网络爬虫是什么什么是网络的拓
网络爬虫是什么 时间:2021-09-14 阅读:()
什么是增量式抓取 关于网络爬虫的
Nutch爬虫的工作策略一般则可以分为累积式抓取(cumulative crawling)和增量式抓取(incremental crawling)两种。累积式抓取是指从某一个时间点开始,通过遍历的方式抓取系统所能允许存储和处理的所有网页。
在理想的软硬件环境 下,经过足够的运行时间,累积式抓取的策略可以保证抓取到相当规模的网页集合。
但由于Web数据的动态特性,集合中网页的被抓取时间点是不同的,页面被更新的情况也不同,因此累积式抓取到的网页集合事实上并无法与真实环境中的网络数据保持一致。
增量式抓取是指在具有一定量规模的网络页面集合的基础上,采用更新数据的方式选取已有集合中的过时网页进行抓取,以保证所抓取到的数据与真实网络数据足够接近。
进行增量式抓取的前提是,系统已经抓取了足够数量的网络页面,并具有这些页面被抓取的时间信息。
面向实际应用环境的网络蜘蛛设计中,通常既包括累积式抓取,也包括增量式抓取的策略。
累积式抓取一般用于数据集合的整体建立或大规模更新阶段;而增量式抓取则主要针对数据集合的日常维护与即时更新。
谁能仔细解释一下网络爬虫
1 爬虫技术研究综述 引言 随着网络的迅速发展,万维网成为大量信息的载体,如何有效地提取并利用这些信息成为一个巨大的挑战。搜索引擎(Search Engine),例如传统的通用搜索引擎AltaVista,Yahoo!和Google等,作为一个辅助人们检索信息的工具成为用户访问万维网的入口和指南。
但是,这些通用性搜索引擎也存在着一定的局限性,如: (1) 不同领域、不同背景的用户往往具有不同的检索目的和需求,通用搜索引擎所返回的结果包含大量用户不关心的网页。
(2) 通用搜索引擎的目标是尽可能大的网络覆盖率,有限的搜索引擎服务器资源与无限的网络数据资源之间的矛盾将进一步加深。
(3) 万维网数据形式的丰富和网络技术的不断发展,图片、数据库、音频/视频多媒体等不同数据大量出现,通用搜索引擎往往对这些信息含量密集且具有一定结构的数据无能为力,不能很好地发现和获取。
(4) 通用搜索引擎大多提供基于关键字的检索,难以支持根据语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的聚焦爬虫应运而生。
聚焦爬虫是一个自动下载网页的程序,它根据既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所需要的信息。
与通用爬虫(generalpurpose web crawler)不同,聚焦爬虫并不追求大的覆盖,而将目标定为抓取与某一特定主题内容相关的网页,为面向主题的用户查询准备数据资源。
1 聚焦爬虫工作原理及关键技术概述 网络爬虫是一个自动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL放入队列,直到满足系统的一定停止条件,如图1(a)流程图所示。
聚焦爬虫的工作流程较为复杂,需要根据一定的网页分析算法过滤与主题无关的链接,保留有用的链接并将其放入等待抓取的URL队列。
然后,它将根据一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止,如图1(b)所示。
另外,所有被爬虫抓取的网页将会被系统存贮,进行一定的分析、过滤,并建立索引,以便之后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。
相对于通用网络爬虫,聚焦爬虫还需要解决三个主要问题: (1) 对抓取目标的描述或定义; (2) 对网页或数据的分析与过滤; (3) 对URL的搜索策略。
抓取目标的描述和定义是决定网页分析算法与URL搜索策略如何制订的基础。
而网页分析算法和候选URL排序算法是决定搜索引擎所提供的服务形式和爬虫网页抓取行为的关键所在。
这两个部分的算法又是紧密相关的。
2 抓取目标描述 现有聚焦爬虫对抓取目标的描述可分为基于目标网页特征、基于目标数据模式和基于领域概念3种。
基于目标网页特征的爬虫所抓取、存储并索引的对象一般为网站或网页。
