casesandybridge
sandybridge 时间:2021-03-27 阅读:()
PLQCDlibraryforLatticeQCDonmulti-coremachinesA.
Abdel-Rehim,aC.
Alexandrou,a,bN.
Anastopoulos,cG.
Koutsou,aI.
LiabotisdandN.
PapadopouloucaTheCyprusInstitute,CaSToRC,20KonstantinouKavaStreet,2121Aglantzia,Nicosia,CyprusbDepartmentofPhysics,UniversityofCyprus,P.
O.
Box20537,1678Nicosia,CypruscComputingSystemsLaboratory,SchoolofElectricalandComputerEngineering,NationalTechnicalUniversityofAthens,ZografouCampus,15773Zografou,Athens,GreecedGreekResearchandTechnologyNetwork,56MesogionAv.
,11527,Athens,GreeceE-mail:a.
abdel-rehim@cyi.
ac.
cy,c.
alexandrou@cyi.
ac.
cy,g.
koutsou@cyi.
ac.
cy,anastop@cslab.
ece.
ntua.
gr,iliaboti@grnet.
gr,nikela@cslab.
ece.
ntua.
grPLQCDisastand–alonesoftwarelibrarydevelopedunderPRACEforlatticeQCD.
Itpro-videsanimplementationoftheDiracoperatorforWilsontypefermionsandfewefcientlin-earsolvers.
Thelibraryisoptimizedformulti-coremachinesusingahybridparallelizationwithOpenMP+MPI.
ThemainobjectivesofthelibraryistoprovideascalableimplementationoftheDiracoperatorforefcientcomputationofthequarkpropagator.
Inthiscontribution,adescrip-tionofthePLQCDlibraryisgiventogetherwithsomebenchmarkresults.
31stInternationalSymposiumonLatticeFieldTheoryLATTICE2013July29August3,2013Mainz,GermanySpeaker.
cCopyrightownedbytheauthor(s)underthetermsoftheCreativeCommonsAttribution-NonCommercial-ShareAlikeLicence.
http://pos.
sissa.
it/arXiv:1405.
0700v1[hep-lat]4May2014PLQCDA.
Abdel-Rehim1.
IntroductionComputerhardwareforcommodityclustersaswellassupercomputershasevolvedtremen-douslyinthelastfewyears.
Nowadaysatypicalcomputenodehasbetween16and64coresandpossiblyanacceleratorsuchasaGraphicsProcessingUnit(GPU)orlatelyanIntelManyIntegratedCore(MIC)card.
Thistrendofpackingmanylow-poweredbutmassivelyparallelpro-cessingunitsisexpectedtocontinueassupercomputingtechnologypursuestheExascaleregime.
Thecurrenttechnologytrendsindicatethatbandwidthtomainmemorywillcontinuetolagbehindcomputationalpower,whichrequiresarethinkingofthedesignoflatticeQCDcodessuchthattheycanefcientlyrunonsucharchitectures.
Takingthisintoaccount,PRACE[1]allocatedresourcesforcommunitycodescalingactivitiesinmanycomputationallyintensiveareasincludinglatticeQCD.
TheworkpresentedherewasdevelopedunderPRACEfocusingonscalingcodesformulti-coremachines.
Theworkwepresentdealswithcommunitycodes,andmorespecicallyoncertaincomputationallyintensivekernelsinthesecodes,inordertoimprovetheirscalingandperformanceformulti-corearchitectures.
WehavecarriedoutoptimizationworkonthetmLQCD[2,3]codeandhavedevelopedanewhybridMPI/OpenMPlibrary(PLQCD)withoptimizedimplementationsoftheWilsonDirackernelandaselectedsetoflinearsolvers.
OurpartnersinthisprojecthavealsoperformedoptimizationworkfortheMolecularDynamicsintegratorsusedinHybridMonteCarlocodes,andalsoforLandaugaugexing.
ThiswasdonewithintheChromasoftwaresuite[4]andwillnotbediscussedhere(See[5]formoreinformation).
Manyothercommunitycodesofcourseexistbutwerenotconsideredinthiswork(See[6]foranoverview).
Inwhatfollows,wewillrstpresenttheworkcarriedoutforthecaseofPLQCD,whereweim-plementedtheWilsonDiracoperatorandassociatedlinearalgebrafunctionsusingMPI+OpenMP.
Inadditiontousingthishybridapproachforparallelism,wealsoimplementadditionaloptimiza-tionssuchasoverlappingcommunicationandcomputation,usingcompilerintrinsicsforvector-izationaswellasimplementingthenewAdvancedVectorInstructions[7](AVXforIntelorQPXforBlue/GeneQ)thatbecamerecentlyavailableinnewgenerationofprocessorssuchastheIntelSandy-Bridge.
TheworkdoneforthecaseofthetmLQCDpackagewillthenbepresented,whereweimplementedsomenewefcientlinearsolvers,inparticularthosebasedondeationsuchastheEigCGsolver[8],forwhichwewillgivesomebenchmarkresults.
