extractor522av.com
522av.com 时间:2021-03-21 阅读:()
ORIGINALRESEARCHARTICLEpublished:12April2012doi:10.
3389/fnins.
2012.
00032Comparisonbetweenframe-constrainedx-pixel-valueandframe-freespiking-dynamic-pixelconvNetsforvisualprocessingClémentFarabet1,2*,RafaelPaz3,JosePérez-Carrasco4,CarlosZamarreo-Ramos4,AlejandroLinares-Barranco3*,YannLeCun1,EugenioCulurciello2*,TeresaSerrano-Gotarredona4andBernabeLinares-Barranco41ComputerScienceDepartment,CourantInstituteofMathematicalSciences,NewYorkUniversity,NewYork,NY,USA2Laboratoired'InformatiqueGaspard-Monge,UniversitéParis-Est,quipeA3SI,ESIEEParis,ChampssurMarne,Marne-la-Vallée,France3RoboticandTechnologyofComputersGroup,UniversityofSeville,Seville,Spain4InstitutodeMicroelectrónicadeSevilla,IMSE-CNM-CSIC,Sevilla,SpainEditedby:TobiDelbruck,InstituteforNeuroinformatics,SwitzerlandReviewedby:TobiDelbruck,InstituteforNeuroinformatics,SwitzerlandAntonCivit,UniversityofSeville,SpainZhengmingFu,AdvancedMicroDevices,USA*Correspondence:ClémentFarabet,ComputerScienceDepartment,CourantInstituteofMathematicalSciences,NewYorkUniversity,715Broadway,12thFloor,NewYork,NY10003,USA.
e-mail:cfarabet@nyu.
edu;www.
clement.
farabet.
net;AlejandroLinares-Barranco,RoboticandTechnologyofComputersLab,UniversityofSeville,ETSIInformática,Av.
ReinaMercedess/n,41012-Sevilla,Spain.
e-mail:alinares@atc.
us.
es;EugenioCulurciello,WeldonSchoolofBiomedicalEngineering,PurdueUniversity,206S.
MartinJischkeDrive,Room2031,WestLafayette,IN47907,USA.
e-mail:euge@purdue.
eduMostscenesegmentationandcategorizationarchitecturesfortheextractionoffeaturesinimagesandpatchesmakeexhaustiveuseof2Dconvolutionoperationsfortemplatematching,templatesearch,anddenoising.
ConvolutionalNeuralNetworks(ConvNets)areoneexampleofsucharchitecturesthatcanimplementgeneral-purposebio-inspiredvisionsystems.
Instandarddigitalcomputers2Dconvolutionsareusuallyexpensiveintermsofresourceconsumptionandimposeseverelimitationsforefcientreal-timeapplications.
Nevertheless,neuro-cortexinspiredsolutions,likededicatedFrame-BasedorFrame-FreeSpikingConvNetConvolutionProcessors,areadvancingreal-timevisualprocessing.
Thesetwoapproachessharetheneuralinspiration,buteachofthemsolvestheproblemindif-ferentways.
Frame-BasedConvNetsprocessframebyframevideoinformationinaveryrobustandfastwaythatrequirestouseandsharetheavailablehardwareresources(suchas:multipliers,adders).
Hardwareresourcesarexed-andtime-multiplexedbyfetchingdatainandout.
Thusmemorybandwidthandsizeisimportantforgoodperformance.
Ontheotherhand,spike-basedconvolutionprocessorsareaframe-freealternativethatisabletoperformconvolutionofaspike-basedsourceofvisualinformationwithverylowlatency,whichmakesidealforveryhigh-speedapplications.
However,hardwareresourcesneedtobeavailableallthetimeandcannotbetime-multiplexed.
Thus,hardwareshouldbemodular,recongurable,andexpansible.
HardwareimplementationsinbothVLSIcustomintegratedcircuits(digitalandanalog)andFPGAhavebeenalreadyusedtodemonstratetheperformanceofthesesystems.
Inthispaperwepresentacomparisonstudyofthesetwoneuro-inspiredsolutions.
Abriefdescriptionofbothsystemsispresentedandalsodiscussionsabouttheirdifferences,prosandcons.
Keywords:convolutionalneuralnetwork,address-event-representation,spike-basedconvolutions,imageconvo-lutions,frame-freevision,FPGA,VHDL1.
INTRODUCTIONConventionalvisionsystemsprocesssequencesofframescap-turedbyvideosources,likewebcams,camcorders(CCDsen-sors),etc.
Forperformingcomplexobjectrecognitionalgorithms,sequencesofcomputationaloperationsareperformedforeachframe.
Thecomputationalpowerandspeedrequiredmakesitdifculttodevelopareal-timeautonomoussystem.
Butbrainsperformpowerfulandfastvisionprocessingusingsmallandslowcells(neurons)workinginparallelinatotallydifferentway.
Visionsensingandobjectrecognitioninthemammalianbrainisnotper-formedframebyframe.
Sensingandprocessingareperformedinacontinuousway,spikebyspike,withoutanynotionofframes.
Thevisualcortexiscomposedbyasetoflayers(Shepherd,1990;Serre,2006),startingfromtheretina.
Theprocessingstartsbeginningatthetimetheinformationiscapturedbytheretina.
Althoughcortexhasfeedbackconnections,itisknownthataveryfastandpurelyfeed-forwardrecognitionpathexistsinthevisualcortex(Thorpeetal.
,1996;Serre,2006).
Inrecentyearssignicantprogresshasbeenmadetowardtheunderstandingofthecomputationalprinciplesexploitedbythevisualcortex.
Manyarticialsystemsthatimplementbio-inspiredsoftwaremodelsusebiological-like(convolutionbased)process-ingthatoutperformmoreconventionallyengineeredmachines(Neubauer,1998).
Thesesystemsrunatlowspeedswhenimple-mentedassoftwareprogramsonconventionalcomputers.
Forreal-timesolutionsdirecthardwareimplementationsofthesemodelsarerequired.
However,hardwareengineersfacealargehurdlewhentryingtomimicthebio-inspiredlayeredstructureandthemassiveconnectivitywithinandbetweenlayers.
Agrow-ingnumberofresearchgroupsworld-widearemappingsomeofwww.
frontiersin.
orgApril2012|Volume6|Article32|1Farabetetal.
Comparison:framevs.
spikingconvNetsthesecomputationalprinciplesontobothreal-timespikinghard-warethroughthedevelopmentandexploitationoftheso-calledAER(Address-Event-Representation)technology,andreal-timestreamingFrame-BasedConvNetsonFPGAs.
ConvNetshavebeensuccessfullyusedinmanyrecognitionandclassicationtasksincludingdocumentrecognition(LeCunetal.
,1998a),objectrecognition(HuangandLeCun,2006;Ranzatoetal.
,2007;Jarrettetal.
,2009),facedetection(Osadchyetal.
,2005),androbotnavigation(Hadselletal.
,2007,2009).
AConvNetconsistsofmultiplelayersoflterbanksfollowedbynon-linearitiesandspatialpooling.
Eachlayertakesasinputtheoutputofprevi-ouslayerandbycombiningmultiplefeaturesandpoolingoverspace,extractscompositefeaturesoveralargerinputarea.
OncetheparametersofaConvNetaretrained,therecognitionoperationisperformedbyasimplefeed-forwardpass.
Thesimplicityofthefeed-forwardpasshaspushedseveralgroupstoimplementitascustomhardwarearchitectures.
MostofConvNethardwareimplementationsreportedovertheyearsarefortheframe-constrainedx-pixel-valueversion,astheymapdirectlyfromthesoftwareversions.
TherstonewastheANNAchip,amixedhigh-end,analog-digitalprocessorthatcouldcom-pute64simultaneous8*8convolutionsatapeakrateof4.
109MACs(multiply-accumulateoperationspersecond;Boseretal.
,1991;Sckingeretal.
,1992).
Subsequently,Cloutieretal.
pro-posedanFPGAimplementationofConvNets(Cloutieretal.
,1996),butttingitintothelimited-capacityFPGAsavailableatthosetimesrequiredtheuseofextremelylow-accuracyarith-metic.
ModernDSP-orientedFPGAsincludelargenumbersofhard-wiredmultiply-accumulateunitsthatcangreatlyspeedupcompute-intensiveoperations,suchasconvolutions.
Theframe-constrainedsystempresentedinthispapertakesfulladvantageofthehighlyparallelnatureofConvNetoperations,andthehigh-degreeofparallelismprovidedbymodernDSP-orientedFPGAs.
Achievedpeakratesareintheorderof1011MACs.
Ontheotherhand,Frame-freeSpiking-Dynamic-PixelCon-vNetscomputeinthespikedomain.
Noframesareusedforsensingandprocessingthevisualinformation.
Inthiscase,specialsensorsarerequiredwithaspike-basedoutput.
Spike-basedsensorsandprocessorstypicallyuseAER(Address-Event-Representation)inordertotransmittheinternalstateand/orresultsoftheneuronsinsideachiporFPGA.
AERwasoriginallyproposedalmosttwentyyearsbackinMead'sCaltechresearchlab(Sivilotti,1991).
SincethenAERhasbeenusedfundamentallyinvision(retina)sensors,suchassimplelightintensitytofrequencytransformations(Culurcielloetal.
,2003;Poschetal.
,2010),time-to-rst-spikecoding(Ruedietal.
,2003;ChenandBermak,2007),foveatedsensors(Azad-mehretal.
,2005),spatialcontrast(Costas-Santosetal.
,2007;Massarietal.
,2008;Ruedietal.
,2009;Leero-Bardalloetal.
,2010),temporalcontrast(Lichtsteineretal.
,1998;Poschetal.
,2010;Leero-Bardalloetal.
,2011),motionsensingandcomputa-tion,(Boahen,1999),andcombinedspatialandtemporalcontrastsensing(ZaghloulandBoahen,2004).
ButAERhasalsobeenusedforauditorysystems(Chanetal.
,2007),competitionandwinner-takes-allnetworks(Chiccaetal.
,2007;Osteretal.
,2008),andevenforsystemsdistributedoverwirelessnetworks(Teixeiraetal.
,2006).
Aftersensing,weneedSpikingSignalEventRepresentationtechniquescapableofefcientlyprocessingthesignalowcomingoutfromthesensors.
Forsimpleper-eventheuristicprocessingandltering,directsoftwarebasedsolutionscanbeused(Delbrück,2005,2008).
Otherschemesrelyonlook-uptablere-routingandeventrepetitionsfollowedbysingle-eventintegration(Vogelsteinetal.
,2007).
Alternatively,wecanndsomepioneeringworkintheliteratureaimingatperformingconvolutionallteringontheAERowproducedbyspikingretinas,(Vernieretal.
,1997;Choietal.
,2005),wheretheshapeofthelterkernelwashard-wired(eitherellipticorGabor).
Since2006,workingAERConvolutionchipshavebeenreportedwitharbitraryshapeprogrammablekernelofsizeupto32*32pixelspre-loadedontoaninternalkernel-RAM(Serrano-Gotarredonaetal.
,2006,2008;Camuas-Mesaetal.
,2011,2012).
ThisopensthepossibilityofimplementinginAERspikinghardwaregenericConvNets,wherelargenumberofconvolutionalmoduleswitharbitrarysizeandshapekernelsarerequired.
Inthispaperwepresent,discussandcomparetwodiffer-entneuro-cortexinspiredapproachesforreal-timevisualpro-cessingbasedonconvolutions:Frame-basedx-pixel-valueandFrame-freedynamic-pixel-spikingConvNetProcessinghardware.
Section2describesgenericConvNetsandtheirstructure.
Section3brieydescribesframe-freeConvNettypesofimple-mentations,andSection4describesaframe-constrainedFPGAimplementation.
Implementiondetailswillbegiveninaveryconcisemanner,sothereadercangraspthemainideasbehindeachimplementation.
Formoredetaileddescriptionsthereaderisrefertothecorrespondingreferences.
Finally,Section5providesacomparisonofbothcasesindicatingprosandconsofeach.
2.
STRUCTUREOFGENERICConvNetsFigure1showsatypicalhierarchicalstructureofafeed-forwardConvNet.
ConvolutionalNetworks(LeCunetal.
,1990,1998a),orConvNets,aretrainablemulti-stagearchitecturescomposedofmultiplestages.
Theinputandoutputofeachstagearesetsofarrayscalledfeaturemaps.
Forexample,iftheinputisacolorimage,eachfeaturemapwouldbea2Darraycontainingacolorchanneloftheinputimage(foranaudioinputeachfeaturemapwouldbea1Darray,andforavideoorvolumetricimage,itwouldbea3Darray).
Attheoutput,eachfeaturemaprepresentsapar-ticularfeatureextractedatalllocationsontheinputtoleratingdegreesofdeformationsandsizes.
Eachstageiscomposedofthreelayers:alterbanklayer,anon-linearitylayer,andafeaturepoolinglayer.
AtypicalConvNetiscomposedofone,two,orthreesuch3-layerstages,followedbyaclassicationmodule.
Eachlayertypeisnowdescribedforthecaseofimagerecognition.
2.
1.
FILTERBANKLAYER-FTheinputisa3Darraywithn12Dfeaturemapsofsizen2*n3,andcoordinates(xi,yi),withi=1,.
.
.
n1.
Let'scalleachinputfea-turemapfi=(xi,yi),withxi=1,.
.
.
n2andyi=1,.
.
.
n3.
Theoutputisalsoa3Darraycomposedofm1featuremapsofsizem2*m3andcoordinates(Xj,Yj)withj=1,.
.
.
m1.
Let'scalleachoutputfeaturemapFj=(Xj,Yj),withXj=1,.
.
.
m2andYj=1,.
.
.
m3.
Atrainablelter(kernel)wijinthelterbankhassizel1*l2andconnectsinputfeaturemapfitooutputfeaturemapFj.
TheFrontiersinNeuroscience|NeuromorphicEngineeringApril2012|Volume6|Article32|2Farabetetal.
Comparison:framevs.
spikingconvNetsFIGURE1|Architectureofatypicalconvolutionalnetworkforobjectrecognition.
ThisimplementsaconvolutionalfeatureextractorandalinearclassierforgenericN-classobjectrecognition.
Oncetrained,thenetworkcanbecomputedonarbitrarylargeinputimages,producingaclassicationmapasoutput.
modulecomputesFj=bj+iwijfiwhereisthe2Dconvolutionoperatorandbjisatrainablebiasparameter.
Eachlterdetectsaparticularfeatureateverylocationontheinput.
Hencespatiallytranslatingtheinputofafeaturedetectionlayerwilltranslatetheoutputbutleaveitotherwiseunchanged.
2.
2.
NON-LINEARITYLAYERIntraditionalConvNetsthissimplyconsistsofapointwisetanh()sigmoidfunctionappliedtoeachsite(Xj,Yj).
However,recentimplementationshaveusedmoresophisticatednon-linearities(LyuandSimoncelli,2008;Pintoetal.
,2008).
2.
3.
FEATUREPOOLINGLAYERThislayertreatseachfeaturemapseparately.
Initssimplestinstance,calledPA,itcomputestheaveragevaluesoveraneigh-borhoodineachfeaturemap.
Thisresultsinareduced-resolutionoutputfeaturemapwhichisrobusttosmallvariationsintheloca-tionoffeaturesinthepreviouslayer.
TheaverageoperationissometimesreplacedbyamaxPM.
TraditionalConvNetsuseapointwisetanh()afterthepoolinglayer,butmorerecentmodelsdonot.
Supervisedtrainingisperformedusingaformofstochasticgradientdescenttominimizethediscrepancybetweenthedesiredoutputandtheactualoutputofthenetwork.
Alltheltercoef-cientsinallthelayersareupdatedsimultaneouslybythelearningprocedure.
Thegradientsarecomputedwiththeback-propagationmethod.
DetailsoftheprocedurearegiveninLeCunetal.
(1998a),andmethodsforefcienttrainingaredetailedinLeCunetal.
(1998b).
3.
FRAME-FREESPIKING-DYNAMIC-PIXELConvNetsInframe-freespikingConvNetstheretinasensorpixelsgener-atespikesautonomously.
Pixelactivitychangescontinuously,asopposedtoframe-basedsystems,wherethepixelvalueisfrozenduringeachframetime.
Suchspikesaresenttoprojectioneldsinthenextlayer,andthecontributionofeachspikeisweightedbya2Dspatiallter/kernelvaluewijovertheprojectioneld.
Inthenextlayerpixels,incomingweightedspikesareaccumulated(integrated)untilapixelresitsownspikeforthenextlayer,andsoon.
EachpixelinanyConvolutionModulerepresentsitsstatebyitsinstantaneousspikingactivity.
Consequently,eachpixelatanylayerhastobepresentatanytimeanditsstatecannotbefetchedinandoutasinFrame-basedapproaches.
Thisisthemaindrawbackofthisapproach:allConvModuleshavetobethereinhardwareandhardwareresourcescannotbetime-multiplexed.
AdaptingConvNetstoSpikingSignalEvent-basedrepresen-tationsyieldssomeveryinterestingproperties.
Therstoneistheveryreducedlatencybetweentheinputandoutputeventowsofaspikingconvolutionprocessor.
Wecallthisthe"pseudo-simultaneity"betweeninputandoutputvisualows.
ThisisillustratedbytheexampleattheendofSection3.
ThesecondinterestingpropertyofimplementingSpikingEventConvolutions(orotheroperators,ingeneral)isitsmodularscala-bility.
Sinceeventowsareasynchronous,eachAERlinkbetweentwoconvolutionalmodulesisindependentandneedsnoglobalsystemlevelsynchronization.
Andthethirdinterestingpropertyofspike-basedhardware,ingeneral,isthatsinceprocessingisper-event,powerconsumptionis,inprinciple,alsoper-event.
Sinceeventsusuallycarryrelevantinformation,powerisconsumedasrelevantinformationissensed,transmitted,andprocessed.
Nextwedescribebrieythreewaysofcomputingwithspik-ingConvNets.
