符号正则表达式java
第四章语法分析赵建华南京大学计算机系2010.
3程序设计语言构造的描述程序设计语言构造的语法可使用上下文无关文法或BNF表示法来描述文法可给出精确易懂的语法规则可以自动构造出某些类型的文法的语法分析器文法指出了语言的结构,有助于进一步的语义处理/代码生成.
支持语言的演化和迭代.
语法分析器的作用基本作用从词法分析器获得词法单元的序列,确认该序列是否可以由语言的文法生成.
对于语法错误的程序,报告错误信息对于语法正确的程序,生成语法分析树.
通常并不真的生产这棵语法分析树语法分析器的分类通用语法分析器可以对任意文法进行语法分析效率很低,不适合用于编译器自顶向下语法分析器从语法分析树的根部开始构造语法分析树自底向上语法分析器从语法分析树的叶子开始构造语法分析树后两种方法总是从左到右、逐个扫描词法单元.
只能处理特定类型的文法,但是这些文法足以用来描述程序设计语言.
上下文无关文法定义:一个上下文无关文法包含四个部分终结符号:组成串的基本符号(词法单元名字)非终结符号:表示串的集合的语法变量.
给出了语言的层次结构.
在程序设计语言中通常对应于某个程序构造,比如stmt(语句)开始符号:某个被指定的非终结符号.
它对应的串的集合就是文法的语言产生式集合:描述将终结符号和非终结符号组成串的方法产生式的形式:头/左部体/右部头部是一个非终结符号,右部是一个符号串;例子:expressionexpression+term上下文无关文法的例子简单算术表达式的文法:终结符号:id非终结符号:expression,term,factor开始符号:expression产生式集合:expressionexpression+termexpressionexpression–termexpressiontermtermterm*factortermterm/factortermfactorfactor(expression)factorid文法书写的约定终结符号靠前的小写字母(a,b,c);运算符号(+*);标点符号;数位;黑体字符串(id,if,while)非终结符号靠前的大小字母(A,B,C);字母S(通常是开始符号);小写斜体字母;表示程序构造的大写字母X,Y,Z文法符号(终结符号或非终结符号)小写希腊字母表示文法符号串(α,β,γ)靠后的小写字母表示终结符号串具有相同头的产生式可以合并成Aα1|α2|…|αn的形式通常第一个产生式的左部就是开始符号.
文法简单形式的例子EE+T|E–T|TTT*F|T/F|FF(E)|id注意:|是元符号(即文法描述方式中的符号,而不是文法符号)这里(,)不是元符号;在有些地方会把()看作元符号推导(1)推导:将待处理的串中的某个非终结符号替换为这个非终结符号的某个产生式的体.
从开始符号出发,不断进行上面的替换,就可以得到文法的不同句型例子文法:E-E|E+E|E*E|(E)|id推导序列:E=>-E=>-(E)=>-(id)推导(2)推导的正式定义如果Aγ是一个产生式,那么αAβ=>αγβ最左(右)推导:α(β)中不包含非终结符号符号:经过零步或者多步推导出:对于任何串αα如果αβ且β=>γ,那么αγ经过一步或者多步推导出:αβ等价于αβ且α不等于β句型/句子/语言句型(sententialform):如果S=*=>α,那么α就是文法的句型可能既包含非终结符号,又包含终结符号;可以是空串句子(sentence)文法的句子就是不包含非终结符号的句型语言文法G的语言就是G的句子的集合,记为L(G)w在L(G)中当且仅当w是G的句子,即S=*=>w语法分析树推导的图形表示形式根结点的标号时文法的开始符号每个叶子结点的标号是非终结符号、终结符号或ε每个内部节点的标号是非终结符号.
每个内部结点表示某个产生式的一次应用内部结点的标号为产生式头,结点的子结点从左到右是产生式的体有时允许树的根不是开始符号(对应于某个短语).
树的叶子组成的序列是根的文法符号的句型一棵分析树可对应多个推导序列,但是分析树和最左(右)推导序列之间具有一一对应关系语法分析树的例子文法:E-E|E+E|E*E|(E)|id句子:-(id+id)从推导序列构造分析树假设有推导序列:A=a1=>a2=>…=>an算法:初始化:a1的分析树是标号为A的单个结点假设已经构造出ai-1=X1X2…Xk的分析树,且ai-1到a1的推导是将Xj替换为β,那么在当前分析树中找出第j个非ε结点,向这个结点增加构成β的子结点.
如果β=ε,则增加一个标号为ε的子结点)构造分析树的例子推导序列:E=>-E=>-(E)=>-(E+E)=>-(id+E)=>-(id+id)二义性(1)二义性(ambiguous):一个文法可以为某个句子生成多棵语法分析树,这个文法就是二义性的例子:E=>E+E=>id+E=>id+E*E=>id+id*E=>id+id*idE=>E*E=>E+E*E=>id+E*E=>id+id*E=>id+id*id二义性(2)程序设计语言的文法通常都应该是无二义性的否则就会导致一个程序有多种"正确"的解释.
比如文法:E-E|E+E|E*E|(E)|id的句子a+b*c但有些二义性的情况可以方便文法或语法分析器的设计.
但是需要消二义性规则来剔除不要的语法分析树比如:先乘除后加减证明文法生成的语言证明文法G生成语言L可以帮助我们了解文法可以生成什么样的语言.
基本步骤:首先证明L(G)L然后证明LL(G)一般使用数学归纳法证明L(G)L的方法之一:构造L',使得L'Vt*=L;并证明S∈L',且对于L'中的任意α,α=>β可推出β也在L中.
也可以按照推导序列长度进行数学归纳证明LL(G)时,通常可按照符号串的长度来构造推导序列.
文法生成语言的例子(1)文法:S(S)S|ε语言:所有具有对称括号对的串L(G)L的证明:令L'={删除S后括号对称的串},显然有L'Vt*=L且S∈L'任意的删除S后括号对称的串α,不管使用Sε还是(S)S推导出串β,删除β中的S后得到的串仍然是括号对称的.
有上面两点可知:G的所有句型都属于L',且L'中的终结符号串就是L.
可知L(G)L.
文法生成语言的例子(2)LL(G)的证明:注意:括号对称的串的长度必然是偶数.