2.
DiracoperatoroptimizationsAkeycomponentofthelatticeDiracoperatoristhehoppingpartgivenbyEq.
2.
1.
ψ(x)=3∑=0[U(x)(1γ)φ(x+e)+U(xe)(1+γ)φ(xe)],(2.
1)where,U(x)isthegaugelinkmatrixinthedirectionatsitex,γaretheDiracmatricesandeisaunitvectorinthedirection.
φandψaretheinputandoutputspinorsrespectively.
Equation2.
1canbere-writtenintermsoftwoauxiliaryeldsθ+(x)=(1γ)φ(x)andθ(x)=U(x)(1+γ)φ(x)asψ(x)=3∑=0[U(x)θ+(x+e)+θ(xe)].
(2.
2)2PLQCDA.
Abdel-RehimBecauseofthestructureoftheγmatrices,onlytheuppertwospincomponentsofθ±needtobecomputedbecausethelowertwospincomponentsarerelatedtotheupperones[9].
Inthefollowingwedescribesomeoftheoptimizationsperformedforthehoppingmatrix.
2.
1HybridparallelizationwithMPIandOpenMPOpenMPprovidesasimpleapproachformulti-threadingsinceitisimplementedascompilerdirectives.
Onecanincrementallyaddmulti-threadingtothecodeandalsousethesamecodewithmulti-threadingturnedonandoff.
Sincethemaincomponentinthehoppingmatrix(Diracoperator)isalarge"forloop"overlatticesites,itisnaturaltousethefor-loopparallelconstructofopenMP.
TheperformanceofthehybridcodeisthentestedagainstthepureMPIversion.
Weperformaweakscalingtestbyxingthelocalvolumepercore(orthread)andincreasethenumberofMPIprocesses.
ThetestwasdoneontheHoppermachineatNERSCwhichisaCrayXE6[10].
Eachcomputenodehas2twelve-coreAMD'MagnyCours'at2.
1-GHzsuchthateach6coressharethesamecache.
WendperformancefortheHybridversionismaximumwhenassigningatmost6threadsperMPIprocesssuchthatthese6OMPthreadssharethesameL3cache.
InFig.
1weshowtheperformanceofthepureMPIandtheMPI+openMPwith6threadsperMPIprocessforatotalnumberofcoresupto49,152cores.
FromtheseresultswerstnoticethatusingOpenMPleadstoaslightdegradationinperformanceascomparedtothepureMPIcase.
However,asweseeinthecasewithlocalvolumeof124,thehybridapproachperformsbetteraswegotoalargenumberofcores.
Similarbehaviorhasbeenalsoobservedforothercodesfromdifferentcomputationalsciences(seethecasestudiesonHopper[11]).
Figure1:WeakscalingtestforthehoppingmatrixonaCrayXE6machinewithlocallatticevolumepercore84(left)and124(right).
2.
2OverlappingcommunicationwithcomputationTypicallyinlatticecodesonerstcomputestheauxiliaryhalf-spinoreldsθ±asgiveninEquation(2.
2)andthencommunicatestheirvaluesontheboundariesbetweenneighboringpro-cessesinthe+anddirections.
Inablockingcommunicationscheme,computationhaltsuntilcommunicationoftheboundariescompletes.
Analternativeapproachistooverlapcommunica-tionswithcomputationsbydividingthelatticesitesintobulksites,forwhichnearestneighborsare3PLQCDA.
Abdel-Rehimavailablelocally,andboundarysites,forwhichthenearestneighborsarelocatedonneighboringprocesses,andthereforecanonlybeoperateduponaftercommunication.
Theorderofoperationsforcomputingtheresultψisthendoneasfollows:Computeθ+andbegincommunicatingthemtotheneighboringMPIprocessinthedirection.
ComputeθandbegincommunicatingthemtotheneighboringMPIprocessinthe+direction.
Computetheresultψ(x)onthebulksiteswhiletheneighborsarebeingcommunicated.
Waitforthecommunicationsinthedirectionstonish,thencomputethecontributions∑3=0[U(x)θ+(x+e)]totheresultontheboundarysites.
Waitforthecommunicationsinthe+directionstonish,thencomputethecontributions∑3=0[θ(xe)]ontheboundarysites.
Communicationisdoneusingnon-blockingMPIfunctionsMPI_Isend,MPI_IrecvandMPI_Wait.
Apossibledrawbackofthisapproachisthatonewillaccessψ(x)andU(x)inanunorderedfash-iondifferentfromtheorderitisstoredinmemory.
This,however,canbecircumventedpartiallybyusinghintsinthecodeforprefetching.
Wehavetestedtheeffectofprefetchingincaseofsequen-tialandrandomaccessofspinorandlinkelds.
Thetestwasdoneusingaseparatebenchmarkkernelcodewhichisolatesthelink-spinormultiplication.
AscanbeseeninFig.
3,prefetchingbecomesimportantforalargenumberofsites,i.
e.
whendata(spinorsandlinks)cannottinthecachememory,whichisatypicalsituationforlatticecalculations.