First,webrieydescribeanevent-basedsimulationsoftwaretoolforemulatingsuchspikingAERhardwaresystems.
Second,webrieysummarizesomeprogrammablekernelVLSIimplementations.
Andthird,similarFPGAimplementationsarediscussed.
3.
1.
SOFTWARESIMULATORAbehavioralevent-drivenAERsimulatorhasbeendevelopedfordescribingandstudyinggenericAERsystems(Pérez-Carrasco,2011).
Suchsimulatorisveryusefulfordesigningandanalyz-ingtheoperationofnewhardwaresystemscombiningexistingandnon-existingAERmodules.
Modulesareuser-denedandtheyareinterconnectedasdenedbyanetlist,andinputsaregivenbystimulusles.
ThesimulatorwaswritteninC++.
Thenetlistusesonlytwotypesofelements:AERmodules(instances)andAERlinks(channels).
AERlinksconstitutethenodesofthenetlistinanAERsystem.
Channelsrepresentpoint-to-pointcon-nections.
Splitterandmergerinstancesareusedforspreadingormerginglinks.
Figure2showsanexamplesystemanditstextlenetlistdescriptionwith7instancesand8channels.
Channel1isasourcechannel.
Allitseventsareavailableaprioriasanwww.
frontiersin.
orgApril2012|Volume6|Article32|3Farabetetal.
Comparison:framevs.
spikingconvNetsFIGURE2|ExamplenetlistanditsASCIIlenetlistdescription.
inputle.
Theseeventscanbepre-recordedbyarealAERretina(Lichtsteineretal.
,1998;Poschetal.
,2010;Leero-Bardalloetal.
,2011).
Eachinstanceisdenedbyaline.
Instanceoperationisdescribedbyauser-denedfunction.
Channelsaredescribedbylistsofevents.
Oncethesimulatorhasnished,therewillbealistoftime-stampedeventsforeachnode.
Eacheventisdenedby6values(TpR,TRqst,TAck,a,b,c).
Therst3aretimingparame-tersandtheotherthreeareopenuser-denedparametersthattheinstancesinterpretandinterchange.
Usually,aandbaretheeventaddress(x,y)andcitssign.
TRqstisthetimewhenaneventRqstwasgeneratedandTAckwhenitwasacknowledged.
TpRisthetimeofcreationofanevent(beforecommunicatingorarbitratingitoutofitssourcemodule).
Thesimulatorscansallchannelslook-ingfortheearliestunprocessedTpR.
Thiseventisprocessed:itsTRqstandTAckarecomputedandthestateoftheeventdestinationmodulesareupdated.
Ifthiscreatesnewevents,theyareaddedtotheendofthecorrespondinglinkseventlists,andthelistisre-sortedforindreasingTpR.
ThenthesimulatorlooksagainfortheearliestunprocessedTpR,andsoon.
3.
2.
VLSIIMPLEMENTATIONReportedVLSIimplementationsofAERspikingConvModules(eithermixed-signal,Serrano-Gotarredonaetal.
,2006,2008;orfullydigital,Camuas-Mesaetal.
,2011,2012)followtheoorplanarchitectureinFigure3,wherethefollowingblocksareshown:(1)arrayoflossyintegrate-and-repixels,(2)staticRAMthatholdsthestoredkernelin2'scomplementrepresentation,(3)synchro-nouscontroller,whichperformsthesequencingofalloperationsforeachinputeventandtheglobalforgettingmechanism,(4)high-speedclockgenerator,usedbythesynchronouscontroller,(5)congurationregistersthatstorecongurationparametersloadedatstartup,(6)left/rightcolumnshifter,toproperlyaligntheFIGURE3|Architectureoftheconvolutionchip.
FrontiersinNeuroscience|NeuromorphicEngineeringApril2012|Volume6|Article32|4Farabetetal.
Comparison:framevs.
spikingconvNetsstoredkernelwiththeincomingeventcoordinates,(7)AER-out,asynchronouscircuitryforarbitratingandsendingouttheout-putaddresseventsgeneratedbythepixels,and(8)forthedigitalversiona2'scomplementblockisrequiredtoinvertkerneldatabeforeaddingthemtothepixels,ifaninputeventisnegative.
Whenaninputeventofaddress(x,y)isreceived,thecontrollercopiesrowafterrowthekernelvaluesfromthekernel-RAMtothecorrespondingpixelarrayrows(theprojectioneld),asindicatedinFigure3.
Thenallpixelswithinthisprojectioneldupdatetheirstate:theyadd/subtractthecorrespondingkernelweightdependingoneventandweightsigns.
Whenapixelreachesitspos-itiveornegativethreshold,itsignalsasignedoutputeventtotheperipheralarbiters,whichsenditsaddressandsignout.
Paralleltothisper-eventprocessing,thereisaglobalforgettingmecha-nismcommonforallpixels:pixelvaluesaredecremented(iftheyarepositive)orincremented(iftheyarenegative)triggeredbyaglobalperiodicsignal.
Thisimplementsaconstantleakofxedratethatdischargestheneurons,allowingtheConvModuletocapturedynamicrealitywithatimeconstantintheorderofthisleak.
Amoreformalmathematicaljusticationofthisevent-drivencon-volutionoperationcanbefoundelsewhere(Serrano-Gotarredonaetal.
,1999).
3.
3.
FPGAIMPLEMENTATIONFigure4showstheblockdiagramofanFPGAspike-basedcon-volver.
Aserialperipheralinterface(SPI)isusedtocommunicatewithaUSBmicrocontrollerinordertoallowtochangethecon-gurationfromalaptop(Kernelmatrix,kernelsize,forgettingperiod,andforgettingquantity).
ThecircuitintheFPGAcanbedividedintothefollowingparallelblocks:A64*64arrayofmemorycells:thematrixisimplementedusingablockofdual-portRAMintheFPGA.
EachpositionoftheRAMis8-bitlength.
Kernelmemory:ThekernelisstoredalsointheinternalRAMoftheFPGAinan11*11matrixwith8-bitresolution.
Convstatemachine:Eachinputeventcorrespondstotheaddressofapixel.
Centeredonthisaddress,thekernelisaddedtothememorymatrix,whichisusedtosavethestateoftheconvolutioncells.
Ifanyofthemodiedcellsreachesavaluehigherthanaglobalprogrammablethreshold(Th),anoutputeventwiththiscelladdressisqueuedtobesentthroughtheAERoutputbus,andthecellisreset.
Forgettingmechanism.
Acongurableforgettingcircuitryisalsopresentinthearchitecture.
Theforgettingisbasedonaprogrammablecounterthataccessesthememorymatrixperiodicallyinordertodecreaseitsvaluesbyaconstant.
Memoryarbiter.
The64*64cellmemorymatrixisasharedresourcebetweentheforgettingcircuitryandtheconvolutionstatemachine.
Therefore,amemoryarbiterisrequired.
FIFOandAERoutputstatemachine:A16eventrst-input-rst-outputbufferisusedtostoretheoutgoingeventsbeforetheyaretransmittedbythestatemachineusingtheasynchro-nousprotocol.
SPIStateMachine.
Thiscontrollerisinchargeofreceivingker-nelsizeandvalues,forgettingperiodandamounttoforget.
ThesystemisconguredandcontrolledthroughacomputerrunningMATLAB.
ThesystemhasbeenimplementedinhardwareinaVirtex-6FPGA.
AVHDLdescriptionofthisConvModulewith64*64pixelsandkernelsofsizeupto11*11hasbeenusedtoprogramdiffer-entConvModulearraysintoaVirtex-6FPGA,togetherwiththecorrespondinginter-modulecommunicationandeventroutingmachinery.
TheinternalstructureofcommercialFPGAswiththeirinternalmemoryarrangementanddistributionisnotoptimumforimplementingevent-drivenparallelmodules.
Nonetheless,itwaspossibletoincludeanarrayof64Gaborlters,eachwithaspecicscaleandorientationtoperformaV1visualcortexpre-processingoneventdatacomingoutofatemporaldifferenceretina(Zamarreo-Ramos,2011;Zamarreo-Ramosetal.
,underreview).
Table1summarizestheresourcesusedbytheVirtex-6.
3.
4.
EXAMPLESYSTEMANDOPERATIONTheexampleinFigure5illustratesevent-drivensensingandprocessing,andpseudo-simultaneity,onaverysimpleFIGURE4|BlockdiagramoftheFPGAAER-basedconvolutionprocessor(left)anditsStateMachine(right).
www.
frontiersin.
orgApril2012|Volume6|Article32|5Farabetetal.
Comparison:framevs.
spikingconvNetsTable1|Frame-freeFPGAresourceconsumption.
ResourcesofaVirtex6LX240T#Used128*8-bitsingle-portblockRAM6416*1-bitsingle-portread-onlydistributedRAM6416*16-bitdual-portdistributedRAM644096*8-bitsingle-portblockRAM644*4-bitsingle-portread-onlydistributedRAM164*64-bitsingle-portread-onlydistributedRAM12-33-bitadders/subtractors27522-14-bitcounters1487Flip-ops91397Finite-state-machines15572-33-bitcomparators32741-32-bitmultiplexors25801Slicesregisters74987outof301440(24%)SlicesLUTs83521outof150720(55%)OccupiedSlices32720outof37680(86%)BlockRAM36E1/FIFO64outof416(15%)BlockRAM18E1/FIFO68outof832(8%)two-convolutionsetup.
Figure5Ashowsthebasicsetup.
A52carddeckisbrowsedinfrontofamotionsensitiveAERretina(Leero-Bardalloetal.
,2011).
Figure5Bshowsapicturetakenwithacommercialcamerawith1/60sec(16.
67ms)exposuretime.
Figure5Cshowstheeventscapturedduringa5-mstimewindow,whileacardwith"clover"symbolsisbrowsed.
Figure5Dshowstheinstantaneouseventrateforthewholeeventsequencewhenbrowsingthecomplete52carddeck.
Mostcardsarebrowsedina410-mstimeinterval,withpeakeventrateofabout8Meps(megaeventspersecond)computedon10μstimebins.
Theeventsproducedbytheretinaaresent(eventafterevent)toarstEvent-DrivenConvolutionchipprogrammedwiththekernelinFigure5Etolteroutnoiseandenhanceshapesofamini-mumsize.
TheoutputeventsproducedbythisrstConvolutionchiparesenttoasecondConvolutionchipprogrammedwiththekernelinFigure5F.
Thiskernelperformscrudetemplatematch-ingtodetect"clover"symbolsofaspecicsizeandorientation.
Inordertoperformmoresophisticatedsizeandposeinvariantobjectrecognitionafullmulti-stageConvNetwouldbeneces-sary.
However,thissimpleexampleissufcienttoillustratethepseudo-simultaneityproperty.
Thetwo-convolutionsystemwassimulatedusingthesimulatordescribedinSection1andusingrecordedeventdatatakenfromarealMotionSensitiveretina(Leero-Bardalloetal.
,2011)usinganeventdataloggerboard(Serrano-Gotarredonaetal.
,2009).
Thiseventdataloggerboardcanrecordupto500keventswithpeakratesofupto9Meps.
Figure5Gshowstheretinaevents(reddots),therstconvo-lutionoutputevents(greencircles)andthesecondconvolutionoutputevents(bluestars)inyvs.
timeprojection,fora85-mstimeinterval.
Onecanseeveryclearlytheeventscorrespondingto4cards(numbered"1"to"4"inthegure).
Cards"2"to"4"contain"clover"symbolsthatmatchthesizeandorientationofFIGURE5|Illustrationofpseudo-simultaneityinfastevent-drivenrecognition.
(A)Feed-forwardTwo-Convolutionsystem.
(B)Photographwithcommercialcameraat1/60s.
(C)FivemillisecondseventcapturefromAERmotionretina.
(D)Eventratecomputedusing10μsbins.
(E)Firstpre-lteringKernel.
(F)Secondtemplate-matchingkernel.
(G)Eventsfromrealretina(reddots),simulatedoutputofrstlter(greencircles),andsimulatedoutputofsecondlter(bluestars).
(H)y/timezoomout.
(I)x/yzoomout.
thekernel.
Figure5Gincludesazoomboxbetween26and29ms.
TheeventsinsidethiszoomboxareshowninFigure5Hinyvs.
timeprojection,andinFigure5Iinyvs.
xprojection.
Asonecansee,betweentime26and29msaclear"clover"symbolispresentattheretinaoutput(smallreddots).
Theretina"clover"eventsrangebetween26.
5and29ms(2.
5msduration).
Theout-puteventsoftherstlter(greencircles)rangebetweentime26.
5and28.
5ms(2.
0msduration),whichisinsidethetimewindowoftheretinaevents.
Consequently,retinaandrstconvolutionFrontiersinNeuroscience|NeuromorphicEngineeringApril2012|Volume6|Article32|6Farabetetal.
Comparison:framevs.
spikingconvNetsstreamsaresimultaneous.
TheoutputeventsofthesecondCon-volution(thickbluedots)areproducedattime27.
8ms(1.
3msafterthe1stretina"clover"eventand1.
2msbeforetheretinalast"clover"event),whichisduringthetimetheretinaisstillsendingouteventsofthe"clover"symbol,andalsowhiletherstConvolu-tionisstillprovidingoutputeventsforthissymbol.
Notethatthesecondconvolutionneedstocollectaverylargenumberofeventsbeforemakingadecision,becauseitskernelisverylarge.
However,inastandardConvNetwithmanyConvModules,kernelsareusu-allymuchsmallerandwouldrequiremuchlessinputeventstostartprovidingoutputs,thereforealsospeedingupthewholerecogni-tionprocess,inprinciple.
AscanbeseeninFigures5G,H,cloversymbolrecognitionisachievedevenbeforethesensorhasdeliv-eredalltheeventsthatformthesymbol.
Allthisillustratesquitenicelythepseudo-simultaneitypropertyofframe-freeevent-drivensystems.
ThiscontrastswiththeFrame-Constraintphilosophy.
Evenifonehasaveryhigh-speedvideocamera,say1kframe/s,thesystemhasrsttoacquireanimage(whichwouldtake1ms),sendittoaframe-constraintprocessingsystem(liketheonedescribedinSection4),andassumingitcanprovideanoutputafteranother1ms,therecognitionresultwouldbeavailable2msafterthestartofsensing.
AlthoughthesetimesarecomparabletowhatisshowninFigure5H,thesensingoutputandtheprocessingoutputaresequential,theyarenotsimultaneous.
Thisisonekeyconcep-tualdifferencebetweenthetwoapproaches.
Tounderstandhowthisextrapolatestomultiplelayers,letusrefertoFigure6.
Atthetop(Figure6A)thereisa6-layerConvNetfeatureextractionsystemforobjectrecognition.
LetusassumeeachlayercontainsalargenumberoffeatureextractionConvModules,whoseout-putsaresenttoeachsubsequentlayer.
LetusassumethatwehaveaveryfastFrame-basedprocessingsystemperlayer(astheonedescribedinthenextSection)andthatitiscapableofcomput-ingallfeaturemapswithinalayerin1ms.
Letusassumealsothatwehaveaveryfastsensorcapableofprovidingaframerateof1image/ms(1000fps),andthattheoutputofeachstagecanbetransmittedtothenextstagemuchfasterthanin1ms.
Letusalsoassumethatthereisasuddenvisualstimulusthatlastsforabout1msorless.
Figure6BshowsthetimingdiagramfortheoutputsxiateachsubsequentlayerofaFrame-basedimple-mentation.
Thesuddenstimulushappensbetweentime0and1ms,andthesensoroutputisprovidedattime1ms.
Therstlayerfeaturemapsoutputisavailableattime2ms,thesecondattime3ms,andsoonuntilthelastoutputisavailableattime6ms.
Figure6Cshowshowthetimingoftheeventswouldbeinanequivalentsixlayerevent-drivenimplementation.
AsinFigure5,thesensorprovidestheoutputeventssimultaneouslytoreality,thusduringtheintervalfrom0to1ms.
Similarly,the1stevent-drivenfeaturemapsx1wouldbeavailableduringthesameinterval,andsoonforallsubsequentlayersxi.
Conse-quently,thenaloutputx5willbeavailableduringthesametimeintervalthesensorisprovidingitsoutput,thisis,duringinterval0to1ms.
Animmediatefeaturethatthepseudo-simultaneitybetweeninputandoutputeventowsallows,isthepossibilityofefcientlyimplementingfeedbacksystems,asfeedbackwouldbeinstanta-neouswithoutanyneedtoiterateforconvergence.
However,thisfeatureisnotexploitedinpresentdayConvNets,becausetheyarepurelyfeed-forward.
3.
5.
FRAME-CONSTRAINEDFIX-PIXEL-VALUEConvNetsInthissectionwepresentarun-timeprogrammabledata-owarchitecture,speciallytailoredforFrame-ConstrainedFix-Pixel-ValueConvNets.
WewillrefertothisimplementationastheFC-ConvNetProcessor.
Theprocessorreceivessequencesofstillimages(frames).
Foreachframe,pixelshavex(constant)values.
Thearchitecturepresentedherehasbeenfullycodedinhardwaredescriptionlanguage(HDL)thattargetbothASICsynthesisandprogrammablehardwarelikeFPGAs.
AschematicsummaryoftheFC-ConvNetProcessorsystemispresentedinFigure7A.
Themaincomponentsare:(1)aControlUnit(implementedonageneral-purposeCPU),(2)agridofindependentProcessingTiles(PTs),eachcontainingaroutingmultiplexer(MUX)andlocaloperators,and(3)aSmartDMAinterfacingexternalmemoryviaastandardcontroller.
Thearchitecturepresentedhereproposesaverydifferentpar-adigmtoparallelism,aseachPTonlycontainsusefulcomputinglogic.
Thisallowsustousethesiliconsurfaceinamostefcientway.
Infact,whereatypicalmulti-processorsystemwouldbeabletouse50cores,theproposeddata-owgridcouldimplement500tiles.
