算法千核处理器
千核处理器 时间:2021-03-27 阅读:()
收稿日期:20150720;修回日期:20150905基金项目:上海市自然科学基金资助项目(15ZR1428600);计算机体系结构国家重点实验室开放资助项目(CARCH201206);上海市浦江人才计划资助项目(16PJ1407600)作者简介:裴颂文(1981),男,湖南邵东人,副教授,博士,主要研究方向为千核处理器微系统结构设计、软件自动化测试、云计算与通信网络、嵌入式系统设计(swpei@usst.
edu.
cn);宁静(1988),女,湖北十堰人,硕士,主要研究方向为异构多核处理器微系统结构设计;张俊格(1989),女,河南平顶山人,硕士,主要研究方向为异构多核处理器微系统结构设计.
CPUGPU异构多核系统的动态任务调度算法裴颂文1,2,宁静1,张俊格1(1.
上海理工大学光电信息与计算机工程学院,上海200093;2.
中国科学院计算机体系结构国家重点实验室,北京100190)摘要:CPUGPU异构多核系统对计算密集型的应用加速效果显著而得到广泛应用,但易出现负载均衡问题.
针对此问题,提出了一种CPUGPU异构多核系统的动态任务调度算法.
该算法充分利用CPU的线程资源和GPU的计算资源,准确测量CPU和GPU的计算能力,从而动态调整分配到CPU和GPU上的数据块大小,减小负载的总执行时间,提高系统加速比.
实验结果表明,该算法使得系统加速比提高34%~103%.
关键词:动态调度;负载均衡;自适应分配;异构计算中图分类号:TP316;TP301.
6文献标志码:A文章编号:10013695(2016)11331505doi:10.
3969/j.
issn.
10013695.
2016.
11.
026DynamictaskschedulingalgorithmbasedonCPUGPUheterogeneousmulticoresystemPeiSongwen1,2,NingJing1,ZhangJunge1(1.
SchoolofOpticalElectrical&ComputerEngineering,UniversityofShanghaiforScience&Technology,Shanghai200093,China;2.
StateKeyLaboratoryofComputerArchitecture,ChineseAcademyofSciences,Beijing100190,China)Abstract:CPUGPUheterogeneousmulticoresystemhasbeenwidelyappliedbecauseofitsaccelerationeffectsforcomputeintensiveapplications.
However,theproblemofworkloadimbalanceisserious.
Therefore,thispaperproposedadynamictaskschedulingalgorithm(DTSA)basedonCPUGPUheterogeneousmulticoresystem.
Inordertoguaranteethatallcoresweredoingusefulwork,itmadefulluseofCPUandGPU.
Furthermore,itcouldaccuratelymeasurethecomputationalpowerofGPUsandCPUsrespectively,dynamicallyadjustedthesizeofdatablockstobeexecutedonCPUsandGPUs,andfinallyreducedthetotalexecutingtimeofworkloadsandincreasedthesystemspeedup.
Accordingtotheresultsofexperimentsbyusingthisalgorithm,thesystemspeedupincreasesby34%~103%.
Keywords:dynamicscheduling;workloadbalance;adaptiveallocation;heterogeneouscomputing!
引言图形处理单元(graphicprocessingunit,GPU)具有高效计算能力、高速内存带宽和并行编程模型而被广泛应用于计算密集型程序.
无论在个人电脑,还是超级计算机或者GPU集群[1,2],GPU都作为主要的加速部件用于负责计算任务.
排名世界500强的天河一号超级计算机[3],SGIAltixUV[4]和CrayXK6[5]超级计算机都使用了大量的GPU.
利用GPU进行加速计算逐渐成为主流,越来越多的高性能计算机由CPU与GPU构成异构计算系统.
CPU和GPU具有不同的硬件特点.
CPU采用乱序执行机制,通过预取策略和高速缓存层级降低内存访问延迟,有较大的缓存容量及大量的数字和逻辑运算单元.
因此,CPU擅长处理具有复杂计算步骤和复杂数据依赖的计算任务,如分布式计算、数据压缩、人工智能、物理模拟等.
而GPU采用顺序执行机制,具有大量的执行单元,依靠大量的并行多线程掩盖其内存访问延迟,并且GPU的执行能力具有应用依赖性,即使同一应用的不同迭代仍会影响GPU执行效率.
GPU主要应用领域有图像分析、海量数据处理、视频处理等.
这些不同导致了CPU与GPU执行性能的显著差异,某些应用可能在CPU(GPU)上执行得快但在GPU(CPU)上执行得慢.
为充分发挥CPUGPU异构系统中CPU和GPU的独特计算能力,提高硬件资源执行效率及优化资源配置显得尤为重要.
因此,采用动态任务调度算法按照一定比例合理地将计算任务分配到相应的硬件计算单元以期达到上述目的.
从广义上讲,计算任务的负载均衡算法[6]主要分为静态任务调度和动态任务调度两大类.
静态调度是在执行负载之前根据预计的运行时间设置好任务的分配比例.
预计时间是基于处理器的执行性能、编译时间参数和离线训练时间的理论分析得到的.
该方法无须任务同步,通信开销小,但是不便于灵活应用到各种计算任务,负载不均问题可能仍然严重.
Qilin[7]是一种典型的静态任务调度算法,通过训练阶段测量的执行时间和数据传输时间,建立CPU和GPU的性能评估模型.
赵国亮等人[8]提出了一种混合静态调度算法,该算法分第33卷第11期2016年11月计算机应用研究ApplicationResearchofComputersVol.
33No.
11Nov.
2016为启发式算法和遗传算法两个阶段.
第一阶段采用所提出的考虑后继节点的列表启发式调度算法产生一个近似最优的调度结果;第二阶段针对调度问题改进的遗传算法,对第一阶段产生的调度结果进行优化.
Axel[9]建立了通信模型和计算模型,任务执行时间和传输时间采用离线计算的方法.
预计算的执行时间和传输时间的准确性严重依赖于训练数据是否能够反映真实的执行时间.
预计算的时间会随着计算任务和硬件环境的变化而变化,使得该算法缺乏应用的灵活性和适应性.
动态调度是在任务执行的过程中根据CPU和GPU的性能动态地确定负载的分配比例.
动态调度的开销虽然比静态调度大,但是预测更精准.
早期Rudolph等人[10]提出了改进式自调度算法(GSS),该算法中某一处理器完成给定任务后,该处理器分得的任务大小为Bc=R/∑V,R为剩余任务量,∑V表示处理器的处理速度和,各处理器不是在同一时间完成任务.
Kaleem等人[11]提出了一种基于统一内存地址空间访问的动态调度算法(AHS),该算法实时分析负载特点及CPU和GPU的执行速率,无须离线分析和训练数据.
Belviranli等人[6]提出了一种动态的自适应调度算法(DSS),在任务处理的初始阶段,分配给处理器的任务块较大,随着剩余任务量的减少,分配给CPU和GPU的任务量线性减少.
Cédric[12]提出了一种工作窃取的方法,由于GPU不能主动向CPU发起通信,也就意味着GPU不能向非本地的工作池发起负载请求.
因此采用CPU的一个线程负责卸载任务给GPU,称此线程为该GPU的专用线程.
当GPU专用线程检测到GPU空闲时,则专用线程卸载任务给GPU.
该算法的不足在于数据转移开销大,且产生大量数据冗余.
上述算法均未充分利用CPU和GPU的计算资源.
Lee等人[13]提出了一种单个内核多设备系统,即在执行一个数据并行内核时,透明地协调CPUs与GPUs的合作.
