样本加快网速的方法
加快网速的方法 时间:2021-05-20 阅读:()
逻辑回归上的反拉加速方法TheCounterPullAccelerationMethodforLogisticRegression何沧平微博cangping@sta.
weibo.
com2018年3月12日摘要本文通过严格数学分析找出了逻辑回归过拟合的成因:边界样本的损失贡献比重大且随法向量增长而加速增大、边界样本分布散乱,顺便理清了正则项的作用机理.
利用过拟合机制,本文提出一种反拉方法,既能缓解过拟合,又能减少训练步数,在MNIST数据集上实现加速38.
25倍,在CIFAR10数据集上实现加速5.
61倍.
Inthispaper,Ifoundthetworeasonsofoverttingoflogisticregression:boundarysamplesoccupyalargerandlargershareasthelengthofnormalvectorbecomeslongerandlonger,boundarysamplesdonotttheirprobabilitydensityfunctionwell.
Withthehelpofinsightinovertting,Iproposeaaccelerationmethodforlogisticregressionandgotatrainingspeedupof38.
25onMNISTdataset,atrainingspeedupof5.
61onCIFAR10dataset.
关键字:逻辑回归,过拟合解释,反拉加速1引言逻辑回归(LogisticRegression)是机器学习的一个基础分类方法[1].
它形式简单,有LIBLIN-EAR[2]这样的工具库,工程实现方便,在互联网推荐系统中有广泛的应用.
各大公司有成千上万台服务器在一刻不停地训练逻辑回归模型,如果能保证正确率的前提下大幅提高训练速度,那么将能节省大量运营成本.
目前提高训练速度的主要手段是样本预处理和设计更好的最优化算法.
一个有效的样本预处理方法是按分量白化[3];可用的最优化算法有很多,常用的是梯度下降法的多种变体[4],例如随机梯度法、Momentum算法、Nesterovacceleratedgradient算法、Adagrad算法、Adadelta算法,等等;还有DFP、BFGS、L-BFGS等拟牛顿算法[6],以及速度更快的信赖域算法[7];并行化的最优化算法[5]也能提高训练速度.
1chinaXiv:201803.
00428v12逻辑回归2过拟合是计算学习的关键障碍,通常的解释是模型过于复杂[1,8],要用相对简单的模型来缓解过拟合现象;至于过拟合的成因,可用"偏差-方差分解"[1,9]来解释,[10]还讨论了过拟合与噪声、多重假设检验的关系.
缓解过拟合的常用手段是添加正则化项,[8]对比了L1正则化和L2正则化的特点.
本文的初衷是探究逻辑回归过拟合的形成机制,因为模型已经确定,所以无法再用"模型过于复杂"这样的理由来解释.
因此跳出常规的概率视角,用Taylor展开分析交叉熵后发现,逻辑回归过拟合的原因有两个:边界样本的损失贡献比重大且随法向量增长而加速增大、边界样本分布散乱.
虽然法向量过大只是过拟合的表象,但是控制法向量模长却能够切实缓解过拟合,因此各种正则化手段有效.
利用对过拟合机制的洞察,本文提出一种反拉方法:修改各个样本在交叉熵损失函数中的贡献比重,提高被分错样本的损失贡献,能够减少提高逻辑回归的训练次数;降低被分错样本的损失贡献,能够减缓过拟合.
为了保证交叉熵的数值稳定性,顺便提出一种近似计算方法.
在手写数字数据集MNIST[12]上,反拉方法将训练速度提高38.
25倍;在CIFRA10数据集上,反拉方法将训练速度提高5.
61倍.
本文后续内容这样组织.
第2节给出逻辑回归公式,为后文公式推导做准备;第3节给合实例和公式推导给出过拟合的2个原因;第4节给出反拉方法;第5节是数值实验,验证反拉方法的加速性能和缓解过拟合的效果.
2逻辑回归给定数据集D={(x1,y1),(x2,y2)xm,ym)},其中d为正整数,列向量xi=(xi1;xi2;xid),标量yi∈{0,1}.
当yi=0时称xi是负样本,当yi=1时称xi是正样本.
二分类问题是要从数据集D中学习到一个模型,然后用这个模型预测任意的样本xj是正样本还是负样本.
逻辑回归的任务是从给定数据集D中学习到分隔面的斜截式方程wTx+b=0,|w|=0(1)确定其中的法向量w和截距b值.
这里的w是列向量,记为w=(w1;w2;wd),b是标量.
任意平面都可以用做分隔面,区别只是推测效果可能不同.
为了寻找分隔面(1),对xi∈D,令zi=wTxi+b,按照[11]中定义,zi为点xi到分隔面(1)的加权距离.
定义单个样本xi上的损失函数l(zi)=ln(1σ(zi)),如果yi=0,ln(σ(zi)),如果yi=1,(2)这里的σ(z)为Sigmoid函数σ(z)=11+ez.
将样本集D上的损失函数定义为L(w,b)=1mm∑i=1l(zi),chinaXiv:201803.
00428v13过拟合实例与成因3图1:线性可分样本集上的过拟合图2:线性可分样本集上的正确率求解它的最小值{w,b}=argminw,bL(w,b),(3)就得到了最优参数w和b,代入(1)即得最优分隔面wTx+b=0.
对任意样本xj,用最优分隔面来推测它归属的类别.
令yj=0,如果wTxj+bln(σ(0)).
当xi为负样本时,情况类似.
从图5中可以直观地看到,相对于被正确分类的样本,被错误分类的样本对损失函数的贡献更大.
为了定量分析样本对损失函数的贡献,需要用Taylor公式寻找l(zi)的简单近似函数.
为此定义两个函数f0(z)=ez,如果zC0>0,(6)f1(z)=zez,如果zC0>0,(7)这里的C0是任意指定的正实数.
chinaXiv:201803.
00428v13过拟合实例与成因6定理1.
函数f0(z)是ln(1σ(z))的近似,函数f1(z)是ln(σ(z))的近似.
证.
先证明f0(z)是ln(1σ(z))的近似.
当zC0时,ezC0时,ezl(z2),即推论1.
样本的加权距离越小,损失贡献越大.
chinaXiv:201803.
00428v13过拟合实例与成因7给定C0>0.
当z11,记z1=wT2(x1c)和z2=wT2(x2c),那么有l(z1)l(z2)=l(sz1)l(sz2)≈f1(sz1)f1(sz2)≈sz1esz1sz2esz2≈z1z2≈l(z1)l(z2),(8)由式(8)得推论2.
被分错样本之间的损失贡献比例不随法向量的变化而变化.
