zookeeperjgroups 和 zookeeper或者mq有什么区别
zookeeper 时间:2021-08-26 阅读:()
zookeeper是怎么配置的
(1)配置管理集中式的配置管理在应用集群中是非常常见的,一般商业公司内部都会实现一套集中的配置管理中心,应对不同的应用集群对于共享各自配置的需求,并且在配置变更时能够通知到集群中的每一个机器。Zookeeper很容易实现这种集中式的配置管理,比如将APP1的所有配置配置到/APP1znode下,APP1所有机器一启动就对/APP1这个节点进行监控(zk.exist("/APP1",true)),并且实现回调方法Watcher,那么在zookeeper上/APP1znode节点下数据发生变化的时候,每个机器都会收到通知,Watcher方法将会被执行,那么应用再取下数据即可(zk.getData("/APP1",false,null));以上这个例子只是简单的粗颗粒度配置监控,细颗粒度的数据可以进行分层级监控,这一切都是可以设计和控制的。
(2)集群管理应用集群中,我们常常需要让每一个机器知道集群中(或依赖的其他某一个集群)哪些机器是活着的,并且在集群机器因为宕机,网络断链等原因能够不在人工介入的情况下迅速通知到每一个机器。
Zookeeper同样很容易实现这个功能,比如我在zookeeper服务器端有一个znode叫/APP1SERVERS,那么集群中每一个机器启动的时候都去这个节点下创建一个EPHEMERAL类型的节点,比如server1创建/APP1SERVERS/SERVER1(可以使用ip,保证不重复),server2创建/APP1SERVERS/SERVER2,然后SERVER1和SERVER2都watch/APP1SERVERS这个父节点,那么也就是这个父节点下数据或者子节点变化都会通知对该节点进行watch的客户端。
因为EPHEMERAL类型节点有一个很重要的特性,就是客户端和服务器端连接断掉或者session过期就会使节点消失,那么在某一个机器挂掉或者断链的时候,其对应的节点就会消失,然后集群中所有对/APP1SERVERS进行watch的客户端都会收到通知,然后取得最新列表即可。
另外有一个应用场景就是集群选master,一旦master挂掉能够马上能从slave中选出一个master,实现步骤和前者一样,只是机器在启动的时候在APP1SERVERS创建的节点类型变为EPHEMERAL_SEQUENTIAL类型,这样每个节点会自动被编号,例如zk.create("/testRootPath/testChildPath1","1".getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUENTIAL);zk.create("/testRootPath/testChildPath2","2".getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUENTIAL);zk.create("/testRootPath/testChildPath3","3".getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUENTIAL);//创建一个子目录节点zk.create("/testRootPath/testChildPath4","4".getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL_SEQUENTIAL);System.out.println(zk.getChildren("/testRootPath",false));打印结果:[testChildPath10000000000,testChildPath20000000001,testChildPath40000000003,testChildPath30000000002]zk.create("/testRootPath","testRootData".getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);//创建一个子目录节点zk.create("/testRootPath/testChildPath1","1".getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL);zk.create("/testRootPath/testChildPath2","2".getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL);zk.create("/testRootPath/testChildPath3","3".getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL);//创建一个子目录节点zk.create("/testRootPath/testChildPath4","4".getBytes(),Ids.OPEN_ACL_UNSAFE,CreateMode.EPHEMERAL);System.out.println(zk.getChildren("/testRootPath",false));打印结果:[testChildPath2,testChildPath1,testChildPath4,testChildPath3]我们默认规定编号最小的为master,所以当我们对/APP1SERVERS节点做监控的时候,得到服务器列表,只要所有集群机器逻辑认为最小编号节点为master,那么master就被选出,而这个master宕机的时候,相应的znode会消失,然后新的服务器列表就被推送到客户端,然后每个节点逻辑认为最小编号节点为master,这样就做到动态master选举。
如何启动ZooKeeper
Zookeeper的启动入口.apache.zookeeper.server.quorum.QuorumPeerMain。在这个类的main方法里进入了zookeeper的启动过程,首先我们会解析配置文件,即zoo.cfg和myid。
这样我们就知道了dataDir和dataLogDir指向哪儿了,然后就可以启动日志清理任务了(如果配置了的话)。
DatadirCleanupManager purgeMgr = new DatadirCleanupManager(config .getDataDir(), config.getDataLogDir(), config .getSnapRetainCount(), config.getPurgeInterval()); purgeMgr.start(); 接下来会初始化ServerCnxnFactory,这个是用来接收来自客户端的连接的,也就是这里启动的是一个tcp server。
在Zookeeper里提供两种tcp server的实现,一个是使用java原生NIO的方式,另外一个是使用Netty。
默认是java nio的方式,一个典型的Reactor模型。
因为java nio编程并不是本文的重点,所以在这里就只是简单的介绍一下。
//首先根据配置创建对应factory的实例:NIOServerCnxnFactory 或者 NettyServerCnxnFactory xnFactory = ServerCnxnFactory.createFactory(); //初始化配置 cnxnFactory.configure(config.getClientPortAddress(),config.getMaxClientCnxns()); 创建几个SelectorThread处理具体的数据读取和写出。
先是创建ServerSocketChannel,bind等 this.ss = ServerSocketChannel.open(); ss.socket().setReuseAddress(true); ss.socket().bind(addr); ss.configureBlocking(false); 然后创建一个eptThread线程来接收客户端的连接。
这一部分就是处理客户端请求的模块了,如果遇到有客户端请求的问题可以看看这部分。
接下来就进入初始化的主要部分了,首先会创建一个QuorumPeer实例,这个类就是表示zookeeper集群中的一个节点。
初始化QuorumPeer的时候有这么几个关键点: 1. 初始化FileTxnSnapLog,这个类主要管理Zookeeper中的操作日志(WAL)和snapshot。
2. 初始化ZKDatabase,这个类就是Zookeeper的目录结构在内存中的表示,所有的操作最后都会映射到这个类上面来。
3. 初始化决议validator(QuorumVerifier->QuorumMaj) (其实这一步,是在配置)。
这一步是从zoo.cfg的server.n这一部分初始化出集群的成员出来,有哪些需要参与投票(follower),有哪些只是observer。
还有决定half是多少等,这些都是zookeeper的核心。
在这一步,对于每个节点会初始化一个QuorumServer对象,并且放到allMembers,votingMembers,observingMembers这几个map里。
而且这里也对参与者的个数进行了一些判断。
4. leader选举 这一步非常重要,也是zookeeper里最复杂而最精华的一部分。
为什么不使用ZooKeeper