编程人员负责在OpenCL中开发一个数据并行的内核,生成内核执行部分负载且合并部分数据输出,而非按照传统给CPU和GPU的角色定位去分配任务.
Oden等人[14]提出了一种无须专用线程的通信方式绕过CPU,GPU联合动态应用来控制通信,但这样却有损计算性能.
基于上述论述提出一种CPUGPU异构多核系统的动态任务调度算法(dynamictaskschedulingalgorithm,DTSA).
该算法能够精确估计CPU和GPU的计算能力,根据计算能力和剩余迭代量为计算资源动态分配任务,联合GPU专用线程,从而充分利用CPU与GPU的硬件资源.
异构系统动态任务调度算法DTSA的目标是减小系统负载不均,提高硬件资源并行计算能力,使得所有计算资源尽可能在同一时间完成执行.
为此采用联合专用线程调度策略,实现GPU与专用线程并行处理.
采用图1所示算法为CPU和GPU合理分配数据块.
在处理任务过程中,对于相同的迭代数目,处理时间长的计算单元其执行速率高,反之执行速率低.
其中,处理时间包括CPU与GPU之间的数据传输时间.
DTSA分为分析阶段和执行两个阶段.
分析阶段的目的是精确找出每个计算资源的最大执行速率,此阶段处理的负载较少.
a)进行全局负载队列初始化;b)若是第一次执行,则执行的块大小是初始化块大小;c)反之,则进入分析阶段,执行该块并记录执行时间,计算执行速率,比较前后两次的执行速率;d)若两次的速率之差小于最小速率改变值,则认为该速率已经趋于稳定;e)反之,说明此计算资源的执行速率还有上升空间,下次该计算资源执行的块大小翻倍;f)直到所有的执行速率都达到稳定值或者迭代总量的固定比例已被执行,此时进入执行阶段;g)当有足够的迭代使得所有的计算资源保持忙碌时,根据分析阶段的执行速率的权重来分配任务块;h)当迭代不足时,采用改进式自调度算法.
联合专用线程调度联合专用线程调度是指GPU获得一个新块时,其专用线程也获得一个块,并与GPU并行执行.
专用线程定期检测GPU是否完成执行.
在计算机统一设备架构(computeunifieddevicearchitecture,CUDA)同步控制机制中,有spin、yield、blocking三个标志.
其中,spin表示专用线程一直忙碌等待,以减少GPU的请求延迟;yield表示专用线程以轮询方式周期性检测GPU的执行状态;blocking表示专用线程一直处于阻塞状态直到GPU完成执行.
联合专用线程调度策略调用yield函数.
联合专用线程调度算法如图2所示.
底部绿色和银色部分表示已分配的迭代,白色B表示剩余迭代(见电子版),左边是TBB产生的口令,即GC_口令、C_口令.
GC_口令表示给GPU和其专用线程同时分配数据块,C_口令表示只给专用线程分配块.
GPU专用线程的任务来源有两个:a)优先从剩余工作队列取得任务,如图中的椭圆部分;b)若剩余工作队列为空,则从剩余迭代中提取任务.
此算法的步骤如下:a)过滤器1判断是否存在空闲GPU流.
若存在,则过滤器1产生GC_口令,为GPU和其专用线程各分配一个块;否则产生C_口令,为GPU专用线程分配一个块.
b)过滤器2接收过滤器1的指令,并根据收到的指令类型(是GC_口令还是C_口令),执行对应计算资源中的任务.
分配给GPU专用线程的块被分成更小的子块装入临时队列.
GPU专有流的执行状态.
若GPU流任务完成,则压缩剩余子块放回剩余工作队列.
c)当GPU流任务完成或临时队列为空,上述轮询过程结束.
系统依据记录CPU和GPU的执行时间计算执行速率.
执行时间包括数据传输(数据从CPU传递到GPU和从GPU传·6133·计算机应用研究第33卷递到CPU)时间和处理数据时间.
调度模型分析用户自定义GPU分得的块大小,调用线程构建模块(threadingbuildingblocks,TBB)的Parallel_for并行算法函数将自定义参数传入系统.
TBB是Intel开发的支持可扩展并行编程的C++模板库,不需要特殊语言或编译器,TBB的编程模式使用模板作为通常的并行迭代模型.
这些丰富的C++模板类使得编程人员无须很专业地去学习同步、负载均衡、缓存优化等问题,就能够轻松地实现自动调度的并行程序.
编程人员可以创建自己的并行组件,以构建大型的并行程序.
TBB的八个迭代模型分别是parallel_for、paralle_reduce、parallel_scan、parallel_for_each、parallel_sort、paralle_pipeline、parallel_invoke、parallel_deterministic_reduce[15].
本文执行的应用包含一个或多个并行数据的Parallel_for循环,Parallel_for样本函数有range、body、partitioner三个参数.
Range划定block的范围,即迭代的起始位置;body指定对block应用的操作,body可以看成是一个操作子functor,它的operator()会以block_range为参数进行调用;partitioner指划分器,即如何划分block.
块大小由GrainSizeGPU说明,GrainSizeGPU由一个元组表示〈GS1,GS2〉,GSi表示id为idi的GPU分得的块为GSi.
假设某个GPUi分得的块大小是Bi,其执行速率是Vi,执行GSi所用的时间为Ti,Ni表示GPUi将要执行的块的数量.
同理,CPUs对应的变量分别是Bc、Vc、Tc、Nc,CPU核的数目为nCores.
T表示在异构系统中利用Parallel_for函数执行任务的优化时间.
负载不均是由于计算资源i的执行时间与T之间的差距造成的,即Ni*Ti-T≠0或Nc*Tc-T≠0.
降低系统负载不均可由下式表示:minimize(∑iNi*Ti-T)+(∑nCoresNc*Tc-T)iTi>0,Tc>0(1)假设理想情况下,系统完全负载均衡,即有Ni*Ti-T(Nc*Tc=T)(2)因此,有T1=T2=…=Ti=Tc1≤i≤N(3)由Nc*Tc=T和Ni*Ti=T代入式(3)得B1/V1=B2/V2=…=Bi/Vi=Bc/Vc(4)从式(4)可以看出,在系统负载均衡时,计算资源的块大小分配和执行速率成正比.
分析阶段首次分配任务时,初始化的块大小供分析阶段使用.
分析阶段第一步测量单位时间内执行迭代的数目,即应用程序迭代计算的前一步执行速率.
若前后执行速率之差小于最小变化速率(实验中设为0.
05),则视当前执行速率达到稳态;否则,按指数级增加块大小.
重复上述测量过程直到当所有计算单元的执行速率均达到稳态或者总任务的20%(固定比例)已完成,则进入执行阶段.
为获取准确的执行速率,减小分析时间,计算单元首先分得小块迭代,依据性能反馈,逐渐增加块大小.
该策略可获得更精确的执行速率信息.
对于GPU而言,理想块大小是其内部线程总数的整数倍.
执行阶段执行初期,迭代数量充足,所有计算单元均处于忙碌状态,此时依据各计算单元执行速率的权重分配任务.
执行速率越快的计算单元分得的迭代数量越多,反之亦然.
执行后期,迭代数量下降,计算单元部分空闲,此时采用改进式自调度算法.
对GPU来说,当剩余迭代量充足时,GPUi分得的块为Bi=GSi.
当剩余迭代量不足时,若Bi在GPUi上执行的时间小于剩余的迭代在除了GPUi以外的所有计算资源执行的时间,说明其他的计算资源要等待GPUi执行完成,这会产生很大的开销.