给定C0>0.
当C01,记z1=wT2(x1c)和z2=wT2(x2c),那么有l(z1)l(z2)=l(sz1)l(sz2)≈f1(sz1)f1(sz2)≈esz1esz2=exp(s(z2z1))=(exp(z2z1))s,(9)由式(9)得推论3.
被分对样本之间的损失贡献比例会随着法向量的增长而指数级增长.
给定C0>0.
当z2>C0且z1=z2时,x1和x2分别位于分隔面wT(xic)=0的背面和正面,即一个被分错了另一个被分对了.
假设w2=sw,其中实数s>1,记z1=wT2(x1c)和z2=wT2(x2c),那么有l(z1)l(z2)=l(sz2)l(sz2)≈f1(sz2)f1(sz2)≈sz2+exp(sz2)exp(sz2)=1+sz2exp(sz2),(10)由式(10)得推论4.
被分错样本与被分对样本之间的损失贡献比例会随着法向量的增长而指数级增长.
将分隔面附近样本称为边界样本.
从推论1推论4可知,对损失函数的贡献比例,由大到小分顺序是:被分错的样本、被分对的边界样本、被分对的其它样本,它们之间的比例关系随着法向量的增长而迅速增大.
适用逻辑回归的数据集,被最优分隔面分错的样本占比不大,这样被分错的样本通常会在分隔面附近.
考虑到,在线性可分数据集上,法向量模长|w|趋向无穷大[11],分隔平面几乎完全由边界样本决定.
在线性不可分数据集上,法向量模长|w|有界[11],但最优分隔面的法向量模长可能仍然很大,过拟合仍然严重.
因此得出过拟合原因之一:边界样本的损失贡献比重大且随权重增长而加速增大.
自然界很多事件服从正态分布,例如图6,中心处样本密度大,能够很好在逼近其概率密度函数;在远离中心的边缘处,概率密度函数的值较小,样本稀疏,不能很好地反映其概率密度函数.
考虑到训练集边界样本基本决定分隔平面,而测试集样本的实际分布与训练集会有一些差异,所以得到的分隔平面不能很好地分隔训练集.
因此得到过拟合的原因之二:边界样本分布散乱.
第3节的2个过拟合例子都是根据这2个原因设计出来的.
chinaXiv:201803.
00428v14反拉加速8图6:一个服从正态分布的样本集3.
4正则化的作用机理缓解过拟合的常用手段是添加正则化项,各种各样的正则化方法的目标都是一致的:控制法向量的模长,不让|w|过大.
由过拟合的成因可知,虽然法向量过大只是过拟合的表象,不是根本原因,但限制它的模长确实有效缓解了过拟合,这是因为它限制了边缘样本的损失贡献比重.
正则化缓解过拟的同时,必然会降低训练集上的正确率.
从过拟合成因还可以知道缓解过拟合的另一个思路:修整边界样本使之准确反映概率密度函数.
教科书[1]中已经写明增加样本数量能缓解过拟合,其实也可以用边界样本散乱的观点来解释:增加样本总量,边界样本数量也同比例增加,从而边界样本更好地反映其概率密度函数,从而缓解过拟合.
4反拉加速图5画出了单个正样本(红色)和单个负样本(蓝色)的损失曲线.
直观地理解,如果样本集是线性可分的,那么正样本对应的zi越大,该样本上的损失函数值越小;负样本对应的zi越小,该样本上的损失函数值越小.
从而,在式(3)的计算过程中,负样本向zi负无穷方向移动,正样本向zi正无穷方向移动,达到了分类的目的.
从过拟合成因的分析过程可知,对给定的w和b,被错误分类的样本的损失贡献比重大,从而能优先减少分错样本的数量.
为了更快速地找到最优分隔面,索性进一步提高被分错样本的损失贡献,让错误更猛烈一些.
chinaXiv:201803.
00428v14反拉加速94.
1反拉方法定义半正定(POsitiveSemidenite)函数pos(z)=0,如果z0.
加权距离的计算方法保持不变,即zi=wTxi+b.
对加权距离进行反拉变换,得到Zi=zi+λpos(zi),如果yi=0,zi+λnes(zi),如果yi=1,这里的λ称为反拉系数,取值范围是(1,+∞).
将损失函数(2)替换为h(zi)=ln(1σ(Zi)),如果yi=0,ln(σ(Zi)),如果yi=1,从而样本集D上的损失函数为H(w,b)=1mm∑i=1h(zi).
求解它的最小值{w,b}=argminw,bH(w,b),(11)就得到了最优参数w和b.
由式(4.
1)(4.
1)知,在λ=0时,h(zi)=l(zi).
图7中对比了逻辑回归损失函数l(z)和反拉后的损失函数h(z),可以看到,当λ>0时,对被分错的样本,反拉后的损失更大了;当10.
反拉加速只用于训练,不用于推测.
一旦得到最优分隔面参数w和b,仍然使用式(4)来推测样本的类别.
4.
2损失函数的数值稳定性使用反拉方法后,对给定的正样本xi、法向量w和截距b,如果zi<0,那么λ越大σ(Zi)越接近于0,损失函数ln(σ(Zi))的数值计算越不稳定,很容易超出计算机的表示范围,得到结果NaN(NotANumber).
负样本的情形类似.
为了保持数值稳定,同时减少一点计算量,用式(6)近似计算式(4.
1)中的ln(1σ(Zi)),用式(7)近似计算式(4.
1)中的ln(σ(Zi)).
式(6)(4.
1)中的常数C0可以根据精度要求取值,例如C0=4.
3时,近似值与精确值之间的误差小于0.
0001.
chinaXiv:201803.
00428v15数值实验115数值实验反拉方法的设计目标是减少迭代次数,降低训练成本,额外收获是能够缓解过拟合.
反拉方法的本质是调整了各个样本的损失比重,不涉及正则项和最优化算法,因此只需要在最优化算法、正则项相同的情况下对比逻辑回归在使用反拉方法前后的性能.
MNIST数据集和CIFAR10数据集分别包含了10类样本,恰好可以任取2类样本组合起来测试反拉方法的性能.
5.
1加速MNIST训练手写数字数据集MNIST[12]包含0-9这个10个数字的图片,图片大小为28*28,将2维单色图像拉平制作为1维向量.
取任意两个数字的图片分别作为负样本、正样本进行训练,组合顺序依次为0-1、0-2、.
.
.
、0-9、1-2、1-3、.
.
.
、1-9、.
.
.
、7-8、8-9,一共45种组合.
