分词分词技术
分词技术 时间:2021-02-20 阅读:()
第43卷第1期2019年2月南京理工大学学报JournalofNanjingUniversityofScienceandTechnologyVol.
43No.
1Feb.
2019收稿日期:2018-01-30修回日期:2018-12-11基金项目:博士后基金(2016M592894XB)云南省科技厅面上项目(KKS0201703015)国家自然科学基金(61741112)云南省自然科学基金(2017FB098)作者简介:蒋卫丽(1995-)女硕士生主要研究方向:数据分析E~mail:1379252229@qq.
com通讯作者:邵党国(1979-)男博士主要研究方向:图像处理、自然语言处理、数据挖掘、机器学习E~mail:huntersdg@126.
com引文格式:蒋卫丽陈振华邵党国等.
基于领域词典的动态规划分词算法[J].
南京理工大学学报201943(1):63-71.
投稿网址:http://zrxuebao.
njust.
edu.
cn基于领域词典的动态规划分词算法蒋卫丽陈振华邵党国马磊相艳郑娜余正涛(昆明理工大学信息工程与自动化学院云南昆明650504)摘要:由于中文分词的复杂性不同专业领域具有不同的词典构造该文通过隐马尔可夫模型(HiddenMarkovmodelHMM)中文分词模型对文本信息进行初步分词并结合相关的搜狗领域词库构建出对应的领域词典对新词出现进行监控实时优化更新从而提出了一种基于领域词典的动态规划分词算法通过对特定领域的信息进行分词实验验证了该文提出的分词算法可获得较高的分词准确率与召回率实验结果表明基于领域词典的动态规划分词算法与基于领域词典的分词算法相比准确率和召回率都有提升基于领域词典的动态规划分词算法与传统的smallseg分词、snailseg分词算法相比分词召回率和准确率都有提升分词召回率提升了大约1%分词准确率提升了大约8%进一步说明了该文提出的分词算法具有很好的领域适应性关键词:动态规划词典领域适应性隐马尔可夫模型召回率准确率中文分词中图分类号:TP391文章编号:1005-9830(2019)01-0063-09DOI:10.
14177/j.
cnki.
32-1397n.
2019.
43.
01.
009DynamicprogrammingwordsegmentationalgorithmbasedondomaindictionariesJiangWeiliChenZhenhuaShaoDangguoMaLeiXiangYanZhengNaYuZhengtao(SchoolofInformationEngineeringandAutomationKunmingUniversityofScienceandTechnologyKunming650504China)南京理工大学学报第43卷第1期Abstract:DuetotheChinesewordsegmentationcomplexitydifferentexpertisefieldshaveitslexicalstructures.
ThispapercombinessougoudomaindictionarytoconstructdomaindictionaryviaChinesesegmentationofthehiddenMarkovmodel(HMM)forinitialsegmentationintextmessage.
Itmonitorstheappearanceofnewwordsoptimizesandupdatesthemintimeandproposesadynamicprogrammingbasedondomaindictionary.
Bysegmentingtheinformationinaspecificfielditisverifiedthatthewordsegmentationalgorithmproposedherecanobtainhigheraccuracyandrecallrateofwordsegmentation.
Theresultsshowthatcomparedwiththedictionary~basedwordsegmenta~tionalgorithmthisalgorithmhasimprovedthewordsegmentrecallrateandaccuracy.
Comparedwiththetraditionalsmallsegwordsegmentationandsnailsegwordsegmentationalgorithmthedynamicdictionarysegmentationalgorithmbasedondomaindictionarieshasimprovedwordsegmen~tationrecallrateandaccuracyrate.
Thewordsegmentationrecallrateisincreasedbyapproximately1%andthewordsegmentationaccuracyrateisincreasedbyapproximately8%.
Thisdemonstratesthatthispaperalgorithmhasgoodfieldadaptation.
Keywords:dynamicprogrammingdictionarydomainadaptabilityhiddenMarkovmodelrecallrateaccuracyrateChinesewordsegmentation汉语以字作为最小单位的特点使得所有基于中文的自然语言处理中都必须在汉字字符串组成的句子被准确识别成词序列之后才能进一步地展开因此要研究中文语言处理技术就必须先解决中文分词问题中文分词的目标就是将一个汉字序列切分成一个一个单独的词如"我是一名研究生"这条短语正确的中文分词应为"我/是/一名/研究生"要实现这一目标就要求计算机识别并理解人类的语言而分词正是让计算机理解人类语言的第一步总之中文分词可以说是中文信息处理领域的基础瓶颈问题对其进行相关的研究也很有实际意义[1]在中文句子中汉字与汉字之间的组合可以构成词语[2]词语长短不一[3]并存在词语有切分歧义的问题切分歧义是指在对一个中文句子进行分词时可能产生不同的切分形式[4]这两者都会给分词造成困难在分词系统中未登录词的识别也是一个很重要的问题未登录词指的是在词典中没有出现的词语[5]基于词典的分词方法[6](又称机械分词)是经典的中文分词技术其优点是分词的速度比较快、效率比较高分词的过程[7]可以转化为与词典中的词语相匹配的过程实现也相对容易但是如果把基于词典的分词方法应用到某具体领域由于领域专业词汇的变化导致许多语料出现了领域词汇使得未登录词识别问题[8]成为跨领域分词的一个关键问题同时由于领域的改变引起上下文变化直接导致已登录词的处理能力下降有色金属行业是中国重要的经济支柱产业我国拥有丰富的有色金属矿产资源有色金属及其合金产品是机械制造业、建筑业、电子工业、航空航天、核能利用等领域不可缺少的结构材料和功能材料互联网中存在大量的有关有色金属矿产资源、有色金属产品生产企业、有色金属行业协会、有色金属产品工艺流程、有色金属行业职能部门、有色金属产品等方面的冶金文本信息所以对冶金领域的信息进行分词有着重要的价值与意义但是由于传统的基于词典的分词方法[9]存在着上述缺陷本文通过对经典的分词算法和词典结构进行分析和研究提出了一种高效的分词算法通过采用领域词典的分词算法[10]对专业领域分词构建出新的词典结构进一步使用专业领域词典对动态规划的分词算法进行改进从而构建出一种基于领域词典的动态规划分词算法算法中增加与专业领域相关的未登录词的数量来改善中文分词的领域适应性能更有效地识别词语切分出一些不是词语的字符串也具有相对较好的歧义识别能力从而有效改善跨领域中文分词的46总第224期蒋卫丽陈振华邵党国马磊相艳郑娜余正涛基于领域词典的动态规划分词算法效果1基于领域词典的动态规划分词算法领域词典的动态规划分词算法的探究模型搭建和模型评估都是按照步骤进行研究工作按照研究路线逐步开展具体如图1所示图1研究路线由图1可以看出传统分词算法在特定领域的适用性不强本文利用Trie树结构构建领域词典并与原词典结合形成新词典对领域词典进行实时监控当有新词出现实行更新优化领域词典新词典与分词算法结合形成基于领域词典的动态规划分词算法下文将详细探讨该算法1.
1HMM分词算法1.
1.
