爬虫下一代互联网技术-2015试卷李楚煌.doc
学院专业姓名学号座号
(密封线内不答题)
„„„„„„„„„„„„„„„„„„„„
密„„„„„„„„„„„„„„„„„„封„„„„„„„„„„„„„„„
线„„„„„„„„„„„„„„线„„„„„„„„„„„„„„„
_____________ ________
„
深圳大学期末考试试卷
命题人(签字) 崔来中 审题人(签字) 年 月 日
《下一代互联网技术》课程综述报告要求
1.课程综述报告由个人独立完成。
2.要求学生从教师的授课专题包括
1 下一代互联网过渡技术翻译技术和隧道技术
2 云计算资源调度、存储、安全
3 社交网络推荐、影响力分析、传播模型
4 物联网无线传感器网络、节能技术
5 搜索技术爬虫技术、 图片搜索、语义搜索
6 P2P 文件下载、流媒体分发
7 大数据处理与分析技术网络与机器学习
8 多媒体网络多媒体网络与SDN、流媒体与机器学习
9 软件定义网络SDN与安全、 SDN与流量优化、 SDN与网络管理
选择一个专题中的具体技术问题上述括号内为推荐的问题内容作为综述报告主题综述报告名称自拟参照附件一“综述报告格式模板”与附件二“综述报告写作指导完成综述报告” 评分标准见附件三。
3.提交的课程综述报告要符合深圳大学相关的格式规范。
4.第17周提交课程综述报告电子版到blackboard系统纸质版交到任课老师处。
附件一综述报告格式模板
深圳大学考试答题纸
(以论文、报告等形式考核专用)
二○一 二○一 学年度第 学期
1.前言
在21世纪互联网高速发展的背景下搜索引擎在人们生活中有着举足轻重的作用而网络爬虫是搜索引擎中的重要的信息采集器是搜索引擎技术的核心部分。
本文是对爬虫技术在现今网络环境中出现不同的问题、漏洞提出一些针对性的探究方法并对各种方法进行实验分析主要研究分析工作如下:
网络爬虫中的核心技术部分 即网络爬虫系统的多线程设计与实现详细介绍网络爬虫的概念及信息分类涉及到的算法技术要点并探讨实现对漏洞平台当中的爬虫技术的聚焦。
网络爬虫的核心在于 以端口接通为设计基础依据HTTP协议使用SOCKET套接字相关函数向服务器端发送HTTP请求得到目标URL对应的网页内容再从该网页提取出未爬取过的URL将该URL重新作为源URL进行新的一轮向下爬取搜索工作按照各种优先算法向下爬行从而完成网络爬虫系统的爬行工作。
在互联网中有着很多协议它们彼此联系着支持着许多网络程序的运行。网络爬虫系统是基于SOCKET协议的而SOCKET协议的基础建立在TCP/IP协议之上。 由此 网络爬虫是基于最原始的协议依靠算法技术组织分布式系统非常
有潜力进行强有力的数据探索与挖掘。既然网络爬虫的优势潜能如此巨大接下来我会详细讨论近期我对这个技术的若干研究。
2. 阅读文献概述
基于此次希望探讨的研究方向 网络爬虫在中文文献方面主要有以下阅读多线程进行网络爬虫的过程优化,基于网络爬虫的Web信息采集技术爬虫对漏洞管理平台核心帮助。在英文文献方面主要有 《A Cloud-based Web CrawlerArchitecture》 , 《A Spatial Web Crawler for Discovering》 , 《Design ofimproved focused web crawler》 。这几篇文献探究的层次在于如何对信息进行有效地采集、采集的量如何够快够大、 以漏洞管理平台为切口看爬虫技术有哪方面的发展潜力。