每种组合训练10次,然后训练下一种组合,共计训练450次.
训练使用负梯度下降法,步长指定为0.
01,无正则化项,w的初值从均匀分布U(1/√784,1/√784)中随机选取,b的初值为0.
最大迭代步数设为20000,LR最大正确率对应的迭代步数(称为LR最优迭代步数),FLR迭代时到达LR最大正确率花费的迭代步数称为FLR最优迭代步数,如图8如示,用LR的最优迭代步数除以FLR的最优迭代步数就得到加速倍数,如图9所示.
加速倍数为1意味着没有加速,加速倍数大于1意味有加速.
从图9看出,加速倍数在13.
1087.
22之间,平均值为38.
25.
反拉方法在训练集和测试集上正确分别为99.
23%和98.
82%,相对于未反拉时正确率的提升见图10,训练集上平均提高0.
51%,测试集上平均提高0.
14%.
5.
2加速CIFAR10训练手写数字数据集CIFAR10[13]包含10类彩色图片,图片大小为32*32,将2维彩色图像拉平制作为1维向量.
取任意两类图片分别作为负样本、正样本进行训练,组合顺序依次为1-2、1-3、.
.
.
、1-10、2-3、2-4、.
.
.
、2-10、.
.
.
、8-9、9-10,一共45种组合.
每种组合训练10次,然后训练下一种组合,共计训练450次.
训练使用负梯度下降法,步长指定为0.
0001,无正则化项,w的初值从均匀分布U(1/√3072,1/√3072)中随机选取,b的初值为0.
最大迭代步数设为20000,最优迭代步数如图11如示,加速倍数如图12所示.
加速倍数在1.
809.
06之间,平均值为5.
61.
反拉方法在训练集和测试集上正确率均值分别为81.
69%和81.
00%,相对于未反拉时正确率的提升见图10,训练集上平均提高2.
52%,测试集上平均提高2.
06%.
图11图13中未显示正确率出现大幅震荡的组合.
5.
3控制过拟合在3.
1节的例子上应用反拉方法,取λ=0.
9,法向量初始值为w=(1/√2;1/√2),截距b=0,初始分隔线如图14中黑线所示.
用负梯度下降法迭代求解式(11),迭代步长指定chinaXiv:201803.
00428v15数值实验12图8:在MNIST上,LR最大正确率对应的训练次数,横轴是各个组合的编号.
LR表示未用反拉加速,FLR代表使用了反拉加速.
图9:在MNIST上,反拉方法获得的加速倍数.
图10:在MNIST上,反拉方法对正确率的影响.
chinaXiv:201803.
00428v15数值实验13图11:在CIFAR10上,LR最大正确率对应的训练次数,横轴是各个组合的编号.
图12:在CIFAR10上,反拉方法获得的加速倍数.
图13:在CIFAR10上,反拉方法对正确率的影响.
chinaXiv:201803.
00428v15数值实验14图14:线性可分训练集上,λ=0.
9时反拉方法的训练效果.
图15:在线性可能分训练集上,最优法向量w随λ的变化情况,右上角的+号代表13个相互接近的点.
为0.
1,前后两步迭代的损失函数值小于=106时停止迭代.
洋红色虚线是迭代1281步后的分隔线,洋红色实直线是迭代2561步后停止时的最优分隔线.
最优分隔线的斜截式方程为4.
1066x1+0.
0718x2+1.
5237*1017=0,调整系数后的等价方程为x1+0.
0175x2+3.
7105*1018=0,与人眼观察的理想分隔线x1=0很接近.
此时,反拉方法有效缓解了过拟合.
在3.
1节的例子上应用反拉方法,λ在区间[1,1]上均匀取21个值,迭步长指定为0.
1,前后两步迭代的损失函数值小于=106时停止迭代.
将所得的21个最优法向量w绘制出来,得到图15.
黑色带箭头直线是λ=1时得到w,洋红色带箭头直线是λ=1时得到w,折线上的+号对应λ∈(1,1)时得到的w.
注意,这个线性不可分样本集的理想分隔线是x1=0,它的法向量w=(1;0).
从图15知,λ=0.
9时的法向量方向与理想法向量最接近,随着λ的增大,最优法向量与理想法向量的夹角越来越大,过拟合起来越严重.
这个实验证明,反拉系数λ能够控制线性可分数据集上的过拟合.
在3.
2节的例子上应用反拉方法,取λ=0.
8,法向量初始值为w=(1/√2;1/√2),截距b=0,初始分隔线如图16黑线所示.
用负梯度下降法迭代求解式(11),迭代步长指定为0.
1,前后两步迭代的损失函数值小于=106时停止迭代.
洋红色虚线是迭代1057步后的分隔线,洋红色实直线是迭代2116步后停止时的最优分隔线.
最优分隔线的斜截式方程为3.
8356x10.
0140x2+0.
0208=0,调整系数后的等价方程为x10.
0037x2+0.
0054=0,与人眼观察的理想分隔线x1=0很接近.
此时,反拉方法有效缓解了过拟合.
在3.
2节的例子上应用反拉方法,λ在区间[1,1]上均匀取21个值,代步长指定为0.
1,前后两步迭代的损失函数值小于=106时停止迭代.
将所得的21个最优法向量w绘制出来,得到图17.
黑色带箭头直线是λ=1时得到w,洋红色带箭头直线是λ=1时得到w,折线上的+号对应λ∈(1,1)时得到的w.
注意,这个线性不可分样本集的理想分隔线是x1=0,它的法向chinaXiv:201803.
00428v16总结与展望15图16:线性不可分训练集上,λ=0.
8时反拉方法的训练效果.
图17:在线性不可能分训练集上,最优法向量w随λ的变化情况.
量w=(1;0).
从图17,λ=0.
8时的法向量方向与理想法向量最接近,随着λ的增大,最优法向量与理想法向量的夹角越来越大,过拟合起来越严重.
这个实验证明,反拉系数λ能够控制线性不可分数据集上的过拟合.
6总结与展望本文用严格数学分析来解释逻辑回归过拟合现象,进而得到了加速训练过程的反拉方法和保证交叉熵数值稳定的近似方法.
由过拟合原因的推导过程知道,反拉加速会导致更加严重的过拟合,必须采取应对措施.
可以添加常规的正则项,也可以将反拉系数逐渐减至0以下.
根据数值实验经验,反拉系数λ过大时,正确率会降低,正确率曲线震荡.
在实际应用中,应首先保证正确率曲线平滑,再追求加速性能.
反拉方法的加速效果看起来与样本集有一定的关联,其间的作用机理需要进一步研究.