Itisalsonotedthataccessingthesitesrandomlyreducestheperformance,aswouldbeexpected.
Inthiscaseonecanimprovethesituationbydeningapointerarray,e.
g.
forthespinorsψ(i)=&ψ(x[i])wherex[i]isthesitetobeaccessedatstepiintheloopsuchasweshowinpseudo-codeinFig.
2.
Thesepointerscanbedenedapriori.
ThisimprovesthepredictiveabilityofthehardwareasisshowninFig.
3wherewecomparethedifferentprefetchingandaddressingschemes.
Sequentialaccessfor(i=0;iSandyBridgeprocessorsandlaterbyAMDintheirBull-dozerprocessor.
The16XMMregistersofSSE3arenow256-bitwideandknownasYMMregisters.
AVX-capableoatingpointunitsareabletoperformon4doubleprecisionoatingpointnumbersor8singleprecision.
Implementingtheseextensionsinthevectorizedpartsoflatticecodeshasthepotentialofprovidingagainofuptoafactor2inanidealsituation,althoughinprac-ticethisdependsonthelayoutoflatticedata.
Weprovidedanimplementationoftheseextensionsusinginlineintrinsics.
InthisimplementationasingleSU(3)matrixmultipliestwoSU(3)vectorssimultaneously.
Againofaboutafactorof1.
5isachievedforthehoppingmatrixinthetmLQCDcodeindoubleprecisionasshowninFig.
(4).
Forillustration,acodesnippetformultiplyingtwocomplexnumbersbytwocomplexnumbersusingAVXisshowninFig.
(5).
3.
EigCGsolverforTwisted-MassfermionsTwisted-MassfermionsoffertheadvantageofautomaticO(a)improvementwhentunedtomaximaltwist[12].
Withinthisdevelopmentworkwehaveaddedanincrementaldeationalgo-rithm,knownasEigCG,tothetmLQCDpackage.
Numericaltestsshowedaconsiderablespeed-upofthesolutionofthelinearsystemsonthelargestvolumessimulatedbytheEuropeanTwistedMassCollaboration(ETMC).
Forillustration,weshowinFig.
(6)thetimetosolutionwithEigCGonaTwisted-Masscongurationwith2+1+1dynamicalavorswithlatticesize483*96atβ=2.
1,andpionmass≈230MeV.
Inthiscasethetotalnumberofeigenvectorsdeatedwas300whichwasbuiltincrementallybycomputing10eigenvectorsduringthesolutionoftherst30right-handsidesusingasearchsubspaceofsize60.
Allsystemsaresolvedindoubleprecisiontorelativetoleranceof108.
5PLQCDA.
Abdel-RehimFigure4:Comparingtheperformanceofthehop-pingmatrixoftmLQCDusingSSE3andAVXindoubleprecisiononanIntelSandyBridgeprocessor.
#include/*t0:a+b*I,e+f*Iandt1:c+d*I,g+h*I*return:(ac-bd)+(ad+bc)*I,*(eg-fh)+(eh+fg)*I*/staticinline__m256dcomplex_mul_regs_256(__m256dt0,__m256dt1){__m256dt2;t2=t1;t1=_mm256_unpacklo_pd(t1,t1);t2=_mm256_unpackhi_pd(t2,t2);t1=_mm256_mul_pd(t1,t0);t2=_mm256_mul_pd(t2,t0);t2=_mm256_shuffle_pd(t2,t2,5);t1=_mm256_addsub_pd(t1,t2);returnt1;}Figure5:MultiplyingtwocomplexnumbersbytwocomplexnumberoftypedoubleusingAVXin-structions.
Figure6:Solutiontimeperprocessfortherst35right-handsidesusingIncrementalEigCGascomparedtoCGonaTwisted-Masscongurationwithlatticesize483*96atβ=2.
1,andpionmass≈230MeV.
4.
ConclusionsandSummaryWehavecarriedoutdevelopmenteffortforafewselectedkernelsusedinlatticeQCD.
TherstoftheseeffortsincludedthedevelopmentofahybridMPI/OpenMPlibrarywhichincludesparallelizedkernelsfortheWilsonDiracoperatorandfewassociatedsolvers.
Anumberofparal-lelizationstrategieshavebeeninvestigated,suchasforoverlappingcommunicationwithcomputa-tions.
ThecodehasbeenshowntoscalefairlywellontheCrayXE6.
Intermsofsingleprocessperformance,wecarriedoutinitialvectorizationeffortsforAVXwhereweseeanimprovementof1.
5comparedtotheideal2.
Inadditionwehaveinvestigatedseveraldata-orderingandassociatedprefetchingstrategies.
ForthecaseoftmLQCD,themainsoftwarecodeoftheETMCcollaboration,wehaveimple-6PLQCDA.
Abdel-Rehimmentedanefcientlinearsolverwhichincrementallydeatedthetwisted-massDiracoperatortogiveaspeed-upofabout3timeswhenenoughright-hand-sidesarerequired.