此时,不适合给GPUi分配任务,即Bi=0;同时,释放掉GPU专有线程.
对于CPUs来讲,当剩余迭代足够多时,每个CPU分得的块大小是Bc=maxiBi/nCores.
当剩余迭代不足时,Bc=R/(∑iVi+nCores*Vc).
最后迭代越来越少的时候,为取得最小的迭代,设立一个阈值R,当Bc实验与讨论实验环境实验评估是在64位Linux操作系统上进行的,测试程序在TBB4.
3和CUDA5.
5[16]上编译执行.
系统有八个2.
2GHz的处理器Inteli552000,四个GPU独立显卡GeForceGTX750,显存的大小和位宽分别为2GB、128bit.
实验采用部分基准测试集Rodinia测试系统性能加速比,其中加速比可用Sp=Tp/T1表示.
T1表示单个应用在单核CPU上的执行时间,Tp表示单个应用在有P个处理器并行系统中的执行时间.
表1是选择的测试程序的信息及其在单核CPU基本执行时间.
表1Rodinia基准上相关测试程序测试程序缩写迭代次数单核CPU的基本执行时间/sbreanthfirstsearchbfs65536次迭代134.
8ludecompositionlud10次迭代,192*8192的矩阵319.
5nbodynb50次迭代165.
2hotspoths600次迭代231.
4smeansks988040个数据点217.
3srad_v2sv2048*2048的矩阵246.
3streamclustersc65536点512维465.
1实验数据及结果分析实验比较了系统配置分别在(八个CPU核,一个GPU核),(八个CPU核,两个GPU核),(八个CPU核,四个GPU·7133·第11期裴颂文,等:CPUGPU异构多核系统的动态任务调度算法核)时,不同调度算法DTSA、Qilin、Axel、AHS、DSS、GSS的加速比,实验结果如图3~5所示.
由图3~5可知,动态调度算法的加速比较静态调度算法高.
以图5为例,分析有:DTSA的加速比比Qilin高47%~95%,比Axel高47%~75%;AHS算法的加速比比Qilin高27%~53%,比Axel高7%~44%;DSS算法的加速比比Qilin高49%~64%,比Axel高33%~49%;GSS的加速比比Qilin高3%~22%,比Axel高2%~13%.
动态调度算法中,DTSA的加速比分别比AHS、DSS、GSS算法高22%~57%、17%~21%、13%~62%.
在同一种配置中,DTSA的加速比最高,加速比提高34%~103%,AHS和DSS次之,然后是GSS,最差的是Qilin和Axel.
Qilin和Axel两种静态调度算法的加速比低是由于对处理器性能预估均不够精确.
Qilin线性预计的执行速率不能反映GPU的实际执行速率,Qilin基于线性时间函数增加块大小.
若起始块太小,易造成处理器资源浪费,负载不均衡.
Axel算法静态估计精确度低,易导致CPU多数时间处于空闲状态,且每个基准的通信模型和计算模型需手动调整,实现困难.
因而上述两种算法的估计结果均不能作为GPU实际性能的参考.
AHS算法分析阶段要么以执行速率的收敛情况(前后两次执行速率之差小于0.
05),要么以分析总迭代数量的固定比例作为结束标准,这样导致分析阶段迭代过多,负载处理延时.
DSS调度算法执行阶段的块大小是时间反比函数.
当剩余迭代不足时,易出现计算单元间的等待延时,实时性能不佳.
GSS没有分析阶段,未能找到CPU和GPU的最大执行速率,并且所有的处理器未在同一时间完成任务,导致某些计算单元在执行任务而其他的计算单元均已完成任务,故存在等待延迟,时间开销较大.
而DTSA则不给这个GPU分配任务,并释放掉其专用线程.
Axel、AHS、DSS、GSS算法中的GPU专用线程在GPU执行负载时均处于忙碌等待状态.
而DTSA联合专用线程调度策略,提高了CPU的线程利用率.
尽管动态算法DSS、GSS和AHS能在一定程度上平衡工作负载,但未充分利用CPU线程和GPU计算资源.
这表明即使所有的处理器都保持忙碌也非理想的负载平衡方法,应从整体角度考虑系统性能.
由图3~5还可知,在七个测试程序中,DTSA在bfs程序上的加速比分别为34%、48%、77%,比同等水平的其他应用加速比低.
这是因为bfs测试程序的计算量高且访存频率也高,而其他测试程序的访存率偏低,更适合GPU计算.
随着GPU核数目的增加,几种算法的加速比均逐渐增大.
其中动态调度算法DTSA、AHS和DSS在(8,1)、(8,2)、(8,4)时的平均加速比用表2表示.
运行单个应用的总时间用T表示,分析阶段时间用Ta表示,则Ta/T表示分析时间占总时间的比例,其中,实验中选择的应用是bfs测试程序,分别在三种不同的配置下执行,结果如表3所示.
表2DTSA、AHS和DSS算法在三种不同配置下的平均加速比/%算法(8,1)加速比(8,2)加速比(8,4)加速比DTSA406195.
5AHS23.
637.
959.
6DSS28.
44476GSS15.
120.
936.
4由表2可知,随着GPU数目的增加,DTSA的加速比由40%提高到95.
5%,AHS算法的加速比由23.
6%提高到59.
6%,DSS算法的加速比由28.
4%提高到76%,GSS算法的加速比由15.
1%提高到36.
4%.
GPU数目增加,系统的计算性能提高,使得所有算法的加速比都有一定程度的提高.
由于DTSA采用联合专用线程调度策略,充分利用CPU线程资源,且在执行阶段末期,采用改进式算法减小处理器等待延迟,故其加速比提升得最高.
表3算法的时间比例/%应用(8,1)(8,2)(8,4)Qilin54.
348.
643.
0Axel57.
449.
941.
8DTSA20.
515.
513.
4DSS40.
324.
727.
6AHS45.
831.
236.
2由表3可知,在同一种系统配置下,DTSA的时间比例在所有算法中是最低的,比DSS、AHS、Axel、Qilin分别低6.
2%~24.
8%、15.
7%~25.
2%、28.
4%~36.
9%、23.
9%~43.
1%.
GSS没有分析阶段,故不存在该项数据.
由于静态算法Qilin和Axel是在运行应用之前预估运行时间,不能反映CPU和GPU的真实执行速率的比例最低,不具灵活性,导致负载不均问题严重,故分析时间占总执行时间大.
动态算法有一定的灵活性,其时间比例比静态算法低.
在三种动态算法中,AHS的比例最高,这是因为分析阶段的收敛条件造成分析迭代较多.
而DTSA分析阶段的收敛速度较快,当计算单元的速率未达稳定值且未完成20%任务时,下次分配的迭代加倍.
同时,GPU的专用线程也参与计算.
总之,通过比较加速比和分析时间占总执行时间的比例,说明本文提出的DTSA相对于其他几种算法的优越性.
结束语随着异构多核系统尤其是CPUGPU异构多核系统的发展,其采用的任务分配与调度算法成为目前研究的热点问题.
动态负载均衡对于实现异构系统的潜能起着至关重要的作用.
本文在独立式显存的多核异构系统上考虑系统特点,提出联合专用线程调度策略,结合计算权重算法和改进式自调度算法,降低单个应用总的执行时间,提高系统加速比,并实验证明了该方法的有效性.
