fileinputformatHadoop,Combiner有什么用?
fileinputformat 时间:2021-06-08 阅读:()
如何使用Hadoop的Partitioner
Hadoop里面的MapReduce编程模型,非常灵活,大部分环节我们都可以重写它的API,来灵活定制我们自己的一些特殊需求。今天散仙要说的这个分区函数Partitioner,也是一样如此,下面我们先来看下Partitioner的作用: 对map端输出的数据key作一个散列,使数据能够均匀分布在各个reduce上进行后续操作,避免产生热点区。
Hadoop默认使用的分区函数是Hash Partitioner,源码如下: /** Partition keys by their {@link Object#hashCode()}. */ public class HashPartitioner<K, V> extends Partitioner<K, V> { /** Use {@link Object#hashCode()} to partition. */ public int getPartition(K key, V value, int numReduceTasks) { //默认使用key的hash值与上int的最大值,避免出现数据溢出 的情况 return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks; } } 大部分情况下,我们都会使用默认的分区函数,但有时我们又有一些,特殊的需求,而需要定制Partition来完成我们的业务,案例如下: 对如下数据,按字符串的长度分区,长度为1的放在一个,2的一个,3的各一个。
河南省;1 河南;2 中国;3 中国人;4 大;1 小;3 中;11 这时候,我们使用默认的分区函数,就不行了,所以需要我们定制自己的Partition,首先分析下,我们需要3个分区输出,所以在设置reduce的个数时,一定要设置为3,其次在partition里,进行分区时,要根据长度具体分区,而不是根据字符串的hash码来分区。
核心代码如下: /** * Partitioner * * * */ public static class PPartition extends Partitioner<Text, Text>{ @Override public int getPartition(Text arg0, Text arg1, int arg2) { /** * 自定义分区,实现长度不同的字符串,分到不同的reduce里面 * * 现在只有3个长度的字符串,所以可以把reduce的个数设置为3 * 有几个分区,就设置为几 * */ String key=arg0.toString(); if(key.length()==1){ return 1%arg2; }else if(key.length()==2){ return 2%arg2; }else if(key.length()==3){ return 3%arg2; } return 0; } } 全部代码如下: .partition.test; import java.io.IOException; .apache.hadoop.fs.FileSystem; .apache.hadoop.fs.Path; .apache.hadoop.io.LongWritable; .apache.hadoop.io.Text; .apache.hadoop.mapred.JobConf; .apache.hadoop.mapreduce.Job; .apache.hadoop.mapreduce.Mapper; .apache.hadoop.mapreduce.Partitioner; .apache.hadoop.mapreduce.Reducer; .apache.hadoop.mapreduce.lib.db.DBConfiguration; .apache.hadoop.mapreduce.lib.db.DBInputFormat; .apache.hadoop.mapreduce.lib.input.FileInputFormat; .apache.hadoop.mapreduce.lib.output.FileOutputFormat; .apache.hadoop.mapreduce.lib.output.MultipleOutputs; .apache.hadoop.mapreduce.lib.output.TextOutputFormat; .qin.operadb.PersonRecoder; .qin.operadb.ReadMapDB; /** * @author qindongliang * * 大数据交流群:376932160 * * * **/ public class MyTestPartition { /** * map任务 * * */ public static class PMapper extends Mapper<LongWritable, Text, Text, Text>{ @Override protected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException { // System.out.println("进map了"); //mos.write(namedOutput, key, value); String ss[]=value.toString().split(";"); context.write(new Text(ss[0]), new Text(ss[1])); } } /** * Partitioner * * * */ public static class PPartition extends Partitioner<Text, Text>{ @Override public int getPartition(Text arg0, Text arg1, int arg2) { /** * 自定义分区,实现长度不同的字符串,分到不同的reduce里面 * * 现在只有3个长度的字符串,所以可以把reduce的个数设置为3 * 有几个分区,就设置为几 * */ String key=arg0.toString(); if(key.length()==1){ return 1%arg2; }else if(key.length()==2){ return 2%arg2; }else if(key.length()==3){ return 3%arg2; } return 0; } } /*** * Reduce任务 * * **/ public static class PReduce extends Reducer<Text, Text, Text, Text>{ @Override protected void reduce(Text arg0, Iterable<Text> arg1, Context arg2) throws IOException, InterruptedException { String key=arg0.toString().split(",")[0]; System.out.println("key==> "+key); for(Text t:arg1){ //System.out.println("Reduce: "+arg0.toString()+" "+t.toString()); arg2.write(arg0, t); } } } public static void main(String[] args) throws Exception{ JobConf conf=new JobConf(ReadMapDB.class); //Configuration conf=new Configuration(); conf.set("mapred.job.tracker","192.168.75.130:9001"); //读取person中的数据字段 conf.setJar("tt.jar"); //注意这行代码放在最前面,进行初始化,否则会报 /**Job任务**/ Job job=new Job(conf, "testpartion"); job.setJarByClass(MyTestPartition.class); System.out.println("模式: "+conf.get("mapred.job.tracker"));; // job.setCombinerClass(PCombine.class); job.setPartitionerClass(PPartition.class); job.setNumReduceTasks(3);//设置为3 job.setMapperClass(PMapper.class); // MultipleOutputs.addNamedOutput(job, "hebei", TextOutputFormat.class, Text.class, Text.class); // MultipleOutputs.addNamedOutput(job, "henan", TextOutputFormat.class, Text.class, Text.class); job.setReducerClass(PReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); String path="hdfs://192.168.75.130:9000/root/outputdb"; FileSystem fs=FileSystem.get(conf); Path p=new Path(path); if(fs.exists(p)){ fs.delete(p, true); System.out.println("输出路径存在,已删除!"); } FileInputFormat.setInputPaths(job, "hdfs://192.168.75.130:9000/root/input"); FileOutputFormat.setOutputPath(job,p ); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
如何使用eclipse调试Hadoop作业
将hadoop开发包里面的相关jar导进工程就行, 至于想调试,就看hadoop计数器返回到eclipse里的内容就可以了. 不过有一点, 如果调试的是MapReduce,速度可能不快.Hadoop,Combiner有什么用?
