robots txt协议robot协议是谁发明的?为什么不允许蜘蛛来
robots txt协议 时间:2022-02-24 阅读:()
robots.txt有什么作用
武汉seo发现很多企业网站没有robots.txt这个文件,也不知道robots.txt是什么,这个文件有什么作用。今天我就和大家详细说下这个文件吃及他的作用。1.什么是robots.txt Baidu作出的回答,robots.txt是一个必须放在根目录底下的纯文本文件,文件名必须全部是小写的字母即“robots.txt”,在这个文件中声明该网站中不想被robot访问的部分,这样,该网站的部分或全部内容就可以不被搜索引擎收录了,或者指定搜索引擎只收录指定的内容。2.robots.txt有什么作用 1.SEO中引导搜索蜘蛛抓取网站地图,更好地收录网站页面。2.禁止所有搜索蜘蛛抓取你网站的所有内容或者是指定目录。3.robots.txt用法举例 1. 允许所有搜索引擎收录本站:robots.txt为空就可以,什么都不要写。2.禁止某个搜索引擎收录本站,例如禁止百度: User-agent: Baiduspider Disallow: / 3.禁止所有搜索引擎收录本站 User-agent: * Disallow: / 4.禁止所有搜索引擎收录网站的某些目录: User-agent: * Disallow: /目录名1/ Disallow: /目录名2/ Disallow: /目录名3/ 参考资料:常见搜索引擎机器人Robots名字 名称 搜索引擎 Baiduspider Googlebot MSNBOT ia_archiver 文章来源: /seo-jiaocheng/robots.txt.html"robots.txt"是什么?
一.什么是robots.txt文件? 搜索引擎通过一种程序robot(又称spider),自动访问互联网上的网页并获取网页信息。 您可以在您的网站中创建一个纯文本文件robots.txt,在这个文件中声明该网站中不想被robot访问的部分,这样,该网站的部分或全部内容就可以不被搜索引擎收录了,或者指定搜索引擎只收录指定的内容。 二. robots.txt文件放在哪里? robots.txt文件应该放在网站根目录下。举例来说,当robots访问一个网站(比如)时,首先会检查该网站中是否存在/robots.txt这个文件,如果机器人找到这个文件,它就会根据这个文件的内容,来确定它访问权限的范围。 网站 URL 相应的 robots.txt的 URL / /robots.txt :80/ :80/robots.txt :1234/ :1234/robots.txt /??/robots.txt 三. robots.txt文件的格式 "robots.txt"文件包含一条或更多的记录,这些记录通过空行分开(以CR,CR/NL, or NL作为结束符),每一条记录的格式如下所示: "<field>:<optionalspace><value><optionalspace>"。 在该文件中可以使用#进行注解,具体使用方法和UNIX中的惯例一样。该文件中的记录通常以一行或多行User-agent开始,后面加上若干Disallow行,详细情况如下: User-agent: 该项的值用于描述搜索引擎robot的名字,在"robots.txt"文件中,如果有多条User-agent记录说明有多个robot会受到该协议的限制,对该文件来说,至少要有一条User-agent记录。如果该项的值设为*,则该协议对任何机器人均有效,在"robots.txt"文件中,"User-agent:*"这样的记录只能有一条。 Disallow : 该项的值用于描述不希望被访问到的一个URL,这个URL可以是一条完整的路径,也可以是部分的,任何以Disallow 开头的URL均不会被robot访问到。例如"Disallow: /help"对/help.html 和/help/index.html都不允许搜索引擎访问,而"Disallow: /help/"则允许robot访问/help.html,而不能访问/help/index.html。 任何一条Disallow记录为空,说明该网站的所有部分都允许被访问,在"/robots.txt"文件中,至少要有一条Disallow记录。如果"/robots.txt"是一个空文件,则对于所有的搜索引擎robot,该网站都是开放的。 四. robots.txt文件用法举例 例1. 禁止所有搜索引擎访问网站的任何部分 下载该robots.txt文件 User-agent: * Disallow: / 例2. 允许所有的robot访问 (或者也可以建一个空文件 "/robots.txt" file) ?? User-agent: * Disallow: 例3. 禁止某个搜索引擎的访问 User-agent: BadBot Disallow: / 例4. 允许某个搜索引擎的访问 User-agent: baiduspider Disallow: User-agent: * Disallow: / 例5. 一个简单例子 在这个例子中,该网站有三个目录对搜索引擎的访问做了限制,即搜索引擎不会访问这三个目录。 