参考文献[1]周志华.
机器学习.
清华大学出版社,2016.
4[2]R.
-E.
Fan,K.
-W.
Chang,C.
-J.
Hsieh,X.
-R.
Wang,andC.
-J.
Lin.
LIBLINEAR:AlibraryforlargelinearclassicationJournalofMachineLearningResearch9(2008),1871-1874.
[3]SimonWiesler,HermannNey.
AConvergenceAnalysisofLog-LinearTraining.
AdvancesinNeuralInformationProcessingSystems,2011:657-665chinaXiv:201803.
00428v1参考文献16[4]SebastianRuder.
Anoverviewofgradientdescentoptimizationalgorithms.
arXiv:1609.
04747[cs.
LG][5]BrendanH.
,HoltG.
,SculleyD.
,YoungM.
,EbnerD.
,GradyJ.
,NieL.
,Phillips.
T,DavydovE.
,GolovinD.
,ChikkerurS.
,LiuD.
,WattenbergM.
,HrafnkelssonA.
,BoulosT.
,KubicaJ.
(2013)AdClickPrediction:aViewfromtheTrenches.
Proceedingsofthe19-thKDD.
[6]G.
AndrewandJ.
Gao.
Scalabletrainingofl1-regularizedlog-linearmodels.
InProceedingsofthe24thinternationalconferenceonMachinelearning,ICML'07,pages33–40,NewYork,NY,USA,2007.
ACM.
[7]C.
-J.
LinandJ.
J.
More.
Newton'smethodforlargebound-constrainedoptimizationprob-lems.
SIAMJ.
onOptimization,9(4):1100–1127,Apr.
1999.
[8]T.
Hastie,R.
Tibshirani,andJ.
Friedman.
TheElementsofStatisticalLearning,SecondEdi-tion:DataMining,Inference,andPrediction.
SpringerSeriesinStatistics.
Springer,0002-2009.
corr.
3rdedition,Feb.
2009.
[9]P.
Domingos.
Auniedbias-variancedecompositionanditsapplications.
InProceedingsoftheSeventeenthInternationalConferenceonMachineLearning,pages231–238,Stanford,CA,2000.
MorganKaufmann.
[10]PedroDomingos.
AFewUsefulThingstoKnowaboutMachineLearning.
CommunicationsoftheACM,Vol.
55No.
10,Pages78-87,2012.
[11]何沧平,对焦分类方法,[ChinaXiv:201711.
02399][12]YannLeCun,CorinnaCortes,ChristopherJ.
C.
Burges.
TheMNISTdatabaseofhandwrittendigits.
http://yann.
lecun.
com/exdb/mnist/[13]AlexKrizhevsky.
TheCIFAR-10dataset.
http://www.
cs.
toronto.
edu/kriz/cifar.
htmlchinaXiv:201803.
00428v1
weibo.
com2018年3月12日摘要本文通过严格数学分析找出了逻辑回归过拟合的成因:边界样本的损失贡献比重大且随法向量增长而加速增大、边界样本分布散乱,顺便理清了正则项的作用机理.
利用过拟合机制,本文提出一种反拉方法,既能缓解过拟合,又能减少训练步数,在MNIST数据集上实现加速38.
25倍,在CIFAR10数据集上实现加速5.
61倍.
Inthispaper,Ifoundthetworeasonsofoverttingoflogisticregression:boundarysamplesoccupyalargerandlargershareasthelengthofnormalvectorbecomeslongerandlonger,boundarysamplesdonotttheirprobabilitydensityfunctionwell.
Withthehelpofinsightinovertting,Iproposeaaccelerationmethodforlogisticregressionandgotatrainingspeedupof38.
25onMNISTdataset,atrainingspeedupof5.
61onCIFAR10dataset.
关键字:逻辑回归,过拟合解释,反拉加速1引言逻辑回归(LogisticRegression)是机器学习的一个基础分类方法[1].
它形式简单,有LIBLIN-EAR[2]这样的工具库,工程实现方便,在互联网推荐系统中有广泛的应用.
各大公司有成千上万台服务器在一刻不停地训练逻辑回归模型,如果能保证正确率的前提下大幅提高训练速度,那么将能节省大量运营成本.
目前提高训练速度的主要手段是样本预处理和设计更好的最优化算法.
一个有效的样本预处理方法是按分量白化[3];可用的最优化算法有很多,常用的是梯度下降法的多种变体[4],例如随机梯度法、Momentum算法、Nesterovacceleratedgradient算法、Adagrad算法、Adadelta算法,等等;还有DFP、BFGS、L-BFGS等拟牛顿算法[6],以及速度更快的信赖域算法[7];并行化的最优化算法[5]也能提高训练速度.
1chinaXiv:201803.
00428v12逻辑回归2过拟合是计算学习的关键障碍,通常的解释是模型过于复杂[1,8],要用相对简单的模型来缓解过拟合现象;至于过拟合的成因,可用"偏差-方差分解"[1,9]来解释,[10]还讨论了过拟合与噪声、多重假设检验的关系.
缓解过拟合的常用手段是添加正则化项,[8]对比了L1正则化和L2正则化的特点.
本文的初衷是探究逻辑回归过拟合的形成机制,因为模型已经确定,所以无法再用"模型过于复杂"这样的理由来解释.
因此跳出常规的概率视角,用Taylor展开分析交叉熵后发现,逻辑回归过拟合的原因有两个:边界样本的损失贡献比重大且随法向量增长而加速增大、边界样本分布散乱.
虽然法向量过大只是过拟合的表象,但是控制法向量模长却能够切实缓解过拟合,因此各种正则化手段有效.
利用对过拟合机制的洞察,本文提出一种反拉方法:修改各个样本在交叉熵损失函数中的贡献比重,提高被分错样本的损失贡献,能够减少提高逻辑回归的训练次数;降低被分错样本的损失贡献,能够减缓过拟合.
为了保证交叉熵的数值稳定性,顺便提出一种近似计算方法.
在手写数字数据集MNIST[12]上,反拉方法将训练速度提高38.
25倍;在CIFRA10数据集上,反拉方法将训练速度提高5.
61倍.
本文后续内容这样组织.
第2节给出逻辑回归公式,为后文公式推导做准备;第3节给合实例和公式推导给出过拟合的2个原因;第4节给出反拉方法;第5节是数值实验,验证反拉方法的加速性能和缓解过拟合的效果.
2逻辑回归给定数据集D={(x1,y1),(x2,y2)xm,ym)},其中d为正整数,列向量xi=(xi1;xi2;xid),标量yi∈{0,1}.