Forimageprocessingtasks(ConvNetsinthiscase),thefollow-ingobservations/designchoicesfullyjustifytheuseofthistypeofgrid:Throughputisatoppriority.
Indeed,mostoftheoperationsperformedonimagesarereplicatedoverbothdimensionsofimages,usuallybringingtheamountofsimilarcomputationstoanumberthatismuchlargerthanthetypicallatenciesofapipelinedprocessingtile.
Recongurationtimehastobelow(intheorderofthesystem'slatency).
Thisisachievedbytheuseofacommonrun-timecongurationbus.
Eachmoduleinthedesignhasasetofcon-gurableparameters,routesorsettings(depictedassquaresonFigure7A),andpossessesauniqueaddressonthenetwork.
Groupsofsimilarmodulesalsoshareabroadcastaddress,whichdramaticallyspeedsuptheirreconguration.
Theprocessingelementsinthegridshouldbeascoarsegrainedaspermitted,tomaximizetheratiobetweencomputinglogicandroutinglogic.
Theprocessingelementsshouldnothaveanyinternalstate,butshouldjustpassivelyprocessanyincomingdata.
Thetaskofsequencingoperationsisdonebytheglobalcontrolunit,whichstoresthestateandsimplycongurestheentiregridforagivenoperation,letsthedata-owin,andpreparesthefollowingoperation.
Figure7Bshowshowthegridcanbeconguredtocomputeasub-partofaConvNet(asumoftwoconvolutionsisfedtoanon-linearmapper).
Inthatparticularconguration,boththekernelsandtheimagesarestreamsloadedfromexternalmemory(thelterkernelscanbepre-loadedinlocalcachesconcurrentlytoanotheroperation).
Byefcientlyalternatingbetweengridrecongurationanddatastreaming,anentireConvNetcanbecomputed(unrolledintime).
www.
frontiersin.
orgApril2012|Volume6|Article32|7Farabetetal.
Comparison:framevs.
spikingconvNetsFIGURE6|Illustrationofpseudo-simultaneityconceptextrapolatedtomultiplelayers.
(A)VisionsystemcomposedofVisionSensorandvesequentialprocessingstages,likeinaConvNet.
(B)TiminginaFrame-constraintsystemwith1msframetimeforsensingandperstageprocessing.
(C)TiminginanEvent-drivensystemwithmicro-seconddelaysforsensorandprocessorevents.
AcompilertakesasoftwarerepresentationofatrainedCon-vNet,andproducesthebinarycodetobeexecutedontheControlUnit.
TheConvNetProcessorcanbereprogrammedwithnewbinarycodeatrun-time.
Thecompilertypicallyexecutesthefollowingoperations:Step1:AnalysesagivenConvNetlayerbylayer,andper-formscross-layeroptimizations(likelayercombinationsandmerging).
Step2:Createsamemorymapwithefcientpacking,toplaceallintermediateresults(mostlyfeaturemapsforConvNets)inaminimalmemoryfootprint.
Step3:Decomposeseachlayerfromstep1intosequencesofgridrecongurationsanddatastreams.
EachrecongurationresultsinasetofoperationstobeperformedbytheControlUnitandeachdatastreamresultsinasetofoperationsfortheSmartDMA(toread/writefrom/toexternalmemory).
Step4:ResultsfromStep3areturnedintoafullysequentialbinarycodefortheControlUnit.
OurarchitecturewasimplementedontwoFPGAs,alow-endVir-tex4withlimitedmemorybandwidthandahigh-endVirtex-6withfourfoldmemorybandwidth.
Figure8showsthetimetakentocomputeatypicalConvNettrainedforsceneanalysis/obstacledetection(pixel-wiseclassica-tion,seeHadselletal.
,2009),ondifferentcomputingplatforms.
TheCPUimplementationisclassicalCimplementationusingBLASlibraries.
TheGPUimplementationisahand-optimizedimplementationthatusesasmanyofthecoresaspossible.
TheGPU,annVidia9400Misamiddle-rangeGPUoptimizedforFrontiersinNeuroscience|NeuromorphicEngineeringApril2012|Volume6|Article32|8Farabetetal.
Comparison:framevs.
spikingconvNetsFIGURE7|(A)Adata-owcomputer.
Asetofrun-timecongurableprocessingtilesareconnectedona2Dgrid.
Theycanexchangedatawiththeir4neighborsandwithanoff-chipmemoryviagloballines.
(B)Thegridisconguredforamorecomplexcomputationthatinvolvesseveraltiles:the3toptilesperforma3*3convolution,the3intermediatetilesanother3*3convolution,thebottomlefttilesumsthesetwoconvolutions,andthebottomcentertileappliesafunctiontotheresult.
low-power.
Ascanbeseen,themostgenerichardware(CPU)istheleastefcientbecauseitislessparallelandreliesonheavyprocessor-memorytrafc.
TheGPUimprovesaboutanorderofmagnitude,asmoreparallelismisachieved.
FPGAimplemen-tationscanbemadetoexploitmassiveparallelismwithhigh-bandwidthmemories,thusachievingmuchhigherefciencies.
Finally,adedicatedASICinahigh-endtechnologywouldbeoptimum.
3.
6.
COMPARISONBETWEENFRAME-CONSTRAINEDANDFRAME-FREESPIKINGConvNetsInordertocompareFrame-Constrainedvs.
Frame-FreespikinghardwareperformanceofConvNetsimplementations,weneedtobeawareofthefundamentaldifferencebetweeninformationcodingofbothapproaches.
FIGURE8|ComputingtimeforatypicalConvNet,versusthenumberofconnectionsusedfortrainingthenetwork.
InaFrame-Constrainedvisionsystem,visualrealityissampledatarateTframe.
Theinputtothesystemisthen,foreachTframe,anarrayofN*Mpixelseachcarryingann-bitvalue.
Thereisaxedamountofinputinformationperframe.
ForagivenCon-vNettopology(asinFigure1),oneknowsexactlythenumberandtypeofoperationsthathavetobecarriedoutstartingfromtheinputframe.
Dependingontheavailablehardwareresources(multipliers,adders,accumulators,etc)onecanestimatethedelayinprocessingthefullConvNetforoneinputimage,independentlyonthecontentoftheimage.
IfthefullConvNetoperatorscanbemappedonebyoneontorespectivehardwareoperators,thennointermediatecomputationdatahastobefetchedinandoutfromthechip/FPGAtoexternalmemory.
Thisistheidealcase.
However,inpracticalimplementationsto-date,eithertheinputimageisprocessedbypatches,ortheConvNetisprocessedbypartswithinthehardware,oracombinationofboth,usingexten-sivechip/FPGAtoexternalmemorytrafc.
Let'scallRhwtheratiobetweentheavailablehardwareresourcesandallthehardwareresourcesagivenConvNetwouldrequiretocomputethefullinputframewithoutfetchingintermediatedatato/fromexternalmem-ory.
Then,inFrame-ConstrainedFix-Pixel-ValueConvNetsspeedisastrongfunctionofRhwandtheexternalmemorybandwidth.
InaFrame-FreeSpikingSystem,sensorpixelsgeneratespikescontinuouslyandasynchronously.
Visualinformationisrepre-sentedbyaowofevents,eachdenedin3D(x,y,t).
Manytimesaneventcarriesalso"sign"information(positiveorneg-ative).
Thenumberofspikespersecondinthevisualowishighlydependentonsceneinformationcontent(asopposedtotheFrame-Constrainedcase).
InFrame-FreeSpikingsystems,thefullConvNetstructure(asinFigure1)mustbeavailableinhardware.
Consequently,Rhw=1.
Thisisduetothefactthatvisualinforma-tionateachnodeoftheConvNetisrepresentedbyasequenceorowofeventsthat"ll"thetimescaleandkeepsynchronyamongallnodes.
Thegreatadvantageofthisisthatthedifferentowsarepracticallysimultaneousbecauseofthe"pseudo-simultaneity"propertyofinput-to-outputowsineachConvNetmodule.
Thewww.
frontiersin.
orgApril2012|Volume6|Article32|9Farabetetal.
Comparison:framevs.
spikingconvNetsprocessingdelaybetweeninput-to-outputowsisdeterminedmainlybythestatisticsoftheinputeventowdata.
Forexample,howmanyspace-timecorrelatedinputeventsneedtobecollectedthatrepresentagivenshape.
Ifonetriestotime-multiplexthehardwareresources(forimplementinglargernetworks,forexam-ple)thentheowswouldneedtobesampledandstored,whichwouldconvertthesystemintoaFrame-Constrainedone.
Conse-quently,ifonewantstoscaleupaFrame-FreeSpikingConvNet,thenitisnecessarytoaddmorehardwaremodules.
Inprinciple,thisshouldbesimple,asinter-modulelinksareasynchronousandmodulesareallalike.
Asthesystemscalesup,however,processingspeedisnotdegraded,asitisdeterminedbythestatisticalinforma-tioncontentoftheinputeventow.
NotethatthisisafundamentaldifferencewithrespecttoFrame-constrainedsystems,whereoneneedstorstwaitforthesensortoprovideafullframebeforestartingprocessingit.
Scalingupaspikingsystemdoesnotaffectthepseudo-simultaneityproperty.
Animportantlimitationwillbegivenbytheinter-moduleeventcommunicationbandwidth.
Nor-mally,eventratelowersasprocessingisperformedatsubsequentstages.
Thusthehighesteventrateisusuallyfoundatthesen-soroutput.
Consequently,itisimportantthatthesensorsincludesomekindofpre-processing(suchasspatialortemporalcontrast)toguaranteearathersparseeventcount.
AlthoughpresentdayConvNetsarepurelyfeed-forwardstruc-tures,itiswidelyacceptedthatcomputationsinbrainsexploitextensiveuseoffeedbackbetweenprocessinglayers.
InaFrame-constraintsystem,implementingfeedbackwouldrequiretoiterateeachfeed-forwardpassuntilconvergence,foreachframe.
Ontheotherhand,inFrame-freeevent-drivensystems,sinceinputandoutputowsateachmoduleareinstantaneous,feedbackwouldbeinstantaneousaswell,withoutanyneedforiterations.
AnotherbigdifferencebetweenFrame-ConstrainedandFrame-Freeimplementationsisthattherstoneistechnologicallymorematurewhilethesecondoneisveryincipientandinresearchphase.
Table2summarizesthemaindifferencesbetweenbothapproachesintermsofhowdataisprocessed,whetherhardwaremultiplexingispossible,howhardwarecanbescaled-up,andwhatdeterminesprocessingspeedandpowerconsumption.
NotethatAERspikinghardwareiseasilyexpandableinamodularfashionbysimplyinterconnectingAERlinks(Serrano-Gotarredonaetal.
,2009;Zamarreo-Ramosetal.
,underreview).
However,expand-ingtheFPGAhardwaredescribedinSection4isnotsostraightforwardanddedicatedadhoctechniquesneedtobedeveloped.
Table3comparesnumericallyperformanceguresofcom-parableConvNetsimplementedusingeitherFrame-Constrainedx-pixel-valueorFrame-freespiking-dynamic-pixeltechniques.
ThersttwocolumnsshowperformanceguresofarraysofGaborlterssynthesizedintoVirtex-6FPGAs.
ThePurdue/NYUsystemimplementsanarrayof16parallel10*10kernelGaborltersoperatingoninputimagesof512*512pixelswithadelayof5.
2ms,thusequivalentto4M-neuronswith400M-synapsesandacomputingpowerof7.
8*1010conn/s.
TheIMSE/USsys-temimplementsanarrayof64Gaborltersoperatingoninputvisualscenesof128*128pixelswithdelaysof3μsper-eventpermodule,thusequivalentto0.
26M-neuronswith32M-synapsesandacomputingpowerof2.
6*109conn/s.
Notethatwhilethe5.
2msdelayofthePurdue/NYUFrame-Constraintsystemrepresentsthelteringdelayof16ConvMod-ules,the3-μs/eventdelayoftheIMSE/USsystemdoesnotrep-resentalteringdelay.
Thisnumbersimplycharacterizestheintrinsicspeedofthehardware.
Thelteringorrecognitiondelaywillbedeterminedbythestatisticaltimedistributionofinputevents.
Assoonasenoughinputeventsareavailablethatallowthesystemtoprovidearecognitiondecision,anoutputeventwillbeproduced(3μsafterthelastinputevent).
Table2|Frame-freevs.
frame-constrained.
Frame-freeFrame-constrainedDataprocessingPer-event,resultinginpseudo-simultaneityPerframe/patchHardwaremultiplexingNotpossiblePossibleHardwareup-scalingByaddingmodulesAdhocSpeedDeterminedbystatisticsofinputstimuliDeterminedbynumberandtypeofoperations,availablehardwareresourcesandtheirspeedPowerconsumptionDeterminedbymodulepowerper-event,andinter-modulecommunicationpowerper-eventDeterminedbypowerofprocessor(s)andmemoryfetchingrequirementsFeedbackInstantaneous.
NoneedtoiterateNeedtoiterateuntilconvergenceforeachframeTable3|Performancecomparison.
Purdue/NYUIMSE/US3DASICGrid40nmInputscenesize521*512128*128512*512512*512Delay5.
2ms/frame3μs/event1.
3ms/frame10ns/eventsGaborarray16convs10*10kernels64convs11*11kernels16convs10*10kernels100convs32*32kernelsNeurons4.
05*1062.
62*1054.
05*106108Synapses4.
05*1083.
20*1074.
05*1081011Conn/s7.
8*10102.
6*1093*10114*1013FrontiersinNeuroscience|NeuromorphicEngineeringApril2012|Volume6|Article32|10Farabetetal.
Comparison:framevs.
spikingconvNetsThethirdandfourthcolumnsrepresentperformanceestima-tionsforfuturisticFrame-constrainedandFrame-freesystems.
Column3correspondstotheASICsystemsprojectedforahigh-end3Dtechnology(seeFigure7),wherespeedisimprovedafactorfourforagivennumberofconnectionswithrespecttotheVirtex-6realization.
Columnfourcorrespondstotheestimatedperformanceforanarrayof100recongurablemulti-module40nmtechnologychips.
Basedontheperformanceguresofanalreadytestedevent-drivenConvChipfabricatedin0.
35μmCMOS(Camuas-Mesaetal.
,2011,2012),whichholdsanarrayof64*64pixelsinabout5mm*5mm,itisreasonabletoexpectthata1-cm2diefabricatedin40nmCMOScouldhold1millionneuronswith1G-synapses.
Inordertoimproveeventthrough-put,processingpixelsshouldbetiledintoslicestoavoidverylonglinesandpipeline/parallelizeeventprocessing.
Off-chipeventcommunicationshouldbedoneserially(Zamarreo-Ramosetal.
,2011a,b),andpossiblyusingmultipleI/Oportstoimproveinter-chipthroughput.
Allthiscouldprobablyimproveeventthrough-putbyafactorof100withrespecttothepresentedprototype.
Consequently,wemightconsiderasviable,eventthroughputsintheorderof108eps(eventspersecond)perchip.
UsingAER-meshtechniques(Zamarreo-Ramos,2011;Zamarreo-Ramosetal.
,underreview)toassemblemodularlyagridof10*10suchchipsona(stackable)PCBwouldallowforaConvNetsystemwithabout108neuronsand1011synapses,whichisabout1%ofthehumancerebralcortex(Azevedoetal.
,2009),intermsofnumberofneu-ronsandsynapses.
Thebrainiscertainlymoresophisticatedandhasotherfeaturesnotconsideredhere,suchaslearning,synapticcomplexity,stochastic,andmolecularcomputations,andmore.
InordertocomparetheeffectiveperformancecapabilityofFrame-ConstraintversusFrame-Freehardware,themostobjec-tivecriteriaistocomparetheir"connections/second"capability,asshowninthebottomofTable3.
However,thesenumbersshouldalsonotbejudgedasstrictlyequivalent,becausewhiletheFrame-Freeversioncomputesconnections/seconactivepixelsonly,theFrame-Constraintversionhastocomputeconnection/sforallpix-elsthusintroducinganextraoverhead.
Thisoverheaddependsonthestatisticalnatureofthedata.
4.
CONCLUSIONWehavepresentedacomparisonanalysisbetweenFrame-ConstrainedandFrame-FreeImplementationsofConvNetSys-temsforapplicationinobjectrecognitionforvision.
WehavepresentedexampleimplementationsofFrame-ConstrainedFPGArealizationofafullConvNetsystem,andpartialconvolutionprocessingstages(orcombinationofstages)usingspikingAERconvolutionhardwareusingeitherVLSIconvolutionchipsorFPGArealizations.
Thedifferencesbetweenthetwoapproachesintermsofsignalrepresentations,computationspeed,scalability,andhardwaremultiplexinghavebeenestablished.
REFERENCESAzadmehr,M.
,Abrahamsen,J.
,andHiger,P.
(2005).
"AfoveatedAERimagerchip,"inProceedingsoftheIEEEInternationalSymposiumonCircuitsandSystems.
(ISCAS)(Kobe:IEEEPress),2751–2754.
Azevedo,F.
A.
,Carvalho,L.
R.
,Grin-berg,L.
T.
,Farfel,J.
M.
,Ferretti,R.
E.
,Leite,R.
E.
,JacobFilho,W.
,Lent,R.
,andHerculano-Houzel,S.
(2009).
Equalnumbersofneuronalandnonneuronalcellsmakethehumanbrainanisometricallyscaled-uppri-matebrain.
J.
Comp.
Neurol.
513,532–541.
Boahen,K.
(1999).
"Retinomorphicchipsthatseequadrupleimages,"inProceedingsoftheInternationalCon-ferenceMicroelectronicsforNeural,FuzzyandBio-InspiredSystems(Microneuro)(Granada:IEEEPress),12–20.
Boser,B.
,Sckinger,E.
,Bromley,J.
,LeCun,Y.
,andJackel,L.
(1991).
Ananalogneuralnetworkproces-sorwithprogrammabletopology.
IEEEJ.