根据种子样本获取方式可分为: (1) 预先给定的初始抓取种子样本; (2) 预先给定的网页分类目录和与分类目录对应的种子样本,如Yahoo!分类结构等; (3) 通过用户行为确定的抓取目标样例,分为: a) 用户浏览过程中显示标注的抓取样本; b) 通过用户日志挖掘得到访问模式及相关样本。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,等等。
现有的聚焦爬虫对抓取目标的描述或定义可以分为基于目标网页特征,基于目标数据模式和基于领域概念三种。
基于目标网页特征的爬虫所抓取、存储并索引的对象一般为网站或网页。
具体的方法根据种子样本的获取方式可以分为:(1)预先给定的初始抓取种子样本;(2)预先给定的网页分类目录和与分类目录对应的种子样本,如Yahoo!分类结构等;(3)通过用户行为确定的抓取目标样例。
其中,网页特征可以是网页的内容特征,也可以是网页的链接结构特征,等等。
作者: 齐保元 2006-1-10 10:11 回复此发言 -------------------------------------------------------------------------------- 2 爬虫技术研究综述 基于目标数据模式的爬虫针对的是网页上的数据,所抓取的数据一般要符合一定的模式,或者可以转化或映射为目标数据模式。
另一种描述方式是建立目标领域的本体或词典,用于从语义角度分析不同特征在某一主题中的重要程度。
3 网页搜索策略 网页的抓取策略可以分为深度优先、广度优先和最佳优先三种。
深度优先在很多情况下会导致爬虫的陷入(trapped)问题,目前常见的是广度优先和最佳优先方法。
3.1 广度优先搜索策略 广度优先搜索策略是指在抓取过程中,在完成当前层次的搜索后,才进行下一层次的搜索。
该算法的设计和实现相对简单。
在目前为覆盖尽可能多的网页,一般使用广度优先搜索方法。
也有很多研究将广度优先搜索策略应用于聚焦爬虫中。
其基本思想是认为与初始URL在一定链接距离内的网页具有主题相关性的概率很大。
另外一种方法是将广度优先搜索与网页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。
这些方法的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。
3.2 最佳优先搜索策略 最佳优先搜索策略按照一定的网页分析算法,预测候选URL与目标网页的相似度,或与主题的相关性,并选取评价最好的一个或几个URL进行抓取。
它只访问经过网页分析算法预测为“有用”的网页。
存在的一个问题是,在爬虫抓取路径上的很多相关网页可能被忽略,因为最佳优先策略是一种局部最优搜索算法。
因此需要将最佳优先结合具体的应用进行改进,以跳出局部最优点。
将在第4节中结合网页分析算法作具体的讨论。
研究表明,这样的闭环调整可以将无关网页数量降低30%~90%。
4 网页分析算法 网页分析算法可以归纳为基于网络拓扑、基于网页内容和基于用户访问行为三种类型。
4.1 基于网络拓扑的分析算法 基于网页之间的链接,通过已知的网页或数据,来对与其有直接或间接链接关系的对象(可以是网页或网站等)作出评价的算法。
又分为网页粒度、网站粒度和网页块粒度这三种。
4.1.1 网页(Webpage)粒度的分析算法 PageRank和HITS算法是最常见的链接分析算法,两者都是通过对网页间链接度的递归和规范化计算,得到每个网页的重要度评价。
PageRank算法虽然考虑了用户访问行为的随机性和Sink网页的存在,但忽略了绝大多数用户访问时带有目的性,即网页和链接与查询主题的相关性。
针对这个问题,HITS算法提出了两个关键的概念:权威型网页(authority)和中心型网页(hub)。
基于链接的抓取的问题是相关页面主题团之间的隧道现象,即很多在抓取路径上偏离主题的网页也指向目标网页,局部评价策略中断了在当前路径上的抓取行为。
文献[21]提出了一种基于反向链接(BackLink)的分层式上下文模型(Context Model),用于描述指向目标网页一定物理跳数半径内的网页拓扑图的中心Layer0为目标网页,将网页依据指向目标网页的物理跳数进行层次划分,从外层网页指向内层网页的链接称为反向链接。
4.1.2 网站粒度的分析算法 网站粒度的资源发现和管理策略也比网页粒度的更简单有效。