1HMM分词模型隐马尔可夫模型(HiddenMarkovmodelHMM)[11]是统计模型用来描述一个隐含未知参数的马尔可夫过程确定隐含的参数然后利用参数来做进一步的分析HMM模型[12]可以用于评估问题、学习问题和解码问题评估问题是用来如何有效地计算某一观测序列的概率学习问题是用来调整参数使观测序列概率最大解码问题就是寻找最优秀的隐状态序列实际的例子就是分词在采用HMM模型[13]时需要建立两个假设首先是齐次马尔科夫性假设即设任意时刻t的所有词的状态只依赖于前一位置的状态与其他时刻的状态无关即P(it|it-1ot-1i1t1)=P(it|it-1)(1)式中:i和o分别表示待分词状态it则表示词i在t时刻的状态P(it|it-1ot-1i1t1)则表示词i和o在以前时刻的状态对当前词i时刻的影响程度其次是观测独立性假设即任意词的观测状态都与该时刻的马尔科夫链状态有关与其他状态无关通常采用条件独立性假设公式计算词的状态转移概率用公式表示为P(ot|iToTiT-1oT-1it+1ot+1itit-1ot-1i1o1)=P(ot|it)(2)式中:P(ot|iToTiT-1oT-1it+1ot+1itit-1ot-1i1o1)表示词i和词o所有状态对词o在t时刻的影响程度P(ot|it)表示词i在t时刻对词o在t时刻的影响程度1.
1.
2动态规划求解本文使用维特比算法(ViterbialgorithmViterbi)[14]来动态规划求解HMM模型Viterbi是通过计算各初始状态的对数概率值然后递推计算每时刻的对数概率值每个词对应Viterbi中的节点一条语句对应一条路径对于任意两个词δ与Ψ定义在t时刻状态i的所有单个路径(i1i2it)中概率最大值为δt(i)=max(i1i2in)P(it=itit-1i1oto1|λ)i=12N(3)那么词δ的递推公式为δt(i)=maxj(δt-1(j)ajibikt)(4)式中:aji表示状态i到状态j的转移概率bikt表示在时刻的观察状态kj的观察概率在t时刻状态i的所有单个路径(i1i2it)中概率最大路径的t个词为Ψt(i)=argmax(x1≤j≤N(δt-1(j)aji))(5)这样便可确定下一状态的分词预测值为it=argmax(δT(i))(6)那么进一步有it=Ψt+1(i)(7)最终分词序列为I=(i1i2iT)(8)1.
2基于领域词典的动态规划分词基于领域词典的分词算法[15]指的是对一些词典中未出现的新词采用HMM模型进行分词其中句子为观测序列分词结果为状态序列首先通过语料训练出HMM相关的模型然后利用Viterbi进行求解最终得到最优的状态序列然后56南京理工大学学报第43卷第1期再根据状态序列输出分词结果领域词典的统计一般通用词库所采用的Trie树[16]对词频进行统计不过其统计的文章只是报纸期刊没有行业代表性针对专业领域如冶金行业本文采用基于前缀词典动态规划结合领域词典的分词算法对专业领域分词进行优化力求克服在专业领域分词不准确的缺点下文将探讨领域词库的构建与领域词典库的动态规划算法1.
2.
1领域词库构建基于Trie树结构的高效词图扫描算法[17]可生成句子中所有汉字可组成词所构成的有向无环图Trie树是哈希树的变种典型地应用在文本词频统计中通过字符串的公共前缀减少查询时间最大限度地减少无用的字符串的比较效率也高于哈希表但在词频统计中仅仅采用一般的词库显然没有领域代表性比如在艺术、体育和冶金等行业的HMM中文分词的准确率及稳定性均较低本文构建相对应的领域词库可能对分词的速度会有相对应的影响但是能提高分词的精确度可以有效地改变中文分词的领域适应性并且在消除歧义方面会展现出较好的性能比如"冶金行业"这个词在不加入领域词库时HMM模型通常会把新词切分为两字组合的形式这个词切分为"冶金"和"行业"两个词但是新建词库中有"冶金行业"这个词那么就会对这个词进行准确切分1.
2.
2动态规划分词算法基于词典的分词方法[18]也是按照一定的规则将待分词的字符串与词典中的词条进行匹配本文通过构造的前缀词典对句子进行切分根据切分位置构造一个有向无环图通过动态规划算法计算的最大概率路径即为最终切分形式由前缀词典对句子切分位置而构建好有向无环图之后需要进一步计算最大概率路径有向无环图中每一个节点都是具有权重值的本文假设第i个节点的权重值为wi所有节点便可构成一个权重向量W={w1w2w3}(9)假设某条路径通过了l个节点这些节点集合为N=(n1n2nl)那么通过这些节点的路径的权重可表示为R(n1n2nl)对于任意节点ni其任意一个后继节点nk满足以下关系R(nink)=R(ni)+wk(10)整个句子的最优路径Rmax与末端节点nx它们存在多个前驱ni、nj、nk等节点这些节点最大路径分别为Rmaxni、Rmaxnj、Rmaxnk因此有Rmax=max(RmaxniRmaxnj)+wnx(11)对于任意句子最终均能通过这种迭代方式找到比较理性的分词结果基于前缀词典的动态规划与领域词典结合的分词算法的算法框架图如图2所示图2分词过程框架图2实验及分析为了验证所提出模型的有效性与本文建立的基于领域词典自适应分词算法进行比较的算法有:smallseg分词算法、snailseg分词算法、添加词库的smallseg分词算法、添加词库的snailseg分词算法实验运行环境为Intelcorei7~6700CPU32GB内存所使用的软件工具为Python2.
72.
1评估标准准确率是指在分词结果中切分正确的词语的总数量与分词系统分出的所有词语数量的比值计算公式为P=分词结果中切分正确的词语数量分词结果中的词语的总数量(12)召回率指的是分词结果中切分正确的词语的总数量与文本中总的正确的词语数量的比值即R=分词结果中切分正确的词语数量分词总的词语数量(13)2.
2领域词典构建通用词库中镶嵌有3种分词模型在进行中66总第224期蒋卫丽陈振华邵党国马磊相艳郑娜余正涛基于领域词典的动态规划分词算法文分词的过程中各个模型交叉使用取长补短并且扩展性能较好在已有的词典的基础上可以根据不同行业的要求加入新的词典本文在原有的通用词典基础之上将搜狗输入法和冶金行业的词库转化为基于领域词典的动态规划分词算法的数据词典[19]并通过对该算法加入数据词典前后的分词结果作对比统计加词典前后的分词结果原词典和领域词典格式的示例如表1所示表1词典格式对照表词典词名词频词性原词典一个床9m领域词典阿达尔铝合金22745无本文中切分文件是从冶金信息网上收集整理大概2个月的新闻数据具体采用的数据信息如表2所示可以看出词库大小有着显著差异尤其是对冶金领域加上该领域专有名词可能导致分词效果的提高表2数据信息表统计项词库大小/MB词库领域切分文件大小/MB原词库5.
16日常领域1.
5冶金词库1.
73冶金领域1.
52.
3动态规划分词算法本文通过比较添加冶金词库前后分词结果差异来对冶金行业中文分词结果进行评估采用交叉验证的方式选取大约80%的文档作为训练集20%的文档作为测试集对分词结果中切分正确的词语数量进行人工统计并计算分词前后的准确率和召回率本文从新闻信息中抽取298篇冶金领域新闻信息对10万多个词进行分词运用前文的动态规划分词模型进行处理在分词过程中分别对添加领域词库前后计算结果进行10次对比得到添加冶金词库前后分词的准确率和召回率如表3所示表3分词效果对照表试验次数分词准确个数比较项准确率/%召回率/%总词汇数1添加词库前添加词库后12658212800387.