Thisisalreadyinuseinproductionprojects,suchasinRefs.
[14]and[13].
Allcodesarepubliclyavailable.
PLQCDisavailablethroughtheHPCFORGEwebsiteattheSwissNationalSupercomputingCentre(CSCS)wheremoreinformationisavailablewithinthecodedocumentation.
OurEigCGimplementationintmLQCDisavailableviagit-hub.
AcknowledgementsThistalkwasapartofacodingsessionsponsoredpartiallybythePRACE-2IPproject,aspartofthe"CommunityCodesDevelopment"WorkPackage8.
PRACE-2IPisa7thFrameworkEUfundedproject(http://www.
prace-ri.
eu/,grantagreementnumber:RI-283493).
Wewouldliketothanktheorganizersofthe2013Latticemeetingfortheirstrongsupporttomakethecodingsessionasuccessandprovideallorganizationsupport.
WewouldliketothankC.
Urbach,A.
Deuzmann,B.
Kostrzewa,HubertSimma,S.
Krieg,andL.
Scorzatoforverystimulatingdiscussionsduringthedevelopmentofthisproject.
WeacknowledgethecomputingresourcesfromTier-0machinesofPRACEincludingJUQUEENandCuriemachinesaswellastheTodimachineatCSCS.
WealsoacknowledgethecomputingsupportfromNERSCandtheHoppermachine.
References[1]http://www.
prace-ri.
eu/.
[2]K.
JansenandC.
Urbach,Comput.
Phys.
Commun.
180,2717(2009),[arXiv:0905.
3331].
[3]ETMCollaboration,https://github.
com/etmc/tmLQCD.
[4]http://usqcd.
jlab.
org/usqcd-docs/chroma/.
[5]SeethepublicdeliverableD8.
3onthePRACEwebsiteunderPRACE-2IP.
[6]A.
Deuzeman,PoS(LATTICE2013).
[7]SeetheIntelDevelopermanual.
[8]A.
StathopoulosandK.
Orginos,Computinganddeatingeigenvalueswhilesolvingmultipleright-handsidelinearsystemswithanapplicationtoquantumchromodynamics,SIAMJ.
Sci.
Comput.
2010;32(1):439–462,[arXiv:0707.
0131].
[9]SeeforexamplethedocumentationoftheDDHMCcodebyM.
L¨uscher.
[10]TheHopperCrayXE6machineatNERSC.
[11]SeedocumentationforcombiningMPIandopenMPontheNERSCwebsite.
[12]R.
Frezzottietal.
[AlphaCollaboration],LatticeQCDwithachirallytwistedmassterm,JHEP0108,058(2001)[hep-lat/0101001].
[13]C.
Alexandrou,M.
Constantinou,S.
Dinter,V.
Drach,K.
Hadjiyiannakou,K.
Jansen,G.
KoutsouandA.
Vaquero,arXiv:1309.
7768[hep-lat].
[14]A.
Abdel-Rehim,C.
Alexandrou,M.
Constantinou,V.
Drach,K.
Hadjiyiannakou,K.
Jansen,G.
KoutsouandA.
Vaquero,arXiv:1310.
6339[hep-lat].
7
Abdel-Rehim,aC.
Alexandrou,a,bN.
Anastopoulos,cG.
Koutsou,aI.
LiabotisdandN.
PapadopouloucaTheCyprusInstitute,CaSToRC,20KonstantinouKavaStreet,2121Aglantzia,Nicosia,CyprusbDepartmentofPhysics,UniversityofCyprus,P.
O.
Box20537,1678Nicosia,CypruscComputingSystemsLaboratory,SchoolofElectricalandComputerEngineering,NationalTechnicalUniversityofAthens,ZografouCampus,15773Zografou,Athens,GreecedGreekResearchandTechnologyNetwork,56MesogionAv.
,11527,Athens,GreeceE-mail:a.
abdel-rehim@cyi.
ac.
cy,c.
alexandrou@cyi.
ac.
cy,g.
koutsou@cyi.
ac.
cy,anastop@cslab.
ece.
ntua.
gr,iliaboti@grnet.
gr,nikela@cslab.
ece.
ntua.
grPLQCDisastand–alonesoftwarelibrarydevelopedunderPRACEforlatticeQCD.
Itpro-videsanimplementationoftheDiracoperatorforWilsontypefermionsandfewefcientlin-earsolvers.
Thelibraryisoptimizedformulti-coremachinesusingahybridparallelizationwithOpenMP+MPI.
ThemainobjectivesofthelibraryistoprovideascalableimplementationoftheDiracoperatorforefcientcomputationofthequarkpropagator.
Inthiscontribution,adescrip-tionofthePLQCDlibraryisgiventogetherwithsomebenchmarkresults.
31stInternationalSymposiumonLatticeFieldTheoryLATTICE2013July29August3,2013Mainz,GermanySpeaker.
cCopyrightownedbytheauthor(s)underthetermsoftheCreativeCommonsAttribution-NonCommercial-ShareAlikeLicence.
http://pos.
sissa.
it/arXiv:1405.
