搜索引擎制作怎么制作搜索引擎
怎么制作搜索引擎啊?
<!--Google站内搜索开始--> <form method=get action=" /search"> <input type=text name=q> <input type=submit name=btnG value="Google 搜索"> <input type=hidden name=ie value=GB2312> <input type=hidden name=oe value=GB2312> <input type=hidden name=hl value=zh-CN> <input type=hidden name=domains value="你的地址"> <input type=hidden name=sitesearch value="你的地址"> </form> <!--Google站内搜索结束--> 下面是Google和百度的Javascript版的站内搜索代码: <!--Google站内搜索开始--> <script type="text/javascript"> function googlesearch () { var wq=document.getElementsByName("wq")[0].value; var link=" /search?domains=你的地址搜索引擎是什么制作出来的?像百度那样!
如果只是想在网页上放一个搜索引擎,加几句代码就可以,把要搜索的信息连到百度或GOOGLE上了,就转到百度的搜索了。如果想做搜索引擎就很麻烦了,投资也很大。
如果是那个连接的代码的话,如下: sousuo.asp <form method="get" action="zhuanxiang.asp"> <input type="text" name="searchstrings"> <Input type="submit" name ="search" value="搜索"> <p> <input name="goURL" type = "radio" Value="百度" checked>百度 <input name="goURL" type = "radio" Value="Yahoo" >Yahoo </form> zhuanxiang.asp <% response.buffer=true Dim strUrlRedirTo,strSearchStrings strSearchStrings=trim(request.QueryString("SearchStrings")) If (Len(strSearchStrings)) then strSearchStrings=Server.UrlEncode(strSearchStrings) If request.QueryString("goURL")="百度" then strUrlRedirTo="/baidu?word="&strSearchStrings end if If request.QueryString("goURL")="Yahoo" then strUrlRedirTo="/search/?p="&strSearchStrings end if response.redirect ("strUrlRedirTo") end if %> 做搜索引擎不是一天两天就能的,你好很多很多服务器,然后检索网络,制成一个信息库,所以你要很好的软件支持,资金投入也是很大的 /question/11040813.html?si=1
自己能做像百度一样的搜索引擎吗?
可以自己做的! 顺便给你点资料: 一、搜索引擎的分类 获得网站网页资料,能够建立数据库并提供查询的系统,我们都可以把它叫做搜索引擎。按照工作原理的不同,可以把它们分为两个基本类别:全文搜索引擎(FullText Search Engine)和分类目录Directory)。
全文搜索引擎的数据库是依靠一个叫“网络机器人(Spider)”或叫“网络蜘蛛(crawlers)”的软件,通过网络上的各种链接自动获取大量网页信息内容,并按以定的规则分析整理形成的。
Google、百度都是比较典型的全文搜索引擎系统。
分类目录则是通过人工的方式收集整理网站资料形成数据库的,比如雅虎中国以及国内的搜狐、新浪、网易分类目录。
另外,在网上的一些导航站点,也可以归属为原始的分类目录,比如“网址之家”。
全文搜索引擎和分类目录在使用上各有长短。
全文搜索引擎因为依靠软件进行,所以数据库的容量非常庞大,但是,它的查询结果往往不够准确;分类目录依靠人工收集和整理网站,能够提供更为准确的查询结果,但收集的内容却非常有限。
为了取长补短,现在的很多搜索引擎,都同时提供这两类查询,一般对全文搜索引擎的查询称为搜索“所有网站”或“全部网站”,比如Google的全文搜索(/intl/zh-CN/);把对分类目录的查询称为搜索“分类目录”或搜索“分类网站”,比如新浪搜索和雅虎中国搜索(/dirsrch/)。