9195.
2594.
1995.
251439811343832添加词库前添加词库后12585412797387.
4195.
2393.
6595.
231439811343833添加词库前添加词库后12510512767786.
8995.
0193.
0995.
011439811343834添加词库前添加词库后12559512812087.
2395.
3493.
4695.
341439811343835添加词库前添加词库后12481712730186.
6994.
7392.
8894.
731439811343836添加词库前添加词库后12611212848387.
5995.
6193.
8495.
611439811343837添加词库前添加词库后12393912617286.
0893.
8992.
2293.
891439811343838添加词库前添加词库后12556612806787.
2195.
3093.
4395.
301439811343839添加词库前添加词库后12473112683086.
6394.
3892.
8294.
3814398113438310添加词库前添加词库后12634312857787.
7595.
6894.
0195.
68143981134383平均值添加词库前添加词库后125464.
4127720.
387.
1395.
0493.
3695.
0414398113438376南京理工大学学报第43卷第1期通过统计分析后发现在添加领域词库后分词准确率大幅度提高因为很多专有名词可以被准确地切分例如"钒钛资源"、"设备故障"、"作业率"、"新产品"、"新技术"这些词在没有添加词库之前被分为"钒""钛"和"资源"、"设备"和"故障"、"作业"和"率"、"新"和"产品"、"新"和"技术"这些词而在添加词库后就不会出现这种情况但新闻中存在一些不属于专业领域且存在歧义的词就可能不被准确切分例如"不知道"、"覆盖率"等词被切分为"不"和"知道"、"覆盖"和"率"就不能被准确切分如果词库更加完善分词精度也会进一步提升本文建立基于领域词典的动态规划分词算法能更好地通过对新词出现实时监控优化更新领域词库完善词库提高分词的准确率2.
4传统分词算法本文使用可自定义词典、有一定新词识别能力的smallseg分词算法和能对单字位置最大概率统计选择最优的snailseg分词算法[20]本文分别对对比算法在添加词库前后对冶金新闻领域分词效果做了实验分析2.
4.
1smallseg分词本文采用smallseg分词算法对冶金新闻信息的词语进行10次交叉验证得到分词的准确率和召回率如表4所示2.
4.
2snailseg分词本文采用snailseg分词算法对冶金新闻信息的词语进行10次交叉验证得到分词的准确率和召回率如表5所示表4分词结果表试验次数比较项分词准确个数准确率/%召回率/%总词汇数1添加词库前添加词库后825489435267.
4578.
0968.
3278.
091223721208262添加词库前添加词库后894369766470.
0680.
0273.
2880.
021241201220473添加词库前添加词库后912779611873.
8879.
8174.
7979.
811235461220444添加词库前添加词库后10402710865480.
0889.
0285.
2389.
021287181220545添加词库前添加词库后9584210105676.
8982.
4678.
2182.
461246481225446添加词库前添加词库后916589745673.
9979.
5274.
7979.
521238771225547添加词库前添加词库后10335410641279.
9286.
8484.
3486.
841293251225448添加词库前添加词库后901349455269.
9773.
4073.
6573.
401288181223819添加词库前添加词库后9483110125374.
2482.
6277.
3882.
6212774212255210添加词库前添加词库后926469812473.
9180.
0775.
6080.
07125347122548平均值添加词库前添加词库后935759956474.
0481.
1976.
5681.
1912585112220986总第224期蒋卫丽陈振华邵党国马磊相艳郑娜余正涛基于领域词典的动态规划分词算法表5分词结果表试验次数比较项分词准确个数准确率/%召回率/%总词汇数1添加词库前添加词库后895489568473.
1778.
4073.
3778.
401223721220502添加词库前添加词库后921349688275.
1679.
3875.
4979.
381225811220483添加词库前添加词库后914789641474.
3078.
9974.
9578.
991231771220524添加词库前添加词库后956429845776.
2280.
6778.
3680.
671254831220555添加词库前添加词库后9438810027474.
7882.
1677.
3482.
161262221220436添加词库前添加词库后884749353172.
0076.
6372.
4976.
631228821220507添加词库前添加词库后924769742373.
1379.
2975.
2679.
291264581228758添加词库前添加词库后943259971575.
6081.
7377.
3181.
731247641220099添加词库前添加词库后9514710116475.
1181.
4276.
5881.
4212667312424510添加词库前添加词库后932269942475.
5582.
9377.
7682.
93123396119889平均值添加词库前添加词库后926849789774.
5080.
1675.
8980.
161244011221322.
5分词算法对比本文将基于领域词典的动态规划分词算法与传统的动态规划分词算法分别进行实验为更直观比较对其结果作出分词准确率图如图3所示图3分词准确率比较图由图3可以看出准确率最高的是基于领域词典的动态规划分词算法大约都在95%相对较差的是传统的动态规划分词算法虽添加词库后的smallseg分词算法和snailseg分词算法准确率都有所提升但波动也较大性能低于基于领域词典的动态规划分词算法本文将基于领域词典的动态规划分词算法与传统的动态规划分词算法分别进行实验为更直观比较对其结果作出分词召回率图如图4所示图4分词召回率比较图由图4可以看出召回率最高的是传统动态规划分词算法大约都在95%相对较差的是传统的动态规划分词算法虽添加词库后的96南京理工大学学报第43卷第1期smallseg分词算法和snailseg分词算法召回率都有所提升但波动也较大性能低于基于领域词典的动态规划分词算法通过对冶金领域的新闻信息进行分词实验从图3和图4可以看出基于领域词典的分词算法分词准确率都有提升并且加了实时监测新词出现进行词库的动态规划来完善词库能提高分词准确率且在图中得到体现基于领域词典的动态规划分词算法与传统的动态规划分词算法的准确率和召回率都高于smallseg分词、snailseg分词基于领域词典的动态规划分词算法与传统的动态规划分词算法相比分词召回率提升了大约1%分词准确率提升了大约8%同时添加词库后的smallseg分词和snailseg分词都比添加词库前分词准确率提高了大约7%分词召回率提高了大约5%由此可见使用本文提出的基于领域词典的动态规划分词算法对特定领域进行分词实验可获得较高的准确率及召回率3结束语本文通过对经典的分词算法和词典结构进行分析和研究提出了一种高效的分词算法本文通过HMM中文分词模型对文本信息进行初步分词并结合相关的搜狗领域词库构建出对应的领域词典实时监控新词进行优化更新完善词库从而提出了一种基于领域词典的动态规划分词算法通过该算法对冶金行业的新闻信息进行分词实验实验结果表明本文提出的分词算法准确率得到大幅度提升尤其在专业名词方面得到了显著性提升改善了歧义识别的问题由于中文分词的复杂性不同专业领域具有不同的词典构造所以进一步的工作是构建适用于更多行业的领域词典利用分词词典的易扩展性来提高在不同领域中分词的效果参考文献:[1]WangKZongCSuK.
Acharacter~basedjointmodelforChinesewordsegmentation[C]//InternationalConferenceonComputationalLinguistics.
NewYorkUSA:AssociationforComputationalLinguistics2010.
[2]常建秋沈炜.