Combiner,Combiner号称本地的Reduce,Reduce最终的输入,是Combiner的输出。Combiner是用reducer来定义的,多数的情况下Combiner和reduce处理的是同一种逻辑,所以job.setCombinerClass()的参数可以直接使用定义的reduce。
当然也可以单独去定义一个有别于reduce的Combiner,继承Reducer,写法基本上定义reduce一样。
- fileinputformatHadoop,Combiner有什么用?相关文档
- fileinputformatmapreduce 键值对怎么定义的
- fileinputformat不同mapreduce程序可以连续运行吗?比如说多个这样的程序,用上一个的输出作为下一个的输入,求
- fileinputformathadoop 怎么设置多个输入路径
buyvm迈阿密机房VPS国内首发测评,高性能平台:AMD Ryzen 9 3900x+DDR4+NVMe+1Gbps带宽不限流量
buyvm的第四个数据中心上线了,位于美国东南沿海的迈阿密市。迈阿密的VPS依旧和buyvm其他机房的一样,KVM虚拟,Ryzen 9 3900x、DDR4、NVMe、1Gbps带宽、不限流量。目前还没有看见buyvm上架迈阿密的block storage,估计不久也会有的。 官方网站:https://my.frantech.ca/cart.php?gid=48 加密货币、信用卡、PayPal、...
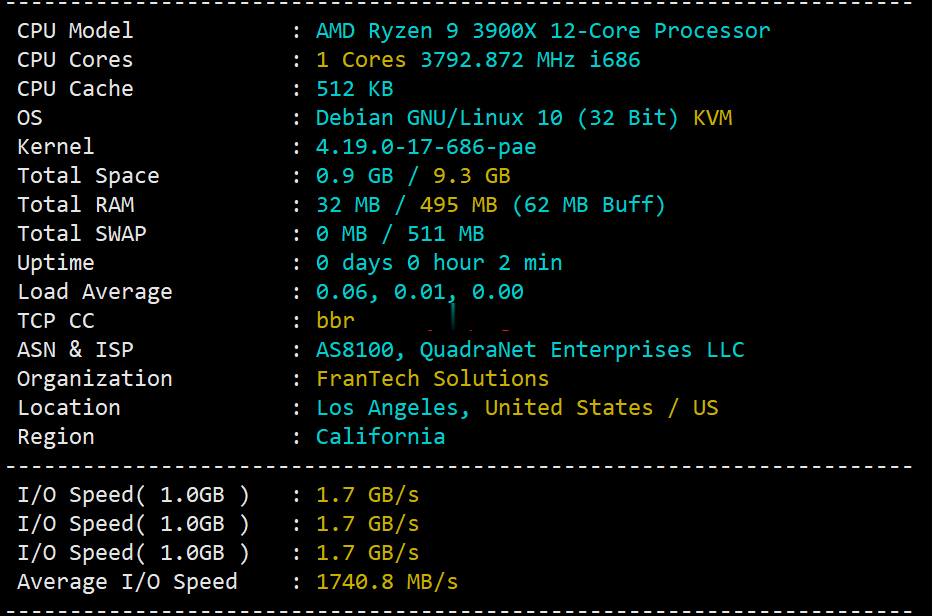
Sharktech:无限流量服务器丹佛,洛杉矶,荷兰$49/月起,1Gbps带宽哦!
鲨鱼机房(Sharktech)我们也叫它SK机房,是一家成立于2003年的老牌国外主机商,提供的产品包括独立服务器租用、VPS主机等,自营机房在美国洛杉矶、丹佛、芝加哥和荷兰阿姆斯特丹等,主打高防产品,独立服务器免费提供60Gbps/48Mpps攻击防御。机房提供1-10Gbps带宽不限流量服务器,最低丹佛/荷兰机房每月49美元起,洛杉矶机房最低59美元/月起。下面列出部分促销机型的配置信息。机房...

Hostio€5/月KVM-2GB/25GB/5TB/荷兰机房
Hostio是一家成立于2006年的国外主机商,提供基于KVM架构的VPS主机,AMD EPYC CPU,NVMe硬盘,1-10Gbps带宽,最低月付5欧元起。商家采用自己的网络AS208258,宿主机采用2 x AMD Epyc 7452 32C/64T 2.3Ghz CPU,16*32GB内存,4个Samsung PM983 NVMe SSD,提供IPv4+IPv6。下面列出几款主机配置信息。...
fileinputformat为你推荐
-
scheduleatfixedrate运用Executors.newScheduledThreadPool的任务调度怎么解决chrome系统Chromenbsp;OS是操作系统吗?视频技术视频监控技术的定义及特点搜索引擎的概念搜索引擎的工作原理是什么及发展历史awvAWV的转换器 要免费的 看好是AWV不是AMVstar413匡威jack star 的后标是不是真的?如图模式识别算法模式识别、神经网络、遗传算法、蚁群算法等等人工智能算法需要哪些数学知识?电子邮件软件常用的邮件收发软件红牛下架红牛下架事件怎么回事?美宜佳最近怎么买不到红牛了?私服发布站程序如何在电脑上建一个私服网站?有网站源码!