SolidStateCircuits26,2017–2025.
Camuas-Mesa,L.
,Acosta-Jiménez,A.
,Zamarreo-Ramos,C.
,Serrano-Gotarredona,T.
,andLinares-Barranco,B.
(2011).
Aconvolutionprocessorchipforaddresseventvisionsensorswith155nseventlatencyand20Mepsthroughput.
IEEETrans.
CircuitsSyst.
58,777–790.
Camuas-Mesa,L.
,Zamarreo-Ramos,C.
,Linares-Barranco,A.
,Acosta-Jiménez,A.
,Serrano-Gotarredona,T.
,andLinares-Barranco,B.
(2012).
Anevent-drivenconvolutionprocessormoduleforevent-drivenvisionsensors.
IEEEJ.
SolidStateCircuits47,504–517.
Chan,V.
,Liu,S.
-C.
,andvanSchaik,A.
(2007).
AEREAR:amatchedsili-concochleapairwithaddresseventrepresentationinterface.
IEEETrans.
CircuitsSyst.
PartI54,48–59.
Chen,S.
,andBermak,A.
(2007).
Arbi-tratedtime-to-rstspikeCMOSimagesensorwithon-chiphis-togramequalization.
IEEETrans.
VLSISyst.
15,346–357.
Chicca,E.
,Whatley,A.
M.
,Lichtsteiner,P.
,Dante,V.
,Delbrück,T.
,DelGiu-dice,P.
,Douglas,R.
J.
,andIndiveri,G.
(2007).
Amultichippulse-basedneuromorphicinfrastructureanditsapplicationtoamodeloforientationselectivity.
IEEETrans.
CircuitsSyst.
PartI54,981–993.
Choi,T.
Y.
W.
,Merolla,P.
,Arthur,J.
,Boahen,K.
,andShi,B.
E.
(2005).
Neuromorphicimplementationoforientationhypercolumns.
IEEETrans.
CircuitsSyst.
PartI52,1049–1060.
Cloutier,J.
,Cosatto,E.
,Pigeon,S.
,Boyer,F.
,andSimard,P.
Y.
(1996).
"Vip:anfpga-basedprocessorforimageprocessingandneuralnetworks,"inProceedingsoftheFifthInterna-tionalConferenceonMicroelectron-icsforNeuralNetworksandFuzzySystemsMicroNeuro'96(Lausanne:IEEEPress),330–336.
Costas-Santos,J.
,Serrano-Gotarredona,T.
,Serrano-Gotarredona,R.
,andLinares-Barranco,B.
(2007).
Acon-trastretinawithon-chipcalibra-tionforneuromorphicspike-basedAERvisionsystems.
IEEETrans.
CircuitsSyst.
IReg.
Papers54,1444–1458.
Culurciello,E.
,Etienne-Cummings,R.
,andBoahen,K.
(2003).
Abiomor-phicdigitalimagesensor.
IEEEJ.
SolidStateCircuits38,281–294.
Delbrück,T.
(2005).
http://jaer.
wiki.
sourceforge.
netDelbrück,T.
(2008).
"Frame-freedynamicdigitalvision,"inProceed-ingsofInternationalSymposiumonSecure-LifeElectronics,AdvancedElectronicsforQualityLifeandSoci-ety(Tokyo:UniversityofTokyo),21–26.
Hadsell,R.
,Sermanet,P.
,Erkan,A.
,Ben,J.
,Han,J.
,Flepp,B.
,Muller,U.
,andLeCun,Y.
(2007).
'On-linelearningforoffroadrobots:usingspatiallabelpropagationtolearnlong-rangetra-versability,"inProceedingsofRoboticsScienceandSystems'07,MITPress,Cambridge.
Hadsell,R.
,Sermanet,P.
,Scofer,M.
,Erkan,A.
,Kavackuoglu,K.
,Muller,U.
,andLeCun,Y.
(2009).
Learninglong-rangevisionforautonomousoff-roaddriving.
J.
FieldRobotics26,120–144.
Huang,F.
-J.
,andLeCun,Y.
(2006).
"Large-scalelearningwithsvmandconvolutionalnetsforgenericobjectcategorization,"inProceedingsofComputerVisionandPatternRecog-nitionConference(CVPR'06)(NewYork:IEEEPress).
Jarrett,K.
,Kavukcuoglu,K.
,Ranzato,M.
,andLeCun,Y.
(2009).
"Whatisthebestmulti-stagearchitectureforobjectrecognition,"inProceed-ingsofInternationalConferenceonComputerVision(ICCV'09)(Kyoto:IEEE).
LeCun,Y.
,Boser,B.
,Denker,J.
S.
,Hen-derson,D.
,Howard,R.
E.
,Hub-bard,W.
,andJackel,L.
D.
(1990).
"Handwrittendigitrecognitionwithaback-propagationnetwork,"InNIPS'89,MITPress,Denver.
LeCun,Y.
,Bottou,L.
,Bengio,Y.
,andHaffner,P.
(1998a).
Gradient-basedlearningappliedtodocumentrecog-nition.
ProceedingsoftheIEEE86,2278–2324.
LeCun,Y.
,Bottou,L.
,Orr,G.
,andMuller,K.
(1998b).
"Efcientback-prop,"inNeuralNetworks:TricksoftheTrade,edsG.
Orr,andK.
Muller(Springer).
www.
frontiersin.
orgApril2012|Volume6|Article32|11Farabetetal.
Comparison:framevs.
spikingconvNetsLeero-Bardallo,J.
A.
,Serrano-Gotarredona,T.
,andLinares-Barranco,B.
(2010).
Ave-decadedynamic-rangeambient-light-independentcalibratedsigned-spatial-contrastAERretinawith0.
1mslatencyandoptionaltime-to-rst-spikemode.
IEEETrans.
CircuitsSyst.
IReg.
Papers57,2632–2643.
Leero-Bardallo,J.
A.
,Serrano-Gotarredona,T.
,andLinares-Barranco,B.
(2011).
A3.
6μslatencyasynchronousframe-freeevent-baseddynamicvisionsensor.
IEEEJ.
SolidStateCircuits46,1443–1455.
Lichtsteiner,P.
,Posch,C.
,andDelbrück,T.
(1998).
A128–128120db15uslatencyasynchronoustemporalcon-trastvisionsensor.
IEEEJ.
SolidStateCircuits43,566–576.
Lyu,S.
,andSimoncelli,E.
P.
(2008).
"Nonlinearimagerepresentationusingdivisivenormalization,"inComputerVisionandPatternRecog-nition,IEEE,Anchorage.
Massari,N.
,Gottardi,M.
,Jawed,S.
A.
,andSoncini,G.
(2008).
A100uw64*128-pixelcontrast-basedasynchronousbinaryvisionsensorforwirelesssensornetworks.
IEEEISSCCDig.
Tech.
Papers588–638.
Neubauer,C.
(1998).
Evaluationofcon-volutionneuralnetworksforvisualrecognition.
IEEETrans.
NeuralNetw.
9,685–696.
Osadchy,R.
,Miller,M.
,andLeCun,Y.
(2005).
"Synergisticfacedetec-tionandposeestimationwithenergy-basedmodel,"inAdvancesinNeuralInformationProcessingSys-tems(NIPS2004)(Vancouver:MITPress).
Oster,M.
,Yingxue,W.
,Douglas,R.
,andShih-Chii,L.
(2008).
Quanticationofaspike-basedwinner-take-allvlsinetwork.
IEEETrans.
Circuits.
Syst.
Part155,3160–3169.
Pérez-Carrasco,J.
A.
(2011).
ASim-ulationToolforBuildingandAna-lyzingComplexandHierarchicallyStructuredAERVisualProcessingSystems.
Ph.
D.
thesis,IMSE-CNM-CSIC,UniversidaddeSevilla,Sevilla.
Pinto,N.
,Cox,D.
D.
,andDiCarlo,J.
J.
(2008).
Whyisreal-worldvisualobjectrecognitionhardPLoSCom-put.
Biol.
4,e27.
doi:10.
1371/jour-nal.
pcbiPosch,C.
,Matolin,D.
,andWohlge-nannt,R.
(2010).
"AQVGA143dBDRasynchronousaddress-eventPWMdynamicvisionandimagesensorwithlosslesspixel-levelvideocompressionandtime-domainCDS,"inISSCCDigestofTechnicalPapers,SanFrancisco,inpress.
Ranzato,M.
,Huang,F.
,Boureau,Y.
,andLeCun,Y.
(2007).
"Unsupervisedlearningofinvariantfeaturehier-archieswithapplicationstoobjectrecognition,"inProceedingsofCom-puterVisionandPatternRecognitionConference(CVPR'07)(Minneapo-lis:IEEEPress).
Ruedi,P.
F.
,Heim,P.
,Gyger,S.
,Kaess,F.
,Arm,C.
,Caseiro,R.
,Nagel,J.
-L.
,andTodeschini,S.
(2009).
"Ansoccom-bininga132dbqvgapixelarrayanda32bdsp/mcuprocessorforvisionapplications,"inIEEEISSCCDigestofTechnicalPapers,SanFrancisco,46–47,47a.
Ruedi,P.
F.
,Heim,P.
,Kaess,F.
,Grenet,E.
,Heitger,F.
,Burgi,P.
-Y.
,Gyger,S.
,andNussbaum,P.
(2003).
A128*128,pixel120-dbdynamic-rangevision-sensorchipforimagecontrastandorientationextraction.
IEEEJ.
SolidStateCircuits38,2325–2333.
Sckinger,E.
,Boser,B.
,Bromley,J.
,LeCun,Y.
,andJackel,L.
D.
(1992).
ApplicationoftheANNAneuralnetworkchiptohigh-speedcharac-terrecognition.
IEEETrans.
NeuralNetw.
3,498–505.
Serrano-Gotarredona,R.
,Oster,M.
,Lichtsteiner,P.
,Linares-Barranco,A.
,Paz-Vicente,R.
,Gómez-Rodríguez,F.
,Camuas-Mesa,L.
,Berner,R.
,Rivas-Pérez,M.
,Delbrück,T.
,Liu,S.
-C.
,Douglas,R.
,Higer,P.
,Jiménez-Moreno,G.
,Ballcels,A.
C.
,Serrano-Gotarredona,T.
,Acosta-Jiménez,A.
J.
,andLinares-Barranco,B.
(2009).
CAVIAR:a45kneu-ron,5Msynapse,12Gconnects/sAERhardwaresensory-processing-learning-actuatingsystemforhigh-speedvisualobjectrecognitionandtracking.
IEEETrans.
NeuralNetw.
20,1417–1438.
Serrano-Gotarredona,R.
,Serrano-Gotarredona,T.
,Acosta-Jiménez,A.
,andLinares-Barranco,B.
(2006).
Aneuromorphiccortical-layermicrochipforspike-basedeventprocessingvisionsystems.
IEEETrans.
CircuitsSyst.
IRegul.
Papers53,2548–2566.
Serrano-Gotarredona,R.
,Serrano-Gotarredona,T.
,Acosta-Jiménez,A.
,Serrano-Gotarredona,C.
,Pérez-Carrasco,J.
A.
,Linares-Barranco,B.
,Linares-Barranco,A.
,Jiménez-Moreno,G.
,andCivit-Ballcels,A.
(2008).
Onreal-timeAER2-Dconvolutionhardwareforneu-romorphicspike-basedcorticalprocessing.
IEEETrans.
NeuralNetw.
19,1196–1219.
Serrano-Gotarredona,T.
,Andreou,A.
G.
,andLinares-Barranco,B.
(1999).
AERimagelteringarchitectureforvisionprocessingsystems.
IEEETrans.
CircuitsSyst.
PartIFundam.
TheoryAppl.
46,1064–1071.
Serre,T.
(2006).
LearningaDictio-naryofShape-ComponentsinVisualCortex:ComparisonwithNeurons,HumansandMachines.
Ph.
D.
thesis,MIT,Boston.
Shepherd,G.
(1990).
TheSynapticOrga-nizationoftheBrain,3rdEdn.
Oxford:OxfordUniversityPress.
Sivilotti,M.
A.
(1991).
"Wiringcon-siderationsinanalogVLSIsys-tems,withapplicationtoeld-programmablenetworks,"inTech-nicalReport,CaliforniaInstituteofTechnology,Pasadena.
Teixeira,T.
,Culurciello,E.
,andAndreou,A.
G.
(2006).
"Anaddress-eventimagesensornetwork,"inIEEEInternationalSymposiumonCircuitsandSystems,ISCAS'06(Kos:IEEE),4467–4470.
Thorpe,S.
,Fize,D.
,andMarlot,C.
(1996).
Speedofprocessinginthehumanvisualsystem.
Nature381,520–522.
Vernier,P.
,Mortara,A.
,Arreguit,X.
,andVittoz,E.
A.
(1997).
Aninte-gratedcorticallayerfororientationenhancement.
IEEEJ.
SolidStateCircuits32,177–186.
Vogelstein,R.
J.
,Mallik,U.
,Culurciello,E.
,Cauwenberghs,G.
,andEtienne-Cummings,R.
(2007).
Amulti-chipneuromorphicsystemforspike-basedvisualinformationprocessing.
NeuralComput.
19,2281–2300.
Zaghloul,K.
A.
,andBoahen,K.
(2004).
Opticnervesignalsinaneuro-morphicchip:parts1and2.
IEEETrans.
Biomed.
Eng.
51,657–675.
Zamarreo-Ramos,C.
(2011).
TowardsModularandScalableHigh-SpeedAERVisionSystems.
Ph.
D.
thesis,IMSE-CNM-CSIC,UniversidaddeSevilla,Sevilla.
Zamarreo-Ramos,C.
,Serrano-Gotarredona,T.
,Linares-Barranco,B.
,Kulkarni,R.
,andSilva-Martinez,J.
(2011a).
"Voltagemodedriverforlowpowertransmissionofhighspeedserialaerlinks,"inProceedingsofIEEEInternationalSymposiumonCircuitsandSystems(ISCAS2011)(RiodeJaneiro),2433–2436.
Zamarreo-Ramos,C.
,Serrano-Gotarredona,T.
,andLinares-Barranco,B.
(2011b).
Aninstant-startupjitter-tolerantmanchester-encodingserializer/deserializarschemeforevent-drivenbit-seriallvdsinter-chipaerlinks.
IEEETrans.
CircuitsSyst.
PartI58,2647–2660.
ConictofInterestStatement:Theauthorsdeclarethattheresearchwasconductedintheabsenceofanycom-mercialornancialrelationshipsthatcouldbeconstruedasapotentialcon-ictofinterest.
Received:28October2011;accepted:21February2012;publishedonline:12April2012.
Citation:FarabetC,PazR,Pérez-CarrascoJ,Zamarreo-RamosC,Linares-BarrancoA,LeCunY,Culur-cielloE,Serrano-GotarredonaTandLinares-BarrancoB(2012)Com-parisonbetweenframe-constrainedx-pixel-valueandframe-freespiking-dynamic-pixelconvNetsforvisualprocessing.
Front.
Neurosci.
6:32.
doi:10.
3389/fnins.
2012.
00032ThisarticlewassubmittedtoFrontiersinNeuromorphicEngineering,aspecialtyofFrontiersinNeuroscience.
Copyright2012Farabet,Paz,Pérez-Carrasco,Zamarreo-Ramos,Linares-Barranco,LeCun,Culurciello,Serrano-GotarredonaandLinares-Barranco.
Thisisanopen-accessarticledistributedunderthetermsoftheCreativeCommonsAttri-butionNonCommercialLicense,whichpermitsnon-commercialuse,distribu-tion,andreproductioninotherforums,providedtheoriginalauthorsandsourcearecredited.
FrontiersinNeuroscience|NeuromorphicEngineeringApril2012|Volume6|Article32|12
3389/fnins.
2012.
00032Comparisonbetweenframe-constrainedx-pixel-valueandframe-freespiking-dynamic-pixelconvNetsforvisualprocessingClémentFarabet1,2*,RafaelPaz3,JosePérez-Carrasco4,CarlosZamarreo-Ramos4,AlejandroLinares-Barranco3*,YannLeCun1,EugenioCulurciello2*,TeresaSerrano-Gotarredona4andBernabeLinares-Barranco41ComputerScienceDepartment,CourantInstituteofMathematicalSciences,NewYorkUniversity,NewYork,NY,USA2Laboratoired'InformatiqueGaspard-Monge,UniversitéParis-Est,quipeA3SI,ESIEEParis,ChampssurMarne,Marne-la-Vallée,France3RoboticandTechnologyofComputersGroup,UniversityofSeville,Seville,Spain4InstitutodeMicroelectrónicadeSevilla,IMSE-CNM-CSIC,Sevilla,SpainEditedby:TobiDelbruck,InstituteforNeuroinformatics,SwitzerlandReviewedby:TobiDelbruck,InstituteforNeuroinformatics,SwitzerlandAntonCivit,UniversityofSeville,SpainZhengmingFu,AdvancedMicroDevices,USA*Correspondence:ClémentFarabet,ComputerScienceDepartment,CourantInstituteofMathematicalSciences,NewYorkUniversity,715Broadway,12thFloor,NewYork,NY10003,USA.
e-mail:cfarabet@nyu.
edu;www.
clement.
farabet.
net;AlejandroLinares-Barranco,RoboticandTechnologyofComputersLab,UniversityofSeville,ETSIInformática,Av.
ReinaMercedess/n,41012-Sevilla,Spain.
e-mail:alinares@atc.
us.
es;EugenioCulurciello,WeldonSchoolofBiomedicalEngineering,PurdueUniversity,206S.
MartinJischkeDrive,Room2031,WestLafayette,IN47907,USA.
e-mail:euge@purdue.
eduMostscenesegmentationandcategorizationarchitecturesfortheextractionoffeaturesinimagesandpatchesmakeexhaustiveuseof2Dconvolutionoperationsfortemplatematching,templatesearch,anddenoising.