基于字符串匹配的中文分词算法的研究[J].
工业控制计算机201629(2):115-116.
ChangJianqiuShenWei.
ResearchonChinesewordsegmentationalgorithmbasedonstringmatching[J].
IndustrialControlComputer201629(2):115-116.
[3]张桂平刘东生尹宝生等.
面向专利文献的中文分词技术的研究[J].
中文信息学报201024(3):112-116.
ZhangGuipingLiuDongshengYinBaosheng.
ResearchonChinesewordsegmentationforpatentdocuments[J].
JournalofChineseInformationProcessing201024(3):112-116.
[4]韩冬煦常宝宝.
中文分词模型的领域适应性方法[J].
计算机学报201538(2):272-281.
HanDonxunChangBaobao.
DomainadaptationmethodofChinesewordsegmentationmodel[J].
ChineseJournalofComputers201538(2):272-281.
[5]魏莎莎.
一种中文未登录词识别及词典设计新方法[D].
重庆:西南大学2011.
[6]何爱元.
基于词典和概率统计的中文分词算法研究[D].
绵阳:辽宁大学2011.
[7]张梅山邓知龙车万翔等.
统计与词典相结合的领域自适应中文分词[J].
中文信息学报201226(2):8-13.
ZhangMeishangDengZhilongCheWangxiangetal.
CombiningstatisticalmodelanddictionaryfordomainadaptionofChinesewordsegmentation[J].
JournalofChineseInformationProcessing201226(2):8-13.
[8]张赢万仲保.
对专业搜索引擎中未登录词的识别研究[J].
计算机技术与发展200919(5):134-136.
ZhangYingWangZhongbao.
Professionalsearchengineunknownwordofrecognition[J].
ComputerTechnologyandDevelopment200919(5):134-136.
[9]蒋建洪赵嵩正罗玫.
词典与统计方法结合的中文分词模型研究及应用[J].
计算机工程与设计201233(1):387-391.
JiangJianhongZhaoSongzhengLuoMei.
AnalysisandapplicationofChinesewordsegmentationmodelwhichconsistofdictionaryandstatisticsmethod[J].
ComputerEngineering&Design201233(1):387-391.
[10]曹勇刚曹羽中金茂忠等.
面向信息检索的自适应中文分词系统[J].
软件学报200617(3):356-363.
CaoYonggangCaoYuzhongJinMaozhongetal.
InformationretrievalorientedadaptiveChinesewordsegmentationsystem[J].
JournalofSoftware200617(3):356-363.
[11]钱智勇周建忠童国平等.
基于HMM的楚辞自07总第224期蒋卫丽陈振华邵党国马磊相艳郑娜余正涛基于领域词典的动态规划分词算法动分词标注研究[J].
图书情报工作201458(4):105-110.
QianZhiyongZhouJianzhongTongGuopingatel.
StudyonautomaticwordsegmentationofthesongsofchubasedonHMM[J].
LibraryandInformationService201458(4):105-110.
[12]陈顺强马嘿玛伙.
基于隐马尔科夫模型的彝文分词系统设计与开发[J].
西南民族大学学报(自然科学版)201238(1):146-149.
ChenShunqiangMaHeimahuo.
DesignanddevelopmentofwordsegmentationsystembasedonhiddenMarkovmodel[J].
JournalofSouthwestUniversityforNationalities(NaturalScienceEdition)201238(1):146-149.
[13]徐钟.
隐马尔科夫模型在中文实体分类中的应用及研究[D].
南昌:南昌大学2012.
[14]李荣郑家恒.
一种改进Viterbi算法的应用研究[J].
计算机工程与设计200728(3):530-531.
LiRongZhengJiaheng.
ApplicationresearchofanimprovedViterbialgorithm[J].
ComputerEngineeringandDesign200728(3):530-531.
[15]倪维健孙浩浩刘彤等.
面向领域文献的无监督中文分词自动优化方法[J].
数据分析与知识发现20182(2):96-104.
NiWeijianSunHaohaoetal.
UnsupervisedChinesewordsegmentationautomaticoptimizationmethodfordomainliterature[J].
Dataanalysisandknowledgediscovery20182(2):96-104.
[16]熊志斌朱剑锋.
基于改进Trie树结构的正向最大匹配算法[J].
计算机应用与软件201431(5):276-278.
XiongZhibinZhuJianfeng.
ForwardmaximummatchingalgorithmbasedonimprovedTrietreestructure[J].
ComputerApplicationsandSoftware201431(5):276-278.
[17]崔尚森冯博琴.
最长前缀匹配查找的索引分离trie树结构及其算法[J].
计算机工程与应用200541(20):131-134.
CuiShangsenFengBoqin.
Indexseparationtrietreestructureandalgorithmforlongestprefixmatchsearch[J].
ComputerEngineeringandApplications200541(20):131-134.
[18]朱艳辉刘璟徐叶强等.
基于条件随机场的中文领域分词研究[J].
计算机工程与应用201652(15):97-100.
ZhuYanhuiLiuJingXuYeqiangetal.
Chinesewordsegmentationresearchbasedonconditionalrandomfield[J].
ComputerEngineeringandApplications201652(15):97-100.
[19]王树梅戴保存吴慧中等.
文本分类的字典生成[J].
南京理工大学学报200226(5):517-521.
WangShumeiDaiBaocunWuHuizhongetal.
Dictionarygenerationoftextclassification[J].
JournalofNanjingUniversityofScienceandTechnology200226(5):517-521.
[20]王文王树锋李洪华.
基于文本语义和表情倾向的微博情感分析方法[J].
南京理工大学学报201438(6):733-738.
WangWenWangShufengLiHonghua.
Microblogsentimentanalysismethodbasedontextsemanticsandexpressiontendency[J].
JournalofNanjingUniversityofScienceandTechnology201438(6):733-738.
17
43No.
1Feb.
2019收稿日期:2018-01-30修回日期:2018-12-11基金项目:博士后基金(2016M592894XB)云南省科技厅面上项目(KKS0201703015)国家自然科学基金(61741112)云南省自然科学基金(2017FB098)作者简介:蒋卫丽(1995-)女硕士生主要研究方向:数据分析E~mail:1379252229@qq.
com通讯作者:邵党国(1979-)男博士主要研究方向:图像处理、自然语言处理、数据挖掘、机器学习E~mail:huntersdg@126.
com引文格式:蒋卫丽陈振华邵党国等.
基于领域词典的动态规划分词算法[J].
南京理工大学学报201943(1):63-71.
投稿网址:http://zrxuebao.
njust.
edu.
cn基于领域词典的动态规划分词算法蒋卫丽陈振华邵党国马磊相艳郑娜余正涛(昆明理工大学信息工程与自动化学院云南昆明650504)摘要:由于中文分词的复杂性不同专业领域具有不同的词典构造该文通过隐马尔可夫模型(HiddenMarkovmodelHMM)中文分词模型对文本信息进行初步分词并结合相关的搜狗领域词库构建出对应的领域词典对新词出现进行监控实时优化更新从而提出了一种基于领域词典的动态规划分词算法通过对特定领域的信息进行分词实验验证了该文提出的分词算法可获得较高的分词准确率与召回率实验结果表明基于领域词典的动态规划分词算法与基于领域词典的分词算法相比准确率和召回率都有提升基于领域词典的动态规划分词算法与传统的smallseg分词、snailseg分词算法相比分词召回率和准确率都有提升分词召回率提升了大约1%分词准确率提升了大约8%进一步说明了该文提出的分词算法具有很好的领域适应性关键词:动态规划词典领域适应性隐马尔可夫模型召回率准确率中文分词中图分类号:TP391文章编号:1005-9830(2019)01-0063-09DOI:10.