0700v1[hep-lat]4May2014PLQCDA.
Abdel-Rehim1.
IntroductionComputerhardwareforcommodityclustersaswellassupercomputershasevolvedtremen-douslyinthelastfewyears.
Nowadaysatypicalcomputenodehasbetween16and64coresandpossiblyanacceleratorsuchasaGraphicsProcessingUnit(GPU)orlatelyanIntelManyIntegratedCore(MIC)card.
Thistrendofpackingmanylow-poweredbutmassivelyparallelpro-cessingunitsisexpectedtocontinueassupercomputingtechnologypursuestheExascaleregime.
Thecurrenttechnologytrendsindicatethatbandwidthtomainmemorywillcontinuetolagbehindcomputationalpower,whichrequiresarethinkingofthedesignoflatticeQCDcodessuchthattheycanefcientlyrunonsucharchitectures.
Takingthisintoaccount,PRACE[1]allocatedresourcesforcommunitycodescalingactivitiesinmanycomputationallyintensiveareasincludinglatticeQCD.
TheworkpresentedherewasdevelopedunderPRACEfocusingonscalingcodesformulti-coremachines.
Theworkwepresentdealswithcommunitycodes,andmorespecicallyoncertaincomputationallyintensivekernelsinthesecodes,inordertoimprovetheirscalingandperformanceformulti-corearchitectures.
WehavecarriedoutoptimizationworkonthetmLQCD[2,3]codeandhavedevelopedanewhybridMPI/OpenMPlibrary(PLQCD)withoptimizedimplementationsoftheWilsonDirackernelandaselectedsetoflinearsolvers.
OurpartnersinthisprojecthavealsoperformedoptimizationworkfortheMolecularDynamicsintegratorsusedinHybridMonteCarlocodes,andalsoforLandaugaugexing.
ThiswasdonewithintheChromasoftwaresuite[4]andwillnotbediscussedhere(See[5]formoreinformation).
Manyothercommunitycodesofcourseexistbutwerenotconsideredinthiswork(See[6]foranoverview).
Inwhatfollows,wewillrstpresenttheworkcarriedoutforthecaseofPLQCD,whereweim-plementedtheWilsonDiracoperatorandassociatedlinearalgebrafunctionsusingMPI+OpenMP.
Inadditiontousingthishybridapproachforparallelism,wealsoimplementadditionaloptimiza-tionssuchasoverlappingcommunicationandcomputation,usingcompilerintrinsicsforvector-izationaswellasimplementingthenewAdvancedVectorInstructions[7](AVXforIntelorQPXforBlue/GeneQ)thatbecamerecentlyavailableinnewgenerationofprocessorssuchastheIntelSandy-Bridge.
TheworkdoneforthecaseofthetmLQCDpackagewillthenbepresented,whereweimplementedsomenewefcientlinearsolvers,inparticularthosebasedondeationsuchastheEigCGsolver[8],forwhichwewillgivesomebenchmarkresults.
2.
DiracoperatoroptimizationsAkeycomponentofthelatticeDiracoperatoristhehoppingpartgivenbyEq.
2.
1.
ψ(x)=3∑=0[U(x)(1γ)φ(x+e)+U(xe)(1+γ)φ(xe)],(2.
1)where,U(x)isthegaugelinkmatrixinthedirectionatsitex,γaretheDiracmatricesandeisaunitvectorinthedirection.
φandψaretheinputandoutputspinorsrespectively.
Equation2.
1canbere-writtenintermsoftwoauxiliaryeldsθ+(x)=(1γ)φ(x)andθ(x)=U(x)(1+γ)φ(x)asψ(x)=3∑=0[U(x)θ+(x+e)+θ(xe)].
(2.
2)2PLQCDA.
Abdel-RehimBecauseofthestructureoftheγmatrices,onlytheuppertwospincomponentsofθ±needtobecomputedbecausethelowertwospincomponentsarerelatedtotheupperones[9].
Inthefollowingwedescribesomeoftheoptimizationsperformedforthehoppingmatrix.
2.
1HybridparallelizationwithMPIandOpenMPOpenMPprovidesasimpleapproachformulti-threadingsinceitisimplementedascompilerdirectives.
Onecanincrementallyaddmulti-threadingtothecodeandalsousethesamecodewithmulti-threadingturnedonandoff.
Sincethemaincomponentinthehoppingmatrix(Diracoperator)isalarge"forloop"overlatticesites,itisnaturaltousethefor-loopparallelconstructofopenMP.
TheperformanceofthehybridcodeisthentestedagainstthepureMPIversion.
Weperformaweakscalingtestbyxingthelocalvolumepercore(orthread)andincreasethenumberofMPIprocesses.
ThetestwasdoneontheHoppermachineatNERSCwhichisaCrayXE6[10].
Eachcomputenodehas2twelve-coreAMD'MagnyCours'at2.