ZooKeeper作为发现服务的问题 ZooKeeper(注:ZooKeeper是著名Hadoop的一个子项目,旨在解决大规模分 布式应用场景下,服务协调同步(Coordinate Service)的问题;它可以为同在一个分布式系统中的其他服务提供:统一命名服务、配置管理、分布式锁服务、集群管理等功能)是个伟大的开源项目,它 很成熟,有相当大的社区来支持它的发展,而且在生产环境得到了广泛的使用;但是用它来做Service发现服务解决方案则是个错误。在分布式系统领域有个著名的 CAP定理(C- 数据一致性;A-服务可用性;P-服务对网络分区故障的容错性,这三个特性在任何分布式系统中不能同时满足,最多同时满足两个);ZooKeeper是个 CP的,即任何时刻对ZooKeeper的访问请求能得到一致的数据结果,同时系统对网络分割具备容错性;但是它不能保证每次服务请求的可用性(注:也就 是在极端环境下,ZooKeeper可能会丢弃一些请求,消费者程序需要重新请求才能获得结果)。
但是别忘了,ZooKeeper是分布式协调服务,它的 职责是保证数据(注:配置数据,状态数据)在其管辖下的所有服务之间保持同步、一致;所以就不难理解为什么ZooKeeper被设计成CP而不是AP特性 的了,如果是AP的,那么将会带来恐怖的后果(注:ZooKeeper就像交叉路口的信号灯一样,你能想象在交通要道突然信号灯失灵的情况吗?)。
而且, 作为ZooKeeper的核心实现算法 Zab,就是解决了分布式系统下数据如何在多个服务之间保持同步问题的。
作为一个分布式协同服务,ZooKeeper非常好,但是对于Service发现服务来说就不合适了;因为对于Service发现服务来说就算 是 返回了包含不实的信息的结果也比什么都不返回要好;再者,对于Service发现服务而言,宁可返回某服务5分钟之前在哪几个服务器上可用的信息,也不能 因为暂时的网络故障而找不到可用的服务器,而不返回任何结果。
所以说,用ZooKeeper来做Service发现服务是肯定错误的,如果你这么用就惨 了! 而且更何况,如果被用作Service发现服务,ZooKeeper本身并没有正确的处理网络分割的问题;而在云端,网络分割问题跟其他类型的 故障一样的确会发生;所以最好提前对这个问题做好100%的准备。
就像 Jepsen在 ZooKeeper网站上发布的博客中所说:在ZooKeeper中,如果在同一个网络分区(partition)的节点数(nodes)数达不到 ZooKeeper选取Leader节点的“法定人数”时,它们就会从ZooKeeper中断开,当然同时也就不能提供Service发现服务了。
如果给ZooKeeper加上客户端缓存(注:给ZooKeeper节点配上本地缓存)或者其他类似技术的话可以缓解ZooKeeper因为网 络故障造成节点同步信息错误的问题。
Pinterest与 Airbnb公 司就使用了这个方法来防止ZooKeeper故障发生。
这种方式可以从表面上解决这个问题,具体地说,当部分或者所有节点跟ZooKeeper断开的情况 下,每个节点还可以从本地缓存中获取到数据;但是,即便如此,ZooKeeper下所有节点不可能保证任何时候都能缓存所有的服务注册信息。
如果 ZooKeeper下所有节点都断开了,或者集群中出现了网络分割的故障(注:由于交换机故障导致交换机底下的子网间不能互访);那么ZooKeeper 会将它们都从自己管理范围中剔除出去,外界就不能访问到这些节点了,即便这些节点本身是“健康”的,可以正常提供服务的;所以导致到达这些节点的服务请求 被丢失了。
(注:这也是为什么ZooKeeper不满足CAP中A的原因) 更深层次的原因是,ZooKeeper是按照CP原则构建的,也就是说它能保证每个节点的数据保持一致,而为ZooKeeper加上缓存的做法 的 目的是为了让ZooKeeper变得更加可靠(available);但是,ZooKeeper设计的本意是保持节点的数据一致,也就是CP。
所以,这样 一来,你可能既得不到一个数据一致的(CP)也得不到一个高可用的(AP)的Service发现服务了;因为,这相当于你在一个已有的CP系统上强制栓了 一个AP的系统,这在本质上就行不通的!一个Service发现服务应该从一开始就被设计成高可用的才行! 如果抛开CAP原理不管,正确的设置与维护ZooKeeper服务就非常的困难;错误会 经常发生, 导致很多工程被建立只是为了减轻维护ZooKeeper的难度。
这些错误不仅存在与客户端而且还存在于ZooKeeper服务器本身。
Knewton平台 很多故障就是由于ZooKeeper使用不当而导致的。
那些看似简单的操作,如:正确的重建观察者(reestablishing watcher)、客户端Session与异常的处理与在ZK窗口中管理内存都是非常容易导致ZooKeeper出错的。
同时,我们确实也遇到过 ZooKeeper的一些经典bug: ZooKeeper-1159 与 ZooKeeper-1576; 我们甚至在生产环境中遇到过ZooKeeper选举Leader节点失败的情况。