ConvolutionalNeuralNetworks(ConvNets)areoneexampleofsucharchitecturesthatcanimplementgeneral-purposebio-inspiredvisionsystems.
Instandarddigitalcomputers2Dconvolutionsareusuallyexpensiveintermsofresourceconsumptionandimposeseverelimitationsforefcientreal-timeapplications.
Nevertheless,neuro-cortexinspiredsolutions,likededicatedFrame-BasedorFrame-FreeSpikingConvNetConvolutionProcessors,areadvancingreal-timevisualprocessing.
Thesetwoapproachessharetheneuralinspiration,buteachofthemsolvestheproblemindif-ferentways.
Frame-BasedConvNetsprocessframebyframevideoinformationinaveryrobustandfastwaythatrequirestouseandsharetheavailablehardwareresources(suchas:multipliers,adders).
Hardwareresourcesarexed-andtime-multiplexedbyfetchingdatainandout.
Thusmemorybandwidthandsizeisimportantforgoodperformance.
Ontheotherhand,spike-basedconvolutionprocessorsareaframe-freealternativethatisabletoperformconvolutionofaspike-basedsourceofvisualinformationwithverylowlatency,whichmakesidealforveryhigh-speedapplications.
However,hardwareresourcesneedtobeavailableallthetimeandcannotbetime-multiplexed.
Thus,hardwareshouldbemodular,recongurable,andexpansible.
HardwareimplementationsinbothVLSIcustomintegratedcircuits(digitalandanalog)andFPGAhavebeenalreadyusedtodemonstratetheperformanceofthesesystems.
Inthispaperwepresentacomparisonstudyofthesetwoneuro-inspiredsolutions.
Abriefdescriptionofbothsystemsispresentedandalsodiscussionsabouttheirdifferences,prosandcons.
Keywords:convolutionalneuralnetwork,address-event-representation,spike-basedconvolutions,imageconvo-lutions,frame-freevision,FPGA,VHDL1.
INTRODUCTIONConventionalvisionsystemsprocesssequencesofframescap-turedbyvideosources,likewebcams,camcorders(CCDsen-sors),etc.
Forperformingcomplexobjectrecognitionalgorithms,sequencesofcomputationaloperationsareperformedforeachframe.
Thecomputationalpowerandspeedrequiredmakesitdifculttodevelopareal-timeautonomoussystem.
Butbrainsperformpowerfulandfastvisionprocessingusingsmallandslowcells(neurons)workinginparallelinatotallydifferentway.
Visionsensingandobjectrecognitioninthemammalianbrainisnotper-formedframebyframe.
Sensingandprocessingareperformedinacontinuousway,spikebyspike,withoutanynotionofframes.
Thevisualcortexiscomposedbyasetoflayers(Shepherd,1990;Serre,2006),startingfromtheretina.
Theprocessingstartsbeginningatthetimetheinformationiscapturedbytheretina.
Althoughcortexhasfeedbackconnections,itisknownthataveryfastandpurelyfeed-forwardrecognitionpathexistsinthevisualcortex(Thorpeetal.
,1996;Serre,2006).
Inrecentyearssignicantprogresshasbeenmadetowardtheunderstandingofthecomputationalprinciplesexploitedbythevisualcortex.
Manyarticialsystemsthatimplementbio-inspiredsoftwaremodelsusebiological-like(convolutionbased)process-ingthatoutperformmoreconventionallyengineeredmachines(Neubauer,1998).
Thesesystemsrunatlowspeedswhenimple-mentedassoftwareprogramsonconventionalcomputers.
Forreal-timesolutionsdirecthardwareimplementationsofthesemodelsarerequired.
However,hardwareengineersfacealargehurdlewhentryingtomimicthebio-inspiredlayeredstructureandthemassiveconnectivitywithinandbetweenlayers.
Agrow-ingnumberofresearchgroupsworld-widearemappingsomeofwww.
frontiersin.
orgApril2012|Volume6|Article32|1Farabetetal.
Comparison:framevs.
spikingconvNetsthesecomputationalprinciplesontobothreal-timespikinghard-warethroughthedevelopmentandexploitationoftheso-calledAER(Address-Event-Representation)technology,andreal-timestreamingFrame-BasedConvNetsonFPGAs.
ConvNetshavebeensuccessfullyusedinmanyrecognitionandclassicationtasksincludingdocumentrecognition(LeCunetal.
,1998a),objectrecognition(HuangandLeCun,2006;Ranzatoetal.
,2007;Jarrettetal.
,2009),facedetection(Osadchyetal.
,2005),androbotnavigation(Hadselletal.
,2007,2009).
AConvNetconsistsofmultiplelayersoflterbanksfollowedbynon-linearitiesandspatialpooling.
Eachlayertakesasinputtheoutputofprevi-ouslayerandbycombiningmultiplefeaturesandpoolingoverspace,extractscompositefeaturesoveralargerinputarea.
OncetheparametersofaConvNetaretrained,therecognitionoperationisperformedbyasimplefeed-forwardpass.
Thesimplicityofthefeed-forwardpasshaspushedseveralgroupstoimplementitascustomhardwarearchitectures.
MostofConvNethardwareimplementationsreportedovertheyearsarefortheframe-constrainedx-pixel-valueversion,astheymapdirectlyfromthesoftwareversions.
TherstonewastheANNAchip,amixedhigh-end,analog-digitalprocessorthatcouldcom-pute64simultaneous8*8convolutionsatapeakrateof4.
109MACs(multiply-accumulateoperationspersecond;Boseretal.
,1991;Sckingeretal.
,1992).
Subsequently,Cloutieretal.
pro-posedanFPGAimplementationofConvNets(Cloutieretal.
,1996),butttingitintothelimited-capacityFPGAsavailableatthosetimesrequiredtheuseofextremelylow-accuracyarith-metic.
ModernDSP-orientedFPGAsincludelargenumbersofhard-wiredmultiply-accumulateunitsthatcangreatlyspeedupcompute-intensiveoperations,suchasconvolutions.
Theframe-constrainedsystempresentedinthispapertakesfulladvantageofthehighlyparallelnatureofConvNetoperations,andthehigh-degreeofparallelismprovidedbymodernDSP-orientedFPGAs.
Achievedpeakratesareintheorderof1011MACs.
Ontheotherhand,Frame-freeSpiking-Dynamic-PixelCon-vNetscomputeinthespikedomain.
Noframesareusedforsensingandprocessingthevisualinformation.
Inthiscase,specialsensorsarerequiredwithaspike-basedoutput.
Spike-basedsensorsandprocessorstypicallyuseAER(Address-Event-Representation)inordertotransmittheinternalstateand/orresultsoftheneuronsinsideachiporFPGA.
AERwasoriginallyproposedalmosttwentyyearsbackinMead'sCaltechresearchlab(Sivilotti,1991).
SincethenAERhasbeenusedfundamentallyinvision(retina)sensors,suchassimplelightintensitytofrequencytransformations(Culurcielloetal.
,2003;Poschetal.
,2010),time-to-rst-spikecoding(Ruedietal.
,2003;ChenandBermak,2007),foveatedsensors(Azad-mehretal.
,2005),spatialcontrast(Costas-Santosetal.
,2007;Massarietal.
,2008;Ruedietal.
,2009;Leero-Bardalloetal.
,2010),temporalcontrast(Lichtsteineretal.
,1998;Poschetal.
,2010;Leero-Bardalloetal.
,2011),motionsensingandcomputa-tion,(Boahen,1999),andcombinedspatialandtemporalcontrastsensing(ZaghloulandBoahen,2004).
ButAERhasalsobeenusedforauditorysystems(Chanetal.
,2007),competitionandwinner-takes-allnetworks(Chiccaetal.
,2007;Osteretal.
,2008),andevenforsystemsdistributedoverwirelessnetworks(Teixeiraetal.
,2006).
Aftersensing,weneedSpikingSignalEventRepresentationtechniquescapableofefcientlyprocessingthesignalowcomingoutfromthesensors.
Forsimpleper-eventheuristicprocessingandltering,directsoftwarebasedsolutionscanbeused(Delbrück,2005,2008).
Otherschemesrelyonlook-uptablere-routingandeventrepetitionsfollowedbysingle-eventintegration(Vogelsteinetal.
,2007).
Alternatively,wecanndsomepioneeringworkintheliteratureaimingatperformingconvolutionallteringontheAERowproducedbyspikingretinas,(Vernieretal.
,1997;Choietal.
,2005),wheretheshapeofthelterkernelwashard-wired(eitherellipticorGabor).
Since2006,workingAERConvolutionchipshavebeenreportedwitharbitraryshapeprogrammablekernelofsizeupto32*32pixelspre-loadedontoaninternalkernel-RAM(Serrano-Gotarredonaetal.
,2006,2008;Camuas-Mesaetal.
,2011,2012).
ThisopensthepossibilityofimplementinginAERspikinghardwaregenericConvNets,wherelargenumberofconvolutionalmoduleswitharbitrarysizeandshapekernelsarerequired.
Inthispaperwepresent,discussandcomparetwodiffer-entneuro-cortexinspiredapproachesforreal-timevisualpro-cessingbasedonconvolutions:Frame-basedx-pixel-valueandFrame-freedynamic-pixel-spikingConvNetProcessinghardware.
Section2describesgenericConvNetsandtheirstructure.
Section3brieydescribesframe-freeConvNettypesofimple-mentations,andSection4describesaframe-constrainedFPGAimplementation.
Implementiondetailswillbegiveninaveryconcisemanner,sothereadercangraspthemainideasbehindeachimplementation.
Formoredetaileddescriptionsthereaderisrefertothecorrespondingreferences.
Finally,Section5providesacomparisonofbothcasesindicatingprosandconsofeach.
2.
STRUCTUREOFGENERICConvNetsFigure1showsatypicalhierarchicalstructureofafeed-forwardConvNet.
ConvolutionalNetworks(LeCunetal.
,1990,1998a),orConvNets,aretrainablemulti-stagearchitecturescomposedofmultiplestages.
Theinputandoutputofeachstagearesetsofarrayscalledfeaturemaps.
Forexample,iftheinputisacolorimage,eachfeaturemapwouldbea2Darraycontainingacolorchanneloftheinputimage(foranaudioinputeachfeaturemapwouldbea1Darray,andforavideoorvolumetricimage,itwouldbea3Darray).
Attheoutput,eachfeaturemaprepresentsapar-ticularfeatureextractedatalllocationsontheinputtoleratingdegreesofdeformationsandsizes.
Eachstageiscomposedofthreelayers:alterbanklayer,anon-linearitylayer,andafeaturepoolinglayer.
AtypicalConvNetiscomposedofone,two,orthreesuch3-layerstages,followedbyaclassicationmodule.
Eachlayertypeisnowdescribedforthecaseofimagerecognition.
2.
1.
FILTERBANKLAYER-FTheinputisa3Darraywithn12Dfeaturemapsofsizen2*n3,andcoordinates(xi,yi),withi=1,.
.
.
n1.
Let'scalleachinputfea-turemapfi=(xi,yi),withxi=1,.
.
.
n2andyi=1,.
.
.
n3.
Theoutputisalsoa3Darraycomposedofm1featuremapsofsizem2*m3andcoordinates(Xj,Yj)withj=1,.
.
.
m1.
Let'scalleachoutputfeaturemapFj=(Xj,Yj),withXj=1,.
.
.
m2andYj=1,.
.
.
m3.
Atrainablelter(kernel)wijinthelterbankhassizel1*l2andconnectsinputfeaturemapfitooutputfeaturemapFj.
TheFrontiersinNeuroscience|NeuromorphicEngineeringApril2012|Volume6|Article32|2Farabetetal.
Comparison:framevs.
spikingconvNetsFIGURE1|Architectureofatypicalconvolutionalnetworkforobjectrecognition.
ThisimplementsaconvolutionalfeatureextractorandalinearclassierforgenericN-classobjectrecognition.
Oncetrained,thenetworkcanbecomputedonarbitrarylargeinputimages,producingaclassicationmapasoutput.
modulecomputesFj=bj+iwijfiwhereisthe2Dconvolutionoperatorandbjisatrainablebiasparameter.
Eachlterdetectsaparticularfeatureateverylocationontheinput.
Hencespatiallytranslatingtheinputofafeaturedetectionlayerwilltranslatetheoutputbutleaveitotherwiseunchanged.
2.
2.
NON-LINEARITYLAYERIntraditionalConvNetsthissimplyconsistsofapointwisetanh()sigmoidfunctionappliedtoeachsite(Xj,Yj).
However,recentimplementationshaveusedmoresophisticatednon-linearities(LyuandSimoncelli,2008;Pintoetal.
,2008).
2.
3.
FEATUREPOOLINGLAYERThislayertreatseachfeaturemapseparately.
Initssimplestinstance,calledPA,itcomputestheaveragevaluesoveraneigh-borhoodineachfeaturemap.
Thisresultsinareduced-resolutionoutputfeaturemapwhichisrobusttosmallvariationsintheloca-tionoffeaturesinthepreviouslayer.
TheaverageoperationissometimesreplacedbyamaxPM.
TraditionalConvNetsuseapointwisetanh()afterthepoolinglayer,butmorerecentmodelsdonot.
Supervisedtrainingisperformedusingaformofstochasticgradientdescenttominimizethediscrepancybetweenthedesiredoutputandtheactualoutputofthenetwork.
Alltheltercoef-cientsinallthelayersareupdatedsimultaneouslybythelearningprocedure.
Thegradientsarecomputedwiththeback-propagationmethod.
DetailsoftheprocedurearegiveninLeCunetal.
(1998a),andmethodsforefcienttrainingaredetailedinLeCunetal.
(1998b).
3.
FRAME-FREESPIKING-DYNAMIC-PIXELConvNetsInframe-freespikingConvNetstheretinasensorpixelsgener-atespikesautonomously.
Pixelactivitychangescontinuously,asopposedtoframe-basedsystems,wherethepixelvalueisfrozenduringeachframetime.
Suchspikesaresenttoprojectioneldsinthenextlayer,andthecontributionofeachspikeisweightedbya2Dspatiallter/kernelvaluewijovertheprojectioneld.
Inthenextlayerpixels,incomingweightedspikesareaccumulated(integrated)untilapixelresitsownspikeforthenextlayer,andsoon.
EachpixelinanyConvolutionModulerepresentsitsstatebyitsinstantaneousspikingactivity.
Consequently,eachpixelatanylayerhastobepresentatanytimeanditsstatecannotbefetchedinandoutasinFrame-basedapproaches.
Thisisthemaindrawbackofthisapproach:allConvModuleshavetobethereinhardwareandhardwareresourcescannotbetime-multiplexed.
AdaptingConvNetstoSpikingSignalEvent-basedrepresen-tationsyieldssomeveryinterestingproperties.
Therstoneistheveryreducedlatencybetweentheinputandoutputeventowsofaspikingconvolutionprocessor.
Wecallthisthe"pseudo-simultaneity"betweeninputandoutputvisualows.
ThisisillustratedbytheexampleattheendofSection3.
ThesecondinterestingpropertyofimplementingSpikingEventConvolutions(orotheroperators,ingeneral)isitsmodularscala-bility.
Sinceeventowsareasynchronous,eachAERlinkbetweentwoconvolutionalmodulesisindependentandneedsnoglobalsystemlevelsynchronization.
Andthethirdinterestingpropertyofspike-basedhardware,ingeneral,isthatsinceprocessingisper-event,powerconsumptionis,inprinciple,alsoper-event.
Sinceeventsusuallycarryrelevantinformation,powerisconsumedasrelevantinformationissensed,transmitted,andprocessed.
Nextwedescribebrieythreewaysofcomputingwithspik-ingConvNets.
First,webrieydescribeanevent-basedsimulationsoftwaretoolforemulatingsuchspikingAERhardwaresystems.
Second,webrieysummarizesomeprogrammablekernelVLSIimplementations.
Andthird,similarFPGAimplementationsarediscussed.
3.
1.
SOFTWARESIMULATORAbehavioralevent-drivenAERsimulatorhasbeendevelopedfordescribingandstudyinggenericAERsystems(Pérez-Carrasco,2011).
Suchsimulatorisveryusefulfordesigningandanalyz-ingtheoperationofnewhardwaresystemscombiningexistingandnon-existingAERmodules.
Modulesareuser-denedandtheyareinterconnectedasdenedbyanetlist,andinputsaregivenbystimulusles.
ThesimulatorwaswritteninC++.
Thenetlistusesonlytwotypesofelements:AERmodules(instances)andAERlinks(channels).
AERlinksconstitutethenodesofthenetlistinanAERsystem.
Channelsrepresentpoint-to-pointcon-nections.
Splitterandmergerinstancesareusedforspreadingormerginglinks.
Figure2showsanexamplesystemanditstextlenetlistdescriptionwith7instancesand8channels.
Channel1isasourcechannel.
Allitseventsareavailableaprioriasanwww.
frontiersin.
orgApril2012|Volume6|Article32|3Farabetetal.
Comparison:framevs.
spikingconvNetsFIGURE2|ExamplenetlistanditsASCIIlenetlistdescription.
inputle.
Theseeventscanbepre-recordedbyarealAERretina(Lichtsteineretal.
,1998;Poschetal.
,2010;Leero-Bardalloetal.
,2011).
Eachinstanceisdenedbyaline.
Instanceoperationisdescribedbyauser-denedfunction.
Channelsaredescribedbylistsofevents.
Oncethesimulatorhasnished,therewillbealistoftime-stampedeventsforeachnode.
Eacheventisdenedby6values(TpR,TRqst,TAck,a,b,c).
Therst3aretimingparame-tersandtheotherthreeareopenuser-denedparametersthattheinstancesinterpretandinterchange.
Usually,aandbaretheeventaddress(x,y)andcitssign.
TRqstisthetimewhenaneventRqstwasgeneratedandTAckwhenitwasacknowledged.
TpRisthetimeofcreationofanevent(beforecommunicatingorarbitratingitoutofitssourcemodule).