1-GHzsuchthateach6coressharethesamecache.
WendperformancefortheHybridversionismaximumwhenassigningatmost6threadsperMPIprocesssuchthatthese6OMPthreadssharethesameL3cache.
InFig.
1weshowtheperformanceofthepureMPIandtheMPI+openMPwith6threadsperMPIprocessforatotalnumberofcoresupto49,152cores.
FromtheseresultswerstnoticethatusingOpenMPleadstoaslightdegradationinperformanceascomparedtothepureMPIcase.
However,asweseeinthecasewithlocalvolumeof124,thehybridapproachperformsbetteraswegotoalargenumberofcores.
Similarbehaviorhasbeenalsoobservedforothercodesfromdifferentcomputationalsciences(seethecasestudiesonHopper[11]).
Figure1:WeakscalingtestforthehoppingmatrixonaCrayXE6machinewithlocallatticevolumepercore84(left)and124(right).
2.
2OverlappingcommunicationwithcomputationTypicallyinlatticecodesonerstcomputestheauxiliaryhalf-spinoreldsθ±asgiveninEquation(2.
2)andthencommunicatestheirvaluesontheboundariesbetweenneighboringpro-cessesinthe+anddirections.
Inablockingcommunicationscheme,computationhaltsuntilcommunicationoftheboundariescompletes.
Analternativeapproachistooverlapcommunica-tionswithcomputationsbydividingthelatticesitesintobulksites,forwhichnearestneighborsare3PLQCDA.
Abdel-Rehimavailablelocally,andboundarysites,forwhichthenearestneighborsarelocatedonneighboringprocesses,andthereforecanonlybeoperateduponaftercommunication.
Theorderofoperationsforcomputingtheresultψisthendoneasfollows:Computeθ+andbegincommunicatingthemtotheneighboringMPIprocessinthedirection.
ComputeθandbegincommunicatingthemtotheneighboringMPIprocessinthe+direction.
Computetheresultψ(x)onthebulksiteswhiletheneighborsarebeingcommunicated.
Waitforthecommunicationsinthedirectionstonish,thencomputethecontributions∑3=0[U(x)θ+(x+e)]totheresultontheboundarysites.
Waitforthecommunicationsinthe+directionstonish,thencomputethecontributions∑3=0[θ(xe)]ontheboundarysites.
Communicationisdoneusingnon-blockingMPIfunctionsMPI_Isend,MPI_IrecvandMPI_Wait.
Apossibledrawbackofthisapproachisthatonewillaccessψ(x)andU(x)inanunorderedfash-iondifferentfromtheorderitisstoredinmemory.
This,however,canbecircumventedpartiallybyusinghintsinthecodeforprefetching.
Wehavetestedtheeffectofprefetchingincaseofsequen-tialandrandomaccessofspinorandlinkelds.
Thetestwasdoneusingaseparatebenchmarkkernelcodewhichisolatesthelink-spinormultiplication.
AscanbeseeninFig.
3,prefetchingbecomesimportantforalargenumberofsites,i.
e.
whendata(spinorsandlinks)cannottinthecachememory,whichisatypicalsituationforlatticecalculations.
Itisalsonotedthataccessingthesitesrandomlyreducestheperformance,aswouldbeexpected.
Inthiscaseonecanimprovethesituationbydeningapointerarray,e.
g.
forthespinorsψ(i)=&ψ(x[i])wherex[i]isthesitetobeaccessedatstepiintheloopsuchasweshowinpseudo-codeinFig.
2.
Thesepointerscanbedenedapriori.
ThisimprovesthepredictiveabilityofthehardwareasisshowninFig.
3wherewecomparethedifferentprefetchingandaddressingschemes.
Sequentialaccessfor(i=0;iSandyBridgeprocessorsandlaterbyAMDintheirBull-dozerprocessor.
The16XMMregistersofSSE3arenow256-bitwideandknownasYMMregisters.
AVX-capableoatingpointunitsareabletoperformon4doubleprecisionoatingpointnumbersor8singleprecision.
Implementingtheseextensionsinthevectorizedpartsoflatticecodeshasthepotentialofprovidingagainofuptoafactor2inanidealsituation,althoughinprac-ticethisdependsonthelayoutoflatticedata.
Weprovidedanimplementationoftheseextensionsusinginlineintrinsics.
InthisimplementationasingleSU(3)matrixmultipliestwoSU(3)vectorssimultaneously.
Againofaboutafactorof1.
5isachievedforthehoppingmatrixinthetmLQCDcodeindoubleprecisionasshowninFig.
(4).
Forillustration,acodesnippetformultiplyingtwocomplexnumbersbytwocomplexnumbersusingAVXisshowninFig.
(5).
3.
EigCGsolverforTwisted-MassfermionsTwisted-MassfermionsoffertheadvantageofautomaticO(a)improvementwhentunedtomaximaltwist[12].
Withinthisdevelopmentworkwehaveaddedanincrementaldeationalgo-rithm,knownasEigCG,tothetmLQCDpackage.