在网上,对这两类搜索引擎进行整合,还产生了其它的搜索服务,在这里,我们权且也把它们称作搜索引擎,主要有这两类: ⒈元搜索引擎(META Search Engine)。
这类搜索引擎一般都没有自己网络机器人及数据库,它们的搜索结果是通过调用、控制和优化其它多个独立搜索引擎的搜索结果并以统一的格式在同一界面集中显示。
元搜索引擎虽没有“网络机器人”或“网络蜘蛛”,也无独立的索引数据库,但在检索请求提交、检索接口代理和检索结果显示等方面,均有自己研发的特色元搜索技术。
比如“metaFisher元搜索引擎” (/fish/),它就调用和整合了Google、Yahoo、AlltheWeb、百度和OpenFind等多家搜索引擎的数据。
⒉集成搜索引擎(All-in-One Search Page)。
集成搜索引擎是通过网络技术,在一个网页上链接很多个独立搜索引擎,查询时,点选或指定搜索引擎,一次输入,多个搜索引擎同时查询,搜索结果由各搜索引擎分别以不同页面显示,比如“网际瑞士军刀”(/%7Efree/search1.htm)。
二、搜索引擎的工作原理 全文搜索引擎的“网络机器人”或“网络蜘蛛”是一种网络上的软件,它遍历Web空间,能够扫描一定IP地址范围内的网站,并沿着网络上的链接从一个网页到另一个网页,从一个网站到另一个网站采集网页资料。
它为保证采集的资料最新,还会回访已抓取过的网页。
网络机器人或网络蜘蛛采集的网页,还要有其它程序进行分析,根据一定的相关度算法进行大量的计算建立网页索引,才能添加到索引数据库中。
我们平时看到的全文搜索引擎,实际上只是一个搜索引擎系统的检索界面,当你输入关键词进行查询时,搜索引擎会从庞大的数据库中找到符合该关键词的所有相关网页的索引,并按一定的排名规则呈现给我们。
不同的搜索引擎,网页索引数据库不同,排名规则也不尽相同,所以,当我们以同一关键词用不同的搜索引擎查询时,搜索结果也就不尽相同。
和全文搜索引擎一样,分类目录的整个工作过程也同样分为收集信息、分析信息和查询信息三部分,只不过分类目录的收集、分析信息两部分主要依靠人工完成。
分类目录一般都有专门的编辑人员,负责收集网站的信息。
随着收录站点的增多,现在一般都是由站点管理者递交自己的网站信息给分类目录,然后由分类目录的编辑人员审核递交的网站,以决定是否收录该站点。
如果该站点审核通过,分类目录的编辑人员还需要分析该站点的内容,并将该站点放在相应的类别和目录中。
所有这些收录的站点同样被存放在一个“索引数据库”中。
用户在查询信息时,可以选择按照关键词搜索,也可按分类目录逐层查找。
如以关键词搜索,返回的结果跟全文搜索引擎一样,也是根据信息关联程度排列网站。
需要注意的是,分类目录的关键词查询只能在网站的名称、网址、简介等内容中进行,它的查询结果也只是被收录网站首页的URL地址,而不是具体的页面。
分类目录就像一个电话号码薄一样,按照各个网站的性质,把其网址分门别类排在一起,大类下面套着小类,一直到各个网站的详细地址,一般还会提供各个网站的内容简介,用户不使用关键词也可进行查询,只要找到相关目录,就完全可以找到相关的网站(注意:是相关的网站,而不是这个网站上某个网页的内容,某一目录中网站的排名一般是按照标题字母的先后顺序或者收录的时间顺序决定的)。
搜索引擎并不真正搜索互联网,它搜索的实际上是预先整理好的网页索引数据库。
真正意义上的搜索引擎,通常指的是收集了因特网上几千万到几十亿个网页并对网页中的每一个词(即关键词)进行索引,建立索引数据库的全文搜索引擎。
当用户查找某个关键词的时候,所有在页面内容中包含了该关键词的网页都将作为搜索结果被搜出来。
在经过复杂的算法进行排序后,这些结果将按照与搜索关键词的相关度高低,依次排列。
现在的搜索引擎已普遍使用超链分析技术,除了分析索引网页本身的内容,还分析索引所有指向该网页的链接的URL、AnchorText、甚至链接周围的文字。
所以,有时候,即使某个网页A中并没有某个词比如“恶魔撒旦”,但如果有别的网页B用链接“恶魔撒旦”指向这个网页A,那么用户搜索“恶魔撒旦”时也能找到网页A。
而且,如果有越多网页(C、D、E、F……)用名为“恶魔撒旦”的链接指向这个网页A,或者给出这个链接的源网页(B、C、D、E、F……)越优秀,那么网页A在用户搜索“恶魔撒旦”时也会被认为更相关,排序也会越靠前。
搜索引擎的原理,可以看做三步:从互联网上抓取网页→建立索引数据库→在索引数据库中搜索排序。
从互联网上抓取网页 利用能够从互联网上自动收集网页的Spider系统程序,自动访问互联网,并沿着任何网页中的所有URL爬到其它网页,重复这过程,并把爬过的所有网页收集回来。
建立索引数据库 由分析索引系统程序对收集回来的网页进行分析,提取相关网页信息(包括网页所在URL、编码类型、页面内容包含的关键词、关键词位置、生成时间、大小、与其它网页的链接关系等),根据一定的相关度算法进行大量复杂计算,得到每一个网页针对页面内容中及超链中每一个关键词的相关度(或重要性),然后用这些相关信息建立网页索引数据库。