这些问题之所以会出现,在于ZooKeeper需要管理与保障所管辖服务 群的Session与网络连接资源(注:这些资源的管理在分布式系统环境下是极其困难的);但是它不负责管理服务的发现,所以使用ZooKeeper当 Service发现服务得不偿失。
做出正确的选择:Eureka的成功 我们把Service发现服务从ZooKeeper切换到了Eureka平台,它是一个开 源的服务发现解决方案,由Netflix公司开发。
(注:Eureka由两个组件组成:Eureka服务器和Eureka客户端。
Eureka服务器用作 服务注册服务器。
Eureka客户端是一个java客户端,用来简化与服务器的交互、作为轮询负载均衡器,并提供服务的故障切换支持。
)Eureka一开 始就被设计成高可用与可伸缩的Service发现服务,这两个特点也是Netflix公司开发所有平台的两个特色。
( 他们都在讨论Eureka)。
自从切换工作开始到现在,我们实现了在生产环境中所有依赖于Eureka的产品没有下线维护的记录。
我们也被告知过,在云平 台做服务迁移注定要遇到失败;但是我们从这个例子中得到的经验是,一个优秀的Service发现服务在其中发挥了至关重要的作用! 首先,在Eureka平台中,如果某台服务器宕机,Eureka不会有类似于ZooKeeper的选举leader的过程;客户端请求会自动切 换 到新的Eureka节点;当宕机的服务器重新恢复后,Eureka会再次将其纳入到服务器集群管理之中;而对于它来说,所有要做的无非是同步一些新的服务 注册信息而已。
所以,再也不用担心有“掉队”的服务器恢复以后,会从Eureka服务器集群中剔除出去的风险了。
Eureka甚至被设计用来应付范围更广 的网络分割故障,并实现“0”宕机维护需求。
当网络分割故障发生时,每个Eureka节点,会持续的对外提供服务(注:ZooKeeper不会):接收新 的服务注册同时将它们提供给下游的服务发现请求。
这样一来,就可以实现在同一个子网中(same side of partition),新发布的服务仍然可以被发现与访问。
但是,Eureka做到的不止这些。
正常配置下,Eureka内置了心跳服务,用于淘汰一些“濒死”的服务器;如果在Eureka中注册的服 务, 它的“心跳”变得迟缓时,Eureka会将其整个剔除出管理范围(这点有点像ZooKeeper的做法)。
这是个很好的功能,但是当网络分割故障发生时, 这也是非常危险的;因为,那些因为网络问题(注:心跳慢被剔除了)而被剔除出去的服务器本身是很”健康“的,只是因为网络分割故障把Eureka集群分割 成了独立的子网而不能互访而已。
幸运的是,Netflix考虑到了这个缺陷。
如果Eureka服务节点在短时间里丢失了大量的心跳连接(注:可能发生了网络故障),那么这个 Eureka节点会进入”自我保护模式“,同时保留那些“心跳死亡“的服务注册信息不过期。
此时,这个Eureka节点对于新的服务还能提供注册服务,对 于”死亡“的仍然保留,以防还有客户端向其发起请求。
当网络故障恢复后,这个Eureka节点会退出”自我保护模式“。
所以Eureka的哲学是,同时保 留”好数据“与”坏数据“总比丢掉任何”好数据“要更好,所以这种模式在实践中非常有效。
最后,Eureka还有客户端缓存功能(注:Eureka分为客户端程序与服务器端程序两个部分,客户端程序负责向外提供注册与发现服务接 口)。
所以即便Eureka集群中所有节点都失效,或者发生网络分割故障导致客户端不能访问任何一台Eureka服务器;Eureka服务的消费者仍然可以通过 Eureka客户端缓存来获取现有的服务注册信息。
甚至最极端的环境下,所有正常的Eureka节点都不对请求产生相应,也没有更好的服务器解决方案来解 决这种问题时;得益于Eureka的客户端缓存技术,消费者服务仍然可以通过Eureka客户端查询与获取注册服务信息,这点很重要。
Eureka的构架保证了它能够成为Service发现服务。
它相对与ZooKeeper来说剔除了Leader节点的选取或者事务日志机制, 这 样做有利于减少使用者维护的难度也保证了Eureka的在运行时的健壮性。
而且Eureka就是为发现服务所设计的,它有独立的客户端程序库,同时提供心 跳服务、服务健康监测、自动发布服务与自动刷新缓存的功能。
但是,如果使用ZooKeeper你必须自己来实现这些功能。
Eureka的所有库都是开源 的,所有人都能看到与使用这些源代码,这比那些只有一两个人能看或者维护的客户端库要好。
维护Eureka服务器也非常的简单,比如,切换一个节点只需要在现有EIP下移除一个现有的节点然后添加一个新的就行。
Eureka提供了一 个 web-based的图形化的运维界面,在这个界面中可以查看Eureka所管理的注册服务的运行状态信息:是否健康,运行日志等。
Eureka甚至提供 了Restful-API接口,方便第三方程序集成Eureka的功能。
zookeeper在Dubbo中扮演了一个什么角色,起到了什么作用啊?