网站粒度的爬虫抓取的关键之处在于站点的划分和站点等级(SiteRank)的计算。
SiteRank的计算方法与PageRank类似,但是需要对网站之间的链接作一定程度抽象,并在一定的模型下计算链接的权重。
网站划分情况分为按域名划分和按IP地址划分两种。
文献[18]讨论了在分布式情况下,通过对同一个域名下不同主机、服务器的IP地址进行站点划分,构造站点图,利用类似PageRank的方法评价SiteRank。
同时,根据不同文件在各个站点上的分布情况,构造文档图,结合SiteRank分布式计算得到DocRank。
文献[18]证明,利用分布式的SiteRank计算,不仅大大降低了单机站点的算法代价,而且克服了单独站点对整个网络覆盖率有限的缺点。
附带的一个优点是,常见PageRank 造假难以对SiteRank进行欺骗。
4.1.3 网页块粒度的分析算法 在一个页面中,往往含有多个指向其他页面的链接,这些链接中只有一部分是指向主题相关网页的,或根据网页的链接锚文本表明其具有较高重要性。
但是,在PageRank和HITS算法中,没有对这些链接作区分,因此常常给网页分析带来广告等噪声链接的干扰。
在网页块级别(Blocklevel)进行链接分析的算法的基本思想是通过VIPS网页分割算法将网页分为不同的网页块(page block),然后对这些网页块建立pagetoblock和blocktopage的链接矩阵,分别记为Z和X。
于是,在pagetopage图上的网页块级别的PageRank为Wp=X×Z;在blocktoblock图上的BlockRank为Wb=Z×X。
已经有人实现了块级别的PageRank和HITS算法,并通过实验证明,效率和准确率都比传统的对应算法要好。
4.2 基于网页内容的网页分析算法 基于网页内容的分析算法指的是利用网页内容(文本、数据等资源)特征进行的网页评价。
网页的内容从原来的以超文本为主,发展到后来动态页面(或称为Hidden Web)数据为主,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的400~500倍。
另一方面,多媒体数据、Web Service等各种网络资源形式也日益丰富。
因此,基于网页内容的分析算法也从原来的较为单纯的文本检索方法,发展为涵盖网页数据抽取、机器学习、数据挖掘、语义理解等多种方法的综合应用。
本节根据网页数据形式的不同,将基于网页内容的分析算法,归纳以下三类:第一种针对以文本和超链接为主的无结构或结构很简单的网页;第二种针对从结构化的数据源(如RDBMS)动态生成的页面,其数据不能直接批量访问;第三种针对的数据界于第一和第二类数据之间,具有较好的结构,显示遵循一定模式或风格,且可以直接访问。
4.2.1 基于文本的网页分析算法 1) 纯文本分类与聚类算法 很大程度上借用了文本检索的技术。
文本分析算法可以快速有效的对网页进行分类和聚类,但是由于忽略了网页间和网页内部的结构信息,很少单独使用。
2) 超文本分类和聚类算法 网页文本还具有大量的
学习网络爬虫好找工作吗?
比较好找工作,大数据时代网络爬虫需求量会越来越大,还是需要个人吧技术学精,工作才会更好,薪资更高。而且现在python也是最近很火的语言,希望能帮助你。
什么是网络的拓
网络拓扑是网络形状,或者是它在物理上的连通性。构成网络的拓扑结构有很多种。
网络拓扑结构是指用传输媒体互连各种设备的物理布局,就是用什么方式把网络中的计算机等设备连接起来。
拓扑图给出网络服务器、工作站的网络配置和相互间的连接,它的结构主要有星型结构、环型结构、总线结构、分布式结构、树型结构、网状结构、蜂窝状结构等。
- 网络爬虫是什么什么是网络的拓相关文档
- 网络爬虫是什么搜索引擎和爬虫的区别
桔子数据58元/月 ,Cera美西云服务器 2核4G 50G数据盘 500M带宽 1000G流量
桔子数据(徐州铭联信息科技有限公司)成立于2020年,是国内领先的互联网业务平台服务提供商。公司专注为用户提供低价高性能云计算产品,致力于云计算应用的易用性开发,并引导云计算在国内普及。目前公司研发以及运营云服务基础设施服务平台(IaaS),面向全球客户提供基于云计算的IT解决方案与客户服务,拥有丰富的国内BGP、双线高防、香港等优质的IDC资源。 公司一直秉承”以人为本、客户为尊、永...