Thesimulatorscansallchannelslook-ingfortheearliestunprocessedTpR.
Thiseventisprocessed:itsTRqstandTAckarecomputedandthestateoftheeventdestinationmodulesareupdated.
Ifthiscreatesnewevents,theyareaddedtotheendofthecorrespondinglinkseventlists,andthelistisre-sortedforindreasingTpR.
ThenthesimulatorlooksagainfortheearliestunprocessedTpR,andsoon.
3.
2.
VLSIIMPLEMENTATIONReportedVLSIimplementationsofAERspikingConvModules(eithermixed-signal,Serrano-Gotarredonaetal.
,2006,2008;orfullydigital,Camuas-Mesaetal.
,2011,2012)followtheoorplanarchitectureinFigure3,wherethefollowingblocksareshown:(1)arrayoflossyintegrate-and-repixels,(2)staticRAMthatholdsthestoredkernelin2'scomplementrepresentation,(3)synchro-nouscontroller,whichperformsthesequencingofalloperationsforeachinputeventandtheglobalforgettingmechanism,(4)high-speedclockgenerator,usedbythesynchronouscontroller,(5)congurationregistersthatstorecongurationparametersloadedatstartup,(6)left/rightcolumnshifter,toproperlyaligntheFIGURE3|Architectureoftheconvolutionchip.
FrontiersinNeuroscience|NeuromorphicEngineeringApril2012|Volume6|Article32|4Farabetetal.
Comparison:framevs.
spikingconvNetsstoredkernelwiththeincomingeventcoordinates,(7)AER-out,asynchronouscircuitryforarbitratingandsendingouttheout-putaddresseventsgeneratedbythepixels,and(8)forthedigitalversiona2'scomplementblockisrequiredtoinvertkerneldatabeforeaddingthemtothepixels,ifaninputeventisnegative.
Whenaninputeventofaddress(x,y)isreceived,thecontrollercopiesrowafterrowthekernelvaluesfromthekernel-RAMtothecorrespondingpixelarrayrows(theprojectioneld),asindicatedinFigure3.
Thenallpixelswithinthisprojectioneldupdatetheirstate:theyadd/subtractthecorrespondingkernelweightdependingoneventandweightsigns.
Whenapixelreachesitspos-itiveornegativethreshold,itsignalsasignedoutputeventtotheperipheralarbiters,whichsenditsaddressandsignout.
Paralleltothisper-eventprocessing,thereisaglobalforgettingmecha-nismcommonforallpixels:pixelvaluesaredecremented(iftheyarepositive)orincremented(iftheyarenegative)triggeredbyaglobalperiodicsignal.
Thisimplementsaconstantleakofxedratethatdischargestheneurons,allowingtheConvModuletocapturedynamicrealitywithatimeconstantintheorderofthisleak.
Amoreformalmathematicaljusticationofthisevent-drivencon-volutionoperationcanbefoundelsewhere(Serrano-Gotarredonaetal.
,1999).
3.
3.
FPGAIMPLEMENTATIONFigure4showstheblockdiagramofanFPGAspike-basedcon-volver.
Aserialperipheralinterface(SPI)isusedtocommunicatewithaUSBmicrocontrollerinordertoallowtochangethecon-gurationfromalaptop(Kernelmatrix,kernelsize,forgettingperiod,andforgettingquantity).
ThecircuitintheFPGAcanbedividedintothefollowingparallelblocks:A64*64arrayofmemorycells:thematrixisimplementedusingablockofdual-portRAMintheFPGA.
EachpositionoftheRAMis8-bitlength.
Kernelmemory:ThekernelisstoredalsointheinternalRAMoftheFPGAinan11*11matrixwith8-bitresolution.
Convstatemachine:Eachinputeventcorrespondstotheaddressofapixel.
Centeredonthisaddress,thekernelisaddedtothememorymatrix,whichisusedtosavethestateoftheconvolutioncells.
Ifanyofthemodiedcellsreachesavaluehigherthanaglobalprogrammablethreshold(Th),anoutputeventwiththiscelladdressisqueuedtobesentthroughtheAERoutputbus,andthecellisreset.
Forgettingmechanism.
Acongurableforgettingcircuitryisalsopresentinthearchitecture.
Theforgettingisbasedonaprogrammablecounterthataccessesthememorymatrixperiodicallyinordertodecreaseitsvaluesbyaconstant.
Memoryarbiter.
The64*64cellmemorymatrixisasharedresourcebetweentheforgettingcircuitryandtheconvolutionstatemachine.
Therefore,amemoryarbiterisrequired.
FIFOandAERoutputstatemachine:A16eventrst-input-rst-outputbufferisusedtostoretheoutgoingeventsbeforetheyaretransmittedbythestatemachineusingtheasynchro-nousprotocol.
SPIStateMachine.
Thiscontrollerisinchargeofreceivingker-nelsizeandvalues,forgettingperiodandamounttoforget.
ThesystemisconguredandcontrolledthroughacomputerrunningMATLAB.
ThesystemhasbeenimplementedinhardwareinaVirtex-6FPGA.
AVHDLdescriptionofthisConvModulewith64*64pixelsandkernelsofsizeupto11*11hasbeenusedtoprogramdiffer-entConvModulearraysintoaVirtex-6FPGA,togetherwiththecorrespondinginter-modulecommunicationandeventroutingmachinery.
TheinternalstructureofcommercialFPGAswiththeirinternalmemoryarrangementanddistributionisnotoptimumforimplementingevent-drivenparallelmodules.
Nonetheless,itwaspossibletoincludeanarrayof64Gaborlters,eachwithaspecicscaleandorientationtoperformaV1visualcortexpre-processingoneventdatacomingoutofatemporaldifferenceretina(Zamarreo-Ramos,2011;Zamarreo-Ramosetal.
,underreview).
Table1summarizestheresourcesusedbytheVirtex-6.
3.
4.
EXAMPLESYSTEMANDOPERATIONTheexampleinFigure5illustratesevent-drivensensingandprocessing,andpseudo-simultaneity,onaverysimpleFIGURE4|BlockdiagramoftheFPGAAER-basedconvolutionprocessor(left)anditsStateMachine(right).
www.
frontiersin.
orgApril2012|Volume6|Article32|5Farabetetal.
Comparison:framevs.
spikingconvNetsTable1|Frame-freeFPGAresourceconsumption.
ResourcesofaVirtex6LX240T#Used128*8-bitsingle-portblockRAM6416*1-bitsingle-portread-onlydistributedRAM6416*16-bitdual-portdistributedRAM644096*8-bitsingle-portblockRAM644*4-bitsingle-portread-onlydistributedRAM164*64-bitsingle-portread-onlydistributedRAM12-33-bitadders/subtractors27522-14-bitcounters1487Flip-ops91397Finite-state-machines15572-33-bitcomparators32741-32-bitmultiplexors25801Slicesregisters74987outof301440(24%)SlicesLUTs83521outof150720(55%)OccupiedSlices32720outof37680(86%)BlockRAM36E1/FIFO64outof416(15%)BlockRAM18E1/FIFO68outof832(8%)two-convolutionsetup.
Figure5Ashowsthebasicsetup.
A52carddeckisbrowsedinfrontofamotionsensitiveAERretina(Leero-Bardalloetal.
,2011).
Figure5Bshowsapicturetakenwithacommercialcamerawith1/60sec(16.
67ms)exposuretime.
Figure5Cshowstheeventscapturedduringa5-mstimewindow,whileacardwith"clover"symbolsisbrowsed.
Figure5Dshowstheinstantaneouseventrateforthewholeeventsequencewhenbrowsingthecomplete52carddeck.
Mostcardsarebrowsedina410-mstimeinterval,withpeakeventrateofabout8Meps(megaeventspersecond)computedon10μstimebins.
Theeventsproducedbytheretinaaresent(eventafterevent)toarstEvent-DrivenConvolutionchipprogrammedwiththekernelinFigure5Etolteroutnoiseandenhanceshapesofamini-mumsize.
TheoutputeventsproducedbythisrstConvolutionchiparesenttoasecondConvolutionchipprogrammedwiththekernelinFigure5F.
Thiskernelperformscrudetemplatematch-ingtodetect"clover"symbolsofaspecicsizeandorientation.
Inordertoperformmoresophisticatedsizeandposeinvariantobjectrecognitionafullmulti-stageConvNetwouldbeneces-sary.
However,thissimpleexampleissufcienttoillustratethepseudo-simultaneityproperty.
Thetwo-convolutionsystemwassimulatedusingthesimulatordescribedinSection1andusingrecordedeventdatatakenfromarealMotionSensitiveretina(Leero-Bardalloetal.
,2011)usinganeventdataloggerboard(Serrano-Gotarredonaetal.
,2009).
Thiseventdataloggerboardcanrecordupto500keventswithpeakratesofupto9Meps.
Figure5Gshowstheretinaevents(reddots),therstconvo-lutionoutputevents(greencircles)andthesecondconvolutionoutputevents(bluestars)inyvs.
timeprojection,fora85-mstimeinterval.
Onecanseeveryclearlytheeventscorrespondingto4cards(numbered"1"to"4"inthegure).
Cards"2"to"4"contain"clover"symbolsthatmatchthesizeandorientationofFIGURE5|Illustrationofpseudo-simultaneityinfastevent-drivenrecognition.
(A)Feed-forwardTwo-Convolutionsystem.
(B)Photographwithcommercialcameraat1/60s.
(C)FivemillisecondseventcapturefromAERmotionretina.
(D)Eventratecomputedusing10μsbins.
(E)Firstpre-lteringKernel.
(F)Secondtemplate-matchingkernel.
(G)Eventsfromrealretina(reddots),simulatedoutputofrstlter(greencircles),andsimulatedoutputofsecondlter(bluestars).
(H)y/timezoomout.
(I)x/yzoomout.
thekernel.
Figure5Gincludesazoomboxbetween26and29ms.
TheeventsinsidethiszoomboxareshowninFigure5Hinyvs.
timeprojection,andinFigure5Iinyvs.
xprojection.
Asonecansee,betweentime26and29msaclear"clover"symbolispresentattheretinaoutput(smallreddots).
Theretina"clover"eventsrangebetween26.
5and29ms(2.
5msduration).
Theout-puteventsoftherstlter(greencircles)rangebetweentime26.
5and28.
5ms(2.
0msduration),whichisinsidethetimewindowoftheretinaevents.
Consequently,retinaandrstconvolutionFrontiersinNeuroscience|NeuromorphicEngineeringApril2012|Volume6|Article32|6Farabetetal.
Comparison:framevs.
spikingconvNetsstreamsaresimultaneous.
TheoutputeventsofthesecondCon-volution(thickbluedots)areproducedattime27.
8ms(1.
3msafterthe1stretina"clover"eventand1.
2msbeforetheretinalast"clover"event),whichisduringthetimetheretinaisstillsendingouteventsofthe"clover"symbol,andalsowhiletherstConvolu-tionisstillprovidingoutputeventsforthissymbol.
Notethatthesecondconvolutionneedstocollectaverylargenumberofeventsbeforemakingadecision,becauseitskernelisverylarge.
However,inastandardConvNetwithmanyConvModules,kernelsareusu-allymuchsmallerandwouldrequiremuchlessinputeventstostartprovidingoutputs,thereforealsospeedingupthewholerecogni-tionprocess,inprinciple.
AscanbeseeninFigures5G,H,cloversymbolrecognitionisachievedevenbeforethesensorhasdeliv-eredalltheeventsthatformthesymbol.
Allthisillustratesquitenicelythepseudo-simultaneitypropertyofframe-freeevent-drivensystems.
ThiscontrastswiththeFrame-Constraintphilosophy.
Evenifonehasaveryhigh-speedvideocamera,say1kframe/s,thesystemhasrsttoacquireanimage(whichwouldtake1ms),sendittoaframe-constraintprocessingsystem(liketheonedescribedinSection4),andassumingitcanprovideanoutputafteranother1ms,therecognitionresultwouldbeavailable2msafterthestartofsensing.
AlthoughthesetimesarecomparabletowhatisshowninFigure5H,thesensingoutputandtheprocessingoutputaresequential,theyarenotsimultaneous.
Thisisonekeyconcep-tualdifferencebetweenthetwoapproaches.
Tounderstandhowthisextrapolatestomultiplelayers,letusrefertoFigure6.
Atthetop(Figure6A)thereisa6-layerConvNetfeatureextractionsystemforobjectrecognition.
LetusassumeeachlayercontainsalargenumberoffeatureextractionConvModules,whoseout-putsaresenttoeachsubsequentlayer.
LetusassumethatwehaveaveryfastFrame-basedprocessingsystemperlayer(astheonedescribedinthenextSection)andthatitiscapableofcomput-ingallfeaturemapswithinalayerin1ms.
Letusassumealsothatwehaveaveryfastsensorcapableofprovidingaframerateof1image/ms(1000fps),andthattheoutputofeachstagecanbetransmittedtothenextstagemuchfasterthanin1ms.
Letusalsoassumethatthereisasuddenvisualstimulusthatlastsforabout1msorless.
Figure6BshowsthetimingdiagramfortheoutputsxiateachsubsequentlayerofaFrame-basedimple-mentation.
Thesuddenstimulushappensbetweentime0and1ms,andthesensoroutputisprovidedattime1ms.
Therstlayerfeaturemapsoutputisavailableattime2ms,thesecondattime3ms,andsoonuntilthelastoutputisavailableattime6ms.
Figure6Cshowshowthetimingoftheeventswouldbeinanequivalentsixlayerevent-drivenimplementation.
AsinFigure5,thesensorprovidestheoutputeventssimultaneouslytoreality,thusduringtheintervalfrom0to1ms.
Similarly,the1stevent-drivenfeaturemapsx1wouldbeavailableduringthesameinterval,andsoonforallsubsequentlayersxi.
Conse-quently,thenaloutputx5willbeavailableduringthesametimeintervalthesensorisprovidingitsoutput,thisis,duringinterval0to1ms.
Animmediatefeaturethatthepseudo-simultaneitybetweeninputandoutputeventowsallows,isthepossibilityofefcientlyimplementingfeedbacksystems,asfeedbackwouldbeinstanta-neouswithoutanyneedtoiterateforconvergence.
However,thisfeatureisnotexploitedinpresentdayConvNets,becausetheyarepurelyfeed-forward.
3.
5.
FRAME-CONSTRAINEDFIX-PIXEL-VALUEConvNetsInthissectionwepresentarun-timeprogrammabledata-owarchitecture,speciallytailoredforFrame-ConstrainedFix-Pixel-ValueConvNets.
WewillrefertothisimplementationastheFC-ConvNetProcessor.
Theprocessorreceivessequencesofstillimages(frames).
Foreachframe,pixelshavex(constant)values.
Thearchitecturepresentedherehasbeenfullycodedinhardwaredescriptionlanguage(HDL)thattargetbothASICsynthesisandprogrammablehardwarelikeFPGAs.
AschematicsummaryoftheFC-ConvNetProcessorsystemispresentedinFigure7A.
Themaincomponentsare:(1)aControlUnit(implementedonageneral-purposeCPU),(2)agridofindependentProcessingTiles(PTs),eachcontainingaroutingmultiplexer(MUX)andlocaloperators,and(3)aSmartDMAinterfacingexternalmemoryviaastandardcontroller.
Thearchitecturepresentedhereproposesaverydifferentpar-adigmtoparallelism,aseachPTonlycontainsusefulcomputinglogic.
Thisallowsustousethesiliconsurfaceinamostefcientway.
Infact,whereatypicalmulti-processorsystemwouldbeabletouse50cores,theproposeddata-owgridcouldimplement500tiles.
Forimageprocessingtasks(ConvNetsinthiscase),thefollow-ingobservations/designchoicesfullyjustifytheuseofthistypeofgrid:Throughputisatoppriority.
Indeed,mostoftheoperationsperformedonimagesarereplicatedoverbothdimensionsofimages,usuallybringingtheamountofsimilarcomputationstoanumberthatismuchlargerthanthetypicallatenciesofapipelinedprocessingtile.
Recongurationtimehastobelow(intheorderofthesystem'slatency).
Thisisachievedbytheuseofacommonrun-timecongurationbus.
Eachmoduleinthedesignhasasetofcon-gurableparameters,routesorsettings(depictedassquaresonFigure7A),andpossessesauniqueaddressonthenetwork.
Groupsofsimilarmodulesalsoshareabroadcastaddress,whichdramaticallyspeedsuptheirreconguration.
Theprocessingelementsinthegridshouldbeascoarsegrainedaspermitted,tomaximizetheratiobetweencomputinglogicandroutinglogic.
Theprocessingelementsshouldnothaveanyinternalstate,butshouldjustpassivelyprocessanyincomingdata.
Thetaskofsequencingoperationsisdonebytheglobalcontrolunit,whichstoresthestateandsimplycongurestheentiregridforagivenoperation,letsthedata-owin,andpreparesthefollowingoperation.
Figure7Bshowshowthegridcanbeconguredtocomputeasub-partofaConvNet(asumoftwoconvolutionsisfedtoanon-linearmapper).
Inthatparticularconguration,boththekernelsandtheimagesarestreamsloadedfromexternalmemory(thelterkernelscanbepre-loadedinlocalcachesconcurrentlytoanotheroperation).
Byefcientlyalternatingbetweengridrecongurationanddatastreaming,anentireConvNetcanbecomputed(unrolledintime).
www.
frontiersin.
orgApril2012|Volume6|Article32|7Farabetetal.
Comparison:framevs.
spikingconvNetsFIGURE6|Illustrationofpseudo-simultaneityconceptextrapolatedtomultiplelayers.
(A)VisionsystemcomposedofVisionSensorandvesequentialprocessingstages,likeinaConvNet.
(B)TiminginaFrame-constraintsystemwith1msframetimeforsensingandperstageprocessing.
(C)TiminginanEvent-drivensystemwithmicro-seconddelaysforsensorandprocessorevents.
