种方法允许多个用户同时读写一个文件。
但这需要操作系统作大量的监控工作以防止文件重写,并保证用户能够看到最新信息。
这种方法即使实现得很好,许多环境中的处理要求和网络通信量也可能使它变得不可接受。
NFS和AFS的区别 NFS和AFS的区别在于对并发写操作的处理方法上。
当一个客户机向服务器请求一个文件(或数据库记录),文件被放在客户工作站的高速缓存中,若另一个用户也请求同一文件,则它也会被放入那个客户工作站的高速缓存中。
当两个客户都对文件进行修改时,从技术上而言就存在着该文件的三个版本(每个客户机一个,再加上服务器上的一个)。
有两种方法可以在这些版本之间保持同步: 无状态系统 在这个系统中,服务器并不保存其客户机正在缓存的文件的信息。
因此,客户机必须协同服务器定期检查是否有其他客户改变了自己正在缓存的文件。
这种方法在大的环境中会产生额外的LAN通信开销,但对小型LAN来说,这是一种令人满意的方法。
NFS就是个无状态系统。
回呼(Callback)系统 在这种方法中,服务器记录它的那些客户机的所作所为,并保留它们正在缓存的文件信息。
服务器在一个客户机改变了一个文件时使用一种叫回叫应答(callbackpromise)的技术通知其它客户机。
这种方法减少了大量网络通信。
AFS(及OSFDCE的DFS)就是回叫系统。
客户机改变文件时,持有这些文件拷贝的其它客户机就被回叫并通知这些改变。
无状态操作在运行性能上有其长处,但AFS通过保证不会被回叫应答充斥也达到了这一点。
方法是在一定时间后取消回叫。
客户机检查回叫应答中的时间期限以保证回叫应答是当前有效的。
回叫应答的另一个有趣的特征是向用户保证了文件的当前有效性。
换句话说,若一个被缓存的文件有一个回叫应答,则客户机就认为文件是当前有效的,除非服务器呼叫指出服务器上的该文件已改变了。
Yonghong Z-Data Mart Yonghong Data Mart是一款数据存储、数据处理的软件。
Yonghong Data Mart采用基于ZDFS的分布式列存储系统,就是将数据分散存储在多台独立的设备上。
传统的网络存储系统采用集中的存储服务器存放所有数据,存储服务器成为系统性能的瓶颈,也是可靠性和安全性的焦点,不能满足大规模存储应用的需要。
分布式网络存储系统采用可扩展的系统结构,利用多台存储服务器分担存储负荷,利用位置服务器定位存储信息,它不但提高了系统的可靠性、可用性和存取效率,还易于扩展。
Yonghong Data Mart的分布式文件存储系统 (ZDFS)是在Hadoop HDFS基础上进行的改造和扩展,将服务器集群内所有节点上存储的文件统一管理和存储。
这些节点包括唯一的一个NamingNode,在 ZDFS 内部提供元数据服务;许多MapNode,提供存储块。
存储在 ZDFS 中的文件被分成块,然后将这些块复制到多个计算机中(Map Node)。
这与传统的 RAID 架构大不相同。
块的大小和复制的块数量在创建文件时由客户机决定。
Naming Node监控存在服务器集群内所有节点上的文件操作,例如文件创建、删除、移动、重命名等等。
Network File System
- 大规模分布式存储系统分布式文件系统的系统分类相关文档
- 大规模分布式存储系统hadoop开发和数据挖掘选哪个好
- 大规模分布式存储系统什么是分布式存储系统?
酷番云78元台湾精品CN2 2核 1G 60G SSD硬盘
酷番云怎么样?酷番云就不讲太多了,介绍过很多次,老牌商家完事,最近有不少小伙伴,一直问我台湾VPS,比较难找好的商家,台湾VPS本来就比较少,也介绍了不少商家,线路都不是很好,有些需求支持Windows是比较少的,这里我们就给大家测评下 酷番云的台湾VPS,支持多个版本Linux和Windows操作系统,提供了CN2线路,并且还是原生IP,更惊喜的是提供的是无限流量。有需求的可以试试。可以看到回程...