归纳基础:如果括号对称的串的长度为0,显然它可以从S推导得到归纳步骤:假设长度小于2n的括号对称的串都能够由S推导得到.
假设w是括号对称且长度为2n的串w必然以左括号开头,且w可以写成(x)y的形式,其中x也是括号对称的.
因为x、y的长度都小于2n,根据归纳假设,x和y都可以从S推导得到.
因此S=>(S)S=*=>(x)y.
上下文无关文法和正则表达式(1)上下文无关文法比正则表达式的能力更强.
即:所有的正则语言都可以使用文法描述但是一些用文法描述的语言不能用正则文法描述.
证明:首先SaSb|ab描述了语言{anbn|n>0},但是这个语言无法用DFA识别.
假设有DFA识别此语言,且这个文法有K个状态.
那么在识别ak+1…的输入串时,必然两次到达同一个状态.
设自动机在第i个和第j个a时进入同一个状态,那么:因为DFA识别L,ajbj必然到达接受状态,因此aibj必然也到达接受状态.
直观地讲:有穷自动机不能数(大)数.
上下文无关文法和正则表达式(2)证明(续)其次证明:任何正则语言都可以表示为上下文无关文法的语言.
任何正则语言都必然有一个NFA.
对于任意的NFA构造如下的上下文无关文法对NFA的每个状态i,创建非终结符号Ai.
如果有i在输入a上到达j的转换,增加产生式AiaAj.
如果i在输入ε上到达j,那么增加产生式AiAj.
如果i是一个接受状态,增加产生式Aiε如果i是开始状态,令Ai为所得文法的开始符号.
NFA构造文法的例子A0aA0|bA0|aA1A1bA2A2bA3A3ε考虑baabb的推导和接受过程可知:NFA接受一个句子的运行过程实际是文法推导出该句子的过程.
设计文法文法能够描述程序设计语言的大部分语法但不是全部,比如:标识符的先声明后使用无法用上下文无关文法描述.
因此:语法分析器接受的语言是程序设计语言的超集.
必须通过语义分析来剔除一些符合文法、但不合法的程序.
二义性的消除(1)一些二义性文法可以被改成等价的无二义性的文法例子:stmtifexprthenstmt|ifexprthenstmtelsestmt|otherifE1thenifE2thenS1elseS2的两棵语法树二义性的消除(2)为了保证"else和最近未匹配的then匹配",我们要求在then分支的语句必须是匹配好的.
引入matched_stmt表示匹配好的语句,有如下文法:stmtmatched_stmt|open_stmtmatched_stmtifexprthenmatched_stmtelsematched_stmt|otheropen_stmtifexprthenstmt|ifexprthenmatched_stmtelseopen_stmt二义性的消除方法没有规律可循.
通常并不是通过改变文法来消除二义性.
左递归的消除左递归的定义:如果一个文法中有非终结符号A使得A=*=>Aα,那么这个文法就是左递归的.
立即左递归(规则左递归)文法中存在一个形如AAα的产生式.
自顶向下的语法分析技术不能处理左递归的情况,因此需要消除左递归;但是自底向上的技术可以处理左递归.
立即左递归的消除假设非终结符号A存在立即左递归的情形,假设以A为左部的规则有:AAα1|Aα2|…|Aαm|β1|β2|…|βn可以替换为Aβ1A'|β2A'|…|βnA'A'α1A'|α2A'|…|αmA'|ε由A生成的串总是以某个βi开头,然后跟上零个或者多个αi的重复.
通用的左递归消除方法输入:没有环和ε产生式的文法G输出:等价的无左递归的文法步骤:将文法的非终结符号任意排序为A1,A2,…,Anfori=1tondo{forj=1toi-1do{将形如AiAjγ的产生式替换为Aiδ1γ|δ2γ|…|δnγ,其中Ajδ1|δ2|…|δm}是以Aj为左部的所有产生式;}消除Ai的立即左递归;}内层循环的每一次迭代保证了Ai的产生式的右部首符号都比Aj更加靠后.
当内层循环结束时,Ai的产生式的右部首符号不先于Ai.
消除立即左递归就保证了Ai的产生式的右部首符号必然比Ai后.
(不能有环和ε产生式)当外层循环结束时,所有的产生式都是如此.
使用这些产生式当然不会产生左递归的情形.
通用左递归消除的例子SAa|bAAc|Sd|ε步骤1:排列为S,Ai=1时:内层循环不运行,S没有立即左递归;i=2时:j=1,处理规则ASd;替换得到AAc|Aad|bd|ε消除A的立即左递归SAa|bAbdA'|A'A'cA'|adA'|ε通用左递归消除的问题在于很难找到新文法和旧文法的推导之间的对应关系,因此很难依据新文法进行语义处理.
本例子中的ε产生式恰好没有影响算法的正确性预测分析法简介试图从开始符号推导出输入符号串;以开始符号作为初始的当前句型每次为最左边的非终结符号选择适当的产生式;通过查看下一个输入符号来选择这个产生式.
有多个可能的产生式时预测分析法无能为力比如文法:E+EE|-EE|id;输入为+id-idid当两个产生式具有相同的前缀时无法预测文法:stmtifexprthenstmtelsestmt|ifexprthenstmt输入:ifathen…新文法:stmtifexprthenstmtelsePartelsePartelsestmt|ε需要提取公因子提取公因子的文法变换算法:输入:文法G输出:等价的提取了左公因子的文法方法:对于每个非终结符号A,找出它的两个或者多个可选产生式体之间的最长公共前缀.
Aαβ1|αβ2|…|αβn|γAαA'|γA'β1|β2|…|βn其中γ是不以α开头的产生式体提取公因子的例子文法:SiEtS|iEtSeS|aEb对于S而言,最长的前缀是iEtS,因此:SiEtSS'|aS'eS|εEb非上下文无关语言的构造抽象语言L1={wcw|w在(a|b)*中}这个语言不是上下文无关的语言它抽象地表示了C或者Java中"标识符先声明后使用"的规则.
说明了这些语言不是上下文无关语言,不能使用上下文无关文法描述.
通常用上下文无关文法描述其基本结构,不能用文法描述的特性在语义分析阶段完成.
原因是上下文文法具有高效的处理算法.
自顶向下的语法分析为输入串构造语法分析树从分析树的根结点开始,按照先根次序,深度优先地创建各个结点对应于最左推导.