需要注意的是对每一个目录必须分开声明,而不要写成 "Disallow: /cgi-bin/ /tmp/"。 User-agent:后的* 具有特殊的含义,代表"any robot",所以在该文件中不能有"Disallow: /tmp/*" or "Disallow: *.gif"这样的记录出现. User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /~joe/ 五. robots.txt文件参考资料 robots.txt文件的更具体设置,请参看以下链接: · Web Server Administrator's Guide to the Robots Exclusion Protocol · HTML Author's Guide to the Robots Exclusion Protocol · The original 1994 protocol description, as currently deployed · The revised -Draft specification, which is not pleted or implemented 在你的主页中为Web Robot设计路标 越来越酷,WWW的知名度如日中天。在上发布公司信息、进行电子商务已经从时髦演化成时尚。作为一个Web Master,你可能对HTML、java script、Java、 ActiveX了如指掌,但你是否知道什么是Web Robot?你是否知道Web Robot和你所设 计的主页有什么关系? 上的流浪汉--- Web Robot 有时你会莫名其妙地发现你的主页的内容在一个搜索引擎中被索引,即使你从未与他 们有过任何联系。其实这正是Web Robot的功劳。Web Robot其实是一些程序,它可以 穿越大量网址的超文本结构,递归地检索网络站点所有的内容。这些程序有时被叫 “蜘蛛(Spider)” , “网上流浪汉(Web Wanderer)”,“网络蠕虫(web worms)”或Web crawler。一些网上知名的搜索引擎站点(Search Engines)都有专门的Web Robot程序来完成信息的采集,例如Lycos,Webcrawler,Altavista等,以及中文搜索引擎站点例如北极星,网易,GOYOYO等。 Web Robot就象一个不速之客,不管你是否在意,它都会忠于自己主人的职责,任劳任怨、不知疲倦地奔波于万维网的空间,当然也会光临你的主页,检索主页内容并生成它所需要的记录格式。或许有的主页内容你乐于世人皆知,但有的内容你却不愿被洞察、索引。难道你就只能任其“横行”于自己主页空间,能否指挥和控制Web Robot的行踪呢?答案当然是肯定的。只要你阅读了本篇的下文,就可以象一个交通 警察一样,布置下一个个路标,告诉Web Robot应该怎么去检索你的主页,哪些可以检索,哪些不可以访问。 其实Web Robot能听懂你的话 不要以为Web Robot是毫无组织,毫无管束地乱跑。很多Web Robot软件给网络站点的 管理员或网页内容制作者提供了两种方法来限制Web Robot的行踪: 1、Robots Exclusion Protocol 协议 网络站点的管理员可以在站点上建立一个专门格式的文件,来指出站点上的哪一部分 可以被robot访问, 这个文件放在站点的根目录下,即robots.txt." target="_blank">/,它先去检查文件robots.txt" target="_blank">/robots.txt。如果这个文件存在,它便会按照这样的记录格式去分析: User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /~joe/ 以确定它是否应该检索站点的文件。这些记录是专门给Web Robot看的,一般的浏览者大概永远不会看到这个文件,所以千万不要异想天开地在里面加入形似<img src=*> 类的HTML语句或是“How do you do? where are you from?”之类假情假意的问候语。 在一个站点上只能有一个 "/robots.txt" 文件,而且文件名的每个字母要求全部是小 写。在Robot的记录格式中每一个单独的"Disallow"行表示你不希望Robot访问的URL, 每个URL必须单独占一行,不能出现 "Disallow: /cgi-bin/ /tmp/"这样的病句。同时在一个记录中不能出现空行,这是因为空行是多个记录分割的标志。 User-agent行指出的是Robot或其他代理的名称。在User-agent行,'*' 表示一个特殊的含义---所有的robot。 下面是几个robot.txt的例子: 在整个服务器上拒绝所有的robots: User-agent: * Disallow: / 允许所有的robots访问整个站点: User-agent: * Disallow: 或者产生一个空的 "/robots.txt" 文件。 