多线程爬虫又可以理解为分布式爬虫主要阅读的部分有分布式网络爬虫结构设计其中又细分为爬行节点的结构设计控制节点的结构设计。分布式网络爬虫的关键技术在于种子集合的优化选取分布函数的选择。有这些分布式策略来带领多线程下载。而对网络信息的阅读在于有效采集需要对信息检索引擎有所划分全文检索、 目录索引型检索、元检索。再深入到网络爬虫的搜索策略有深度优先搜索策略、宽度优先搜索策略、聚焦搜索策略。针对信息的实质内容爬虫有其特色性质布告栏的数据分类及并联式关联、视频的可预览及真实寻址、论坛的自动动态更新实现。对漏洞平台的爬虫聚焦技术的阅读首先了解的是在漏洞平台这个领域爬虫子模块的划分爬虫接口模块、配置文件解析模块、 网页爬取模块、 网页解析模块、 URL过滤去重模块、漏洞信息保存模块。在漏洞平台管理这个框架下对爬虫效率如何改进、 URL相关内容如何改进有所阅读了解。
此外 《A Cloud-based Web Crawler Architecture》主要论述的网络爬虫为代表的应用程序如何在网络上更好得进行有趣的信息的查找。因为网路上有巨量的索引的链接或非结构化的数据这需要网络爬虫去应对这些挑战链接和高密度计算的复杂性。在这种背景下该文献提供了云计算模式支持弹性的资源化和非结构化的数据并提供读写加注功能。采用云计算的功能和MapReduce编程技
术可以使我们能够分布式抓取网页和存储在云计算中所发现的Azure表。 《ASpatial Web Crawler for Discovering》 这篇文献其实与单纯地谈论爬虫技术不一样一般地讨论爬虫技术是如何在物理、软件层面提高单体计算机的速度、分布式地进行搜索又或者对URL等算法策略的优化。而这篇文献谈论的可以归属另一个学科它围绕地缘服务器提供的地理特征进行空间信息的划分使用空间的数据源。核心来说这是一个对地理领域信息系统的研究。地理空间数据在本质上常常动态并在异构的形式提供 网上空间数据是一个基于地理的形式进行发布的。空间网络爬虫专注于地理空间在地缘服务器上的功能。 《Design of improvedfocused web crawler》这篇文献讲述的东西比较细是对URL和锚文本的语义性质的研究分析。它提出了一种技术偏重于基于语义重点的网络履带的分析探讨。
3.课题研究方向的现状与发展趋势
研究方向主要有以下六个分支:多线程分布式进行网络爬虫的过程优化,基于网络爬虫的Web信息采集技术爬虫对漏洞管理平台核心帮助云计算模式这种支持弹性的资源化和非结构化的数据的爬虫技术空间网络爬虫这样专注于地理空间在地缘服务器上研究的新科技锚文本的语义性质的研究分析。
分布式网络爬虫的理论基础它由多台PC机组成其中一台是控制节点其他为爬行节点控制节点负责维护所有结点的信息对所有结点的信息进行同步同时在控制节点上进行结点的添加和删除。它分为5个模块 URL分析模块、下载模块、 网页分析模块、结点通信模块、 URL分配模块。
分布式网络爬虫的方法可以具体到5个模块来分析探讨。 URL分析模块是接受来自分布式模块分配的URL任务判断该URL是否被访问过。访问过进队列没访问过忽略。那在分布式网络爬虫中与单台PC有所不同的是单台PC机只需要对URL地址进行记录还有域名转换计算复杂度低分布式网络爬虫中对需要IP与域名转换的计算量大复杂度高。下面具体解释维护URL队列在每个节点维护一个本节点将要访问的URL队列模块可以参照Mercator系统每一道指向一个domain这样可以避免多个线程同时访问一个domain。刚刚已经谈到计算