基本步骤确定对句型中最左边的非终结符号应用哪个产生式然后对句型中的非终结符号和输入符号进行匹配关键问题是:确定对最左边的非终结符号应用哪个产生式自顶向下分析的例子文法:ETE'E'+TE'|εTFT'T'*FT'|εF(E)|id输入id+id*id分析树序列见右面(图4-12)递归下降的语法分析递归下降语法分析程序由一组过程组成每个非终结符号对应于一个过程,该过程负责扫描非终结符号对应的结构程序执行从开始符号对应的过程开始当扫描整个输入串时宣布分析成功完成递归下降分析技术的回溯如果没有足够的信息来唯一地确定可能的产生式,那么分析过程就产生回溯.
前面的算法报告错误(第7行)并不意味着输入串不是句子,而可能是表示前面选错了产生式.
第一行上保存当前的扫描指针在第七行上应该改成回退到保存的指针;GOTO(1)并选择下一个产生式;如果没有下一个产生式可选,报告错误.
回溯需要来回扫描,低效如果嵌入了语义处理,则需要撤销已经完成的语义处理动作.
解决方法:设法通过一些信息确定唯一可能的产生式递归下降分析中回溯的例子文法:ScAdAab|a输入串:cad步骤:调用函数S;S选择唯一产生式ScAd输入中的c和句型中的c匹配,继续调用AA首先选择产生式Aab,a和输入的a匹配,b和输入的d不匹配;回溯并选择下一个产生式Aa;a和输入的a相匹配;对A的调用返回;到S的调用;ScAd中的d和下一个输入匹配;对S的调用返回,已经读入所有输入符号;因此扫描结束,cad是句子.
FIRST和FOLLOW(1)在自顶向下的分析技术中,通常使用向前看几个符号来唯一地确定产生式(这里假定只看一个符号)当前句型是xAβ,而输入是xa….
那么选择产生式Aα的必要条件是下列之一:α=*=>ε,且β以a开头;也就是说在某个句型中a跟在A之后;α=*=>a…;如果按照这两个条件选择时能够保证唯一性,那么我们就可以避免回溯.
因此,我们定义FIRST和FOLLOWFIRST和FOLLOW(2)FIRST(α):可以从α推导得到的串的首符号的集合;如果α=*=>ε,那么ε也在FIRST(α)中;FOLLOW(A):可能在某些句型中紧跟在A右边的终结符号的集合.
FIRST的计算方法计算FIRST(X)的方法如果X是终结符号,那么FIRS(X)=X如果X是非终结符号,且XY1Y2…Yk是产生式,如果a在FIRST(Yi)中,且ε在FIRST(Y1),FIRST(Y2),…,FIRST(Yi-1)中,那么a也在FIRST(X)中.
如果ε在FIRST(Y1),FIRST(Y2),…,FIRST(Yk)中,那么ε在FIRST(X)中.
如果X是非终结符号,且Xε是一个产生式,那么ε在FIRST(X)中计算FIRST(X1X2…Xn)的方法向集合中加入FIRST(X1)中所有非ε的符号;如果ε在FIRST(X1)中,再加入FIRST(X2)中的所有非ε的符号;…如果ε在所有的FIRST(X1)中,将ε加入FIRST(X1X2…Xn)中.
FOLLOW的计算方法算法将右端结束标记$放到FOLLOW(S)中按照下面的两个规则不断迭代,直到所有的FOLLOW集合都不再增长为止.
如果存在产生式AαBβ,那么FIRST(β)中所有非ε的符号都在FOLLOW(B)中.
如果存在一个产生式AαB,或者AαBβ且FIRST(β)包含ε,那么FOLLOW(A)中的所有符号都加入到FOLLOW(B)中.
请注意各个步骤中将符号加入到FOLLOW集合中的理由.
FIRST/FOLLOW的例子(1)文法:ETE'E'+TE'|εTFT'T'*FT'|εF(E)|idFIRST集合FIRST(F)={(,id};FIRST(E)=FIRST(T)={(,id}FIRST(E'ε};FIRST(T')={*,ε}由此可以推出各个产生式右部的FIRST集合.
FIRST/FOLLOW的例子(2)FOLLOW集合的计算过程$在FOLLOW(E)中(E是开始符号)由规则F(E)可知,)也在FOLLOW(E)中由规则ETE'可知FOLLOW(E')也包含了$和).
注意:因为E'只出现在E和E'的产生式的尾部,因此FOLLOW(E')必然等于FOLLOW(E).
由规则E'+TE',FIRST(E')中的+在FOLLOW(T)中;且FIRST(E')包含ε,因此FOLLOW(E')中的$和)也在FOLLOW(T)中.
因为T'只出现在T'和T的产生式的末尾,可以FOLLOW(T')=FOLLOW(T);由规则TFT'且T'可以推导出ε,因此可知FOLLOW(F)包含FOLLOW(T);同时FIRST(T')也在FOLLOW(F)中.
因此E:{$,)}E':{$,)}T,T'F:LL(1)文法(1)定义:对于文法的任意两个不同的产生式Aα|β不存在终结符号a使得α和β都可以推导出以a开头的串α和β最多只有一个可以推导出空串如果β可以推导出空串,那么α不能推导出以FOLLOW中任何终结符号开头的串;等价于:FIRST(α)FIRST(β)=Φ;(条件一、二)如果ε∈FIRST(β),那么FIRST(α)FOLLOW(A)=Φ;反之亦然.
(条件三)考虑:对于一个LL(1)文法,我们期望从A推导出以终结符号a开头的符号串,我们如何选择产生式有多个选择吗LL(1)文法(2)对于LL(1)文法,可以在自顶向下分析过程中,根据当前输入符号来确定使用的产生式.
例如:产生式:stmtif(exp)stmtelsestmt|while(exp)stmt|a输入:if(exp)while(exp)aelsea首先选择产生式stmtif(exp)stmtelsestmt得到句型if(exp)stmtelsestmt然后发现要把句型中的第一个stmt展开,选择产生式stmtwhile(exp)stmt,得到句型if(exp)while(exp)stmtelsestmt.