当yi=0时称xi是负样本,当yi=1时称xi是正样本.
二分类问题是要从数据集D中学习到一个模型,然后用这个模型预测任意的样本xj是正样本还是负样本.
逻辑回归的任务是从给定数据集D中学习到分隔面的斜截式方程wTx+b=0,|w|=0(1)确定其中的法向量w和截距b值.
这里的w是列向量,记为w=(w1;w2;wd),b是标量.
任意平面都可以用做分隔面,区别只是推测效果可能不同.
为了寻找分隔面(1),对xi∈D,令zi=wTxi+b,按照[11]中定义,zi为点xi到分隔面(1)的加权距离.
定义单个样本xi上的损失函数l(zi)=ln(1σ(zi)),如果yi=0,ln(σ(zi)),如果yi=1,(2)这里的σ(z)为Sigmoid函数σ(z)=11+ez.
将样本集D上的损失函数定义为L(w,b)=1mm∑i=1l(zi),chinaXiv:201803.
00428v13过拟合实例与成因3图1:线性可分样本集上的过拟合图2:线性可分样本集上的正确率求解它的最小值{w,b}=argminw,bL(w,b),(3)就得到了最优参数w和b,代入(1)即得最优分隔面wTx+b=0.
对任意样本xj,用最优分隔面来推测它归属的类别.
令yj=0,如果wTxj+bln(σ(0)).
当xi为负样本时,情况类似.
从图5中可以直观地看到,相对于被正确分类的样本,被错误分类的样本对损失函数的贡献更大.
为了定量分析样本对损失函数的贡献,需要用Taylor公式寻找l(zi)的简单近似函数.
为此定义两个函数f0(z)=ez,如果zC0>0,(6)f1(z)=zez,如果zC0>0,(7)这里的C0是任意指定的正实数.
chinaXiv:201803.
00428v13过拟合实例与成因6定理1.
函数f0(z)是ln(1σ(z))的近似,函数f1(z)是ln(σ(z))的近似.
证.
先证明f0(z)是ln(1σ(z))的近似.
当zC0时,ezC0时,ezl(z2),即推论1.
样本的加权距离越小,损失贡献越大.
chinaXiv:201803.
00428v13过拟合实例与成因7给定C0>0.
当z11,记z1=wT2(x1c)和z2=wT2(x2c),那么有l(z1)l(z2)=l(sz1)l(sz2)≈f1(sz1)f1(sz2)≈sz1esz1sz2esz2≈z1z2≈l(z1)l(z2),(8)由式(8)得推论2.
被分错样本之间的损失贡献比例不随法向量的变化而变化.
给定C0>0.
当C01,记z1=wT2(x1c)和z2=wT2(x2c),那么有l(z1)l(z2)=l(sz1)l(sz2)≈f1(sz1)f1(sz2)≈esz1esz2=exp(s(z2z1))=(exp(z2z1))s,(9)由式(9)得推论3.
被分对样本之间的损失贡献比例会随着法向量的增长而指数级增长.
给定C0>0.
当z2>C0且z1=z2时,x1和x2分别位于分隔面wT(xic)=0的背面和正面,即一个被分错了另一个被分对了.
假设w2=sw,其中实数s>1,记z1=wT2(x1c)和z2=wT2(x2c),那么有l(z1)l(z2)=l(sz2)l(sz2)≈f1(sz2)f1(sz2)≈sz2+exp(sz2)exp(sz2)=1+sz2exp(sz2),(10)由式(10)得推论4.
被分错样本与被分对样本之间的损失贡献比例会随着法向量的增长而指数级增长.
将分隔面附近样本称为边界样本.
从推论1推论4可知,对损失函数的贡献比例,由大到小分顺序是:被分错的样本、被分对的边界样本、被分对的其它样本,它们之间的比例关系随着法向量的增长而迅速增大.
适用逻辑回归的数据集,被最优分隔面分错的样本占比不大,这样被分错的样本通常会在分隔面附近.
考虑到,在线性可分数据集上,法向量模长|w|趋向无穷大[11],分隔平面几乎完全由边界样本决定.
在线性不可分数据集上,法向量模长|w|有界[11],但最优分隔面的法向量模长可能仍然很大,过拟合仍然严重.
因此得出过拟合原因之一:边界样本的损失贡献比重大且随权重增长而加速增大.
自然界很多事件服从正态分布,例如图6,中心处样本密度大,能够很好在逼近其概率密度函数;在远离中心的边缘处,概率密度函数的值较小,样本稀疏,不能很好地反映其概率密度函数.
考虑到训练集边界样本基本决定分隔平面,而测试集样本的实际分布与训练集会有一些差异,所以得到的分隔平面不能很好地分隔训练集.
因此得到过拟合的原因之二:边界样本分布散乱.
第3节的2个过拟合例子都是根据这2个原因设计出来的.
chinaXiv:201803.
00428v14反拉加速8图6:一个服从正态分布的样本集3.
4正则化的作用机理缓解过拟合的常用手段是添加正则化项,各种各样的正则化方法的目标都是一致的:控制法向量的模长,不让|w|过大.
由过拟合的成因可知,虽然法向量过大只是过拟合的表象,不是根本原因,但限制它的模长确实有效缓解了过拟合,这是因为它限制了边缘样本的损失贡献比重.
正则化缓解过拟的同时,必然会降低训练集上的正确率.
从过拟合成因还可以知道缓解过拟合的另一个思路:修整边界样本使之准确反映概率密度函数.
教科书[1]中已经写明增加样本数量能缓解过拟合,其实也可以用边界样本散乱的观点来解释:增加样本总量,边界样本数量也同比例增加,从而边界样本更好地反映其概率密度函数,从而缓解过拟合.
4反拉加速图5画出了单个正样本(红色)和单个负样本(蓝色)的损失曲线.
直观地理解,如果样本集是线性可分的,那么正样本对应的zi越大,该样本上的损失函数值越小;负样本对应的zi越小,该样本上的损失函数值越小.
从而,在式(3)的计算过程中,负样本向zi负无穷方向移动,正样本向zi正无穷方向移动,达到了分类的目的.
从过拟合成因的分析过程可知,对给定的w和b,被错误分类的样本的损失贡献比重大,从而能优先减少分错样本的数量.
为了更快速地找到最优分隔面,索性进一步提高被分错样本的损失贡献,让错误更猛烈一些.
chinaXiv:201803.
00428v14反拉加速94.
1反拉方法定义半正定(POsitiveSemidenite)函数pos(z)=0,如果z0.