Numericaltestsshowedaconsiderablespeed-upofthesolutionofthelinearsystemsonthelargestvolumessimulatedbytheEuropeanTwistedMassCollaboration(ETMC).
Forillustration,weshowinFig.
(6)thetimetosolutionwithEigCGonaTwisted-Masscongurationwith2+1+1dynamicalavorswithlatticesize483*96atβ=2.
1,andpionmass≈230MeV.
Inthiscasethetotalnumberofeigenvectorsdeatedwas300whichwasbuiltincrementallybycomputing10eigenvectorsduringthesolutionoftherst30right-handsidesusingasearchsubspaceofsize60.
Allsystemsaresolvedindoubleprecisiontorelativetoleranceof108.
5PLQCDA.
Abdel-RehimFigure4:Comparingtheperformanceofthehop-pingmatrixoftmLQCDusingSSE3andAVXindoubleprecisiononanIntelSandyBridgeprocessor.
#include/*t0:a+b*I,e+f*Iandt1:c+d*I,g+h*I*return:(ac-bd)+(ad+bc)*I,*(eg-fh)+(eh+fg)*I*/staticinline__m256dcomplex_mul_regs_256(__m256dt0,__m256dt1){__m256dt2;t2=t1;t1=_mm256_unpacklo_pd(t1,t1);t2=_mm256_unpackhi_pd(t2,t2);t1=_mm256_mul_pd(t1,t0);t2=_mm256_mul_pd(t2,t0);t2=_mm256_shuffle_pd(t2,t2,5);t1=_mm256_addsub_pd(t1,t2);returnt1;}Figure5:MultiplyingtwocomplexnumbersbytwocomplexnumberoftypedoubleusingAVXin-structions.
Figure6:Solutiontimeperprocessfortherst35right-handsidesusingIncrementalEigCGascomparedtoCGonaTwisted-Masscongurationwithlatticesize483*96atβ=2.
1,andpionmass≈230MeV.
4.
ConclusionsandSummaryWehavecarriedoutdevelopmenteffortforafewselectedkernelsusedinlatticeQCD.
TherstoftheseeffortsincludedthedevelopmentofahybridMPI/OpenMPlibrarywhichincludesparallelizedkernelsfortheWilsonDiracoperatorandfewassociatedsolvers.
Anumberofparal-lelizationstrategieshavebeeninvestigated,suchasforoverlappingcommunicationwithcomputa-tions.
ThecodehasbeenshowntoscalefairlywellontheCrayXE6.
Intermsofsingleprocessperformance,wecarriedoutinitialvectorizationeffortsforAVXwhereweseeanimprovementof1.
5comparedtotheideal2.
Inadditionwehaveinvestigatedseveraldata-orderingandassociatedprefetchingstrategies.
ForthecaseoftmLQCD,themainsoftwarecodeoftheETMCcollaboration,wehaveimple-6PLQCDA.
Abdel-Rehimmentedanefcientlinearsolverwhichincrementallydeatedthetwisted-massDiracoperatortogiveaspeed-upofabout3timeswhenenoughright-hand-sidesarerequired.
Thisisalreadyinuseinproductionprojects,suchasinRefs.
[14]and[13].
Allcodesarepubliclyavailable.
PLQCDisavailablethroughtheHPCFORGEwebsiteattheSwissNationalSupercomputingCentre(CSCS)wheremoreinformationisavailablewithinthecodedocumentation.
OurEigCGimplementationintmLQCDisavailableviagit-hub.
AcknowledgementsThistalkwasapartofacodingsessionsponsoredpartiallybythePRACE-2IPproject,aspartofthe"CommunityCodesDevelopment"WorkPackage8.
PRACE-2IPisa7thFrameworkEUfundedproject(http://www.
prace-ri.
eu/,grantagreementnumber:RI-283493).
Wewouldliketothanktheorganizersofthe2013Latticemeetingfortheirstrongsupporttomakethecodingsessionasuccessandprovideallorganizationsupport.
WewouldliketothankC.
Urbach,A.
Deuzmann,B.
Kostrzewa,HubertSimma,S.
Krieg,andL.
Scorzatoforverystimulatingdiscussionsduringthedevelopmentofthisproject.
WeacknowledgethecomputingresourcesfromTier-0machinesofPRACEincludingJUQUEENandCuriemachinesaswellastheTodimachineatCSCS.
WealsoacknowledgethecomputingsupportfromNERSCandtheHoppermachine.
References[1]http://www.
prace-ri.
eu/.
[2]K.
JansenandC.
Urbach,Comput.
Phys.
Commun.
180,2717(2009),[arXiv:0905.
3331].
[3]ETMCollaboration,https://github.
com/etmc/tmLQCD.
[4]http://usqcd.
jlab.
org/usqcd-docs/chroma/.
[5]SeethepublicdeliverableD8.
3onthePRACEwebsiteunderPRACE-2IP.
[6]A.
Deuzeman,PoS(LATTICE2013).
[7]SeetheIntelDevelopermanual.