hostyun评测香港原生IPVPS
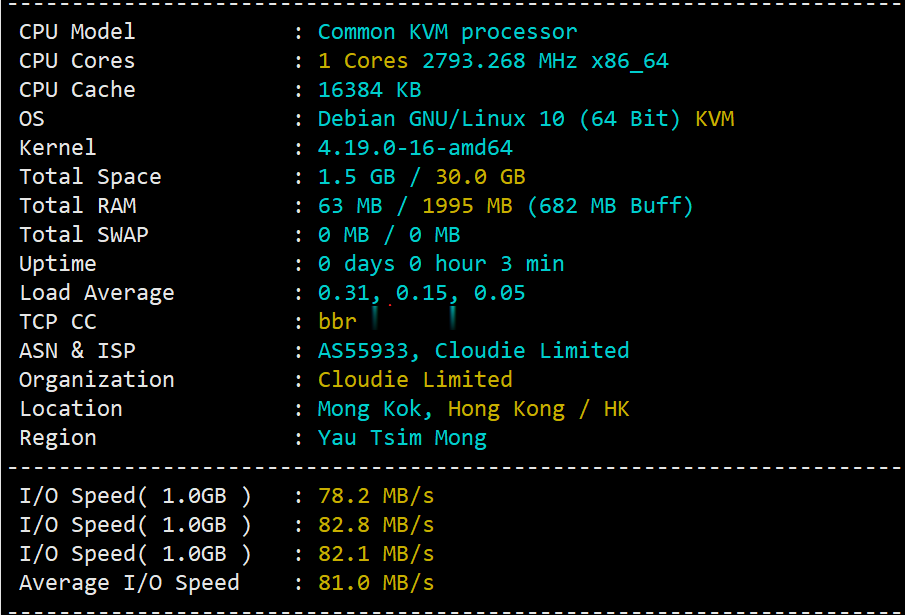
hostyun新上了香港cloudie机房的香港原生IP的VPS,写的是默认接入200Mbps带宽(共享),基于KVM虚拟,纯SSD RAID10,三网直连,混合超售的CN2网络,商家对VPS的I/O有大致100MB/S的限制。由于是原生香港IP,所以这个VPS还是有一定的看头的,这里给大家弄个测评,数据仅供参考!9折优惠码:hostyun,循环优惠内存CPUSSD流量带宽价格购买1G1核10G3...
个人网站备案流程及注意事项(内容方向和适用主机商)
如今我们还有在做个人网站吗?随着自媒体和短视频的发展和兴起,包括我们很多WEB2.0产品的延续,当然也包括个人建站市场的低迷和用户关注的不同,有些个人已经不在做网站。但是,由于我们有些朋友出于网站的爱好或者说是有些项目还是基于PC端网站的,还是有网友抱有信心的,比如我们看到有一些老牌个人网站依旧在运行,且还有新网站的出现。今天在这篇文章中谈谈有网友问关于个人网站备案的问题。这个也是前几天有他在选择...
网络爬虫是什么为你推荐
-
descriptiondescription是什么文体按键精灵教程按键精灵看不懂教程谁能简化教教大概主要步骤搜索引擎有哪些1.什么是搜索引擎?举出几个常用的搜索引擎。短信应用Android手机短信应用都有哪些?b2c网站B2C模式的网站4g上网卡什么是4G无线上网卡burndownburn down与burn up有何区别硬盘分区格式化新硬盘分区格式化有哪些方法?sd卡座sd卡座使用过程中需注意哪些事项海淀区公司注册在北京如何注册公司