服务器的部分内容允许所有的robot访问 User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /private/ 拒绝某一个专门的robot: User-agent: BadBot Disallow: / 只允许某一个robot光顾: User-agent: WebCrawler Disallow: User-agent: * Disallow: / 最后我们给出 /站点上的robots.txt: # For use by User-agent: W3Crobot/1 Disallow: User-agent: * Disallow: /Member/ # This is restricted to W3C Members only Disallow: /member/ # This is restricted to W3C Members only Disallow: /team/ # This is restricted to W3C Team only Disallow: /TandS/Member # This is restricted to W3C Members only Disallow: /TandS/Team # This is restricted to W3C Team only Disallow: /Project Disallow: /Systems Disallow: /Web Disallow: /Team 使用Robots META tag方式 Robots META tag 允许HTML网页作者指出某一页是否可以被索引,或是否可以用来查找更多的链接文件。目前只有部分robot实施了这一功能。 Robots META tag的格式为: <META NAME="ROBOTS" CONTENT="NOINDEX, NOFOLLOW"> 象其他的META tag一样,它应该放在HTML文件的HEAD区: <html> <head> <meta name="robots" content="noindex,nofollow"> <meta name="description" content="This page ...."> <title>...</title> </head> <body> ... Robots META tag指令使用逗号隔开,可以使用的指令包括 [NO]INDEX 和[NO]FOLLOW。INDEX 指令指出一个索引性robot是否可以对本页进行索引;FOLLOW 指 令指出robot是否可以跟踪本页的链接。缺省的情况是INDEX和FOLLOW。例如: <meta name="robots" content="index,follow"> <meta name="robots" content="noindex,follow"> <meta name="robots" content="index,nofollow"> <meta name="robots" content="noindex,nofollow"> 一个好的Web 站点管理员应该将robot的管理考虑在内,使robot为自己的主页服务, 同时又不损害自己网页的安全。如何配置网站Robots.txt
网站要设置robots.txt文件,我们就必需先了解什么是robots.txt?robots.txt是一个协议,而不是一个命令。robots.txt文件是搜索引擎来到一个网站必先看的文件,它是用来告诉搜索引擎在这个网站上什么可以看,什么不可以看。robots.txt文件对我们做seo的来说是非常有好处的,所以一个seo出色的网站在这些细节上做的非常到位,许多大型的网站都有设置robots.txt协议。比如:Robots.txt 文件应放在哪里?
Anny说的不错,是放在根目录,蜘蛛进入网站是进入网站的根目录,根据根目录的结构来爬取,所以这就体现了首页的重要性,同样的道理,robots.txt是一个蜘蛛的协议,蜘蛛到一个网站之后,第一个就会看一下有哪些是可以爬取的,哪些是禁止爬取的!所以放在根目录是无可厚非的!robots协议是什么?
Robots是一个英文单词,对英语比较懂的朋友相信都知道,Robots的中文意思是机器人。而我们通常提到的主要是Robots协议,Robots.txt被称之为机器人或Robots协议(也称为爬虫协议、机器人协议等)它的全称是“网络爬虫排除标准” 英文“Robots Exclusion Protocol”这也是搜索引擎的国际默认公约。我们网站可以通过Robots协议从而告诉搜索引擎的蜘蛛哪些页面可以抓取,哪些页面不能抓取。Robots协议的本质是网站和搜索引擎爬虫的沟通方式,是用来指引搜索引擎更好地抓取网站里的内容。 比如说,一个搜索蜘蛛访问一个网站时,它第一个首先检查的文件就是该网站的根目录里有没有robots.txt文件。 如果有,蜘蛛就会按照该文件中的条件代码来确定能访问什么页面或内容;如果没有协议文件的不存在,所有的搜索蜘蛛将能够访问网站上所有没有被协议限制的内容页面。 而百度官方上的建议是:仅当您的网站包含不希望被搜索引擎收录的内容时,才需要使用robots.txt文件进行屏蔽。而如果您希望搜索引擎收录网站上所有内容,请勿建立robots.txt文件。什么是robots.txt文件?