加权距离的计算方法保持不变,即zi=wTxi+b.
对加权距离进行反拉变换,得到Zi=zi+λpos(zi),如果yi=0,zi+λnes(zi),如果yi=1,这里的λ称为反拉系数,取值范围是(1,+∞).
将损失函数(2)替换为h(zi)=ln(1σ(Zi)),如果yi=0,ln(σ(Zi)),如果yi=1,从而样本集D上的损失函数为H(w,b)=1mm∑i=1h(zi).
求解它的最小值{w,b}=argminw,bH(w,b),(11)就得到了最优参数w和b.
由式(4.
1)(4.
1)知,在λ=0时,h(zi)=l(zi).
图7中对比了逻辑回归损失函数l(z)和反拉后的损失函数h(z),可以看到,当λ>0时,对被分错的样本,反拉后的损失更大了;当10.
反拉加速只用于训练,不用于推测.
一旦得到最优分隔面参数w和b,仍然使用式(4)来推测样本的类别.
4.
2损失函数的数值稳定性使用反拉方法后,对给定的正样本xi、法向量w和截距b,如果zi<0,那么λ越大σ(Zi)越接近于0,损失函数ln(σ(Zi))的数值计算越不稳定,很容易超出计算机的表示范围,得到结果NaN(NotANumber).
负样本的情形类似.
为了保持数值稳定,同时减少一点计算量,用式(6)近似计算式(4.
1)中的ln(1σ(Zi)),用式(7)近似计算式(4.
1)中的ln(σ(Zi)).
式(6)(4.
1)中的常数C0可以根据精度要求取值,例如C0=4.
3时,近似值与精确值之间的误差小于0.
0001.
chinaXiv:201803.
00428v15数值实验115数值实验反拉方法的设计目标是减少迭代次数,降低训练成本,额外收获是能够缓解过拟合.
反拉方法的本质是调整了各个样本的损失比重,不涉及正则项和最优化算法,因此只需要在最优化算法、正则项相同的情况下对比逻辑回归在使用反拉方法前后的性能.
MNIST数据集和CIFAR10数据集分别包含了10类样本,恰好可以任取2类样本组合起来测试反拉方法的性能.
5.
1加速MNIST训练手写数字数据集MNIST[12]包含0-9这个10个数字的图片,图片大小为28*28,将2维单色图像拉平制作为1维向量.
取任意两个数字的图片分别作为负样本、正样本进行训练,组合顺序依次为0-1、0-2、.
.
.
、0-9、1-2、1-3、.
.
.
、1-9、.
.
.
、7-8、8-9,一共45种组合.
每种组合训练10次,然后训练下一种组合,共计训练450次.
训练使用负梯度下降法,步长指定为0.
01,无正则化项,w的初值从均匀分布U(1/√784,1/√784)中随机选取,b的初值为0.
最大迭代步数设为20000,LR最大正确率对应的迭代步数(称为LR最优迭代步数),FLR迭代时到达LR最大正确率花费的迭代步数称为FLR最优迭代步数,如图8如示,用LR的最优迭代步数除以FLR的最优迭代步数就得到加速倍数,如图9所示.
加速倍数为1意味着没有加速,加速倍数大于1意味有加速.
从图9看出,加速倍数在13.
1087.
22之间,平均值为38.
25.
反拉方法在训练集和测试集上正确分别为99.
23%和98.
82%,相对于未反拉时正确率的提升见图10,训练集上平均提高0.
51%,测试集上平均提高0.
14%.
5.
2加速CIFAR10训练手写数字数据集CIFAR10[13]包含10类彩色图片,图片大小为32*32,将2维彩色图像拉平制作为1维向量.
取任意两类图片分别作为负样本、正样本进行训练,组合顺序依次为1-2、1-3、.
.
.
、1-10、2-3、2-4、.
.
.
、2-10、.
.
.
、8-9、9-10,一共45种组合.
每种组合训练10次,然后训练下一种组合,共计训练450次.
训练使用负梯度下降法,步长指定为0.
0001,无正则化项,w的初值从均匀分布U(1/√3072,1/√3072)中随机选取,b的初值为0.
最大迭代步数设为20000,最优迭代步数如图11如示,加速倍数如图12所示.
加速倍数在1.
809.
06之间,平均值为5.
61.
反拉方法在训练集和测试集上正确率均值分别为81.
69%和81.
00%,相对于未反拉时正确率的提升见图10,训练集上平均提高2.
52%,测试集上平均提高2.
06%.
图11图13中未显示正确率出现大幅震荡的组合.
5.
3控制过拟合在3.
1节的例子上应用反拉方法,取λ=0.
9,法向量初始值为w=(1/√2;1/√2),截距b=0,初始分隔线如图14中黑线所示.
用负梯度下降法迭代求解式(11),迭代步长指定chinaXiv:201803.
00428v15数值实验12图8:在MNIST上,LR最大正确率对应的训练次数,横轴是各个组合的编号.
LR表示未用反拉加速,FLR代表使用了反拉加速.
图9:在MNIST上,反拉方法获得的加速倍数.
图10:在MNIST上,反拉方法对正确率的影响.
chinaXiv:201803.
00428v15数值实验13图11:在CIFAR10上,LR最大正确率对应的训练次数,横轴是各个组合的编号.
图12:在CIFAR10上,反拉方法获得的加速倍数.
图13:在CIFAR10上,反拉方法对正确率的影响.
chinaXiv:201803.
00428v15数值实验14图14:线性可分训练集上,λ=0.
9时反拉方法的训练效果.
图15:在线性可能分训练集上,最优法向量w随λ的变化情况,右上角的+号代表13个相互接近的点.
为0.
1,前后两步迭代的损失函数值小于=106时停止迭代.
洋红色虚线是迭代1281步后的分隔线,洋红色实直线是迭代2561步后停止时的最优分隔线.
最优分隔线的斜截式方程为4.
1066x1+0.
0718x2+1.
5237*1017=0,调整系数后的等价方程为x1+0.
0175x2+3.
7105*1018=0,与人眼观察的理想分隔线x1=0很接近.
此时,反拉方法有效缓解了过拟合.
在3.
1节的例子上应用反拉方法,λ在区间[1,1]上均匀取21个值,迭步长指定为0.
1,前后两步迭代的损失函数值小于=106时停止迭代.
将所得的21个最优法向量w绘制出来,得到图15.
黑色带箭头直线是λ=1时得到w,洋红色带箭头直线是λ=1时得到w,折线上的+号对应λ∈(1,1)时得到的w.