14177/j.
cnki.
32-1397n.
2019.
43.
01.
009DynamicprogrammingwordsegmentationalgorithmbasedondomaindictionariesJiangWeiliChenZhenhuaShaoDangguoMaLeiXiangYanZhengNaYuZhengtao(SchoolofInformationEngineeringandAutomationKunmingUniversityofScienceandTechnologyKunming650504China)南京理工大学学报第43卷第1期Abstract:DuetotheChinesewordsegmentationcomplexitydifferentexpertisefieldshaveitslexicalstructures.
ThispapercombinessougoudomaindictionarytoconstructdomaindictionaryviaChinesesegmentationofthehiddenMarkovmodel(HMM)forinitialsegmentationintextmessage.
Itmonitorstheappearanceofnewwordsoptimizesandupdatesthemintimeandproposesadynamicprogrammingbasedondomaindictionary.
Bysegmentingtheinformationinaspecificfielditisverifiedthatthewordsegmentationalgorithmproposedherecanobtainhigheraccuracyandrecallrateofwordsegmentation.
Theresultsshowthatcomparedwiththedictionary~basedwordsegmenta~tionalgorithmthisalgorithmhasimprovedthewordsegmentrecallrateandaccuracy.
Comparedwiththetraditionalsmallsegwordsegmentationandsnailsegwordsegmentationalgorithmthedynamicdictionarysegmentationalgorithmbasedondomaindictionarieshasimprovedwordsegmen~tationrecallrateandaccuracyrate.
Thewordsegmentationrecallrateisincreasedbyapproximately1%andthewordsegmentationaccuracyrateisincreasedbyapproximately8%.
Thisdemonstratesthatthispaperalgorithmhasgoodfieldadaptation.
Keywords:dynamicprogrammingdictionarydomainadaptabilityhiddenMarkovmodelrecallrateaccuracyrateChinesewordsegmentation汉语以字作为最小单位的特点使得所有基于中文的自然语言处理中都必须在汉字字符串组成的句子被准确识别成词序列之后才能进一步地展开因此要研究中文语言处理技术就必须先解决中文分词问题中文分词的目标就是将一个汉字序列切分成一个一个单独的词如"我是一名研究生"这条短语正确的中文分词应为"我/是/一名/研究生"要实现这一目标就要求计算机识别并理解人类的语言而分词正是让计算机理解人类语言的第一步总之中文分词可以说是中文信息处理领域的基础瓶颈问题对其进行相关的研究也很有实际意义[1]在中文句子中汉字与汉字之间的组合可以构成词语[2]词语长短不一[3]并存在词语有切分歧义的问题切分歧义是指在对一个中文句子进行分词时可能产生不同的切分形式[4]这两者都会给分词造成困难在分词系统中未登录词的识别也是一个很重要的问题未登录词指的是在词典中没有出现的词语[5]基于词典的分词方法[6](又称机械分词)是经典的中文分词技术其优点是分词的速度比较快、效率比较高分词的过程[7]可以转化为与词典中的词语相匹配的过程实现也相对容易但是如果把基于词典的分词方法应用到某具体领域由于领域专业词汇的变化导致许多语料出现了领域词汇使得未登录词识别问题[8]成为跨领域分词的一个关键问题同时由于领域的改变引起上下文变化直接导致已登录词的处理能力下降有色金属行业是中国重要的经济支柱产业我国拥有丰富的有色金属矿产资源有色金属及其合金产品是机械制造业、建筑业、电子工业、航空航天、核能利用等领域不可缺少的结构材料和功能材料互联网中存在大量的有关有色金属矿产资源、有色金属产品生产企业、有色金属行业协会、有色金属产品工艺流程、有色金属行业职能部门、有色金属产品等方面的冶金文本信息所以对冶金领域的信息进行分词有着重要的价值与意义但是由于传统的基于词典的分词方法[9]存在着上述缺陷本文通过对经典的分词算法和词典结构进行分析和研究提出了一种高效的分词算法通过采用领域词典的分词算法[10]对专业领域分词构建出新的词典结构进一步使用专业领域词典对动态规划的分词算法进行改进从而构建出一种基于领域词典的动态规划分词算法算法中增加与专业领域相关的未登录词的数量来改善中文分词的领域适应性能更有效地识别词语切分出一些不是词语的字符串也具有相对较好的歧义识别能力从而有效改善跨领域中文分词的46总第224期蒋卫丽陈振华邵党国马磊相艳郑娜余正涛基于领域词典的动态规划分词算法效果1基于领域词典的动态规划分词算法领域词典的动态规划分词算法的探究模型搭建和模型评估都是按照步骤进行研究工作按照研究路线逐步开展具体如图1所示图1研究路线由图1可以看出传统分词算法在特定领域的适用性不强本文利用Trie树结构构建领域词典并与原词典结合形成新词典对领域词典进行实时监控当有新词出现实行更新优化领域词典新词典与分词算法结合形成基于领域词典的动态规划分词算法下文将详细探讨该算法1.
1HMM分词算法1.
1.
1HMM分词模型隐马尔可夫模型(HiddenMarkovmodelHMM)[11]是统计模型用来描述一个隐含未知参数的马尔可夫过程确定隐含的参数然后利用参数来做进一步的分析HMM模型[12]可以用于评估问题、学习问题和解码问题评估问题是用来如何有效地计算某一观测序列的概率学习问题是用来调整参数使观测序列概率最大解码问题就是寻找最优秀的隐状态序列实际的例子就是分词在采用HMM模型[13]时需要建立两个假设首先是齐次马尔科夫性假设即设任意时刻t的所有词的状态只依赖于前一位置的状态与其他时刻的状态无关即P(it|it-1ot-1i1t1)=P(it|it-1)(1)式中:i和o分别表示待分词状态it则表示词i在t时刻的状态P(it|it-1ot-1i1t1)则表示词i和o在以前时刻的状态对当前词i时刻的影响程度其次是观测独立性假设即任意词的观测状态都与该时刻的马尔科夫链状态有关与其他状态无关通常采用条件独立性假设公式计算词的状态转移概率用公式表示为P(ot|iToTiT-1oT-1it+1ot+1itit-1ot-1i1o1)=P(ot|it)(2)式中:P(ot|iToTiT-1oT-1it+1ot+1itit-1ot-1i1o1)表示词i和词o所有状态对词o在t时刻的影响程度P(ot|it)表示词i在t时刻对词o在t时刻的影响程度1.
1.
2动态规划求解本文使用维特比算法(ViterbialgorithmViterbi)[14]来动态规划求解HMM模型Viterbi是通过计算各初始状态的对数概率值然后递推计算每时刻的对数概率值每个词对应Viterbi中的节点一条语句对应一条路径对于任意两个词δ与Ψ定义在t时刻状态i的所有单个路径(i1i2it)中概率最大值为δt(i)=max(i1i2in)P(it=itit-1i1oto1|λ)i=12N(3)那么词δ的递推公式为δt(i)=maxj(δt-1(j)ajibikt)(4)式中:aji表示状态i到状态j的转移概率bikt表示在时刻的观察状态kj的观察概率在t时刻状态i的所有单个路径(i1i2it)中概率最大路径的t个词为Ψt(i)=argmax(x1≤j≤N(δt-1(j)aji))(5)这样便可确定下一状态的分词预测值为it=argmax(δT(i))(6)那么进一步有it=Ψt+1(i)(7)最终分词序列为I=(i1i2iT)(8)1.