搜索引擎使用spider程序自动访问互联网上的网页并获取网页信息。spider在访问一个网站时,会首先会检查该网站的根域下是否有一个叫做robots.txt的纯文本文件,这个文件用于指定spider在您网站上的抓取范围。您可以在您的网站中创建一个robots.txt,在文件中声明该网站中不想被搜索引擎收录的部分或者指定搜索引擎只收录特定的部分。 请注意,仅当您的网站包含不希望被搜索引擎收录的内容时,才需要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿建立robots.txt文件。robots.txt,什么是robots.txt?
在这里说一下robots.txt只是一个协议,搜索引擎不一定会遵守什么是robots.txt?检查robots.tx有什么作用吗?
robots.txt文件会告诉蜘蛛程序在服务器上什么文件是可以被查看的什么文件是不允许查看的。举一个简单的例子:当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存robots.txt,如果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面robost.txt能带来什么好处
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取,当spider访问一个网站时,首先会检查该网站中是否存在robots.txt这个文件,如果 Spider找到这个文件,它就会根据这个文件的内容,来确定它访问权限的范围, 一句话总结 :robost.txt 文件可以有效保护网站的隐私。希望对你有帮助。robots.txt协议 全站动态页面屏蔽代码怎么回事啊?
如何避免内容被重复收录 找到了问题的根源,接下来便是解决问题的时候,那么如何解决如此现象呢,其实也很容易: A:URL标准化,B:利用robots.txt进行屏蔽动态文件 A:在网站建设过程中尽量统一URL地址,勿使用动态页面进行链接,一来是搜索引擎青睐静态页面,另一方面也防止了相同内容被搜索引擎重复收录的结局。 B:利用robots.txt进行动态文件的屏蔽,如:“Disallow: /*?*”说明:如此屏蔽法适合在不存在“TAG标签”下利用,否则标签也将被屏蔽。不过屏蔽可灵活运用,在不同的程序下,不同屏蔽即可。robots.txt文件的规范性。许多同学估计在开头就没有进行空格。这个空格在哪里呢?例如,robots.txt文件的开头: “User-agent: * Disallow: /plus/ad_js.php” 很多的时候,user-agent分号后面没有空格,而是直接“*”号了。这就是一个很微小的错误,但是也是致命的错误。 要注意的是,我们知道php动态页面都是从数据调用的数据,而这个网页不是真实存在的,所以搜索引擎久而久之就会丢弃这样的页面,它会认为这是不可靠的页面。所以我们要屏蔽这样的动态页面,从而降低我们网页的重复页面。那么我们只要在robots.txt文件里面,加上这样的代码就行了:"Disallow:/*?*”。这个代码的意思是根目录下个所有动态禁止搜索引擎访问。 网站建设与优化严把细节优化,内容重复收录是大患,应认真对待,否最终难以逾越排名障碍。(怎样写robots屏蔽动态页面,防止内容被百度等搜索引擎重复收录)什么是robots.txt?