基于统一内存地址空间访问的异构计算是未来异构结构的一个重要特征[17],如IntelIvvBridge、Haswell、AMDTrinity和Richland处理器.
此时系统有更低的数据传输开销、更低的通信开销、更小的能耗预算和更高的计算潜能.
·8133·计算机应用研究第33卷而这些变化将会如何影响CPU和GPU的执行速率以及负载均衡问题,是未来工作的研究重点.
参考文献:[1]KindratenkoVV,EnosJJ,ShiGC,etal.
GPUclusterforhighperformancecomputing[C]//ProcofIEEEInternationalConferenceonClusterComputerandWorkshops.
2009:638645.
[2]ShowermanM,EnosJ,SteffenC,etal.
Ecog:apowerefficientGPUclusterarchitectureforscientificcomputing[J].
ComputinginScienceEngineering,2011,13(2):8387.
[3]TianHe1Asupercomputer[EB/OL].
(20091203)[20150506].
http://www.
nscctj.
gov.
cn/resources/resources_2.
asp.
[4]SGI:GPUcomputesolutions[EB/OL].
(20130809)[20150506].
http://www.
sgi.
com/solutions/.
[5]CrayXK6:redefiningsupercomputing[EB/OL].
(20110621)[20150506].
http://www.
cray.
com/Assets/PDF/products/xk/CrayXK6Brochure.
pdf.
[6]BelviranliME,BhuyanLN,GuptaR,etal.
Adynamicselfschedulingschemeforheterogeneousmultiprocessorarchitectures[J].
ACMTransonArchitectureandCodeOptimization,2013,9(4):301321.
[7]LukCK,HongSunpyo,KimH.
Qilin:exploitingparallelismonheterogeneousmultiprocessorswithadaptivemapping[C]//Procofthe42ndAnnualIEEE/ACMInternationalSymposiumonMicroarchitecture.
2009:4555.
[8]赵国亮,李云飞,王川.
异构多核系统任务调度算法研究[J].
计算机工程与设计,2014,35(9):30993106.
[9]TsoiKH,LukW.
Axel:aheterogeneousclusterwithFPGAsandGPUs[C]//Procofthe18thACMInternationalSymposiumonFieldProgrammableGateArrays.
NewYork:ACMPress,2010:115124.
[10]RudolphDC,PolychronopoulosCD.
Anefficientmessagepassingschedulerbasedonguidedselfscheduling[C]//Procofthe3rdInternationalConferenceonSupercomputing.
NewYork:ACMPress,1989:5669.
[11]KaleemR,BarikR,ShpeismanT,etal.
AdaptiveheterogeneousschedulingforintegratedGPUs[J].
TheJournalSupercomputer,2014,70(2):756771.
[12]CédricA,SamuelT,RaymandN,etal.
StarPU:aunifiedplatformfortaskschedulingonheterogeneousmulticorearchitectures[C]//Procofthe15thInternationalEuroParConferenceonParallelComputing.
[S.
l.
]:Wiley,2009:863874.
[13]LeeJ,SamadiM,ParkY,etal.
TransparentCPUGPUcollaborationfordataparallelkernelsonheterogeneaussystems[C]//Procofthe22ndInternationalConferenceonParallelArchitecturesandCompilationTechniques.
[S.
l.
]:IEEEPress,2013.
[14]OdenL,KlenkB,NingH.
EnergyefficientstencilcomputationsondistributedGPUsusingdynamicparallelismandGPUcontrolledcommunication[C]//ProcofEnergyEfficientSupercomputingWorkshop.
2014:3140.
[15]Threadingbuildingblocksdocumentation[EB/OL].
(20150409)[20150506].
https://www.
threadingbuildingblocks.
org/.
[16]RossbachCJ,YuYuan,CurreyJ,etal.
Dandelion:acompilerandruntimeforheterogeneoussystems[C]//Procofthe24thACMSymposiumonOperatingSystemPrinciples.
NewYork:ACMPress,2013:4968.
[17]KecklerS,DallyW,KhailanyB,etal.
GPUsandthefutureofparallelcomputing[J].
IEEEMicro,2011,31(5):717.
(上接第3292页)向于AR&BR策略,最终联盟的博弈均衡为ABR策略.
但如果外部环境变化导致零售商博弈力量强于制造商,则制造商将妥协选择AR&BR策略.
本文尚存在一些不足,无限周期的研究将是今后的研究方向.
参考文献:[1]ShapiroE.
Movies:blockbusterseeksanewdealwithHollywood[J].
WallStreetJournal,1999,3(25):12.
[2]孔晓红.
卡特彼勒为产品制造来生[J].
中国循环经济,2014,9:5054.
[3]FergusonME,ToktayLB.
Theeffectofcompetitiononrecoverystrategies[J].
ProductionandOperationsManagement,2006,15(3):351.
[4]易余胤.
基于再制造的闭环供应链博弈模型[J].
系统工程理论与实践,2009,29(8):2835.
[5]熊中楷,王凯,熊榆.
经销商从事再制造的闭环供应链模式研究[J].
管理科学学报,2011,14(11):19.
[6]McWilliamsB.
Moneybackguarantees:helpingthelowqualityretailer[J].
ManagementScience,2012,58(8):15211524.
[7]ShulmanJD,CoughlanAT,SavaskanRC.
Managingconsumerreturnsinacompetitiveenvironment[J].
ManagementScience,2011,57(2):347362.
[8]GuQiaolun,GaoTiegang.
Managementoftwocompetitiveclosedloopsupplychains[J].
InternationalJournalofSustainableEngineering,2012,5(4):325337.
[9]WuChenghan.
Priceandservicecompetitionbetweennewandremanufacturedproductsinatwoechelonsupplychain[J].
InternationalJournalofProductionEconomics,2012,140(1):496507.
[10]ChenJing,GrewalR.
Competinginasupplychainviafullrefundandnorefundcustomerreturnspolicies[J].
InternationalJournalofProductionEconomics,2013,146(1):246258.
[11]QiangQiang,KeKe,AndersonT,etal.
Theclosedloopsupplychainnetworkwithcompetition,distributionchannelinvestment,anduncertainties[J].
Omega,2013,41(2):186194.
[12]高阳,林恺.
考虑异质需求的再制造系统最优产量与定价研究[J].
计算机应用研究,2015,32(5):13491952.
[13]FallahH,EskandariH,PishvaeeMS.
Competitiveclosedloopsupplychainnetworkdesignunderuncertainty[J].
JournalofManufacturingSystems,2015,37(3):649661.
[14]KumarS,MalegeantP.
Strategicallianceinaclosedloopsupplychain,acaseofmanufacturerandecononprofitorganization[J].
Technovation,2006,26(10):11271135.
[15]LiXiuhui,WangQinan.
Coordinationmechanismsofsupplychainsystems[J].
EuropeanJournalofOperationalResearch,2007,179(1):116.
[16]晏妮娜,黄小原.
基于第3方逆向物流的闭环供应链模型及应用[J].
管理科学学报,2008,11(4):8393.
[17]JenaSK,SarmahSP.
Pricecompetitionandcooperationinaduopolyclosedloopsupplychain[J].
InternationalJournalofProductionEconomics,2014,156:346360.
[18]高阳,杨新.
基于WTP差异化的再制造闭环供应链利益协调机制[J].
计算机应用研究,2014,31(2):388391.
·9133·第11期裴颂文,等:CPUGPU异构多核系统的动态任务调度算法
edu.
cn);宁静(1988),女,湖北十堰人,硕士,主要研究方向为异构多核处理器微系统结构设计;张俊格(1989),女,河南平顶山人,硕士,主要研究方向为异构多核处理器微系统结构设计.