然后再展开第一个stmt,得到if(exp)while(exp)aelsestmt…预测分析表构造算法输入:文法G输出:预测分析表M方法:对于文法G的每个产生式Aα对于FIRST(α)中的每个终结符号a,将Aα加入到M[A,a]中;如果ε在FIRST(α),那么对于FOLLOW(A)中的每个符号b,将将Aα加入到M[A,b]中.
最后在所有的空白条目中填入error.
预测分析表的例子文法:ETE'E'+TE'|εTFT'T'*FT'|εF(E)|idFIRST集:F:{(,id};E,T:{(,id};E':{+,ε};T':{*,ε}FOLLOW集:E:{$,)}E':{$,)}T,T'F:这个例子恰巧使得每个产生式的右部的第一个符号的FIRST集合就等于产生式右部的FIRST集合.
但是在一般情况下不总是这样的.
预测分析表冲突的例子文法:SiEtSS'|aS'eS|εEbFIRST(eS)={e},使得S'eS在M[S',e]中;FOLLOW(S')={$,e}使得S'ε也在M[S',e]中注意:LL(1)文法必然不是二义性的;而这个文法是二义性的LL(1)文法的递归下降分析递归下降语法分析程序由一组过程组成每个非终结符号对应于一个过程,该过程负责扫描非终结符号对应的结构可以使用当前的输入符号来唯一地选择产生式如果当前输入符号为a,那么选择M[A,a]中的产生式非递归的预测分析(1)在自顶向下分析的过程中,我们总是匹配掉句型中左边的所有终结符号;对于最左边的非终结符号,我们选择适当的产生式展开.
匹配成功的终结符号不会再被考虑,因此我们只需要记住句型的余下部分,以及尚未匹配的输入终结符号串.
由于展开的动作总是发生在余下部分的左端,我们可以用栈来存放这些符号.
非递归的预测分析(2)分析时的处理过程:初始化时,栈中仅包含开始符号;如果栈顶元素是终结符号,那么进行匹配如果栈顶元素是非终结符号使用预测分析表来选择适当的产生式;在栈顶用产生式右部替换产生式左部;因此对所有文法的预测分析都可以共用同样的驱动程序.
分析表驱动的预测分析器性质1:如果栈中的符号序列为α,而w是已经被读入的部分输入,w'是尚未处理的输入;那么S推导出wα我们试图从α推导出余下的输入终结符号串w'预测分析程序使用M[X,a]来扩展X,将此产生式的右部按倒序压入栈中请注意:这样的操作使得分析过程中性质1得到保持.
预测分析算法输入:串w,预测分析表M输出:如果w是句子,输出w的最左推导;否则报错方法:初始化:输入缓冲区中为w$;栈中包含S$;ip指向w的第一个符号;令X=栈顶符号,ip指向符号aif(X==a)出栈,ip向前移动;/*和终结符号的匹配*/elseif(X是终结符号)error();/*失配*/elseif(M[X,a]是报错条目)error();/*无适当的产生式*/elseif(M[X,a]=XY1Y2…Yk){输出产生式XY1Y2…Yk;弹出栈顶符号X;将Yk,Yk-1,…,Y1压入栈中;}不断执行第二步;直到要么报错,要么栈中为空分析表驱动预测分析的例子文法4.
28,输入:id+id*id;注意:已经匹配部分加上栈中符号必然是一个最左句型预测分析中的错误恢复错误恢复当预测分析器报错时,表示输入的串不是句子.
对于使用者而言,希望预测分析器能够进行恢复,并继续语法分析过程,以便在一次分析中找到更多的语法错误.
有可能恢复得并不成功,之后找到的语法错误有可能是假的.
进行错误恢复时可用的信息:栈里面的符号,待分析的符号两类错误恢复方法:恐慌模式短语层次的恢复恐慌模式基本思想语法分析器忽略输入中的一些符号,直到出现由设计者选定的某个同步词法单元;解释:语法分析过程总是试图在输入的前缀中找到和某个非终结符号对应的串;出现错误表明现在已经不可能找到这个非终结符号(程序结构)的串.
如果编程错误仅仅局限于这个程序结构,那么我们可以考虑跳过这个程序结构,假装已经找到了这个结构;然后继续进行语法分析处理.
同步词法单元就是这个程序结构结束的标志.
同步词法单元的确定非终结符号A的同步集合的启发式规则FOLLOW(A)的所有非终结符号A的同步集合中这些符号的出现可能表示之前的那些符号是错误的A的串;将高层次的非终结符号对应串的开始符号加入到较低层次的非终结符号的同步集合比如语句的开始符号,if,while等可以作为表达式的同步集合;FIRST(A)中的符号加入到非终结符号A的同步集合.
碰到这些符号时,可能意味着前面的符号是多余的符号如果A可以推导出空串,那么把此产生式当作默认值.
在匹配时出现错误,可以直接弹出相应的符号;哪些符号需要确定同步集合需要根据特定的应用而定.
恐慌模式的例子(1)对文法4.
28的表达式进行语法分析时,可以直接使用FIRST、FOLLOW作为同步集合.
我们为E、T和F设定同步集合;空条目表示忽略输入符号;synch条目表示忽略到同步集合,然后弹出非终结符号;终结符号不匹配时,弹出栈中终结符号;恐慌模式的例子(2)错误输入:id*+id短语层次的恢复在预测语法分析表的空白条目中插入错误处理例程的函数指针;例程可以改变、插入或删除输入中的符号;发出适当的错误消息;自底向上的语法分析为一个输入串构造语法分析树的过程;从叶子(输入串中的终结符号,将位于分析树的底端)开始,向上到达根结点;在实际的语法分析过程中并不会真的构造出相应的分析树,但是分析树概念可以方便理解;重要的自底向上语法分析的通用框架移入-归约;LR:最大的可以构造出移入-归约语法分析器的语法类分析过程示例归约自底向上语法分析过程看成从串w"归约"为文法开始符号的过程;归约步骤:一个与某产生式体相匹配的特定子串被替换为该产生式头部的非终结符号;问题:何时归约(归约哪些符号串)归约到哪个非终结符号归约的例子id*id的归约过程id*id,F*id,F*id,T*F,T,E对于句型T*id,有两个子串和某产生式右部匹配T是ET的右部;id是Fid的右部;为什么选择将id归约为F,而不是将T归约为E原因:T归约为E之后,E*id不再是句型;问题:如何确定这一点句柄剪枝对输入从左到右扫描,并进行自底向上语法分析,实际上可以反向构造出一个最右推导;句柄:最右句型中和某个产生式体匹配的子串,对它的归约代表了该最右句型的最右推导的最后一步;正式定义:如果SαAwαβw;那么紧跟α之后的Aβ的一个句柄;在一个最右句型中,句柄右边只有终结符号如果文法是无二义性的,那么每个句型都有且只有一个句柄.