2基于领域词典的动态规划分词基于领域词典的分词算法[15]指的是对一些词典中未出现的新词采用HMM模型进行分词其中句子为观测序列分词结果为状态序列首先通过语料训练出HMM相关的模型然后利用Viterbi进行求解最终得到最优的状态序列然后56南京理工大学学报第43卷第1期再根据状态序列输出分词结果领域词典的统计一般通用词库所采用的Trie树[16]对词频进行统计不过其统计的文章只是报纸期刊没有行业代表性针对专业领域如冶金行业本文采用基于前缀词典动态规划结合领域词典的分词算法对专业领域分词进行优化力求克服在专业领域分词不准确的缺点下文将探讨领域词库的构建与领域词典库的动态规划算法1.
2.
1领域词库构建基于Trie树结构的高效词图扫描算法[17]可生成句子中所有汉字可组成词所构成的有向无环图Trie树是哈希树的变种典型地应用在文本词频统计中通过字符串的公共前缀减少查询时间最大限度地减少无用的字符串的比较效率也高于哈希表但在词频统计中仅仅采用一般的词库显然没有领域代表性比如在艺术、体育和冶金等行业的HMM中文分词的准确率及稳定性均较低本文构建相对应的领域词库可能对分词的速度会有相对应的影响但是能提高分词的精确度可以有效地改变中文分词的领域适应性并且在消除歧义方面会展现出较好的性能比如"冶金行业"这个词在不加入领域词库时HMM模型通常会把新词切分为两字组合的形式这个词切分为"冶金"和"行业"两个词但是新建词库中有"冶金行业"这个词那么就会对这个词进行准确切分1.
2.
2动态规划分词算法基于词典的分词方法[18]也是按照一定的规则将待分词的字符串与词典中的词条进行匹配本文通过构造的前缀词典对句子进行切分根据切分位置构造一个有向无环图通过动态规划算法计算的最大概率路径即为最终切分形式由前缀词典对句子切分位置而构建好有向无环图之后需要进一步计算最大概率路径有向无环图中每一个节点都是具有权重值的本文假设第i个节点的权重值为wi所有节点便可构成一个权重向量W={w1w2w3}(9)假设某条路径通过了l个节点这些节点集合为N=(n1n2nl)那么通过这些节点的路径的权重可表示为R(n1n2nl)对于任意节点ni其任意一个后继节点nk满足以下关系R(nink)=R(ni)+wk(10)整个句子的最优路径Rmax与末端节点nx它们存在多个前驱ni、nj、nk等节点这些节点最大路径分别为Rmaxni、Rmaxnj、Rmaxnk因此有Rmax=max(RmaxniRmaxnj)+wnx(11)对于任意句子最终均能通过这种迭代方式找到比较理性的分词结果基于前缀词典的动态规划与领域词典结合的分词算法的算法框架图如图2所示图2分词过程框架图2实验及分析为了验证所提出模型的有效性与本文建立的基于领域词典自适应分词算法进行比较的算法有:smallseg分词算法、snailseg分词算法、添加词库的smallseg分词算法、添加词库的snailseg分词算法实验运行环境为Intelcorei7~6700CPU32GB内存所使用的软件工具为Python2.
72.
1评估标准准确率是指在分词结果中切分正确的词语的总数量与分词系统分出的所有词语数量的比值计算公式为P=分词结果中切分正确的词语数量分词结果中的词语的总数量(12)召回率指的是分词结果中切分正确的词语的总数量与文本中总的正确的词语数量的比值即R=分词结果中切分正确的词语数量分词总的词语数量(13)2.
2领域词典构建通用词库中镶嵌有3种分词模型在进行中66总第224期蒋卫丽陈振华邵党国马磊相艳郑娜余正涛基于领域词典的动态规划分词算法文分词的过程中各个模型交叉使用取长补短并且扩展性能较好在已有的词典的基础上可以根据不同行业的要求加入新的词典本文在原有的通用词典基础之上将搜狗输入法和冶金行业的词库转化为基于领域词典的动态规划分词算法的数据词典[19]并通过对该算法加入数据词典前后的分词结果作对比统计加词典前后的分词结果原词典和领域词典格式的示例如表1所示表1词典格式对照表词典词名词频词性原词典一个床9m领域词典阿达尔铝合金22745无本文中切分文件是从冶金信息网上收集整理大概2个月的新闻数据具体采用的数据信息如表2所示可以看出词库大小有着显著差异尤其是对冶金领域加上该领域专有名词可能导致分词效果的提高表2数据信息表统计项词库大小/MB词库领域切分文件大小/MB原词库5.
16日常领域1.
5冶金词库1.
73冶金领域1.
52.
3动态规划分词算法本文通过比较添加冶金词库前后分词结果差异来对冶金行业中文分词结果进行评估采用交叉验证的方式选取大约80%的文档作为训练集20%的文档作为测试集对分词结果中切分正确的词语数量进行人工统计并计算分词前后的准确率和召回率本文从新闻信息中抽取298篇冶金领域新闻信息对10万多个词进行分词运用前文的动态规划分词模型进行处理在分词过程中分别对添加领域词库前后计算结果进行10次对比得到添加冶金词库前后分词的准确率和召回率如表3所示表3分词效果对照表试验次数分词准确个数比较项准确率/%召回率/%总词汇数1添加词库前添加词库后12658212800387.
9195.
2594.
1995.
251439811343832添加词库前添加词库后12585412797387.
4195.
2393.
6595.
231439811343833添加词库前添加词库后12510512767786.
8995.
0193.
0995.
011439811343834添加词库前添加词库后12559512812087.
2395.
3493.
4695.
341439811343835添加词库前添加词库后12481712730186.
6994.
7392.
8894.
731439811343836添加词库前添加词库后12611212848387.
5995.
6193.
8495.
611439811343837添加词库前添加词库后12393912617286.
0893.
8992.
2293.
891439811343838添加词库前添加词库后12556612806787.
2195.
3093.
4395.
301439811343839添加词库前添加词库后12473112683086.
6394.
3892.
8294.
3814398113438310添加词库前添加词库后12634312857787.
7595.
6894.
0195.
68143981134383平均值添加词库前添加词库后125464.
4127720.
387.
1395.
0493.
3695.
0414398113438376南京理工大学学报第43卷第1期通过统计分析后发现在添加领域词库后分词准确率大幅度提高因为很多专有名词可以被准确地切分例如"钒钛资源"、"设备故障"、"作业率"、"新产品"、"新技术"这些词在没有添加词库之前被分为"钒""钛"和"资源"、"设备"和"故障"、"作业"和"率"、"新"和"产品"、"新"和"技术"这些词而在添加词库后就不会出现这种情况但新闻中存在一些不属于专业领域且存在歧义的词就可能不被准确切分例如"不知道"、"覆盖率"等词被切分为"不"和"知道"、"覆盖"和"率"就不能被准确切分如果词库更加完善分词精度也会进一步提升本文建立基于领域词典的动态规划分词算法能更好地通过对新词出现实时监控优化更新领域词库完善词库提高分词的准确率2.