注意,这个线性不可分样本集的理想分隔线是x1=0,它的法向量w=(1;0).
从图15知,λ=0.
9时的法向量方向与理想法向量最接近,随着λ的增大,最优法向量与理想法向量的夹角越来越大,过拟合起来越严重.
这个实验证明,反拉系数λ能够控制线性可分数据集上的过拟合.
在3.
2节的例子上应用反拉方法,取λ=0.
8,法向量初始值为w=(1/√2;1/√2),截距b=0,初始分隔线如图16黑线所示.
用负梯度下降法迭代求解式(11),迭代步长指定为0.
1,前后两步迭代的损失函数值小于=106时停止迭代.
洋红色虚线是迭代1057步后的分隔线,洋红色实直线是迭代2116步后停止时的最优分隔线.
最优分隔线的斜截式方程为3.
8356x10.
0140x2+0.
0208=0,调整系数后的等价方程为x10.
0037x2+0.
0054=0,与人眼观察的理想分隔线x1=0很接近.
此时,反拉方法有效缓解了过拟合.
在3.
2节的例子上应用反拉方法,λ在区间[1,1]上均匀取21个值,代步长指定为0.
1,前后两步迭代的损失函数值小于=106时停止迭代.
将所得的21个最优法向量w绘制出来,得到图17.
黑色带箭头直线是λ=1时得到w,洋红色带箭头直线是λ=1时得到w,折线上的+号对应λ∈(1,1)时得到的w.
注意,这个线性不可分样本集的理想分隔线是x1=0,它的法向chinaXiv:201803.
00428v16总结与展望15图16:线性不可分训练集上,λ=0.
8时反拉方法的训练效果.
图17:在线性不可能分训练集上,最优法向量w随λ的变化情况.
量w=(1;0).
从图17,λ=0.
8时的法向量方向与理想法向量最接近,随着λ的增大,最优法向量与理想法向量的夹角越来越大,过拟合起来越严重.
这个实验证明,反拉系数λ能够控制线性不可分数据集上的过拟合.
6总结与展望本文用严格数学分析来解释逻辑回归过拟合现象,进而得到了加速训练过程的反拉方法和保证交叉熵数值稳定的近似方法.
由过拟合原因的推导过程知道,反拉加速会导致更加严重的过拟合,必须采取应对措施.
可以添加常规的正则项,也可以将反拉系数逐渐减至0以下.
根据数值实验经验,反拉系数λ过大时,正确率会降低,正确率曲线震荡.
在实际应用中,应首先保证正确率曲线平滑,再追求加速性能.
反拉方法的加速效果看起来与样本集有一定的关联,其间的作用机理需要进一步研究.
参考文献[1]周志华.
机器学习.
清华大学出版社,2016.
4[2]R.
-E.
Fan,K.
-W.
Chang,C.
-J.
Hsieh,X.
-R.
Wang,andC.
-J.
Lin.
LIBLINEAR:AlibraryforlargelinearclassicationJournalofMachineLearningResearch9(2008),1871-1874.
[3]SimonWiesler,HermannNey.
AConvergenceAnalysisofLog-LinearTraining.
AdvancesinNeuralInformationProcessingSystems,2011:657-665chinaXiv:201803.
00428v1参考文献16[4]SebastianRuder.
Anoverviewofgradientdescentoptimizationalgorithms.
arXiv:1609.
04747[cs.
LG][5]BrendanH.
,HoltG.
,SculleyD.
,YoungM.
,EbnerD.
,GradyJ.
,NieL.
,Phillips.
T,DavydovE.
,GolovinD.
,ChikkerurS.
,LiuD.
,WattenbergM.
,HrafnkelssonA.
,BoulosT.
,KubicaJ.
(2013)AdClickPrediction:aViewfromtheTrenches.
Proceedingsofthe19-thKDD.
[6]G.
AndrewandJ.
Gao.
Scalabletrainingofl1-regularizedlog-linearmodels.
InProceedingsofthe24thinternationalconferenceonMachinelearning,ICML'07,pages33–40,NewYork,NY,USA,2007.
ACM.
[7]C.
-J.
LinandJ.
J.
More.
Newton'smethodforlargebound-constrainedoptimizationprob-lems.
SIAMJ.
onOptimization,9(4):1100–1127,Apr.
1999.
[8]T.
Hastie,R.
Tibshirani,andJ.
Friedman.
TheElementsofStatisticalLearning,SecondEdi-tion:DataMining,Inference,andPrediction.
SpringerSeriesinStatistics.
Springer,0002-2009.
corr.
3rdedition,Feb.
2009.
[9]P.
Domingos.
Auniedbias-variancedecompositionanditsapplications.
InProceedingsoftheSeventeenthInternationalConferenceonMachineLearning,pages231–238,Stanford,CA,2000.
MorganKaufmann.
[10]PedroDomingos.
AFewUsefulThingstoKnowaboutMachineLearning.
CommunicationsoftheACM,Vol.
55No.
10,Pages78-87,2012.
[11]何沧平,对焦分类方法,[ChinaXiv:201711.
02399][12]YannLeCun,CorinnaCortes,ChristopherJ.
C.
Burges.
TheMNISTdatabaseofhandwrittendigits.
http://yann.
lecun.
com/exdb/mnist/[13]AlexKrizhevsky.
TheCIFAR-10dataset.
http://www.
cs.
toronto.
edu/kriz/cifar.
htmlchinaXiv:201803.
00428v1
青果网络-618阿里云,腾讯云特惠优惠折上折!
官方网站:点击访问青果云官方网站活动方案:—————————–活动规则—————————1、选购活动产品并下单(先不要支付)2、联系我司在线客服修改价格或领取赠送时间3、确认价格已按活动政策修改正确后,支付订单,到此产品开设成功4、本活动产品可以升级,升级所需费用按产品原价计算若发生退款,按资源实际使用情况折算为产品原价再退还剩余余额! 美国洛杉矶CN2_GIACPU内存系统盘流量宽带i...