Zookeeper是゛dubbo゛推荐的注册中心,是管理员! 就像一个分布式的项目,web层与 service层被拆分了开来, 部署在不同的tomcat中, 我在web层 需要调用 service层的接口,但是两个运行在不同tomcat下的服务无法直接互调接口,那么就可以通过zookeeper和dubbo实现。我们通过dubbo 建立ItemService这个服务,并且到zookeeper上面注册,填写对应的zookeeper服务所在 的IP及端口号。
【按照我上面的比喻就是,学生注册入学(接口是学号,学生本人是impl实现),填写学校教务网网址(就是zookeeper)】 dubbo的服务提供者会在zookeeper上面创建一个临时节点,表明自己的ip和端口,当消费者需要使用服务时,会先在zookeeper上面查询,找到服务提供者,做一些负载的选择(比如随机、轮流),然后按照这些信息,访问服务提供者。
Zookeeper一个分布式的服务框架,是树型的目录服务的数据存储,能做到集群管理数据 ,这里能很好的作为Dubbo服务的注册中心,Dubbo能与Zookeeper做到集群部署,当提供者出现断电等异常停机时,Zookeeper注册中心能自动删除提供者信息,当提供者重启时,能自动恢复注册数据,以及订阅请求。
zookeeper 是怎么实现的
利用节点名称的唯一性来实现共享锁 ZooKeeper抽象出来的节点结构是一个和unix文件系统类似的小型的树状的目录结构。ZooKeeper机制规定:同一个目录下只能有一个唯一的文件名
jgroups 和 zookeeper或者mq有什么区别
UDP 。zk用来管理集群差别自然是知道的、zookeeper跨机房容灾系统的调试、zookeepeer集群简介,跨机房容灾系统架构设计 第2节、zookeeper的java客户端与spring整合(上) 第3节、zookeeper的java客户端与spring整合(下) 第4节、zookeeper-3watcher使用(上) 第5节、zookeeper-3watcher使用(下) 第6节、Curator介绍与使用 第7节,保证数据一致性。
mq消息队列,实际上也是发消息啊。
一、课程使用到的软件及版本: centos系统,zookeeper 3.4.6,Spring4 二,不过向底层看都是通讯。
jgroups走TCP ,可以发现宕机的机器(这点jgroups好像能做到)、掌控zookeeper java客户端开发 3、熟练运用curator的各种特性 三、课程目录 第1节、课程目标: 1、熟练开发各种分布式应用 2、zookeeper跨机房容灾系统设计两种方案详细讲解 第8节、zookeeper跨机房容灾具体实现 第9节
- zookeeperjgroups 和 zookeeper或者mq有什么区别相关文档
- zookeeperzookeeper 可以做什么
- zookeeper什么是Zookeeper,Zookeeper的作用是什么,在Hadoop及hbase中具体,7
- zookeeperzookeeper 到底是个什么
- zookeeper为什么要使用zookeeper?有什么功能吗?