句柄的例子输入:id*id移入-归约分析技术使用一个栈来保存归约/扫描移入的文法符号;栈中符号(从底向上)和待扫描的符号组成了一个最右句型;开始时刻:栈中只包含$,而输入为w$;成功结束时刻:栈中$S,而输入$;在分析过程中,不断地移入符号,并在识别到句型时进行归约;句柄被识别时总是出现在栈的顶部;主要分析动作移入:将下一个输入符号移动到栈顶;归约:将句柄归约为相应的非终结符号;句柄总是在栈顶.
具体操作时弹出句柄,压入被归约到的非终结符号.
接受:宣布分析过程成功完成;报错:发现语法错误,调用错误恢复子程序;归约分析过程的例子为什么句柄总是在栈顶(1)为什么每次归约得到的新句型的句柄仍不在栈顶考虑最右推导的两个连续步骤的两种情况A被替换为βBy,然后产生式体中的最右非终结符号B被替换为γ.
(归约之后句柄为βBy)A首先被展开,产生式体中只包含终结符号;下一个最右非终结符号B位于y左侧.
y是终结符号串移入-归约分析中的冲突对于有些不能使用移入-归约分析的文法,不管用什么样的移入-归约分析器都会到达这样的格局即使知道了栈中所有内容、以及下面k个输入符号,人们仍然无法知道是否该进行归约,或者不知道按照什么产生式进行归约;形式化地表达:设栈中符号串是αβ,接下来的k个符号是x,产生移动/归约冲突的原因是存在y和y'使得aβxy是最右句型且β是句柄,而aβxy'也是最右句型,但是句柄还在右边.
归约/归约冲突的例子输入为id(id,id)冲突时的格局:栈:…id(id输入:,id)…某个语言中,多维数组的表示方法.
LR语法分析技术LR(k)的语法分析概念L表示最左扫描,R表示反向构造出最右推导;k表示最多向前看k个符号;当k的数量增大时,相应的语法分析器的规模急剧增大;K=2时,程序设计语言的语法分析器的规模通常非常庞大;当k=0、1时已经可以解决很多语法分析问题,因此具有实践意义.
因此,我们只考虑kαβ1β2w,那么我们说项Aβ1.
β2么对αβ1有效.
SLR的原理:可行前缀(2)如果我们知道Aβ1.
β2对αβ1有效,当β2不等于空,表示句柄尚未出现在栈中,应该移入或者等待归约;如果β2等于空,表示句柄出现在栈中,应该归约.
如果某个时刻存在两个有效项要求执行不同的动作,那么就应该设法解决冲突.
冲突实际上表示可行前缀可能是两个最右句型的前缀,第一个包含了句柄,而另一个尚未包含句型E+T+idE+T*idSLR解决冲突的思想:假如要按照Aβ进行归约,那么得到的新句型中A后面跟随下一个输入符号.
因此只有当下一个输入在FOLLOW(A)中时才可以归约.
也可能都认为包含句柄,但是规则不一样SLR的原理:可行前缀(3)如果在文法G的LR(0)自动机中,从初始状态出发,沿着标号为γ的路径到达一个状态,那么这个状态对应的项集就是γ的有效项集.
回顾确定分析动作的方法,就可以知道我们实际上是按照有效项来确定的.
为了避免冲突,归约时要求下一个输入符号在FOLLOW(A)中.
活前缀/有效项的例子可行前缀E+T*对应的LR(0)项TT*.
FF.
(E)F.
id对应的最右推导E'EE+TE+T*FE'EE+TE+T*FE+T*(E)E'EE+TE+T*FE+T*idSLR语法分析器的弱点(1)SLR技术解决冲突的方法:项集中包含[Aα.
]时,按照Aα进行归约的条件是下一个输入符号a可以在某个句型中跟在A之后.
如果对于a还有其它的移入/归约操作,则出现冲突.
假设此时栈中的符号串为βα,如果βAa不可能是某个最右句型的前缀,那么即使a在某个句型中跟在A之后,仍然不应该按照Aα归约.
进行归约的条件更加严格可以降低冲突的可能性SLR语法分析器的弱点(2)[Aα.
]出现在项集中的条件:首先[A.
α]出现在某个项集中,然后逐步读入/归约到α中的符号,点不断后移,到达末端.
而[A.
α]出现的条件是Bβ.
Aγ出现在项中期望首先按照Aα归约,然后将Bβ.
Aγ中的点后移到A之后.
显然,在按照Aα归约时要求下一个输入符号是γ的第一个符号.
但是从LR(0)项集中不能确定这个信息.
更强大的LR语法分析器规范LR方法(或直接称LR方法)添加项[A.
α]时,把期望的向前看符号也加入项中.
这个做法可以充分利用向前看符号,但是状态很多.
向前看LR(LALR方法)基于LR(0)项集族.
但是每个LR(0)项都带有向前看符号.
分析能力强于SLR方法,且分析表和SLR分析表一样大.
LALR已经可以处理大部分的程序设计语言.
LR(1)项LR(1)项中包含更多信息来消除一些归约动作.
实际的做法相当于"分裂"一些LR(0)状态,精确地指明何时应该归约.
LR(1)项的形式[Aα.
β,a]a称为向前看符号,可以是终结符号或者$a表示如果将来要按照Aαβ进行归约,归约时的下一个输入符号必须是a.
当β非空时,移入动作不考虑a,a传递到下一状态.
LR(1)项和可行前缀[Aα.
β,a]对于一个可行前缀γ有效的条件是存在一个推导SδAwδαβw,其中γ=δα,且a是w的第一个符号,或者w为空且a=$.
如果[Aα.
Bβ,a]对于可行前缀γ有效,那么[B.
θ,b]对于γ有效的条件是什么SδAwδαBβwδαBxwδαθxw显然:b应该是xw的第一个符号,或xw为空且b=$.
如果x为空,则b=a.