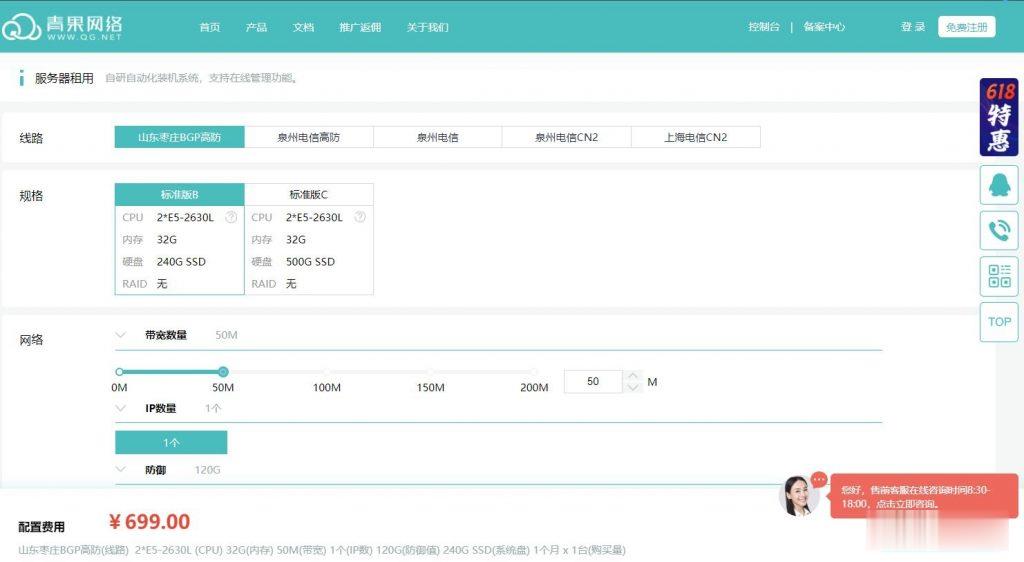
€4.99/月Contabo云服务器,美国高性价比VPS/4核8G内存200G SSD存储
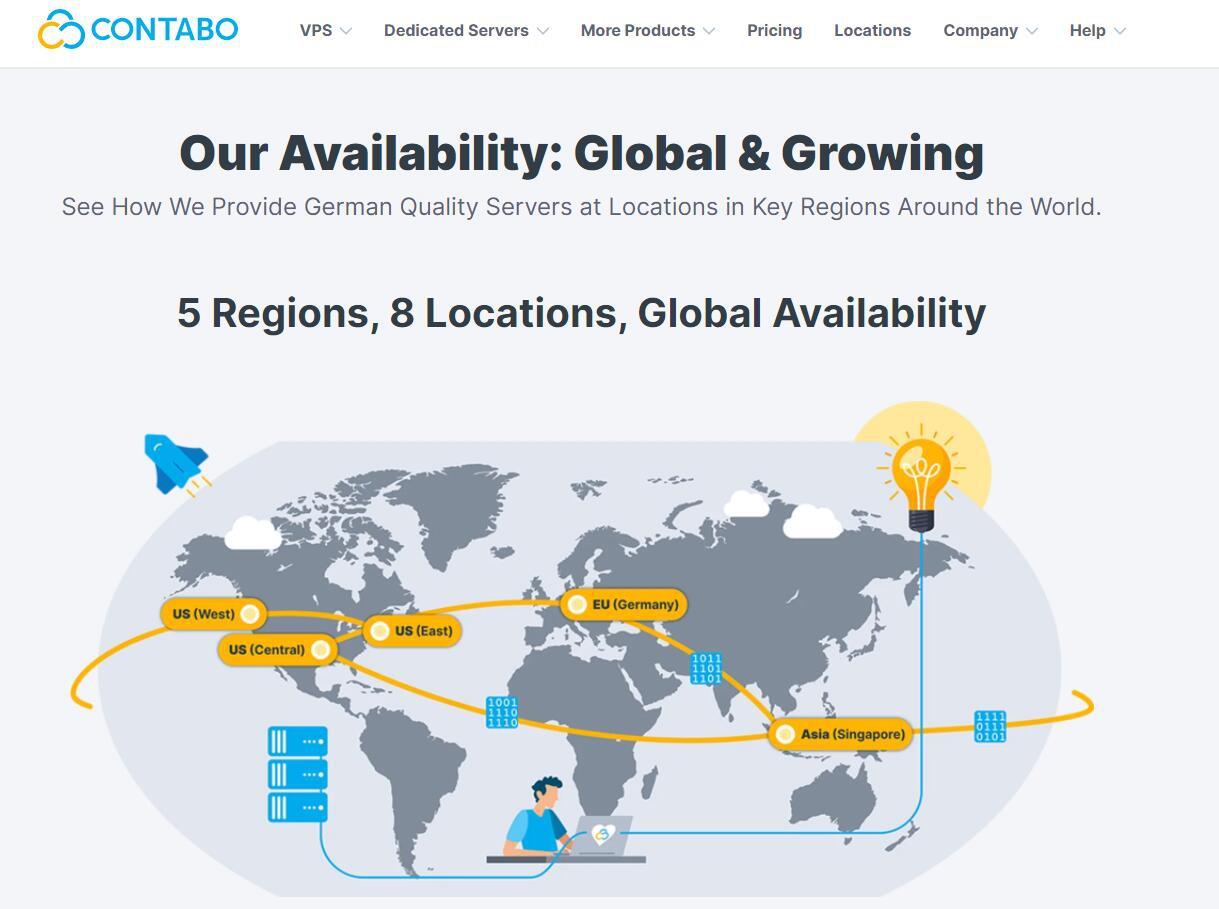
Contabo是一家运营了20多年的欧洲老牌主机商,之前主要是运营德国数据中心,Contabo在今年4月份增设新加坡数据中心,近期同时新增了美国纽约和西雅图数据中心。全球布局基本完成,目前可选的数据中心包括:德国本土、美国东部(纽约)、美国西部(西雅图)、美国中部(圣路易斯)和亚洲的新加坡数据中心。Contabo的之前国外主机测评网站有多次介绍,他们家的特点就是性价比高,而且这个高不是一般的高,是...
NameCheap新注册.COM域名$5.98
随着自媒体和短视频的发展,确实对于传统的PC独立网站影响比较大的。我们可以看到云服务器商家的各种促销折扣活动,我们也看到传统域名商的轮番新注册和转入的促销,到现在这个状态已经不能说这些商家的为用户考虑,而是在不断的抢夺同行的客户。我们看到Namecheap商家新注册域名和转入活动一个接一个。如果我们有需要新注册.COM域名的,只需要5.98美元。优惠码:NEWCOM598。同时有赠送2个月免费域名...

加快网速的方法为你推荐
-
考试chromepcllenchromeSource163计划ipad支持ipad支持ipad司机苹果5photoshop技术ps几大关键技术?勒索病毒win7补丁我的电脑是windows7系统,为什么打不了针对勒索病毒的补丁(杀毒软件显ipadwifiIpad怎么用移动无线上网