量大的问题是由于多道队列的数据结构在爬行进行到一定阶段时数据量一定分成庞大。如何解决在内存不能够承载时将队列的中间部分放在硬盘上在内存中只保留队列的头和尾。还有就是完整的URL是没必要记录的只需要判断URL是否已经下载过了。因此可以采用哈希表存储URL的checksums,高位存储hostname的checksum这样一来来自同样的domain的URL就会排列在一起。之前说过把数据放在硬盘上。这样实现建立一个LRU cache。 明显 网页链接的聚簇性和高位存储hostname的数据结构使硬盘的读写概率非常小提高了爬虫分布式系统的运行速度。 IP与域名需要转换是因为URL地址不同但可能指向同一物理网页。譬如多个域名共同拥有一个IP而各个域名下的内容是不同的DNS转换导致的同一域名对应的IP是不一样的一个站点多个域名。面多这种情况如何解决呢首先积累一定数量的域名和IP下载一些网页判断分别属于哪种情况积累下来然后针对性地取舍避免重复收集使用。下载模块的核心在于节点线程控制。主要解决的是本地节点与Web端服务器的通信问题。在前言中提到爬虫技术也是基于TCP协议的。客户有时在同一次会话中希望从服务器端下载更多的HTML页面 由于HTTP1.0该TCP需要终止。这是可以这样为了节省时间和网络带宽可以保留上次已经建立好的链接。如果该链接没有失效本次可以继续使用。详细点说就是服务器接收爬虫客户端发送的请求消息后先返回一个HTTP头信息包含文件类型大小最后修改时间等内容后续添加包含网页的文本内容。根据网页体的大小 申请内存空间准备接收有两种情况需要放弃接收一、 网页类型不符合要求。二、超出预定接收大小。毕竟我们现在讨论的是多线程的网络爬虫技术在下载模块重点在于结点线程模块。结点线程根据控制计算机硬件的运行情况把并行开设的线程数控制在一个最佳的数量上并监控保证同时访问同一个domain的线程数不超过n这样是为了保证web服务器不会出现类似于拒绝服务攻击DOS反应使得一些URL的漏取。最好建立一个DNS缓冲区即是缓存。这样可以避免频繁地查询DNS服务器。 网页分析模块相对简单 HTML比较灵活 URL出现的语境较多我们应该参照HTML的语法给出相应的URL出现的语境。 URL分配模块工作是为了协调各个节点将任务分配给不同的节点并且能够增删节点。节点通信模块负责节点间的相互通信除了采集器采集网页时直
接与Internet交互外其他时候所有网络通讯都通过通信器完成。上次模块通过Send把它的数据包以单体为目标标识发布。接收上层的发送请求后通信器先将数据包缓存起来再通过目标标识维护每个节点的节点号和IP对应的节点信息。有节点通信模块可以只关注本身的策略并且和其他模块松耦合方便架构在不同的对等网络上。
分布式网络爬虫的方案可以先讲述一个中级规模的网页搜集 当然对于一些大型的网站如凤凰网、腾讯首页等网站的全站下载分布式系统仍有用武之地。先了解下对中等规模的网站的爬虫搜集一个网站的host是一样的 因此需要在普通的任务分配基础上做出一些改动首先任务的粒度不能再选择host 因为这样一来 同一网站的网页的哈希函数的数值是唯一的任务只能分配在节点上对于分布式网络爬虫系统显然是不行的。粒度如果按URL分配粒度又太小了 由此可以对网站的URL信息收集和分析总结出网站全站下载多机协同任务分配算法。举例说明大型网站下有很多子网站而同一子网站网页的URL有一些共同点它们的URL前一两个字都相同这些子网页的互联关系比较紧密子网站与子网站网页的引用频繁度没有那么高差别较大可以把任务分配的粒度定为子网站。 由于粒度的合理分配分布式对中大型网站进行全站下载是可实现的。