如果[Aα.
Xβ,a]对于可行前缀γ有效,[AαX.
β,a]对γX有效.
可行前缀和LR(1)有效项的例子文法:SBBBaB|b最右推导:SaaBabaaaBab.
对应于前面的定义:δ=aa,A=Bw=ab,α=aβ=Bγ=δα=aaa因此:[Ba.
B,a]对于aaa是有效的;构造LR(1)项集项集族的构造和LR(0)项集族的构造类似,但是CLOSURE和GOTO有所不同:在CLOSURE中,当由项[Aα.
Bβ,a]生成新项[B.
θ,b]时,b必须在FIRST(βa)中.
注意:对应LR(1)项集族中的任意项[Aα.
Bβ,a],总是保证a在FOLLOW(A)中初始项集满足这个条件每次求CLOSURE项集时,新产生的项也满足这个条件.
LR(1)项集的CLOSURE算法注意添加[B.
γ,b]时,b的取值范围.
即点后面跟着终结符号的项LR(1)项集的GOTO算法和LR(0)项集的GOTO算法基本相同即点后面跟文法符号X的项LR(1)项集族的主构造算法和LR(0)项集族的构造算法相同LR(1)项集族的例子增广文法S'SSCCCcC|dI0=CLOSURE{[S'.
S,$]}[S'.
S,$],[S.
CC,$],[C.
cC,c/d],[C.
d,c/d]GOTO(I0,S)={[S'S.
,$]}GOTO(I0,C)=CLOSURE{[SC.
C,$]}={[SC.
C,$],[C.
cC,$],[C.
d,$]}GOTO(I0,c)={[Cc.
C,c/d],[C.
cC,c/d],[C.
d,c/d]}GOTO(I0,d)={[Cd.
,c/d]}如果它是当前状态,下一个输入符号必须是c或者d才可以归约…LR(1)项集的GOTO图不计向前看符号,I3,I6相同I8,I9相同I4,I7相同如果构造LR(0)项集族,只有6个项集.
LR语法分析表的构造步骤:构造得到LR(1)项集族C'={I0,I1,…,In}.
状态i对应于项集Ii.
其分析动作如下:[Aα.
aβ,b]在项集中,且GOTO(Ii,a)=Ij,那么ACTION[i,a]="移入j"[Aα.
,a]在项集中,ACTION[i,a]="按照Aα归约"[S'S.
,$]在项集中,ACTION[i,$]="接受".
GOTO表:GOTO[i,A]=j,如果GOTO(Ii,A)=Ij.
没有填写的条目为报错.
如果条目有冲突,则不是LR(1)的.
初始状态对应于[S'S.
,$]所在的项集.
移入时不考虑向前看符号LR(1)语法分析表的例子(3,6),(4,7),(8,9)分别可以看作是由原来的一个LR(0)状态拆分而来的.
文法:S'SSCCCcC|d构造LALR语法分析表LR(1)语法分析表的状态数量很大SLR(1)语法分析表的分析能力较弱LALR(1)是实践中常用的方法状态数量和SLR(1)的状态数量相同能够方便地处理大部分常见的程序设计语言的构造LR(1)语法分析表的合并状态4和7仅在向前看符号上有所不同.
[Cd.
c/d]vs[Cd.
,$]状态4:下一个符号如果为c或d则归约;为$在报错.
状态7:分析动作正好反过来.
如果我们将4和7中的项合并得47,那么在所有情况都归约新的语法分析过程会在原来报错时进行归约;但是最终总会报错.
对与这个文法,合并4和7不会引起任何冲突,但是有些文法会有冲突.
对任意文法,如果SLR(1)分析表无冲突,合并后的分析表也无冲突.
文法:S'SSCCCcC|dLALR分析技术的基本思想寻找具有相同核心的LR(1)项集,并把它们合并成为一个项集项集的核心就是项的第一分量的集合;I4和I7的核心都是{[Cd.
]},I3和I6的核心{Cc.
CC.
cCC.
d}一个LR(1)项集的核心是一个LR(0)项集;GOTO(I,X)的核心只由I的核心决定,因此被合并项集的GOTO目标也可以合并.
这表示合并之后,我们仍然可以建立GOTO关系.
合并引起的冲突原来无冲突的LR(1)分析表在合并之后得到LALR(1)分析表;新的表中可能存在冲突.
合并不会导致移入/归约冲突假设合并之后在a上存在移入/归约冲突,即存在项[Bβ.
aγ,]和[Aα.
,a].
因为被合并的项集具有相同的核心,因此被合并的所有项集中都包括[Bβ.
aγ,].
而[Aα.
,a]必然在某个项集中.
这个项集必然已经存在冲突!
合并会引起归约/归约冲突,即不能确定按照哪个产生式进行归约.
合并引起归约/归约冲突的例子文法:S'SSaAd|bBd|aBe|bAeAcBc语言{acd,ace,bcd,bce}可行前缀ac的有效项集{[Ac.
,d],[Bc.
,e]}可行前缀bc的有效项集{[Ac.
,e],[Bc.
,d]}合并之后的项集为{[Ac.
,d/e],[Bc.
,d/e]}.
这个项集包含了归约/归约冲突.
应该把c归约成为A还是B基本的LALR分析表构造算法步骤:构造得到LR(1)项集族C={I0,I1,…,In}.
对于LR(1)中的每个核心,找出所有具有这个核心的项集,并把这些项集替换为它们的并集令C'={J0,J1,…,Jn}为得到的LR(1)项集族按照LR分析表的构造方法得到ACTION表.
(如果存在冲突,则这个文法不是LALR的)GOTO表的构造:设J是一个或者多个LR(1)项集(包括I1)的并集,令K是所有和GOTO(I1,X)具有相同核心的项集的并集,那么GOTO(J,X)=K.
得到的分析表称为LALR语法分析表.
LALR分析表的例子(1)文法:S'SSCCCcC|d文法的LR(1)项集族中有三对可以合并的项集:I3和I6(I36):[Cc.
C,c/d/$][C.
cC,c/d/$][C.
d,c/d/$]I4和I7(I47):Cd.
,c/d/$I8和I9(I89):CcC.
,c/d/$GOTO(I36,C)就是原来的GOTO(I3,C)(即I8)所在的并集I89.