华为云(69元)828促销活动 2G1M云服务器
华为云818上云活动活动截止到8月31日。1、秒杀限时区优惠仅限一单!云服务器秒杀价低至0.59折,每日9点开抢秒杀抢购活动仅限早上9点开始,有限量库存的。2G1M云服务器低至首年69元。2、新用户折扣区优惠仅限一单!购云服务器享3折起加购主机安全及数据库。企业和个人的优惠力度和方案是不同的。比如还有.CN域名首年8元。华为云服务器CPU资源正常没有扣量。3、抽奖活动在8.4-8.31日期间注册并...
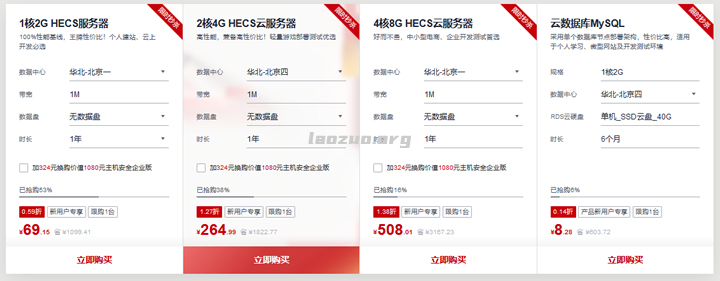
易探云:香港大带宽/大内存物理机服务器550元;20Mbps带宽!三网BGP线路
易探云怎么样?易探云隶属于纯乐电商旗下网络服务品牌,香港NTT Communications合作伙伴,YiTanCloud Limited旗下合作云计算品牌,数十年云计算行业经验。发展至今,我们已凝聚起港内领先的开发和运维团队,积累起4年市场服务经验,提供电话热线/在线咨询/服务单系统等多种沟通渠道,7*24不间断服务,3分钟快速响应。目前,易探云提供香港大带宽20Mbps、16G DDR3内存、...
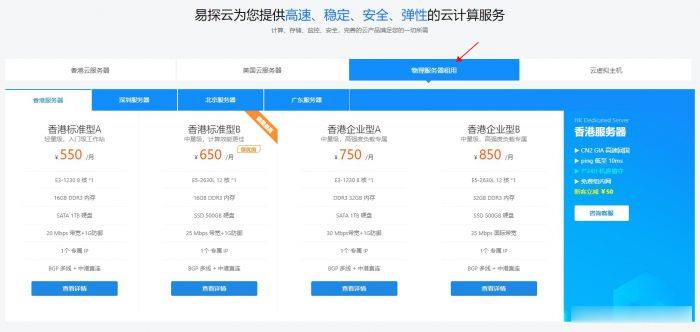
TabbyCloud周年庆&七夕节活动 美國INAP 香港CN2
TabbyCloud迎来一周岁的生日啦!在这一年里,感谢您包容我们的不足和缺点,在您的理解与建议下我们也在不断改变与成长。为庆祝TabbyCloud运营一周年和七夕节,TabbyCloud推出以下活动。TabbyCloud周年庆&七夕节活动官方网站:https://tabbycloud.com/香港CN2: https://tabbycloud.com/cart.php?gid=16购买链...
zookeeper为你推荐
-
阈值电压在MOS管里面,为什么阈值电压正负跟是否是耗尽型还是增强型有至?移动开发移动应用开发具体做什么,不要复制粘贴,说简单点,女生适合吗?360网络收藏夹360浏览器的网络收藏夹怎么导出啊?混乱模式拳皇2002李梅的混乱模式出招网通玩电信游戏卡怎么办我的网是网通,我玩电信区的游戏,总是卡,怎么办呢照片ps是什么意思照片上的PS是什么意思?2017双112017双十一晚会播出时间,2017双11晚会举办城市网络黑科技受欢迎的十大黑科技产品有哪些系统部署方案一个软件项目的实施方案要怎么写宽带天线为什么我家装了宽带有4个无线信号?