关于分布式网络爬虫技术的现状 国内外的一些大公司已经有很成熟的解决方案并已投入使用。其中以Google研究的最早也最先进。在Google公开的网络爬虫设计中 Internet Archive Crawler是可以使用多台机器进行爬行的每个Crawler进程可分配64个站点同时爬行每个站点只分配一个Crawler进行爬行。谷歌的分布式网络爬虫技术能够在全球处于领先地方也在于它的搜索引擎在全球处于领先地位。 Google每天都会对使用它搜索引擎的网站进行一定量的爬虫有了大量的数据分析它对于网络上的语义分析是领先的而在全球大量分布的服务器也促进了它在分布式网络爬虫的发展。其中它研发的Mercator是一个非常出色的Crawler该技术完全用Java实现它才用的数据结构可以不管爬行规模的大小在内存只占有限的空间。分布式网络爬虫现阶段采用的技术主要是服务器集群技术 由中央控制软件进行任务发布、负载平衡和运行监控。
- 爬虫下一代互联网技术-2015试卷李楚煌.doc相关文档
- 待定下一代互联网
- 互联网下一代互联网
- 互联网下一代互联网
- 互联网下一代互联网
- 证监会审核华创证券投资咨询业务资格批文号:证监许可(2009)1210
- 邬贺铨在3月9日香港"下一代互联网会议"上的报告题目:
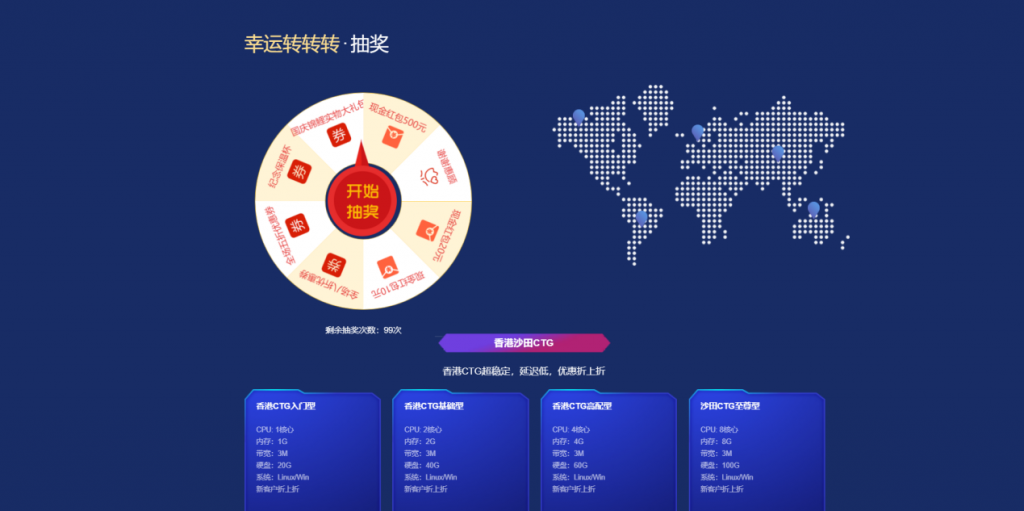
美国G口/香港CTG/美国T级超防云/物理机/CDN大促销 1核 1G 24元/月
[六一云迎国庆]转盘活动实物礼品美国G口/香港CTG/美国T级超防云/物理机/CDN大促销六一云 成立于2018年,归属于西安六一网络科技有限公司,是一家国内正规持有IDC ISP CDN IRCS电信经营许可证书的老牌商家。大陆持证公司受大陆各部门监管不好用支持退款退现,再也不怕被割韭菜了!主要业务有:国内高防云,美国高防云,美国cera大带宽,香港CTG,香港沙田CN2,海外站群服务,物理机,...
HostYun(月18元),CN2直连香港大带宽VPS 50M带宽起
对于如今的云服务商的竞争着实很激烈,我们可以看到国内国外服务商的各种内卷,使得我们很多个人服务商压力还是比较大的。我们看到这几年的服务商变动还是比较大的,很多新服务商坚持不超过三个月,有的是多个品牌同步进行然后分别的跑路赚一波走人。对于我们用户来说,便宜的服务商固然可以试试,但是如果是不确定的,建议月付或者主力业务尽量的还是注意备份。HostYun 最近几个月还是比较活跃的,在前面也有多次介绍到商...
legionbox:美国、德国和瑞士独立服务器,E5/16GB/1Gbps月流量10TB起/$69/月起
legionbox怎么样?legionbox是一家来自于澳大利亚的主机销售商,成立时间在2014年,属于比较老牌商家。主要提供VPS和独立服务器产品,数据中心包括美国洛杉矶、瑞士、德国和俄罗斯。其中VPS采用KVM和Xen架构虚拟技术,硬盘分机械硬盘和固态硬盘,系统支持Windows。当前商家有几款大硬盘的独立服务器,可选美国、德国和瑞士机房,有兴趣的可以看一下,付款方式有PAYPAL、BTC等。...
-
操作http小企业如何做品牌小公司的品牌建设怎么样才能做好thinksnsthinksns 好用吗?靠谱吗accessdenied升级后出现Access denied 如何解决进入查看空间文章qq空间日志文章,要求经典outlookexpress如何开启OUTLOOK EXPRESS功能?美要求解锁iPhone如何看美版苹果是有锁无锁科创板首批名单2019年房产税试点城市名单zhuo爱大涿爱— 金鱼花火 、 歌词给我翻译过来。!即时通如何使用即时通啊