## robots.txt for Discuz! X2#User-agent: *Disallow: /api/Disallow: /data/Disallow: /source/Disallow: /install/Disallow: /template/Disallow: /config/Disallow: /uc_client/Disallow: /uc_server/Disallow: /static/Disallow: /admin.phpDisallow: /search.phpDisallow: /member.phpDisallow: /api.phpDisallow: /misc.phpDisallow: /connect.phpDisallow: /forum.php?mod=redirect*Disallow: /forum.php?mod=post*Disallow: /home.php?mod=spacecp*Disallow: /userapp.php?mod=app&*Disallow: /*?mod=misc*Disallow: /*?mod=attachment*Disallow: /*mobile=yes*robots.txt协议,怎么设置
robots.txt文件的格式 User-agent: 定义搜索引擎的类型 Disallow: 定义禁止搜索引擎收录的地址 Allow: 定义允许搜索引擎收录的地址 我们常用的搜索引擎类型有: google蜘蛛:62616964757a686964616fe58685e5aeb931333337623431googlebot 百度蜘蛛:baiduspider yahoo蜘蛛:slurp alexa蜘蛛:ia_archiver msn蜘蛛:msnbot altavista蜘蛛:scooter lycos蜘蛛:lycos_spider_(t-rex) alltheweb蜘蛛:fast-webcrawler inktomi蜘蛛: slurp robots.txt文件的写法 User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符 Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录 Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录 Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录 Disallow: /ABC 这里定义是禁止爬寻ABC整个目录 Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。 Disallow: /*?* 禁止访问网站中所有的动态页面 Disallow: .jpg$ 禁止抓取网页所有的.jpg格式的图片 Disallow:/ab/adc.html 禁止爬去ab文件夹下面的adc.html所有文件 User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符 Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录 Allow: /tmp 这里定义是允许爬寻tmp的整个目录 Allow: .htm$ 仅允许访问以".htm"为后缀的URL。 Allow: .gif$ 允许抓取网页和gif格式图片 robots.txt文件用法举例 例1. 禁止所有搜索引擎访问网站的任何部分 User-agent: * Disallow: / 实例分析:淘宝网的 Robots.txt文件 User-agent: Baiduspider Disallow: / 很显然淘宝不允许百度的机器人访问其网站下其所有的目录。 例2. 允许所有的robot访问 (或者也可以建一个空文件 “/robots.txt” file) User-agent: * Disallow: 例3. 禁止某个搜索引擎的访问 User-agent: BadBot Disallow: / 例4. 允许某个搜索引擎的访问 User-agent: baiduspider Disallow: User-agent: *Disallow: /robots.txt文件主要是干什么的?
robots.txt是一个协议.robots.txt是搜索引擎中访问的时候要查看的第一个文件。robots.txt文件告诉搜索引擎的蜘蛛在服务器上什么文件是可以被查看的。 最简单的robots.txt 文件使用两条规则:User-Agent适用下列规则的漫游器(访问的设备)Disallow: 要拦截的网页robots协议怎么书写?
# # robots.txt for 你的网站安装包,或者你的网站名 # User-agent: * Disallow(不允许): /不想被收的目录/ Disallow(不允许): /不想被收的目录/ (结束。把括号内中文去了。把其他的转换成要求。格式为.TXT,扔在根目录下。记得不要把根目录填上去就行了。若是某个网页,就填绝对路径。)什么是robots.txt文件?在网站优化中有什么作用
robots.txt 也就 robots协议,是搜索引擎中访问网站的时候要查看的第一个文件。通过robots.txt文件告诉搜索引擎蜘蛛哪些页面可以抓取,哪些页面不能抓取。如何使用robots.txt控制网络蜘蛛访问
网络蜘蛛进入一个网站,一般会访问一个特殊的文本文件Robots.txt,这个文件一般放在网站服务器的根目录下。网站管理员可以通过robots.txt来定义哪些目录网络蜘蛛不能访问,或者哪些目录对于某些特定的网络蜘蛛不能访问。例如有些网站的可执行文件目录和临时文件目录不希望被搜索引擎搜索到,那么网站管理员就可以把这些目录定义为拒绝访问目录。Robots.txt语法很简单,例如如果对目录没有任何限制,可以用以下两行来描述: User-agent: * Disallow 当然,Robots.txt只是一个协议,如果网络蜘蛛的设计者不遵循这个协议,网站管理员也无法阻止网络蜘蛛对于某些页面的访问,但一般的网络蜘蛛都会遵循这些协议,而且网站管理员还可以通过其它方式来拒绝网络蜘蛛对某些网页的抓取。 回答不容易,希望能帮到您,满意请帮忙采纳一下,谢谢 !robots.txt和robots meta标签 有什么作用 ,怎么查看
robots.txt和robots meta标签都是搜索引擎机器人爬行协议 控制搜索引擎爬行站点内文件(txt管理)或者网页内代码(meta管理)的一种协议。 一般meta支持的不广,所以只用txt就可以了。 这个需要自己写 具体语法我举个例子 User-agent: * Disallow: /image/ Disallow: /Image/ Disallow: /UpLoadFiles/ Disallow: /Web_Offices/什么是robots.txt?什么是"网址受到 robots.txt 的限制"错误
什么是robots.txt文件:搜索引擎通过一种爬虫spider程序(又称搜索蜘蛛、robot、搜索机器人等),自动搜集互联网上的网页并获取相关信息。鉴于网络安全与隐私的考虑,搜索引擎遵循robots.txt协议。通过根目录中创建的纯文本文件robots.txt,网站可以声明不想被robots访问的部分。每个网站都可以自主控制网站是否愿意被搜索引擎收录,或者指定搜索引擎只收录指定的内容。当一个搜索引擎的爬虫访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如果该文件不存在,那么爬虫就沿着链接抓取,如果存在,爬虫就会按照该文件中的内容来确定访问的范围。关于robots.txt的问题?