4传统分词算法本文使用可自定义词典、有一定新词识别能力的smallseg分词算法和能对单字位置最大概率统计选择最优的snailseg分词算法[20]本文分别对对比算法在添加词库前后对冶金新闻领域分词效果做了实验分析2.
4.
1smallseg分词本文采用smallseg分词算法对冶金新闻信息的词语进行10次交叉验证得到分词的准确率和召回率如表4所示2.
4.
2snailseg分词本文采用snailseg分词算法对冶金新闻信息的词语进行10次交叉验证得到分词的准确率和召回率如表5所示表4分词结果表试验次数比较项分词准确个数准确率/%召回率/%总词汇数1添加词库前添加词库后825489435267.
4578.
0968.
3278.
091223721208262添加词库前添加词库后894369766470.
0680.
0273.
2880.
021241201220473添加词库前添加词库后912779611873.
8879.
8174.
7979.
811235461220444添加词库前添加词库后10402710865480.
0889.
0285.
2389.
021287181220545添加词库前添加词库后9584210105676.
8982.
4678.
2182.
461246481225446添加词库前添加词库后916589745673.
9979.
5274.
7979.
521238771225547添加词库前添加词库后10335410641279.
9286.
8484.
3486.
841293251225448添加词库前添加词库后901349455269.
9773.
4073.
6573.
401288181223819添加词库前添加词库后9483110125374.
2482.
6277.
3882.
6212774212255210添加词库前添加词库后926469812473.
9180.
0775.
6080.
07125347122548平均值添加词库前添加词库后935759956474.
0481.
1976.
5681.
1912585112220986总第224期蒋卫丽陈振华邵党国马磊相艳郑娜余正涛基于领域词典的动态规划分词算法表5分词结果表试验次数比较项分词准确个数准确率/%召回率/%总词汇数1添加词库前添加词库后895489568473.
1778.
4073.
3778.
401223721220502添加词库前添加词库后921349688275.
1679.
3875.
4979.
381225811220483添加词库前添加词库后914789641474.
3078.
9974.
9578.
991231771220524添加词库前添加词库后956429845776.
2280.
6778.
3680.
671254831220555添加词库前添加词库后9438810027474.
7882.
1677.
3482.
161262221220436添加词库前添加词库后884749353172.
0076.
6372.
4976.
631228821220507添加词库前添加词库后924769742373.
1379.
2975.
2679.
291264581228758添加词库前添加词库后943259971575.
6081.
7377.
3181.
731247641220099添加词库前添加词库后9514710116475.
1181.
4276.
5881.
4212667312424510添加词库前添加词库后932269942475.
5582.
9377.
7682.
93123396119889平均值添加词库前添加词库后926849789774.
5080.
1675.
8980.
161244011221322.
5分词算法对比本文将基于领域词典的动态规划分词算法与传统的动态规划分词算法分别进行实验为更直观比较对其结果作出分词准确率图如图3所示图3分词准确率比较图由图3可以看出准确率最高的是基于领域词典的动态规划分词算法大约都在95%相对较差的是传统的动态规划分词算法虽添加词库后的smallseg分词算法和snailseg分词算法准确率都有所提升但波动也较大性能低于基于领域词典的动态规划分词算法本文将基于领域词典的动态规划分词算法与传统的动态规划分词算法分别进行实验为更直观比较对其结果作出分词召回率图如图4所示图4分词召回率比较图由图4可以看出召回率最高的是传统动态规划分词算法大约都在95%相对较差的是传统的动态规划分词算法虽添加词库后的96南京理工大学学报第43卷第1期smallseg分词算法和snailseg分词算法召回率都有所提升但波动也较大性能低于基于领域词典的动态规划分词算法通过对冶金领域的新闻信息进行分词实验从图3和图4可以看出基于领域词典的分词算法分词准确率都有提升并且加了实时监测新词出现进行词库的动态规划来完善词库能提高分词准确率且在图中得到体现基于领域词典的动态规划分词算法与传统的动态规划分词算法的准确率和召回率都高于smallseg分词、snailseg分词基于领域词典的动态规划分词算法与传统的动态规划分词算法相比分词召回率提升了大约1%分词准确率提升了大约8%同时添加词库后的smallseg分词和snailseg分词都比添加词库前分词准确率提高了大约7%分词召回率提高了大约5%由此可见使用本文提出的基于领域词典的动态规划分词算法对特定领域进行分词实验可获得较高的准确率及召回率3结束语本文通过对经典的分词算法和词典结构进行分析和研究提出了一种高效的分词算法本文通过HMM中文分词模型对文本信息进行初步分词并结合相关的搜狗领域词库构建出对应的领域词典实时监控新词进行优化更新完善词库从而提出了一种基于领域词典的动态规划分词算法通过该算法对冶金行业的新闻信息进行分词实验实验结果表明本文提出的分词算法准确率得到大幅度提升尤其在专业名词方面得到了显著性提升改善了歧义识别的问题由于中文分词的复杂性不同专业领域具有不同的词典构造所以进一步的工作是构建适用于更多行业的领域词典利用分词词典的易扩展性来提高在不同领域中分词的效果参考文献:[1]WangKZongCSuK.
Acharacter~basedjointmodelforChinesewordsegmentation[C]//InternationalConferenceonComputationalLinguistics.
NewYorkUSA:AssociationforComputationalLinguistics2010.
[2]常建秋沈炜.
基于字符串匹配的中文分词算法的研究[J].
工业控制计算机201629(2):115-116.
ChangJianqiuShenWei.
ResearchonChinesewordsegmentationalgorithmbasedonstringmatching[J].
IndustrialControlComputer201629(2):115-116.
[3]张桂平刘东生尹宝生等.
面向专利文献的中文分词技术的研究[J].
中文信息学报201024(3):112-116.
ZhangGuipingLiuDongshengYinBaosheng.
ResearchonChinesewordsegmentationforpatentdocuments[J].
JournalofChineseInformationProcessing201024(3):112-116.
[4]韩冬煦常宝宝.
中文分词模型的领域适应性方法[J].
计算机学报201538(2):272-281.
HanDonxunChangBaobao.
DomainadaptationmethodofChinesewordsegmentationmodel[J].
ChineseJournalofComputers201538(2):272-281.
[5]魏莎莎.
一种中文未登录词识别及词典设计新方法[D].
重庆:西南大学2011.
[6]何爱元.
基于词典和概率统计的中文分词算法研究[D].
绵阳:辽宁大学2011.
[7]张梅山邓知龙车万翔等.
统计与词典相结合的领域自适应中文分词[J].
中文信息学报201226(2):8-13.
ZhangMeishangDengZhilongCheWangxiangetal.
CombiningstatisticalmodelanddictionaryfordomainadaptionofChinesewordsegmentation[J].
JournalofChineseInformationProcessing201226(2):8-13.
[8]张赢万仲保.
对专业搜索引擎中未登录词的识别研究[J].
计算机技术与发展200919(5):134-136.
ZhangYingWangZhongbao.
Professionalsearchengineunknownwordofrecognition[J].
ComputerTechnologyandDevelopment200919(5):134-136.