…LALR分析表的例子(2)合并后得到的LALR分析表LALR分析表的例子(3)处理语法正确的输入时,LALR语法分析器和LR语法分析器的动作序列完全相同.
栈中的状态名字不同,但是状态序列之间有对应关系:如果LR分析器压入状态I,那么LALR分析器压入I对应的合并项集.
比如:当前面的LR分析器压入状态I3时,LALR分析器压入状态I36.
当处理错误的输入时,LALR可能多执行一些归约动作,但是不会多移入一个符号.
LALR分析表的高效构造算法LALR的项集可以看作是在LR(0)项集上添加了适当的向前看符号.
基本方法只使用内核项来表示LR(0)或LR(1)项集.
只使用[S'.
S]或[S'.
S,$],以及点不在最左端的项.
使用传播和自发生成的过程来生成向前看符号,得到LALR(1)内核项.
使用CLOSURE函数,求出内核的闭包.
然后得到LALR分析表.
LALR项中的向前看符号LALR项集中的项[Aα.
β,a]必然是具有相同核心的LR项集中的一个项.
LALR项集J中包含项[Bγ.
δ,b]的条件:存在相应的LR项集J'使得下列条件之一成立LR项集I'中包含项[Aα.
β,a]且J'=GOTO(I',X),且[Bγ.
δ,b]在GOTO(CLOSURE({[Aα.
β,a]}),X)中.
b是"自发生成的",不管a是什么,[Bγ.
δ,b]一定在J中.
LR项集I'中包含项[Aα.
β,b]且J'=GOTO(I',X),且[Bγ.
δ,b]在GOTO(CLOSURE({[Aα.
β,b]}),X)中.
b是从前一个状态传播过来的,即[Aα.
β,b]在I'中则[Bγ.
δ,b]在J中;若[Aα.
β,c]在I'中则[Bγ.
δ,b]在J中.
存在LR项集I'包含某个项,也就是存在LALR项集I包含该项传播关系只取决于项的核心部分,和具体的向前看符号无关要么传播所有的向前看符号,要么都不传播.
确定自发生成/传播关系基本思想:引入一个特殊向前看符号#作为"指示剂",察看这个符号可以如何传播.
令[Aα.
β]为项集I中的一个项,对每个文法符号X计算J=GOTO(CLOSURE({[Aα.
β,#]}),X).
检查J中的每个内核项,检查它的向前看符号集合.
如果项[Bγ.
δ,#]在J中就表示#从I中的Aα.
β传播到了[Bγ.
δ,#].
其它的向前看符号都是自发生成的.
确定向前看符号的算法输入:LR(0)项集I的内核K以及一个文法符号输出:向前看符号的传播/自发生成.
LALR项集族中向前看符号的计算基本思想:以LR(0)项集为基础;自发生成的符号首先被加入到相应的LALR项集中;然后不停地传播向前看符号,直到收敛.
具体算法构造G的LR(0)项集族的内核将确定自发生成/传播关系的算法应用于每个LR(0)项集的内核和每个文法符号X,确定自发生成和传播的向前看符号.
初始化:给出每个项集和每个内核项的自发生成的向前看符号;迭代:不断扫描所有项集的内核项,将项I的向前看符号加入到传播目标项的向前看符号集合中.
直到各个向前看符号集合不变为止.
构造LALR项集的例子(1)文法:S'SSL=RSRL*RLidRLLR(0)项集内核:构造LALR项集的例子(2)对于I0的内核,CLOSURE({[S'S,#]}):S'.
S,#S.
L=R,#S.
R,#L.
*R,#/=Lid,#/=RL,#对各文法符号计算GOTO,可知I0中的S'.
S将向前看符号传播到I1:S'S.
I2:SL.
=RI3:SR.
I4:L*.
RI5:Lid.
I2:RL.
构造LALR项集的例子(3)得到的传播关系:构造LALR项集的例子(4)计算向前看符号传播的迭代过程:二义性文法的使用二义性文法都不是LR的.
某些二义性文法是有用的可以简洁地描述某些结构;隔离某些语法结构,对其进行特殊处理.
对于某些二义性文法可以通过消除二义性规则来保证每个句子只有一棵语法分析树.
且可以在LR分析器中实现这个规则.
优先级/结合性消除冲突二义性文法:EE+E|E*E|(E)|id等价于:EE+T|TTT*F|FF(E)|id二义性文法的优点:容易修改算符的优先级和结合性.
简洁:如果有多个优先级,那么无二义性文法讲引入太多的非终结符号高效:不需要处理ET这样的归约.
二义性表达式文法的LR(0)项集EE+E|E*E|(E)|idI7、I8中有冲突,且不可能通过向前看符号解决!
冲突的原因以及解决当栈顶状态为7时,表明栈中状态序列对应的文法符号序列为…E+E;下一个输入符号不等于+、*,则归约归约之后早晚会报错;如果下一个符号为+或*,移入还是归约…E+E*(…E+E+)时,是否先求和如果*的优先级大于+,且+是左结合的下一个符号为+时,我们应该将E+E归约为E下一个符号为*时,我们应该移入*,期待引入下一个符号.
解决冲突之后的SLR(1)分析表对于状态7,+时归约*时移入对于状态8执行归约这个表和等价的无二义性文法的分析表类似悬空else的二义性文法:S'SSiSeS|iS|aLR(0)项集中I4包含冲突,它出现在栈顶时,栈中符号为iS如果下一个符号为e,因栈中的i尚未匹配,因此应该移入e.
否则,如果下一个符号属于FOLLOW(S),就归约.
LR语法分析中的错误恢复(1)LR语法分析器查询GOTO表时不会有语法错误.
查询ACTION表时可能发现报错条目假设栈中的符号串为α,当前输入符号为a;报错表示不可能存在终结符号串x使得αax是一个最右句型.
恐慌模式的错误恢复策略从栈顶向下扫描,找到状态s,s有一个对应于非终结符号A的GOTO目标;(s之上的状态被丢弃)在输入中读入并丢弃一些符号,直到找到一个可以合法跟在A之后的符号a(不丢弃a);将GOTO(s,A)压栈;继续进行正常的语法分析.
基本思想:假定当前正在试图归约到A且碰到了语法错误.
因此设法扫描完包含语法错误的A的子串,假装找到了A的一个实例.