CPUGPU异构多核系统的动态任务调度算法裴颂文1,2,宁静1,张俊格1(1.
上海理工大学光电信息与计算机工程学院,上海200093;2.
中国科学院计算机体系结构国家重点实验室,北京100190)摘要:CPUGPU异构多核系统对计算密集型的应用加速效果显著而得到广泛应用,但易出现负载均衡问题.
针对此问题,提出了一种CPUGPU异构多核系统的动态任务调度算法.
该算法充分利用CPU的线程资源和GPU的计算资源,准确测量CPU和GPU的计算能力,从而动态调整分配到CPU和GPU上的数据块大小,减小负载的总执行时间,提高系统加速比.
实验结果表明,该算法使得系统加速比提高34%~103%.
关键词:动态调度;负载均衡;自适应分配;异构计算中图分类号:TP316;TP301.
6文献标志码:A文章编号:10013695(2016)11331505doi:10.
3969/j.
issn.
10013695.
2016.
11.
026DynamictaskschedulingalgorithmbasedonCPUGPUheterogeneousmulticoresystemPeiSongwen1,2,NingJing1,ZhangJunge1(1.
SchoolofOpticalElectrical&ComputerEngineering,UniversityofShanghaiforScience&Technology,Shanghai200093,China;2.
StateKeyLaboratoryofComputerArchitecture,ChineseAcademyofSciences,Beijing100190,China)Abstract:CPUGPUheterogeneousmulticoresystemhasbeenwidelyappliedbecauseofitsaccelerationeffectsforcomputeintensiveapplications.
However,theproblemofworkloadimbalanceisserious.
Therefore,thispaperproposedadynamictaskschedulingalgorithm(DTSA)basedonCPUGPUheterogeneousmulticoresystem.
Inordertoguaranteethatallcoresweredoingusefulwork,itmadefulluseofCPUandGPU.
Furthermore,itcouldaccuratelymeasurethecomputationalpowerofGPUsandCPUsrespectively,dynamicallyadjustedthesizeofdatablockstobeexecutedonCPUsandGPUs,andfinallyreducedthetotalexecutingtimeofworkloadsandincreasedthesystemspeedup.
Accordingtotheresultsofexperimentsbyusingthisalgorithm,thesystemspeedupincreasesby34%~103%.
Keywords:dynamicscheduling;workloadbalance;adaptiveallocation;heterogeneouscomputing!
引言图形处理单元(graphicprocessingunit,GPU)具有高效计算能力、高速内存带宽和并行编程模型而被广泛应用于计算密集型程序.
无论在个人电脑,还是超级计算机或者GPU集群[1,2],GPU都作为主要的加速部件用于负责计算任务.
排名世界500强的天河一号超级计算机[3],SGIAltixUV[4]和CrayXK6[5]超级计算机都使用了大量的GPU.
利用GPU进行加速计算逐渐成为主流,越来越多的高性能计算机由CPU与GPU构成异构计算系统.
CPU和GPU具有不同的硬件特点.
CPU采用乱序执行机制,通过预取策略和高速缓存层级降低内存访问延迟,有较大的缓存容量及大量的数字和逻辑运算单元.
因此,CPU擅长处理具有复杂计算步骤和复杂数据依赖的计算任务,如分布式计算、数据压缩、人工智能、物理模拟等.
而GPU采用顺序执行机制,具有大量的执行单元,依靠大量的并行多线程掩盖其内存访问延迟,并且GPU的执行能力具有应用依赖性,即使同一应用的不同迭代仍会影响GPU执行效率.
GPU主要应用领域有图像分析、海量数据处理、视频处理等.
这些不同导致了CPU与GPU执行性能的显著差异,某些应用可能在CPU(GPU)上执行得快但在GPU(CPU)上执行得慢.
为充分发挥CPUGPU异构系统中CPU和GPU的独特计算能力,提高硬件资源执行效率及优化资源配置显得尤为重要.
因此,采用动态任务调度算法按照一定比例合理地将计算任务分配到相应的硬件计算单元以期达到上述目的.
从广义上讲,计算任务的负载均衡算法[6]主要分为静态任务调度和动态任务调度两大类.
静态调度是在执行负载之前根据预计的运行时间设置好任务的分配比例.
预计时间是基于处理器的执行性能、编译时间参数和离线训练时间的理论分析得到的.
该方法无须任务同步,通信开销小,但是不便于灵活应用到各种计算任务,负载不均问题可能仍然严重.
Qilin[7]是一种典型的静态任务调度算法,通过训练阶段测量的执行时间和数据传输时间,建立CPU和GPU的性能评估模型.
赵国亮等人[8]提出了一种混合静态调度算法,该算法分第33卷第11期2016年11月计算机应用研究ApplicationResearchofComputersVol.
33No.
11Nov.
2016为启发式算法和遗传算法两个阶段.
第一阶段采用所提出的考虑后继节点的列表启发式调度算法产生一个近似最优的调度结果;第二阶段针对调度问题改进的遗传算法,对第一阶段产生的调度结果进行优化.
Axel[9]建立了通信模型和计算模型,任务执行时间和传输时间采用离线计算的方法.
预计算的执行时间和传输时间的准确性严重依赖于训练数据是否能够反映真实的执行时间.
预计算的时间会随着计算任务和硬件环境的变化而变化,使得该算法缺乏应用的灵活性和适应性.
动态调度是在任务执行的过程中根据CPU和GPU的性能动态地确定负载的分配比例.
动态调度的开销虽然比静态调度大,但是预测更精准.
早期Rudolph等人[10]提出了改进式自调度算法(GSS),该算法中某一处理器完成给定任务后,该处理器分得的任务大小为Bc=R/∑V,R为剩余任务量,∑V表示处理器的处理速度和,各处理器不是在同一时间完成任务.
Kaleem等人[11]提出了一种基于统一内存地址空间访问的动态调度算法(AHS),该算法实时分析负载特点及CPU和GPU的执行速率,无须离线分析和训练数据.
Belviranli等人[6]提出了一种动态的自适应调度算法(DSS),在任务处理的初始阶段,分配给处理器的任务块较大,随着剩余任务量的减少,分配给CPU和GPU的任务量线性减少.
Cédric[12]提出了一种工作窃取的方法,由于GPU不能主动向CPU发起通信,也就意味着GPU不能向非本地的工作池发起负载请求.
因此采用CPU的一个线程负责卸载任务给GPU,称此线程为该GPU的专用线程.
当GPU专用线程检测到GPU空闲时,则专用线程卸载任务给GPU.
该算法的不足在于数据转移开销大,且产生大量数据冗余.
上述算法均未充分利用CPU和GPU的计算资源.
Lee等人[13]提出了一种单个内核多设备系统,即在执行一个数据并行内核时,透明地协调CPUs与GPUs的合作.
编程人员负责在OpenCL中开发一个数据并行的内核,生成内核执行部分负载且合并部分数据输出,而非按照传统给CPU和GPU的角色定位去分配任务.
Oden等人[14]提出了一种无须专用线程的通信方式绕过CPU,GPU联合动态应用来控制通信,但这样却有损计算性能.
基于上述论述提出一种CPUGPU异构多核系统的动态任务调度算法(dynamictaskschedulingalgorithm,DTSA).
该算法能够精确估计CPU和GPU的计算能力,根据计算能力和剩余迭代量为计算资源动态分配任务,联合GPU专用线程,从而充分利用CPU与GPU的硬件资源.