在索引数据库中搜索排序 当用户输入关键词搜索后,由搜索系统程序从网页索引数据库中找到符合该关键词的所有相关网页。
因为所有相关网页针对该关键词的相关度早已算好,所以只需按照现成的相关度数值排序,相关度越高,排名越靠前。
最后,由页面生成系统将搜索结果的链接地址和页面内容摘要等内容组织起来返回给用户。
搜索引擎的Spider一般要定期重新访问所有网页(各搜索引擎的周期不同,可能是几天、几周或几月,也可能对不同重要性的网页有不同的更新频率),更新网页索引数据库,以反映出网页内容的更新情况,增加新的网页信息,去除死链接,并根据网页内容和链接关系的变化重新排序。
这样,网页的具体内容和变化情况就会反映到用户查询的结果中。
互联网虽然只有一个,但各搜索引擎的能力和偏好不同,所以抓取的网页各不相同,排序算法也各不相同。
大型搜索引擎的数据库储存了互联网上几亿至几十亿的网页索引,数据量达到几千G甚至几万G。
但即使最大的搜索引擎建立超过二十亿网页的索引数据库,也只能占到互联网上普通网页的不到30%,不同搜索引擎之间的网页数据重叠率一般在70%以下。
我们使用不同搜索引擎的重要原因,就是因为它们能分别搜索到不同的内容。
而互联网上有更大量的内容,是搜索引擎无法抓取索引的,也是我们无法用搜索引擎搜索到的。
你心里应该有这个概念:搜索引擎只能搜到它网页索引数据库里储存的内容。
你也应该有这个概念:如果搜索引擎的网页索引数据库里应该有而你没有搜出来,那是你的能力问题,学习搜索技巧可以大幅度提高你的搜索能力。
怎么制作搜索引擎
<html> <body> <table width="365" height="44" class="sch"> <tr> <form name=f action=" /s" onSubmit="DynamicForm.submit();return false;"> <td width="258"><div id="sugOut"> <input value="" name="wd" maxlength=100 id="kww" plete="off"> </td>
<td width="95"><button type="submit">我的所搜引擎</button></td> </form> </table> </body> </html>
将上面的保存为HTML文件,就好了
- 搜索引擎制作怎么制作搜索引擎相关文档
- 搜索引擎制作如何制作搜索引擎? 像百度这样的!
- 搜索引擎制作怎样让搜索引擎搜到自己制作的网页?
- 搜索引擎制作怎么制作网页中的搜索引擎啊?~~谢谢
raksmart:全新cloud云服务器系列测评,告诉你raksmart新产品效果好不好
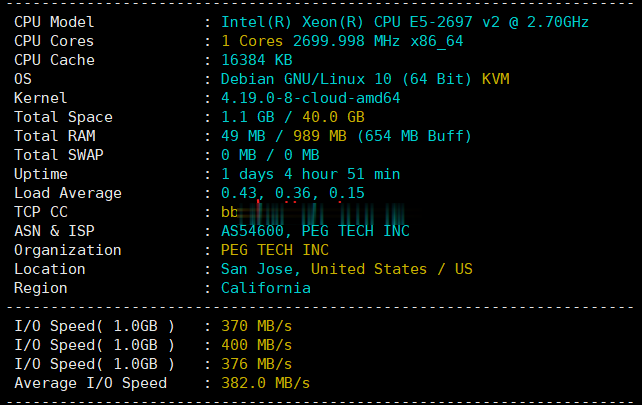
2021年6月底,raksmart开发出来的新产品“cloud-云服务器”正式上线对外售卖,当前只有美国硅谷机房(或许以后会有其他数据中心加入)可供选择。或许你会问raksmart云服务器怎么样啊、raksm云服务器好不好、网络速度快不好之类的废话(不实测的话),本着主机测评趟雷、大家受益的原则,先开一个给大家测评一下!官方网站:https://www.raksmart.com云服务器的说明:底层...
亚州云-美国Care云服务器,618大带宽美国Care年付云活动服务器,采用KVM架构,支持3天免费无理由退款!
官方网站:点击访问亚州云活动官网活动方案:地区:美国CERA(联通)CPU:1核(可加)内存:1G(可加)硬盘:40G系统盘+20G数据盘架构:KVM流量:无限制带宽:100Mbps(可加)IPv4:1个价格:¥128/年(年付为4折)购买:直达订购链接测试IP:45.145.7.3Tips:不满意三天无理由退回充值账户!地区:枣庄电信高防防御:100GCPU:8核(可加)内存:4G(可加)硬盘:...

RAKsmart 黑色星期五云服务器七折优惠 站群服务器首月半价
一年一度的黑色星期五和网络星期一活动陆续到来,看到各大服务商都有发布促销活动。同时RAKsmart商家我们也是比较熟悉的,这次是继双十一活动之后的促销活动。在活动产品中基本上沿袭双11的活动策略,比如有提供云服务器七折优惠,站群服务器首月半价、还有新人赠送红包等活动。如果我们有需要RAKsmart商家VPS、云服务器、独立服务器等产品的可以看看他们家的活动。这次活动截止到11月30日。第一、限时限...
-
限制局域网网速怎么限制局域网的网速?常用软件开发工具网站开发过程中常用的工具有哪些怎么取消焦点WOW焦点怎么解除!windows7正版验证怎样验证windows7是不是正版?qq空间个性域名QQ空间里什么是 空间个性域名qq空间个性域名Qq空间的个性域名是什么意思。多重阴影[讨论]《多重阴影》的中文配音好熟悉啊!做视频的免费软件求有哪种视频制作软件是全免费的啊?如何修改手机ip安卓手机怎样设置ID发送验证码怎样向好友发微信验证码