AcompilertakesasoftwarerepresentationofatrainedCon-vNet,andproducesthebinarycodetobeexecutedontheControlUnit.
TheConvNetProcessorcanbereprogrammedwithnewbinarycodeatrun-time.
Thecompilertypicallyexecutesthefollowingoperations:Step1:AnalysesagivenConvNetlayerbylayer,andper-formscross-layeroptimizations(likelayercombinationsandmerging).
Step2:Createsamemorymapwithefcientpacking,toplaceallintermediateresults(mostlyfeaturemapsforConvNets)inaminimalmemoryfootprint.
Step3:Decomposeseachlayerfromstep1intosequencesofgridrecongurationsanddatastreams.
EachrecongurationresultsinasetofoperationstobeperformedbytheControlUnitandeachdatastreamresultsinasetofoperationsfortheSmartDMA(toread/writefrom/toexternalmemory).
Step4:ResultsfromStep3areturnedintoafullysequentialbinarycodefortheControlUnit.
OurarchitecturewasimplementedontwoFPGAs,alow-endVir-tex4withlimitedmemorybandwidthandahigh-endVirtex-6withfourfoldmemorybandwidth.
Figure8showsthetimetakentocomputeatypicalConvNettrainedforsceneanalysis/obstacledetection(pixel-wiseclassica-tion,seeHadselletal.
,2009),ondifferentcomputingplatforms.
TheCPUimplementationisclassicalCimplementationusingBLASlibraries.
TheGPUimplementationisahand-optimizedimplementationthatusesasmanyofthecoresaspossible.
TheGPU,annVidia9400Misamiddle-rangeGPUoptimizedforFrontiersinNeuroscience|NeuromorphicEngineeringApril2012|Volume6|Article32|8Farabetetal.
Comparison:framevs.
spikingconvNetsFIGURE7|(A)Adata-owcomputer.
Asetofrun-timecongurableprocessingtilesareconnectedona2Dgrid.
Theycanexchangedatawiththeir4neighborsandwithanoff-chipmemoryviagloballines.
(B)Thegridisconguredforamorecomplexcomputationthatinvolvesseveraltiles:the3toptilesperforma3*3convolution,the3intermediatetilesanother3*3convolution,thebottomlefttilesumsthesetwoconvolutions,andthebottomcentertileappliesafunctiontotheresult.
low-power.
Ascanbeseen,themostgenerichardware(CPU)istheleastefcientbecauseitislessparallelandreliesonheavyprocessor-memorytrafc.
TheGPUimprovesaboutanorderofmagnitude,asmoreparallelismisachieved.
FPGAimplemen-tationscanbemadetoexploitmassiveparallelismwithhigh-bandwidthmemories,thusachievingmuchhigherefciencies.
Finally,adedicatedASICinahigh-endtechnologywouldbeoptimum.
3.
6.
COMPARISONBETWEENFRAME-CONSTRAINEDANDFRAME-FREESPIKINGConvNetsInordertocompareFrame-Constrainedvs.
Frame-FreespikinghardwareperformanceofConvNetsimplementations,weneedtobeawareofthefundamentaldifferencebetweeninformationcodingofbothapproaches.
FIGURE8|ComputingtimeforatypicalConvNet,versusthenumberofconnectionsusedfortrainingthenetwork.
InaFrame-Constrainedvisionsystem,visualrealityissampledatarateTframe.
Theinputtothesystemisthen,foreachTframe,anarrayofN*Mpixelseachcarryingann-bitvalue.
Thereisaxedamountofinputinformationperframe.
ForagivenCon-vNettopology(asinFigure1),oneknowsexactlythenumberandtypeofoperationsthathavetobecarriedoutstartingfromtheinputframe.
Dependingontheavailablehardwareresources(multipliers,adders,accumulators,etc)onecanestimatethedelayinprocessingthefullConvNetforoneinputimage,independentlyonthecontentoftheimage.
IfthefullConvNetoperatorscanbemappedonebyoneontorespectivehardwareoperators,thennointermediatecomputationdatahastobefetchedinandoutfromthechip/FPGAtoexternalmemory.
Thisistheidealcase.
However,inpracticalimplementationsto-date,eithertheinputimageisprocessedbypatches,ortheConvNetisprocessedbypartswithinthehardware,oracombinationofboth,usingexten-sivechip/FPGAtoexternalmemorytrafc.
Let'scallRhwtheratiobetweentheavailablehardwareresourcesandallthehardwareresourcesagivenConvNetwouldrequiretocomputethefullinputframewithoutfetchingintermediatedatato/fromexternalmem-ory.
Then,inFrame-ConstrainedFix-Pixel-ValueConvNetsspeedisastrongfunctionofRhwandtheexternalmemorybandwidth.
InaFrame-FreeSpikingSystem,sensorpixelsgeneratespikescontinuouslyandasynchronously.
Visualinformationisrepre-sentedbyaowofevents,eachdenedin3D(x,y,t).
Manytimesaneventcarriesalso"sign"information(positiveorneg-ative).
Thenumberofspikespersecondinthevisualowishighlydependentonsceneinformationcontent(asopposedtotheFrame-Constrainedcase).
InFrame-FreeSpikingsystems,thefullConvNetstructure(asinFigure1)mustbeavailableinhardware.
Consequently,Rhw=1.
Thisisduetothefactthatvisualinforma-tionateachnodeoftheConvNetisrepresentedbyasequenceorowofeventsthat"ll"thetimescaleandkeepsynchronyamongallnodes.
Thegreatadvantageofthisisthatthedifferentowsarepracticallysimultaneousbecauseofthe"pseudo-simultaneity"propertyofinput-to-outputowsineachConvNetmodule.
Thewww.
frontiersin.
orgApril2012|Volume6|Article32|9Farabetetal.
Comparison:framevs.
spikingconvNetsprocessingdelaybetweeninput-to-outputowsisdeterminedmainlybythestatisticsoftheinputeventowdata.
Forexample,howmanyspace-timecorrelatedinputeventsneedtobecollectedthatrepresentagivenshape.
Ifonetriestotime-multiplexthehardwareresources(forimplementinglargernetworks,forexam-ple)thentheowswouldneedtobesampledandstored,whichwouldconvertthesystemintoaFrame-Constrainedone.
Conse-quently,ifonewantstoscaleupaFrame-FreeSpikingConvNet,thenitisnecessarytoaddmorehardwaremodules.
Inprinciple,thisshouldbesimple,asinter-modulelinksareasynchronousandmodulesareallalike.
Asthesystemscalesup,however,processingspeedisnotdegraded,asitisdeterminedbythestatisticalinforma-tioncontentoftheinputeventow.
NotethatthisisafundamentaldifferencewithrespecttoFrame-constrainedsystems,whereoneneedstorstwaitforthesensortoprovideafullframebeforestartingprocessingit.
Scalingupaspikingsystemdoesnotaffectthepseudo-simultaneityproperty.
Animportantlimitationwillbegivenbytheinter-moduleeventcommunicationbandwidth.
Nor-mally,eventratelowersasprocessingisperformedatsubsequentstages.
Thusthehighesteventrateisusuallyfoundatthesen-soroutput.
Consequently,itisimportantthatthesensorsincludesomekindofpre-processing(suchasspatialortemporalcontrast)toguaranteearathersparseeventcount.
AlthoughpresentdayConvNetsarepurelyfeed-forwardstruc-tures,itiswidelyacceptedthatcomputationsinbrainsexploitextensiveuseoffeedbackbetweenprocessinglayers.
InaFrame-constraintsystem,implementingfeedbackwouldrequiretoiterateeachfeed-forwardpassuntilconvergence,foreachframe.
Ontheotherhand,inFrame-freeevent-drivensystems,sinceinputandoutputowsateachmoduleareinstantaneous,feedbackwouldbeinstantaneousaswell,withoutanyneedforiterations.
AnotherbigdifferencebetweenFrame-ConstrainedandFrame-Freeimplementationsisthattherstoneistechnologicallymorematurewhilethesecondoneisveryincipientandinresearchphase.
Table2summarizesthemaindifferencesbetweenbothapproachesintermsofhowdataisprocessed,whetherhardwaremultiplexingispossible,howhardwarecanbescaled-up,andwhatdeterminesprocessingspeedandpowerconsumption.
NotethatAERspikinghardwareiseasilyexpandableinamodularfashionbysimplyinterconnectingAERlinks(Serrano-Gotarredonaetal.
,2009;Zamarreo-Ramosetal.
,underreview).
However,expand-ingtheFPGAhardwaredescribedinSection4isnotsostraightforwardanddedicatedadhoctechniquesneedtobedeveloped.
Table3comparesnumericallyperformanceguresofcom-parableConvNetsimplementedusingeitherFrame-Constrainedx-pixel-valueorFrame-freespiking-dynamic-pixeltechniques.
ThersttwocolumnsshowperformanceguresofarraysofGaborlterssynthesizedintoVirtex-6FPGAs.
ThePurdue/NYUsystemimplementsanarrayof16parallel10*10kernelGaborltersoperatingoninputimagesof512*512pixelswithadelayof5.
2ms,thusequivalentto4M-neuronswith400M-synapsesandacomputingpowerof7.
8*1010conn/s.
TheIMSE/USsys-temimplementsanarrayof64Gaborltersoperatingoninputvisualscenesof128*128pixelswithdelaysof3μsper-eventpermodule,thusequivalentto0.
26M-neuronswith32M-synapsesandacomputingpowerof2.
6*109conn/s.
Notethatwhilethe5.
2msdelayofthePurdue/NYUFrame-Constraintsystemrepresentsthelteringdelayof16ConvMod-ules,the3-μs/eventdelayoftheIMSE/USsystemdoesnotrep-resentalteringdelay.
Thisnumbersimplycharacterizestheintrinsicspeedofthehardware.
Thelteringorrecognitiondelaywillbedeterminedbythestatisticaltimedistributionofinputevents.
Assoonasenoughinputeventsareavailablethatallowthesystemtoprovidearecognitiondecision,anoutputeventwillbeproduced(3μsafterthelastinputevent).
Table2|Frame-freevs.
frame-constrained.
Frame-freeFrame-constrainedDataprocessingPer-event,resultinginpseudo-simultaneityPerframe/patchHardwaremultiplexingNotpossiblePossibleHardwareup-scalingByaddingmodulesAdhocSpeedDeterminedbystatisticsofinputstimuliDeterminedbynumberandtypeofoperations,availablehardwareresourcesandtheirspeedPowerconsumptionDeterminedbymodulepowerper-event,andinter-modulecommunicationpowerper-eventDeterminedbypowerofprocessor(s)andmemoryfetchingrequirementsFeedbackInstantaneous.
NoneedtoiterateNeedtoiterateuntilconvergenceforeachframeTable3|Performancecomparison.
Purdue/NYUIMSE/US3DASICGrid40nmInputscenesize521*512128*128512*512512*512Delay5.
2ms/frame3μs/event1.
3ms/frame10ns/eventsGaborarray16convs10*10kernels64convs11*11kernels16convs10*10kernels100convs32*32kernelsNeurons4.
05*1062.
62*1054.
05*106108Synapses4.
05*1083.
20*1074.
05*1081011Conn/s7.
8*10102.
6*1093*10114*1013FrontiersinNeuroscience|NeuromorphicEngineeringApril2012|Volume6|Article32|10Farabetetal.
Comparison:framevs.
spikingconvNetsThethirdandfourthcolumnsrepresentperformanceestima-tionsforfuturisticFrame-constrainedandFrame-freesystems.
Column3correspondstotheASICsystemsprojectedforahigh-end3Dtechnology(seeFigure7),wherespeedisimprovedafactorfourforagivennumberofconnectionswithrespecttotheVirtex-6realization.
Columnfourcorrespondstotheestimatedperformanceforanarrayof100recongurablemulti-module40nmtechnologychips.
Basedontheperformanceguresofanalreadytestedevent-drivenConvChipfabricatedin0.
35μmCMOS(Camuas-Mesaetal.
,2011,2012),whichholdsanarrayof64*64pixelsinabout5mm*5mm,itisreasonabletoexpectthata1-cm2diefabricatedin40nmCMOScouldhold1millionneuronswith1G-synapses.
Inordertoimproveeventthrough-put,processingpixelsshouldbetiledintoslicestoavoidverylonglinesandpipeline/parallelizeeventprocessing.
Off-chipeventcommunicationshouldbedoneserially(Zamarreo-Ramosetal.
,2011a,b),andpossiblyusingmultipleI/Oportstoimproveinter-chipthroughput.
Allthiscouldprobablyimproveeventthrough-putbyafactorof100withrespecttothepresentedprototype.
Consequently,wemightconsiderasviable,eventthroughputsintheorderof108eps(eventspersecond)perchip.
UsingAER-meshtechniques(Zamarreo-Ramos,2011;Zamarreo-Ramosetal.
,underreview)toassemblemodularlyagridof10*10suchchipsona(stackable)PCBwouldallowforaConvNetsystemwithabout108neuronsand1011synapses,whichisabout1%ofthehumancerebralcortex(Azevedoetal.
,2009),intermsofnumberofneu-ronsandsynapses.
Thebrainiscertainlymoresophisticatedandhasotherfeaturesnotconsideredhere,suchaslearning,synapticcomplexity,stochastic,andmolecularcomputations,andmore.
InordertocomparetheeffectiveperformancecapabilityofFrame-ConstraintversusFrame-Freehardware,themostobjec-tivecriteriaistocomparetheir"connections/second"capability,asshowninthebottomofTable3.
However,thesenumbersshouldalsonotbejudgedasstrictlyequivalent,becausewhiletheFrame-Freeversioncomputesconnections/seconactivepixelsonly,theFrame-Constraintversionhastocomputeconnection/sforallpix-elsthusintroducinganextraoverhead.
Thisoverheaddependsonthestatisticalnatureofthedata.
4.
CONCLUSIONWehavepresentedacomparisonanalysisbetweenFrame-ConstrainedandFrame-FreeImplementationsofConvNetSys-temsforapplicationinobjectrecognitionforvision.
WehavepresentedexampleimplementationsofFrame-ConstrainedFPGArealizationofafullConvNetsystem,andpartialconvolutionprocessingstages(orcombinationofstages)usingspikingAERconvolutionhardwareusingeitherVLSIconvolutionchipsorFPGArealizations.
Thedifferencesbetweenthetwoapproachesintermsofsignalrepresentations,computationspeed,scalability,andhardwaremultiplexinghavebeenestablished.
REFERENCESAzadmehr,M.
,Abrahamsen,J.
,andHiger,P.
(2005).
"AfoveatedAERimagerchip,"inProceedingsoftheIEEEInternationalSymposiumonCircuitsandSystems.
(ISCAS)(Kobe:IEEEPress),2751–2754.
Azevedo,F.
A.
,Carvalho,L.
R.
,Grin-berg,L.
T.
,Farfel,J.
M.
,Ferretti,R.
E.
,Leite,R.
E.
,JacobFilho,W.
,Lent,R.
,andHerculano-Houzel,S.
(2009).
Equalnumbersofneuronalandnonneuronalcellsmakethehumanbrainanisometricallyscaled-uppri-matebrain.
J.
Comp.
Neurol.
513,532–541.
Boahen,K.
(1999).
"Retinomorphicchipsthatseequadrupleimages,"inProceedingsoftheInternationalCon-ferenceMicroelectronicsforNeural,FuzzyandBio-InspiredSystems(Microneuro)(Granada:IEEEPress),12–20.
Boser,B.
,Sckinger,E.
,Bromley,J.
,LeCun,Y.
,andJackel,L.
(1991).
Ananalogneuralnetworkproces-sorwithprogrammabletopology.
IEEEJ.
SolidStateCircuits26,2017–2025.
Camuas-Mesa,L.
,Acosta-Jiménez,A.
,Zamarreo-Ramos,C.
,Serrano-Gotarredona,T.
,andLinares-Barranco,B.
(2011).
Aconvolutionprocessorchipforaddresseventvisionsensorswith155nseventlatencyand20Mepsthroughput.
IEEETrans.
CircuitsSyst.
58,777–790.
Camuas-Mesa,L.
,Zamarreo-Ramos,C.
,Linares-Barranco,A.
,Acosta-Jiménez,A.
,Serrano-Gotarredona,T.
,andLinares-Barranco,B.
(2012).
Anevent-drivenconvolutionprocessormoduleforevent-drivenvisionsensors.
IEEEJ.
SolidStateCircuits47,504–517.
Chan,V.
,Liu,S.
-C.
,andvanSchaik,A.
(2007).
AEREAR:amatchedsili-concochleapairwithaddresseventrepresentationinterface.
IEEETrans.
CircuitsSyst.
PartI54,48–59.
Chen,S.
,andBermak,A.
(2007).
Arbi-tratedtime-to-rstspikeCMOSimagesensorwithon-chiphis-togramequalization.
IEEETrans.
VLSISyst.
15,346–357.
Chicca,E.
,Whatley,A.
M.
,Lichtsteiner,P.
,Dante,V.
,Delbrück,T.
,DelGiu-dice,P.
,Douglas,R.
J.
,andIndiveri,G.
(2007).
Amultichippulse-basedneuromorphicinfrastructureanditsapplicationtoamodeloforientationselectivity.
IEEETrans.
CircuitsSyst.
PartI54,981–993.
Choi,T.
Y.
W.
,Merolla,P.
,Arthur,J.
,Boahen,K.
,andShi,B.
E.
(2005).
Neuromorphicimplementationoforientationhypercolumns.
IEEETrans.
CircuitsSyst.
PartI52,1049–1060.
Cloutier,J.
,Cosatto,E.
,Pigeon,S.
,Boyer,F.
,andSimard,P.
Y.
(1996).
"Vip:anfpga-basedprocessorforimageprocessingandneuralnetworks,"inProceedingsoftheFifthInterna-tionalConferenceonMicroelectron-icsforNeuralNetworksandFuzzySystemsMicroNeuro'96(Lausanne:IEEEPress),330–336.
Costas-Santos,J.