robots.txt是一个协议,而不是一个命令。robots.txt是搜索引擎中访问网站的时候要查看的第一个文件。robots.txt文件告诉蜘蛛程序在服务器上什么文件是可以被查看的。 当一个搜索蜘蛛访问一个站点时,它会首先检查该站点根目录下是否存在robots.txt,如 果存在,搜索机器人就会按照该文件中的内容来确定访问的范围;如果该文件不存在,所有的搜索蜘蛛将能够访问网站上所有没有被口令保护的页面。百度官方建 议,仅当您的网站包含不希望被搜索引擎收录的内容时,才需要使用robots.txt文件。如果您希望搜索引擎收录网站上所有内容,请勿建立 robots.txt文件。什么是robots协议?网站中的robots.txt写法和作用
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。 文件写法 User-agent: * 这里的*代表的所有的搜索引擎种类,*是一个通配符 Disallow: /admin/ 这里定义是禁止爬寻admin目录下面的目录 Disallow: /require/ 这里定义是禁止爬寻require目录下面的目录 Disallow: /ABC/ 这里定义是禁止爬寻ABC目录下面的目录 Disallow: /cgi-bin/*.htm 禁止访问/cgi-bin/目录下的所有以".htm"为后缀的URL(包含子目录)。 Disallow: /*?* 禁止访问网站中所有包含问号 (?) 的网址 Disallow: /.jpg$ 禁止抓取网页所有的.jpg格式的图片 Disallow:/ab/adc.html 禁止爬取ab文件夹下面的adc.html文件。 Allow: /cgi-bin/ 这里定义是允许爬寻cgi-bin目录下面的目录 Allow: /tmp 这里定义是允许爬寻tmp的整个目录 Allow: .htm$ 仅允许访问以".htm"为后缀的URL。 Allow: .gif$ 允许抓取网页和gif格式图片 Sitemap: 网站地图 告诉爬虫这个页面是网站地图 文件用法 例1. 禁止所有搜索引擎访问网站的任何部分 User-agent: * Disallow: / 实例分析:淘宝网的 Robots.txt文件 User-agent: Baiduspider Disallow: / User-agent: baiduspider Disallow: / 很显然淘宝不允许百度的机器人访问其网站下其所有的目录。 例2. 允许所有的robot访问 (或者也可以建一个空文件 “/robots.txt” file) User-agent: * Allow: / 例3. 禁止某个搜索引擎的访问 User-agent: BadBot Disallow: / 例4. 允许某个搜索引擎的访问 User-agent: Baiduspider allow:/ 例5.一个简单例子 在这个例子中,该网站有三个目录对搜索引擎的访问做了限制,即搜索引擎不会访问这三个目录。 需要注意的是对每一个目录必须分开声明,而不要写成 “Disallow: /cgi-bin/ /tmp/”。 User-agent:后的*具有特殊的含义,代表“any robot”,所以在该文件中不能有“Disallow: /tmp/*” or “Disallow:*.gif”这样的记录出现。 User-agent: * Disallow: /cgi-bin/ Disallow: /tmp/ Disallow: /~joe/ Robot特殊参数: 允许 Googlebot: 如果您要拦截除Googlebot以外的所有漫游器不能访问您的网页,可以使用下列语法: User-agent: Disallow: / User-agent: Googlebot Disallow: Googlebot 跟随指向它自己的行,而不是指向所有漫游器的行。 “Allow”扩展名: Googlebot 可识别称为“Allow”的 robots.txt 标准扩展名。其他搜索引擎的漫游器可能无法识别此扩展名,因此请使用您感兴趣的其他搜索引擎进行查找。“Allow”行的作用原理完全与“Disallow”行一样。只需列出您要允许的目录或页面即可。 您也可以同时使用“Disallow”和“Allow”。