异构系统动态任务调度算法DTSA的目标是减小系统负载不均,提高硬件资源并行计算能力,使得所有计算资源尽可能在同一时间完成执行.
为此采用联合专用线程调度策略,实现GPU与专用线程并行处理.
采用图1所示算法为CPU和GPU合理分配数据块.
在处理任务过程中,对于相同的迭代数目,处理时间长的计算单元其执行速率高,反之执行速率低.
其中,处理时间包括CPU与GPU之间的数据传输时间.
DTSA分为分析阶段和执行两个阶段.
分析阶段的目的是精确找出每个计算资源的最大执行速率,此阶段处理的负载较少.
a)进行全局负载队列初始化;b)若是第一次执行,则执行的块大小是初始化块大小;c)反之,则进入分析阶段,执行该块并记录执行时间,计算执行速率,比较前后两次的执行速率;d)若两次的速率之差小于最小速率改变值,则认为该速率已经趋于稳定;e)反之,说明此计算资源的执行速率还有上升空间,下次该计算资源执行的块大小翻倍;f)直到所有的执行速率都达到稳定值或者迭代总量的固定比例已被执行,此时进入执行阶段;g)当有足够的迭代使得所有的计算资源保持忙碌时,根据分析阶段的执行速率的权重来分配任务块;h)当迭代不足时,采用改进式自调度算法.
联合专用线程调度联合专用线程调度是指GPU获得一个新块时,其专用线程也获得一个块,并与GPU并行执行.
专用线程定期检测GPU是否完成执行.
在计算机统一设备架构(computeunifieddevicearchitecture,CUDA)同步控制机制中,有spin、yield、blocking三个标志.
其中,spin表示专用线程一直忙碌等待,以减少GPU的请求延迟;yield表示专用线程以轮询方式周期性检测GPU的执行状态;blocking表示专用线程一直处于阻塞状态直到GPU完成执行.
联合专用线程调度策略调用yield函数.
联合专用线程调度算法如图2所示.
底部绿色和银色部分表示已分配的迭代,白色B表示剩余迭代(见电子版),左边是TBB产生的口令,即GC_口令、C_口令.
GC_口令表示给GPU和其专用线程同时分配数据块,C_口令表示只给专用线程分配块.
GPU专用线程的任务来源有两个:a)优先从剩余工作队列取得任务,如图中的椭圆部分;b)若剩余工作队列为空,则从剩余迭代中提取任务.
此算法的步骤如下:a)过滤器1判断是否存在空闲GPU流.
若存在,则过滤器1产生GC_口令,为GPU和其专用线程各分配一个块;否则产生C_口令,为GPU专用线程分配一个块.
b)过滤器2接收过滤器1的指令,并根据收到的指令类型(是GC_口令还是C_口令),执行对应计算资源中的任务.
分配给GPU专用线程的块被分成更小的子块装入临时队列.
GPU专有流的执行状态.
若GPU流任务完成,则压缩剩余子块放回剩余工作队列.
c)当GPU流任务完成或临时队列为空,上述轮询过程结束.
系统依据记录CPU和GPU的执行时间计算执行速率.
执行时间包括数据传输(数据从CPU传递到GPU和从GPU传·6133·计算机应用研究第33卷递到CPU)时间和处理数据时间.
调度模型分析用户自定义GPU分得的块大小,调用线程构建模块(threadingbuildingblocks,TBB)的Parallel_for并行算法函数将自定义参数传入系统.
TBB是Intel开发的支持可扩展并行编程的C++模板库,不需要特殊语言或编译器,TBB的编程模式使用模板作为通常的并行迭代模型.
这些丰富的C++模板类使得编程人员无须很专业地去学习同步、负载均衡、缓存优化等问题,就能够轻松地实现自动调度的并行程序.
编程人员可以创建自己的并行组件,以构建大型的并行程序.
TBB的八个迭代模型分别是parallel_for、paralle_reduce、parallel_scan、parallel_for_each、parallel_sort、paralle_pipeline、parallel_invoke、parallel_deterministic_reduce[15].
本文执行的应用包含一个或多个并行数据的Parallel_for循环,Parallel_for样本函数有range、body、partitioner三个参数.
Range划定block的范围,即迭代的起始位置;body指定对block应用的操作,body可以看成是一个操作子functor,它的operator()会以block_range为参数进行调用;partitioner指划分器,即如何划分block.
块大小由GrainSizeGPU说明,GrainSizeGPU由一个元组表示〈GS1,GS2〉,GSi表示id为idi的GPU分得的块为GSi.
假设某个GPUi分得的块大小是Bi,其执行速率是Vi,执行GSi所用的时间为Ti,Ni表示GPUi将要执行的块的数量.
同理,CPUs对应的变量分别是Bc、Vc、Tc、Nc,CPU核的数目为nCores.
T表示在异构系统中利用Parallel_for函数执行任务的优化时间.
负载不均是由于计算资源i的执行时间与T之间的差距造成的,即Ni*Ti-T≠0或Nc*Tc-T≠0.
降低系统负载不均可由下式表示:minimize(∑iNi*Ti-T)+(∑nCoresNc*Tc-T)iTi>0,Tc>0(1)假设理想情况下,系统完全负载均衡,即有Ni*Ti-T(Nc*Tc=T)(2)因此,有T1=T2=…=Ti=Tc1≤i≤N(3)由Nc*Tc=T和Ni*Ti=T代入式(3)得B1/V1=B2/V2=…=Bi/Vi=Bc/Vc(4)从式(4)可以看出,在系统负载均衡时,计算资源的块大小分配和执行速率成正比.
分析阶段首次分配任务时,初始化的块大小供分析阶段使用.
分析阶段第一步测量单位时间内执行迭代的数目,即应用程序迭代计算的前一步执行速率.
若前后执行速率之差小于最小变化速率(实验中设为0.
05),则视当前执行速率达到稳态;否则,按指数级增加块大小.
重复上述测量过程直到当所有计算单元的执行速率均达到稳态或者总任务的20%(固定比例)已完成,则进入执行阶段.
为获取准确的执行速率,减小分析时间,计算单元首先分得小块迭代,依据性能反馈,逐渐增加块大小.
该策略可获得更精确的执行速率信息.
对于GPU而言,理想块大小是其内部线程总数的整数倍.
执行阶段执行初期,迭代数量充足,所有计算单元均处于忙碌状态,此时依据各计算单元执行速率的权重分配任务.
执行速率越快的计算单元分得的迭代数量越多,反之亦然.
执行后期,迭代数量下降,计算单元部分空闲,此时采用改进式自调度算法.
对GPU来说,当剩余迭代量充足时,GPUi分得的块为Bi=GSi.
当剩余迭代量不足时,若Bi在GPUi上执行的时间小于剩余的迭代在除了GPUi以外的所有计算资源执行的时间,说明其他的计算资源要等待GPUi执行完成,这会产生很大的开销.
此时,不适合给GPUi分配任务,即Bi=0;同时,释放掉GPU专有线程.
对于CPUs来讲,当剩余迭代足够多时,每个CPU分得的块大小是Bc=maxiBi/nCores.
当剩余迭代不足时,Bc=R/(∑iVi+nCores*Vc).
最后迭代越来越少的时候,为取得最小的迭代,设立一个阈值R,当Bc
3和CUDA5.
5[16]上编译执行.
系统有八个2.
2GHz的处理器Inteli552000,四个GPU独立显卡GeForceGTX750,显存的大小和位宽分别为2GB、128bit.