美国cera机房 2核4G 19.9元/月 宿主机 E5 2696v2x2 512G
美国特价云服务器 2核4G 19.9元杭州王小玉网络科技有限公司成立于2020是拥有IDC ISP资质的正规公司,这次推荐的美国云服务器也是商家主打产品,有点在于稳定 速度 数据安全。企业级数据安全保障,支持异地灾备,数据安全系数达到了100%安全级别,是国内唯一一家美国云服务器拥有这个安全级别的商家。E5 2696v2x2 2核 4G内存 20G系统盘 10G数据盘 20M带宽 100G流量 1...
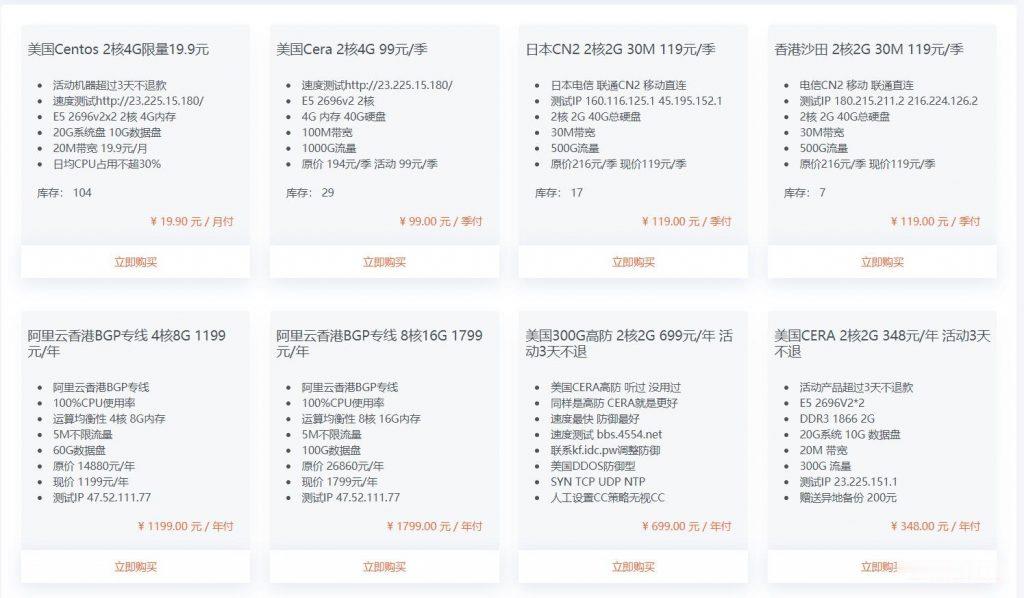
TmhHost暑假活动:高端线路VPS季付8折优惠,可选洛杉矶CN2 GIA/日本软银/香港三网CN2 GIA/韩国双向CN2等
tmhhost怎么样?tmhhost正在搞暑假大促销活动,全部是高端线路VPS,现在直接季付8折优惠,活动截止时间是8月31日。可选机房及线路有美国洛杉矶cn2 gia+200G高防、洛杉矶三网CN2 GIA、洛杉矶CERA机房CN2 GIA,日本软银(100M带宽)、香港BGP直连200M带宽、香港三网CN2 GIA、韩国双向CN2。点击进入:tmhhost官方网站地址tmhhost优惠码:Tm...

大规模分布式存储系统为你推荐
-
小米云服务器登录小米帐号登录官网传奇云服务器传奇只开一个网关游戏会卡吗?云服务器2核2g系统盘50g数据盘10g带宽20m,加速器789给个网速加速器,永久免费的中国电信112测速中国电信 上行速度 最高几M?共享虚拟主机基础版主机与VMWare虚拟机文件共享的几种方法云服务器可以做什么小米云服务的家人共享能做什么?那好上海哪里好找工作?快云服务器快云的云服务器好用吗?在线图片换背景照片手机自动换背景接收验证码手机为什么突然收到很多验证码短信