例如,要拦截子目录中某个页面之外的其他所有页面,可以使用下列条目: User-agent: Googlebot Allow: /folder1/myfile.html Disallow: /folder1/ 这些条目将拦截 folder1 目录内除 myfile.html 之外的所有页面。 如果您要拦截 Googlebot 并允许 Google 的另一个漫游器(如 Googlebot-Mobile),可使用”Allow”规则允许该漫游器的访问。例如: User-agent: Googlebot Disallow: / User-agent: Googlebot-Mobile Allow: 使用 * 号匹配字符序列: 您可使用星号 (*) 来匹配字符序列。例如,要拦截对所有以 private 开头的子目录的访问,可使用下列条目: User-Agent: Googlebot Disallow: /private*/ 要拦截对所有包含问号 (?) 的网址的访问,可使用下列条目: User-agent: * Disallow: /*?* 使用 $ 匹配网址的结束字符 您可使用 $字符指定与网址的结束字符进行匹配。例如,要拦截以 .asp 结尾的网址,可使用下列条目: User-agent: Googlebot Disallow: /*.asp$ 您可将此模式匹配与 Allow 指令配合使用。例如,如果 ? 表示一个会话 ID,您可排除所有包含该 ID 的网址,确保 Googlebot 不会抓取重复的网页。但是,以 ? 结尾的网址可能是您要包含的网页版本。在此情况下,可对 robots.txt 文件进行如下设置: User-agent: * Allow: /*?$ Disallow: /*? Disallow: / *? 一行将拦截包含 ? 的网址(具体而言,它将拦截所有以您的域名开头、后接任意字符串,然后是问号 (?),而后又是任意字符串的网址)。 Allow: /*?$ 一行将允许包含任何以 ? 结尾的网址(具体而言,它将允许包含所有以您的域名开头、后接任意字符串,然后是问号 (?),问号之后没有任何字符的网址)。 尽管robots.txt已经存在很多年了,但是各大搜索引擎对它的解读都有细微差别。Google与百度都分别在自己的站长工具中提供了robots工具。如果您编写了robots.txt文件,建议您在这两个工具中都进行测试,因为这两者的解析实现确实有细微差别。robot协议是谁发明的?为什么不允许蜘蛛来
robots.txt并不是某一个公司制定的,而是早在20世纪93、94年就早已出现,当时还没有Google。真实Robots协议的起源,是在互联网从业人员的公开邮件组里面讨论并且诞生的。即便是今天,互联网领域的相关问题也仍然是在一些专门的邮件组中讨论,并产生(主要是在美国)。 1994年6月30日,在经过搜索引擎人员以及被搜索引擎抓取的网站站长共同讨论后,正式发布了一份行业规范,即robots.txt协议。在此之前,相关人员一直在起草这份文档,并在世界互联网技术邮件组发布后,这一协议被几乎所有的搜索引擎采用,包括最早的altavista,infoseek,后来的google,bing,以及中国的百度,搜搜,搜狗等公司也相继采用并严格遵循。 不允许蜘蛛来抓取的情况有很多,比如某个网站不靠搜索引擎导入流量,就可以通过robots.txt协议禁止搜索引擎抓取,因为搜索引擎频繁抓取页面会占用服务器的带宽,影响服务器性能;再比如会员登录后才能看到的内容、重复内容、程序文件等等都需要通过robots.txt文件来禁止搜索引擎抓取,一方面可以节约带宽,另一方面可以对搜索引擎友好。。。
- robots txt协议robot协议是谁发明的?为什么不允许蜘蛛来相关文档
提速啦母鸡 E5 128G 61IP 1200元
提速啦(www.tisula.com)是赣州王成璟网络科技有限公司旗下云服务器品牌,目前拥有在籍员工40人左右,社保在籍员工30人+,是正规的国内拥有IDC ICP ISP CDN 云牌照资质商家,2018-2021年连续4年获得CTG机房顶级金牌代理商荣誉 2021年赣州市于都县创业大赛三等奖,2020年于都电子商务示范企业,2021年于都县电子商务融合推广大使。资源优势介绍:Ceranetwo...