实验采用部分基准测试集Rodinia测试系统性能加速比,其中加速比可用Sp=Tp/T1表示.
T1表示单个应用在单核CPU上的执行时间,Tp表示单个应用在有P个处理器并行系统中的执行时间.
表1是选择的测试程序的信息及其在单核CPU基本执行时间.
表1Rodinia基准上相关测试程序测试程序缩写迭代次数单核CPU的基本执行时间/sbreanthfirstsearchbfs65536次迭代134.
8ludecompositionlud10次迭代,192*8192的矩阵319.
5nbodynb50次迭代165.
2hotspoths600次迭代231.
4smeansks988040个数据点217.
3srad_v2sv2048*2048的矩阵246.
3streamclustersc65536点512维465.
1实验数据及结果分析实验比较了系统配置分别在(八个CPU核,一个GPU核),(八个CPU核,两个GPU核),(八个CPU核,四个GPU·7133·第11期裴颂文,等:CPUGPU异构多核系统的动态任务调度算法核)时,不同调度算法DTSA、Qilin、Axel、AHS、DSS、GSS的加速比,实验结果如图3~5所示.
由图3~5可知,动态调度算法的加速比较静态调度算法高.
以图5为例,分析有:DTSA的加速比比Qilin高47%~95%,比Axel高47%~75%;AHS算法的加速比比Qilin高27%~53%,比Axel高7%~44%;DSS算法的加速比比Qilin高49%~64%,比Axel高33%~49%;GSS的加速比比Qilin高3%~22%,比Axel高2%~13%.
动态调度算法中,DTSA的加速比分别比AHS、DSS、GSS算法高22%~57%、17%~21%、13%~62%.
在同一种配置中,DTSA的加速比最高,加速比提高34%~103%,AHS和DSS次之,然后是GSS,最差的是Qilin和Axel.
Qilin和Axel两种静态调度算法的加速比低是由于对处理器性能预估均不够精确.
Qilin线性预计的执行速率不能反映GPU的实际执行速率,Qilin基于线性时间函数增加块大小.
若起始块太小,易造成处理器资源浪费,负载不均衡.
Axel算法静态估计精确度低,易导致CPU多数时间处于空闲状态,且每个基准的通信模型和计算模型需手动调整,实现困难.
因而上述两种算法的估计结果均不能作为GPU实际性能的参考.
AHS算法分析阶段要么以执行速率的收敛情况(前后两次执行速率之差小于0.
05),要么以分析总迭代数量的固定比例作为结束标准,这样导致分析阶段迭代过多,负载处理延时.
DSS调度算法执行阶段的块大小是时间反比函数.
当剩余迭代不足时,易出现计算单元间的等待延时,实时性能不佳.
GSS没有分析阶段,未能找到CPU和GPU的最大执行速率,并且所有的处理器未在同一时间完成任务,导致某些计算单元在执行任务而其他的计算单元均已完成任务,故存在等待延迟,时间开销较大.
而DTSA则不给这个GPU分配任务,并释放掉其专用线程.
Axel、AHS、DSS、GSS算法中的GPU专用线程在GPU执行负载时均处于忙碌等待状态.
而DTSA联合专用线程调度策略,提高了CPU的线程利用率.
尽管动态算法DSS、GSS和AHS能在一定程度上平衡工作负载,但未充分利用CPU线程和GPU计算资源.
这表明即使所有的处理器都保持忙碌也非理想的负载平衡方法,应从整体角度考虑系统性能.
由图3~5还可知,在七个测试程序中,DTSA在bfs程序上的加速比分别为34%、48%、77%,比同等水平的其他应用加速比低.
这是因为bfs测试程序的计算量高且访存频率也高,而其他测试程序的访存率偏低,更适合GPU计算.
随着GPU核数目的增加,几种算法的加速比均逐渐增大.
其中动态调度算法DTSA、AHS和DSS在(8,1)、(8,2)、(8,4)时的平均加速比用表2表示.
运行单个应用的总时间用T表示,分析阶段时间用Ta表示,则Ta/T表示分析时间占总时间的比例,其中,实验中选择的应用是bfs测试程序,分别在三种不同的配置下执行,结果如表3所示.
表2DTSA、AHS和DSS算法在三种不同配置下的平均加速比/%算法(8,1)加速比(8,2)加速比(8,4)加速比DTSA406195.
5AHS23.
637.
959.
6DSS28.
44476GSS15.
120.
936.
4由表2可知,随着GPU数目的增加,DTSA的加速比由40%提高到95.
5%,AHS算法的加速比由23.
6%提高到59.
6%,DSS算法的加速比由28.
4%提高到76%,GSS算法的加速比由15.
1%提高到36.
4%.
GPU数目增加,系统的计算性能提高,使得所有算法的加速比都有一定程度的提高.
由于DTSA采用联合专用线程调度策略,充分利用CPU线程资源,且在执行阶段末期,采用改进式算法减小处理器等待延迟,故其加速比提升得最高.
表3算法的时间比例/%应用(8,1)(8,2)(8,4)Qilin54.
348.
643.
0Axel57.
449.
941.
8DTSA20.
515.
513.
4DSS40.
324.
727.
6AHS45.
831.
236.
2由表3可知,在同一种系统配置下,DTSA的时间比例在所有算法中是最低的,比DSS、AHS、Axel、Qilin分别低6.
2%~24.
8%、15.
7%~25.
2%、28.
4%~36.
9%、23.
9%~43.
1%.
GSS没有分析阶段,故不存在该项数据.
由于静态算法Qilin和Axel是在运行应用之前预估运行时间,不能反映CPU和GPU的真实执行速率的比例最低,不具灵活性,导致负载不均问题严重,故分析时间占总执行时间大.
动态算法有一定的灵活性,其时间比例比静态算法低.
在三种动态算法中,AHS的比例最高,这是因为分析阶段的收敛条件造成分析迭代较多.
而DTSA分析阶段的收敛速度较快,当计算单元的速率未达稳定值且未完成20%任务时,下次分配的迭代加倍.
同时,GPU的专用线程也参与计算.
总之,通过比较加速比和分析时间占总执行时间的比例,说明本文提出的DTSA相对于其他几种算法的优越性.
结束语随着异构多核系统尤其是CPUGPU异构多核系统的发展,其采用的任务分配与调度算法成为目前研究的热点问题.
动态负载均衡对于实现异构系统的潜能起着至关重要的作用.
本文在独立式显存的多核异构系统上考虑系统特点,提出联合专用线程调度策略,结合计算权重算法和改进式自调度算法,降低单个应用总的执行时间,提高系统加速比,并实验证明了该方法的有效性.
基于统一内存地址空间访问的异构计算是未来异构结构的一个重要特征[17],如IntelIvvBridge、Haswell、AMDTrinity和Richland处理器.
此时系统有更低的数据传输开销、更低的通信开销、更小的能耗预算和更高的计算潜能.
·8133·计算机应用研究第33卷而这些变化将会如何影响CPU和GPU的执行速率以及负载均衡问题,是未来工作的研究重点.
参考文献:[1]KindratenkoVV,EnosJJ,ShiGC,etal.
GPUclusterforhighperformancecomputing[C]//ProcofIEEEInternationalConferenceonClusterComputerandWorkshops.
2009:638645.
[2]ShowermanM,EnosJ,SteffenC,etal.
Ecog:apowerefficientGPUclusterarchitectureforscientificcomputing[J].
ComputinginScienceEngineering,2011,13(2):8387.