[9]蒋建洪赵嵩正罗玫.
词典与统计方法结合的中文分词模型研究及应用[J].
计算机工程与设计201233(1):387-391.
JiangJianhongZhaoSongzhengLuoMei.
AnalysisandapplicationofChinesewordsegmentationmodelwhichconsistofdictionaryandstatisticsmethod[J].
ComputerEngineering&Design201233(1):387-391.
[10]曹勇刚曹羽中金茂忠等.
面向信息检索的自适应中文分词系统[J].
软件学报200617(3):356-363.
CaoYonggangCaoYuzhongJinMaozhongetal.
InformationretrievalorientedadaptiveChinesewordsegmentationsystem[J].
JournalofSoftware200617(3):356-363.
[11]钱智勇周建忠童国平等.
基于HMM的楚辞自07总第224期蒋卫丽陈振华邵党国马磊相艳郑娜余正涛基于领域词典的动态规划分词算法动分词标注研究[J].
图书情报工作201458(4):105-110.
QianZhiyongZhouJianzhongTongGuopingatel.
StudyonautomaticwordsegmentationofthesongsofchubasedonHMM[J].
LibraryandInformationService201458(4):105-110.
[12]陈顺强马嘿玛伙.
基于隐马尔科夫模型的彝文分词系统设计与开发[J].
西南民族大学学报(自然科学版)201238(1):146-149.
ChenShunqiangMaHeimahuo.
DesignanddevelopmentofwordsegmentationsystembasedonhiddenMarkovmodel[J].
JournalofSouthwestUniversityforNationalities(NaturalScienceEdition)201238(1):146-149.
[13]徐钟.
隐马尔科夫模型在中文实体分类中的应用及研究[D].
南昌:南昌大学2012.
[14]李荣郑家恒.
一种改进Viterbi算法的应用研究[J].
计算机工程与设计200728(3):530-531.
LiRongZhengJiaheng.
ApplicationresearchofanimprovedViterbialgorithm[J].
ComputerEngineeringandDesign200728(3):530-531.
[15]倪维健孙浩浩刘彤等.
面向领域文献的无监督中文分词自动优化方法[J].
数据分析与知识发现20182(2):96-104.
NiWeijianSunHaohaoetal.
UnsupervisedChinesewordsegmentationautomaticoptimizationmethodfordomainliterature[J].
Dataanalysisandknowledgediscovery20182(2):96-104.
[16]熊志斌朱剑锋.
基于改进Trie树结构的正向最大匹配算法[J].
计算机应用与软件201431(5):276-278.
XiongZhibinZhuJianfeng.
ForwardmaximummatchingalgorithmbasedonimprovedTrietreestructure[J].
ComputerApplicationsandSoftware201431(5):276-278.
[17]崔尚森冯博琴.
最长前缀匹配查找的索引分离trie树结构及其算法[J].
计算机工程与应用200541(20):131-134.
CuiShangsenFengBoqin.
Indexseparationtrietreestructureandalgorithmforlongestprefixmatchsearch[J].
ComputerEngineeringandApplications200541(20):131-134.
[18]朱艳辉刘璟徐叶强等.
基于条件随机场的中文领域分词研究[J].
计算机工程与应用201652(15):97-100.
ZhuYanhuiLiuJingXuYeqiangetal.
Chinesewordsegmentationresearchbasedonconditionalrandomfield[J].
ComputerEngineeringandApplications201652(15):97-100.
[19]王树梅戴保存吴慧中等.
文本分类的字典生成[J].
南京理工大学学报200226(5):517-521.
WangShumeiDaiBaocunWuHuizhongetal.
Dictionarygenerationoftextclassification[J].
JournalofNanjingUniversityofScienceandTechnology200226(5):517-521.
[20]王文王树锋李洪华.
基于文本语义和表情倾向的微博情感分析方法[J].
南京理工大学学报201438(6):733-738.
WangWenWangShufengLiHonghua.
Microblogsentimentanalysismethodbasedontextsemanticsandexpressiontendency[J].
JournalofNanjingUniversityofScienceandTechnology201438(6):733-738.
17
企鹅小屋:垃圾服务商有跑路风险,站长注意转移备份数据!
企鹅小屋:垃圾服务商有跑路风险!企鹅不允许你二次工单的,二次提交工单直接关服务器,再严重就封号,意思是你提交工单要小心,别因为提交工单被干了账号!前段时间,就有站长说企鹅小屋要跑路了,站长不太相信,本站平台已经为企鹅小屋推荐了几千元的业绩,CPS返利达182.67CNY。然后,站长通过企鹅小屋后台申请提现,提现申请至今已经有20几天,企鹅小屋也没有转账。然后,搞笑的一幕出现了:平台账号登录不上提示...
HostKvm:夏季优惠,香港云地/韩国vps终身7折,线路好/机器稳/适合做站
hostkvm怎么样?hostkvm是一家国内老牌主机商家,商家主要销售KVM架构的VPS,目前有美国、日本、韩国、中国香港等地的服务,站长目前还持有他家香港CN2线路的套餐,已经用了一年多了,除了前段时间香港被整段攻击以外,一直非常稳定,是做站的不二选择,目前商家针对香港云地和韩国机房的套餐进行7折优惠,其他套餐为8折,商家支持paypal和支付宝付款。点击进入:hostkvm官方网站地址hos...

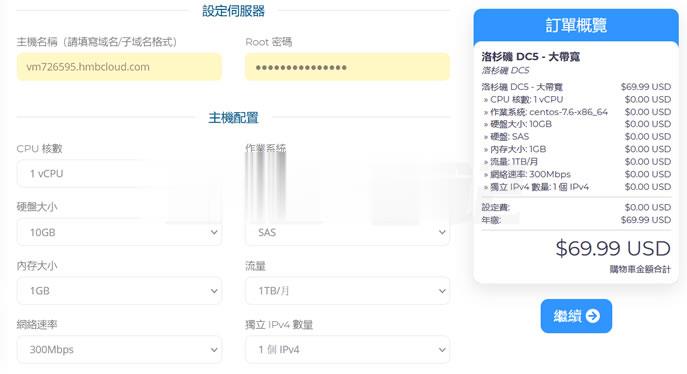
半月湾hmbcloud升级500Mbps带宽,原生VPS,$4.99/月
关于半月湾HMBCloud商家之前也有几篇那文章介绍过这个商家的产品,对于他们家的其他产品我都没有多加留意,而是对他们家的DC5机房很多人还是比较喜欢的,这个比我们有些比较熟悉的某商家DC6 DC9机房限时,而且半月湾HMBCloud商家是相对便宜的。关于半月湾DC5机房的方案选择和介绍:1、半月湾三网洛杉矶DC5 CN2 GIA同款DC6 DC9 1G内存 1TB流量 月$4.992、亲测选择半...
分词技术为你推荐
-
赵雨润电影《奇迹世界》详细剧情介绍网站联盟网盟跟b2b平台有什么区别ps抠图技巧如何使用PS抠图腾讯文章怎么在手机腾讯网发文章ios7固件下载iphone自动下载IOS7固件版本怎么删除怎么升级ios6苹果iPhone6怎么升级系统宕机宕机是什么意思?电子商务网站模板网页制作模板网站优化方案网站优化方案如何写?三星s8什么时候上市三星s8什么时候首发