,Serrano-Gotarredona,T.
,Serrano-Gotarredona,R.
,andLinares-Barranco,B.
(2007).
Acon-trastretinawithon-chipcalibra-tionforneuromorphicspike-basedAERvisionsystems.
IEEETrans.
CircuitsSyst.
IReg.
Papers54,1444–1458.
Culurciello,E.
,Etienne-Cummings,R.
,andBoahen,K.
(2003).
Abiomor-phicdigitalimagesensor.
IEEEJ.
SolidStateCircuits38,281–294.
Delbrück,T.
(2005).
http://jaer.
wiki.
sourceforge.
netDelbrück,T.
(2008).
"Frame-freedynamicdigitalvision,"inProceed-ingsofInternationalSymposiumonSecure-LifeElectronics,AdvancedElectronicsforQualityLifeandSoci-ety(Tokyo:UniversityofTokyo),21–26.
Hadsell,R.
,Sermanet,P.
,Erkan,A.
,Ben,J.
,Han,J.
,Flepp,B.
,Muller,U.
,andLeCun,Y.
(2007).
'On-linelearningforoffroadrobots:usingspatiallabelpropagationtolearnlong-rangetra-versability,"inProceedingsofRoboticsScienceandSystems'07,MITPress,Cambridge.
Hadsell,R.
,Sermanet,P.
,Scofer,M.
,Erkan,A.
,Kavackuoglu,K.
,Muller,U.
,andLeCun,Y.
(2009).
Learninglong-rangevisionforautonomousoff-roaddriving.
J.
FieldRobotics26,120–144.
Huang,F.
-J.
,andLeCun,Y.
(2006).
"Large-scalelearningwithsvmandconvolutionalnetsforgenericobjectcategorization,"inProceedingsofComputerVisionandPatternRecog-nitionConference(CVPR'06)(NewYork:IEEEPress).
Jarrett,K.
,Kavukcuoglu,K.
,Ranzato,M.
,andLeCun,Y.
(2009).
"Whatisthebestmulti-stagearchitectureforobjectrecognition,"inProceed-ingsofInternationalConferenceonComputerVision(ICCV'09)(Kyoto:IEEE).
LeCun,Y.
,Boser,B.
,Denker,J.
S.
,Hen-derson,D.
,Howard,R.
E.
,Hub-bard,W.
,andJackel,L.
D.
(1990).
"Handwrittendigitrecognitionwithaback-propagationnetwork,"InNIPS'89,MITPress,Denver.
LeCun,Y.
,Bottou,L.
,Bengio,Y.
,andHaffner,P.
(1998a).
Gradient-basedlearningappliedtodocumentrecog-nition.
ProceedingsoftheIEEE86,2278–2324.
LeCun,Y.
,Bottou,L.
,Orr,G.
,andMuller,K.
(1998b).
"Efcientback-prop,"inNeuralNetworks:TricksoftheTrade,edsG.
Orr,andK.
Muller(Springer).
www.
frontiersin.
orgApril2012|Volume6|Article32|11Farabetetal.
Comparison:framevs.
spikingconvNetsLeero-Bardallo,J.
A.
,Serrano-Gotarredona,T.
,andLinares-Barranco,B.
(2010).
Ave-decadedynamic-rangeambient-light-independentcalibratedsigned-spatial-contrastAERretinawith0.
1mslatencyandoptionaltime-to-rst-spikemode.
IEEETrans.
CircuitsSyst.
IReg.
Papers57,2632–2643.
Leero-Bardallo,J.
A.
,Serrano-Gotarredona,T.
,andLinares-Barranco,B.
(2011).
A3.
6μslatencyasynchronousframe-freeevent-baseddynamicvisionsensor.
IEEEJ.
SolidStateCircuits46,1443–1455.
Lichtsteiner,P.
,Posch,C.
,andDelbrück,T.
(1998).
A128–128120db15uslatencyasynchronoustemporalcon-trastvisionsensor.
IEEEJ.
SolidStateCircuits43,566–576.
Lyu,S.
,andSimoncelli,E.
P.
(2008).
"Nonlinearimagerepresentationusingdivisivenormalization,"inComputerVisionandPatternRecog-nition,IEEE,Anchorage.
Massari,N.
,Gottardi,M.
,Jawed,S.
A.
,andSoncini,G.
(2008).
A100uw64*128-pixelcontrast-basedasynchronousbinaryvisionsensorforwirelesssensornetworks.
IEEEISSCCDig.
Tech.
Papers588–638.
Neubauer,C.
(1998).
Evaluationofcon-volutionneuralnetworksforvisualrecognition.
IEEETrans.
NeuralNetw.
9,685–696.
Osadchy,R.
,Miller,M.
,andLeCun,Y.
(2005).
"Synergisticfacedetec-tionandposeestimationwithenergy-basedmodel,"inAdvancesinNeuralInformationProcessingSys-tems(NIPS2004)(Vancouver:MITPress).
Oster,M.
,Yingxue,W.
,Douglas,R.
,andShih-Chii,L.
(2008).
Quanticationofaspike-basedwinner-take-allvlsinetwork.
IEEETrans.
Circuits.
Syst.
Part155,3160–3169.
Pérez-Carrasco,J.
A.
(2011).
ASim-ulationToolforBuildingandAna-lyzingComplexandHierarchicallyStructuredAERVisualProcessingSystems.
Ph.
D.
thesis,IMSE-CNM-CSIC,UniversidaddeSevilla,Sevilla.
Pinto,N.
,Cox,D.
D.
,andDiCarlo,J.
J.
(2008).
Whyisreal-worldvisualobjectrecognitionhardPLoSCom-put.
Biol.
4,e27.
doi:10.
1371/jour-nal.
pcbiPosch,C.
,Matolin,D.
,andWohlge-nannt,R.
(2010).
"AQVGA143dBDRasynchronousaddress-eventPWMdynamicvisionandimagesensorwithlosslesspixel-levelvideocompressionandtime-domainCDS,"inISSCCDigestofTechnicalPapers,SanFrancisco,inpress.
Ranzato,M.
,Huang,F.
,Boureau,Y.
,andLeCun,Y.
(2007).
"Unsupervisedlearningofinvariantfeaturehier-archieswithapplicationstoobjectrecognition,"inProceedingsofCom-puterVisionandPatternRecognitionConference(CVPR'07)(Minneapo-lis:IEEEPress).
Ruedi,P.
F.
,Heim,P.
,Gyger,S.
,Kaess,F.
,Arm,C.
,Caseiro,R.
,Nagel,J.
-L.
,andTodeschini,S.
(2009).
"Ansoccom-bininga132dbqvgapixelarrayanda32bdsp/mcuprocessorforvisionapplications,"inIEEEISSCCDigestofTechnicalPapers,SanFrancisco,46–47,47a.
Ruedi,P.
F.
,Heim,P.
,Kaess,F.
,Grenet,E.
,Heitger,F.
,Burgi,P.
-Y.
,Gyger,S.
,andNussbaum,P.
(2003).
A128*128,pixel120-dbdynamic-rangevision-sensorchipforimagecontrastandorientationextraction.
IEEEJ.
SolidStateCircuits38,2325–2333.
Sckinger,E.
,Boser,B.
,Bromley,J.
,LeCun,Y.
,andJackel,L.
D.
(1992).
ApplicationoftheANNAneuralnetworkchiptohigh-speedcharac-terrecognition.
IEEETrans.
NeuralNetw.
3,498–505.
Serrano-Gotarredona,R.
,Oster,M.
,Lichtsteiner,P.
,Linares-Barranco,A.
,Paz-Vicente,R.
,Gómez-Rodríguez,F.
,Camuas-Mesa,L.
,Berner,R.
,Rivas-Pérez,M.
,Delbrück,T.
,Liu,S.
-C.
,Douglas,R.
,Higer,P.
,Jiménez-Moreno,G.
,Ballcels,A.
C.
,Serrano-Gotarredona,T.
,Acosta-Jiménez,A.
J.
,andLinares-Barranco,B.
(2009).
CAVIAR:a45kneu-ron,5Msynapse,12Gconnects/sAERhardwaresensory-processing-learning-actuatingsystemforhigh-speedvisualobjectrecognitionandtracking.
IEEETrans.
NeuralNetw.
20,1417–1438.
Serrano-Gotarredona,R.
,Serrano-Gotarredona,T.
,Acosta-Jiménez,A.
,andLinares-Barranco,B.
(2006).
Aneuromorphiccortical-layermicrochipforspike-basedeventprocessingvisionsystems.
IEEETrans.
CircuitsSyst.
IRegul.
Papers53,2548–2566.
Serrano-Gotarredona,R.
,Serrano-Gotarredona,T.
,Acosta-Jiménez,A.
,Serrano-Gotarredona,C.
,Pérez-Carrasco,J.
A.
,Linares-Barranco,B.
,Linares-Barranco,A.
,Jiménez-Moreno,G.
,andCivit-Ballcels,A.
(2008).
Onreal-timeAER2-Dconvolutionhardwareforneu-romorphicspike-basedcorticalprocessing.
IEEETrans.
NeuralNetw.
19,1196–1219.
Serrano-Gotarredona,T.
,Andreou,A.
G.
,andLinares-Barranco,B.
(1999).
AERimagelteringarchitectureforvisionprocessingsystems.
IEEETrans.
CircuitsSyst.
PartIFundam.
TheoryAppl.
46,1064–1071.
Serre,T.
(2006).
LearningaDictio-naryofShape-ComponentsinVisualCortex:ComparisonwithNeurons,HumansandMachines.
Ph.
D.
thesis,MIT,Boston.
Shepherd,G.
(1990).
TheSynapticOrga-nizationoftheBrain,3rdEdn.
Oxford:OxfordUniversityPress.
Sivilotti,M.
A.
(1991).
"Wiringcon-siderationsinanalogVLSIsys-tems,withapplicationtoeld-programmablenetworks,"inTech-nicalReport,CaliforniaInstituteofTechnology,Pasadena.
Teixeira,T.
,Culurciello,E.
,andAndreou,A.
G.
(2006).
"Anaddress-eventimagesensornetwork,"inIEEEInternationalSymposiumonCircuitsandSystems,ISCAS'06(Kos:IEEE),4467–4470.
Thorpe,S.
,Fize,D.
,andMarlot,C.
(1996).
Speedofprocessinginthehumanvisualsystem.
Nature381,520–522.
Vernier,P.
,Mortara,A.
,Arreguit,X.
,andVittoz,E.
A.
(1997).
Aninte-gratedcorticallayerfororientationenhancement.
IEEEJ.
SolidStateCircuits32,177–186.
Vogelstein,R.
J.
,Mallik,U.
,Culurciello,E.
,Cauwenberghs,G.
,andEtienne-Cummings,R.
(2007).
Amulti-chipneuromorphicsystemforspike-basedvisualinformationprocessing.
NeuralComput.
19,2281–2300.
Zaghloul,K.
A.
,andBoahen,K.
(2004).
Opticnervesignalsinaneuro-morphicchip:parts1and2.
IEEETrans.
Biomed.
Eng.
51,657–675.
Zamarreo-Ramos,C.
(2011).
TowardsModularandScalableHigh-SpeedAERVisionSystems.
Ph.
D.
thesis,IMSE-CNM-CSIC,UniversidaddeSevilla,Sevilla.
Zamarreo-Ramos,C.
,Serrano-Gotarredona,T.
,Linares-Barranco,B.
,Kulkarni,R.
,andSilva-Martinez,J.
(2011a).
"Voltagemodedriverforlowpowertransmissionofhighspeedserialaerlinks,"inProceedingsofIEEEInternationalSymposiumonCircuitsandSystems(ISCAS2011)(RiodeJaneiro),2433–2436.
Zamarreo-Ramos,C.
,Serrano-Gotarredona,T.
,andLinares-Barranco,B.
(2011b).
Aninstant-startupjitter-tolerantmanchester-encodingserializer/deserializarschemeforevent-drivenbit-seriallvdsinter-chipaerlinks.
IEEETrans.
CircuitsSyst.
PartI58,2647–2660.
ConictofInterestStatement:Theauthorsdeclarethattheresearchwasconductedintheabsenceofanycom-mercialornancialrelationshipsthatcouldbeconstruedasapotentialcon-ictofinterest.
Received:28October2011;accepted:21February2012;publishedonline:12April2012.
Citation:FarabetC,PazR,Pérez-CarrascoJ,Zamarreo-RamosC,Linares-BarrancoA,LeCunY,Culur-cielloE,Serrano-GotarredonaTandLinares-BarrancoB(2012)Com-parisonbetweenframe-constrainedx-pixel-valueandframe-freespiking-dynamic-pixelconvNetsforvisualprocessing.
Front.
Neurosci.
6:32.
doi:10.
3389/fnins.
2012.
00032ThisarticlewassubmittedtoFrontiersinNeuromorphicEngineering,aspecialtyofFrontiersinNeuroscience.
Copyright2012Farabet,Paz,Pérez-Carrasco,Zamarreo-Ramos,Linares-Barranco,LeCun,Culurciello,Serrano-GotarredonaandLinares-Barranco.
Thisisanopen-accessarticledistributedunderthetermsoftheCreativeCommonsAttri-butionNonCommercialLicense,whichpermitsnon-commercialuse,distribu-tion,andreproductioninotherforums,providedtheoriginalauthorsandsourcearecredited.
FrontiersinNeuroscience|NeuromorphicEngineeringApril2012|Volume6|Article32|12
- extractor522av.com相关文档
- saturated522av.com
- install522av.com
- partecipa522av.com
- 小学522av.com
- initializes522av.com
- devices522av.com
老薛主机VPS年付345元,活动进行时。
老薛主机,虽然是第一次分享这个商家的信息,但是这个商家实际上也有存在有一些年头。看到商家有在进行夏季促销,比如我们很多网友可能有需要的香港VPS主机季度及以上可以半价优惠,如果有在选择不同主机商的香港机房的可以看看老薛主机商家的香港VPS。如果没有记错的话,早年这个商家是主营个人网站虚拟主机业务的,还算不错在异常激烈的市场中生存到现在,应该算是在众多商家中早期积累到一定的用户群的,主打小众个人网站...

简单测评v5.net的美国cn2云服务器:电信双程cn2+联通AS9929+移动直连
v5.net一直做独立服务器这块儿的,自从推出云服务器(VPS)以来站长一直还没有关注过,在网友的提醒下弄了个6G内存、2核、100G SSD的美国云服务器来写测评,主机测评给大家趟雷,让你知道v5.net的美国云服务器效果怎么样。本次测评数据仅供参考,有兴趣的还是亲自测试吧! 官方网站:https://v5.net/cloud.html 从显示来看CPU是e5-2660(2.2GHz主频),...
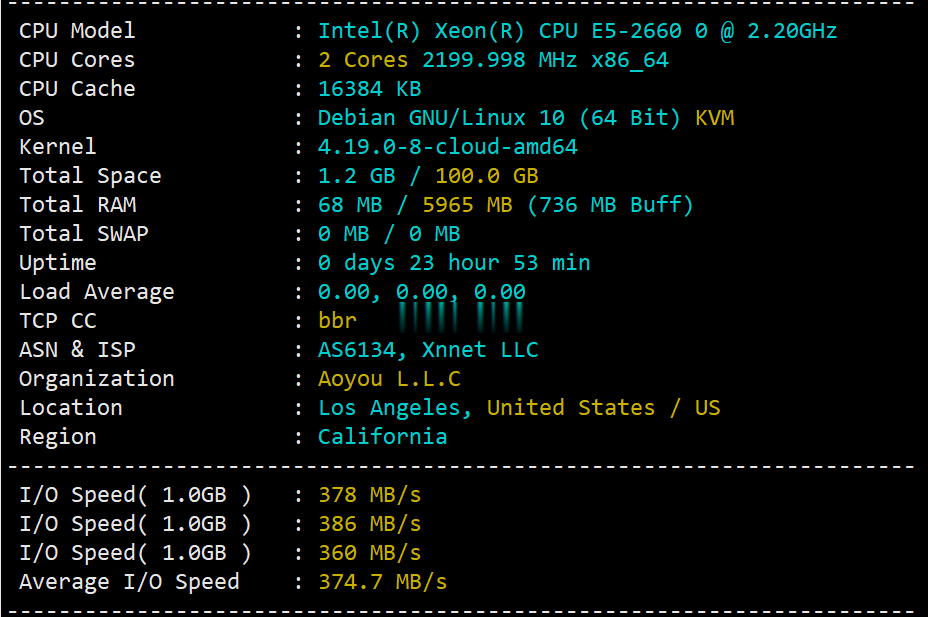
10gbiz:香港/洛杉矶CN2直连线路VPS四折优惠,直连香港/香港/洛杉矶CN2四折
10gbiz怎么样?10gbiz在本站也多次分享过,是一家成立于2020的国人主机商家,主要销售VPS和独立服务器,机房目前有中国香港和美国洛杉矶、硅谷等地,线路都非常不错,香港为三网直连,电信走CN2,洛杉矶线路为三网回程CN2 GIA,10gbiz商家七月连续推出各种优惠活动,除了延续之前的VPS产品4折优惠,目前增加了美国硅谷独立服务器首月半价的活动,有需要的朋友可以看看。10gbiz优惠码...
522av.com为你推荐
-
外挂购买自动充值软件.cn域名cn是什么域名?neworiental上海新东方有几个校区,分别是那几个?2020双十一成绩单2020考研成绩出分后需要做什么?硬盘的工作原理简述下硬盘的工作原理?微信回应封杀钉钉为什么微信被封以后然后解封了过了一会又被封了罗伦佐娜手上鸡皮肤怎么办,维洛娜毛周角化修复液丑福晋谁有好看的言情小说介绍下www.119mm.comwww.993mm+com精品集!ip在线查询我要用eclipse做个ip在线查询功能,用QQwry数据库,可是我不知道怎么把这个数据库放到我的程序里面去,高手帮忙指点下,小弟在这谢谢了