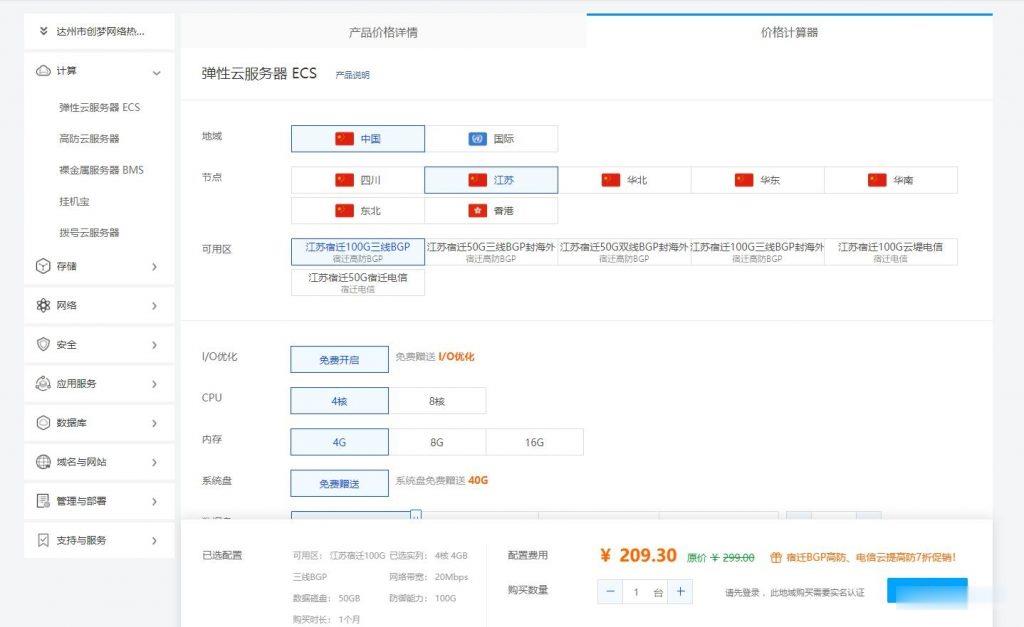
创梦网络-江苏宿迁BGP云服务器100G高防资源,全程ceph集群存储,安全可靠,数据有保证,防护真实,现在购买7折促销,续费同价!
官方网站:点击访问创梦网络宿迁BGP高防活动方案:机房CPU内存硬盘带宽IP防护流量原价活动价开通方式宿迁BGP4vCPU4G40G+50G20Mbps1个100G不限流量299元/月 209.3元/月点击自助购买成都电信优化线路8vCPU8G40G+50G20Mbps1个100G不限流量399元/月 279.3元/月点击自助购买成都电信优化线路8vCPU16G40G+50G2...
福州云服务器 1核 2G 2M 12元/月(买5个月) 萤光云
厦门靠谱云股份有限公司 双十一到了,站长我就给介绍一家折扣力度名列前茅的云厂商——萤光云。1H2G2M的高防50G云服务器,依照他们的规则叠加优惠,可以做到12元/月。更大配置和带宽的价格,也在一般云厂商中脱颖而出,性价比超高。官网:www.lightnode.cn叠加优惠:全区季付55折+满100-50各个配置价格表:地域配置双十一优惠价说明福州(带50G防御)/上海/北京1H2G2M12元/月...

robots txt协议为你推荐
-
显卡挖矿啥意思显卡怎么分辨是不是矿卡?挖矿卡又是什么意思?row函数EXCEL 中的 ROW函数1u1U的 定义郭凡生馬云的簡介3Qwebcrackwebcrack4网页密码slideshare佳能复印MG3620怎么使用?保留两位有效数字物理中保留两位有效数字是保留小数点后的两位还是从小数点前不是0的数开始保留两位?spawning急救!编好C++程序后(确认无误),再编译时总出现error spawning 是什么意思?是不是系统出了问题radius认证电信或网通的RADIUS认证都记录些什么?谁能说说ISP的宽带帐号检查流程欢迎页面windows欢迎界面