[8]A.
StathopoulosandK.
Orginos,Computinganddeatingeigenvalueswhilesolvingmultipleright-handsidelinearsystemswithanapplicationtoquantumchromodynamics,SIAMJ.
Sci.
Comput.
2010;32(1):439–462,[arXiv:0707.
0131].
[9]SeeforexamplethedocumentationoftheDDHMCcodebyM.
L¨uscher.
[10]TheHopperCrayXE6machineatNERSC.
[11]SeedocumentationforcombiningMPIandopenMPontheNERSCwebsite.
[12]R.
Frezzottietal.
[AlphaCollaboration],LatticeQCDwithachirallytwistedmassterm,JHEP0108,058(2001)[hep-lat/0101001].
[13]C.
Alexandrou,M.
Constantinou,S.
Dinter,V.
Drach,K.
Hadjiyiannakou,K.
Jansen,G.
KoutsouandA.
Vaquero,arXiv:1309.
7768[hep-lat].
[14]A.
Abdel-Rehim,C.
Alexandrou,M.
Constantinou,V.
Drach,K.
Hadjiyiannakou,K.
Jansen,G.
KoutsouandA.
Vaquero,arXiv:1310.
6339[hep-lat].
7
- casesandybridge相关文档
- E5sandybridge
- PenguinComputingClustersandybridge
- cumulativesandybridge
- 5.sandybridge
- 希捷sandybridge
- layerssandybridge
LOCVPS全场8折,香港云地/邦联VPS带宽升级不加价
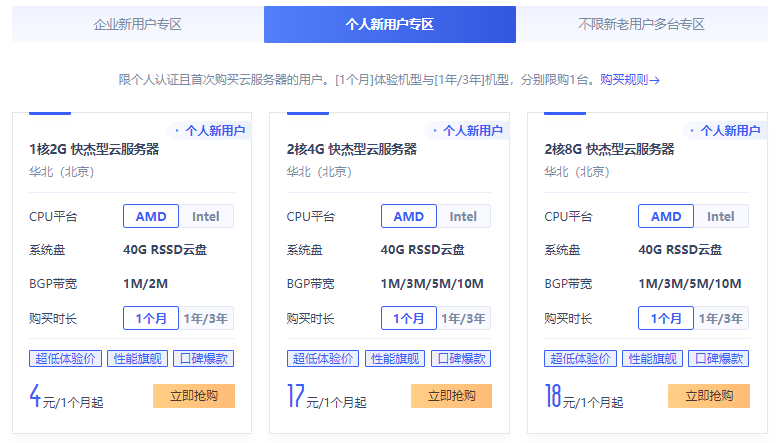
LOCVPS发布了7月份促销信息,全场VPS主机8折优惠码,续费同价,同时香港云地/邦联机房带宽免费升级不加价,原来3M升级至6M,2GB内存套餐优惠后每月44元起。这是成立较久的一家国人VPS服务商,提供美国洛杉矶(MC/C3)、和中国香港(邦联、沙田电信、大埔)、日本(东京、大阪)、新加坡、德国和荷兰等机房VPS主机,基于XEN或者KVM虚拟架构,均选择国内访问线路不错的机房,适合建站和远程办...
UCloud新人优惠中国香港/日本/美国云服务器低至4元
UCloud优刻得商家这几年应该已经被我们不少的个人站长用户认知,且确实在当下阿里云、腾讯云服务商不断的只促销服务于新用户活动,给我们很多老用户折扣的空间不多。于是,我们可以通过拓展选择其他同类服务商享受新人的福利,这里其中之一就选择UCloud商家。UCloud服务商2020年创业板上市的,实际上很早就有认识到,那时候价格高的离谱,谁让他们只服务有钱的企业用户呢。这里希望融入到我们大众消费者,你...
HostKvm开年促销:香港国际/美国洛杉矶VPS七折,其他机房八折
HostKvm也发布了开年促销方案,针对香港国际和美国洛杉矶两个机房的VPS主机提供7折优惠码,其他机房业务提供8折优惠码。商家成立于2013年,提供基于KVM架构的VPS主机,可选数据中心包括日本、新加坡、韩国、美国、中国香港等多个地区机房,均为国内直连或优化线路,延迟较低,适合建站或者远程办公等。下面列出几款主机配置信息。美国洛杉矶套餐:美国 US-Plan1CPU:1core内存:2GB硬盘...
sandybridge为你推荐
-
microcenter美国哪里可以买插头转换器摩根币摩根币是怎么骗人的?刘祚天还有DJ网么?陈嘉垣陈浩民、马德钟强吻女星陈嘉桓,求大家一个说法。丑福晋爱新觉罗.允禄真正的福晋是谁?他真的是一个残酷,噬血但很专情的一个人吗?同ip站点同IP网站具体是什么意思,能换独立的吗lcoc.topeagle solder stop mask top是什么层www.diediao.com跪求鸭王2关键词分析如何进行关键词指数分析国风商讯国风快胃片多少钱