LR语法分析中的错误恢复(2)短语层次的恢复检查LR分析表中的每个报错条目,根据语言的特性来确定程序员最可能犯了什么错误,然后构造适当的恢复程序.
语法分析器生成工具YACCYACC的使用方法如下:YACC源程序的结构声明分为两节:第一节放置C声明,第二节是对词法单元的声明.
翻译规则:指明产生式及相关的语义动作辅助性C语言例程被直接拷贝到生成的C语言源程序中,可以在语义动作中调用.
其中必须包括yylex().
这个函数返回词法单元,可以由LEX生成声明%%翻译规则%%辅助性C语言程序翻译规则的格式:1{1}|2{2}产生式体>n{n};第一个产生式的头被看作开始符号;语义动作是C语句序列;$$表示和产生式头相关的属性值,$i表示产生式体中第i个文法符号(注意,保护终结符号)的属性值.
在按照某个产生式归约时,执行相应的语义动作.
通常根据$i来计算$$的值.
在YACC源程序中,可以通过定义YYSTYPE来定义$$,$i的类型.
YACC源程序的例子YACC中的冲突处理缺省的处理方法对于归约/归约冲突,选择列在前面的产生式对于归约/移入冲突,总是移入(悬空-else的解决)运行选项-v可以在文件y.
output中描述冲突及其解决方法;可以通过一些命令来确定终结符号的优先级/结合性,解决移入/归约冲突.
结合性:%left%right%nonassoc产生式的优先级它的最右终结符号的优先级.
或者加标记%prec,指明产生式的优先级移入符号a/按照Aα归约:比较a和Aα的优先级,根据结合性,选择不同的操作.
YACC的错误恢复使用错误产生式的方式来完成语法错误恢复错误产生式Aerrorα例如:stmterror;首先定义哪些"主要"非终结符号有错误恢复动作;比如:表达式,语句,块,函数定义等非终结符号当语法分析器碰到错误时不断弹出栈中状态,直到栈顶状态包含A.
errorα;分析器将error移入栈中.
如果α为空,分析器直接执行归约,并调用相关的语义动作;否则向前跳过一些符号,找到可以归约为α的串为止.
- 符号正则表达式java相关文档
- 投标正则表达式java
- 词法正则表达式java
- 对象正则表达式java
- 生物信息学基础教程第4讲:正则表达式教程
- 正则表达式正则表达式java
- OWASP中文项目组http://www.owasp.org.cn
俄罗斯vps主机推荐,怎么样俄罗斯vps俄罗斯vps速度怎么样?
俄罗斯vps速度怎么样?俄罗斯vps云主机节点是欧洲十大节点之一,地处俄罗斯首都莫斯科,网络带宽辐射周边欧洲大陆,10G专线连通德国法兰克福、法国巴黎、意大利米兰等,向外连接全球。俄罗斯vps云主机速度快吗、延迟多少?由于俄罗斯数据中心出口带宽充足,俄罗斯vps云主机到全球各地的延迟、速度相对来说都不错。今天,云服务器网(yuntue.com)小编介绍一下俄罗斯vps速度及俄罗斯vps主机推荐!俄...
酷番云-618云上秒杀,香港1核2M 29/月,高防服务器20M 147/月 50M 450/月,续费同价!
官方网站:点击访问酷番云官网活动方案:优惠方案一(限时秒杀专场)有需要海外的可以看看,比较划算29月,建议年付划算,月付续费不同价,这个专区。国内节点可以看看,性能高IO为主, 比较少见。平常一般就100IO 左右。优惠方案二(高防专场)高防专区主要以高防为主,节点有宿迁,绍兴,成都,宁波等,节点挺多,都支持防火墙自助控制。续费同价以下专场。 优惠方案三(精选物理机)西南地区节点比较划算,赠送5...

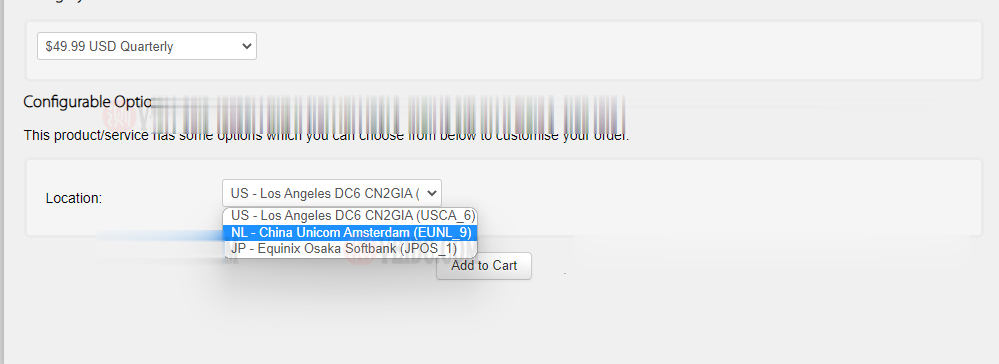
搬瓦工:新增荷兰机房 EUNL_9 测评,联通 AS10099/AS9929 高端优化路线/速度 延迟 路由 丢包测试
搬瓦工最近上线了一个新的荷兰机房,荷兰 EUNL_9 机房,这个 9 的编号感觉也挺随性的,之前的荷兰机房编号是 EUNL_3。这次荷兰新机房 EUNL_9 采用联通 AS9929 高端路线,三网都接入了 AS9929,对于联通用户来说是个好消息,又多了一个选择。对于其他用户可能还是 CN2 GIA 机房更合适一些。其实对于联通用户,这个荷兰机房也是比较远的,相比之下日本软银 JPOS_1 机房可...
-
google地球打不开google earth打不开怎么办?iphone5解锁苹果5手机怎么解屏幕锁天天酷跑刷积分教程天天酷跑积分怎么获得 天天酷跑刷积分方法渗透测试软件测试与渗透测试那个工作有前途公章制作在WOLD里怎样制作公章数码资源网安卓有没有可以离线刷题的软件?怎么点亮qq空间图标怎么点亮QQ空间的图标安装迅雷看看播放器迅雷看看不能播放,说我尚未安装迅雷看看播放器云挂机快手极速版后台云挂机辅?助各位用了吗?在哪找的?分词技术怎样做好百度分词技术和长尾词优化