[3]TianHe1Asupercomputer[EB/OL].
(20091203)[20150506].
http://www.
nscctj.
gov.
cn/resources/resources_2.
asp.
[4]SGI:GPUcomputesolutions[EB/OL].
(20130809)[20150506].
http://www.
sgi.
com/solutions/.
[5]CrayXK6:redefiningsupercomputing[EB/OL].
(20110621)[20150506].
http://www.
cray.
com/Assets/PDF/products/xk/CrayXK6Brochure.
pdf.
[6]BelviranliME,BhuyanLN,GuptaR,etal.
Adynamicselfschedulingschemeforheterogeneousmultiprocessorarchitectures[J].
ACMTransonArchitectureandCodeOptimization,2013,9(4):301321.
[7]LukCK,HongSunpyo,KimH.
Qilin:exploitingparallelismonheterogeneousmultiprocessorswithadaptivemapping[C]//Procofthe42ndAnnualIEEE/ACMInternationalSymposiumonMicroarchitecture.
2009:4555.
[8]赵国亮,李云飞,王川.
异构多核系统任务调度算法研究[J].
计算机工程与设计,2014,35(9):30993106.
[9]TsoiKH,LukW.
Axel:aheterogeneousclusterwithFPGAsandGPUs[C]//Procofthe18thACMInternationalSymposiumonFieldProgrammableGateArrays.
NewYork:ACMPress,2010:115124.
[10]RudolphDC,PolychronopoulosCD.
Anefficientmessagepassingschedulerbasedonguidedselfscheduling[C]//Procofthe3rdInternationalConferenceonSupercomputing.
NewYork:ACMPress,1989:5669.
[11]KaleemR,BarikR,ShpeismanT,etal.
AdaptiveheterogeneousschedulingforintegratedGPUs[J].
TheJournalSupercomputer,2014,70(2):756771.
[12]CédricA,SamuelT,RaymandN,etal.
StarPU:aunifiedplatformfortaskschedulingonheterogeneousmulticorearchitectures[C]//Procofthe15thInternationalEuroParConferenceonParallelComputing.
[S.
l.
]:Wiley,2009:863874.
[13]LeeJ,SamadiM,ParkY,etal.
TransparentCPUGPUcollaborationfordataparallelkernelsonheterogeneaussystems[C]//Procofthe22ndInternationalConferenceonParallelArchitecturesandCompilationTechniques.
[S.
l.
]:IEEEPress,2013.
[14]OdenL,KlenkB,NingH.
EnergyefficientstencilcomputationsondistributedGPUsusingdynamicparallelismandGPUcontrolledcommunication[C]//ProcofEnergyEfficientSupercomputingWorkshop.
2014:3140.
[15]Threadingbuildingblocksdocumentation[EB/OL].
(20150409)[20150506].
https://www.
threadingbuildingblocks.
org/.
[16]RossbachCJ,YuYuan,CurreyJ,etal.
Dandelion:acompilerandruntimeforheterogeneoussystems[C]//Procofthe24thACMSymposiumonOperatingSystemPrinciples.
NewYork:ACMPress,2013:4968.
[17]KecklerS,DallyW,KhailanyB,etal.
GPUsandthefutureofparallelcomputing[J].
IEEEMicro,2011,31(5):717.
(上接第3292页)向于AR&BR策略,最终联盟的博弈均衡为ABR策略.
但如果外部环境变化导致零售商博弈力量强于制造商,则制造商将妥协选择AR&BR策略.
本文尚存在一些不足,无限周期的研究将是今后的研究方向.
参考文献:[1]ShapiroE.
Movies:blockbusterseeksanewdealwithHollywood[J].
WallStreetJournal,1999,3(25):12.
[2]孔晓红.
卡特彼勒为产品制造来生[J].
中国循环经济,2014,9:5054.
[3]FergusonME,ToktayLB.
Theeffectofcompetitiononrecoverystrategies[J].
ProductionandOperationsManagement,2006,15(3):351.
[4]易余胤.
基于再制造的闭环供应链博弈模型[J].
系统工程理论与实践,2009,29(8):2835.
[5]熊中楷,王凯,熊榆.
经销商从事再制造的闭环供应链模式研究[J].
管理科学学报,2011,14(11):19.
[6]McWilliamsB.
Moneybackguarantees:helpingthelowqualityretailer[J].
ManagementScience,2012,58(8):15211524.
[7]ShulmanJD,CoughlanAT,SavaskanRC.
Managingconsumerreturnsinacompetitiveenvironment[J].
ManagementScience,2011,57(2):347362.
[8]GuQiaolun,GaoTiegang.
Managementoftwocompetitiveclosedloopsupplychains[J].
InternationalJournalofSustainableEngineering,2012,5(4):325337.
[9]WuChenghan.
Priceandservicecompetitionbetweennewandremanufacturedproductsinatwoechelonsupplychain[J].
InternationalJournalofProductionEconomics,2012,140(1):496507.
[10]ChenJing,GrewalR.
Competinginasupplychainviafullrefundandnorefundcustomerreturnspolicies[J].
InternationalJournalofProductionEconomics,2013,146(1):246258.
[11]QiangQiang,KeKe,AndersonT,etal.
Theclosedloopsupplychainnetworkwithcompetition,distributionchannelinvestment,anduncertainties[J].
Omega,2013,41(2):186194.
[12]高阳,林恺.
考虑异质需求的再制造系统最优产量与定价研究[J].
计算机应用研究,2015,32(5):13491952.
[13]FallahH,EskandariH,PishvaeeMS.
Competitiveclosedloopsupplychainnetworkdesignunderuncertainty[J].
JournalofManufacturingSystems,2015,37(3):649661.
[14]KumarS,MalegeantP.
Strategicallianceinaclosedloopsupplychain,acaseofmanufacturerandecononprofitorganization[J].
Technovation,2006,26(10):11271135.
[15]LiXiuhui,WangQinan.
Coordinationmechanismsofsupplychainsystems[J].
EuropeanJournalofOperationalResearch,2007,179(1):116.
[16]晏妮娜,黄小原.
基于第3方逆向物流的闭环供应链模型及应用[J].
管理科学学报,2008,11(4):8393.
[17]JenaSK,SarmahSP.
Pricecompetitionandcooperationinaduopolyclosedloopsupplychain[J].
InternationalJournalofProductionEconomics,2014,156:346360.
[18]高阳,杨新.
基于WTP差异化的再制造闭环供应链利益协调机制[J].
计算机应用研究,2014,31(2):388391.
·9133·第11期裴颂文,等:CPUGPU异构多核系统的动态任务调度算法
- 算法千核处理器相关文档
- 线程千核处理器
- 计算千核处理器
- 光电千核处理器
- 上海市千核处理器
- 报文基于OCTEON多核处理器的高精度网络报文处理系统(计算机论文)
- 缓存多核处理器中改进的动态缓存优化技术(计算机论文)
AkkoCloud(60元/月 ),英国伦敦CN2 1核 768 MB 内存 10 GB SSD 硬盘 600GB 流量 英国伦敦CN2 1核 1.5G 300Mbps
官方网站:https://www.akkocloud.com/AkkoCloud新品英国伦敦CN2 GIA已上线三网回程CN2 GIA 国内速度优秀.电信去程CN2 GIALooking Glass:http://lonlg.akkocloud.com/Speedtest:http://lonlg.akkocloud.com/speedtest/新品上线刚好碰上国庆节 特此放上国庆专属九折循环优惠...
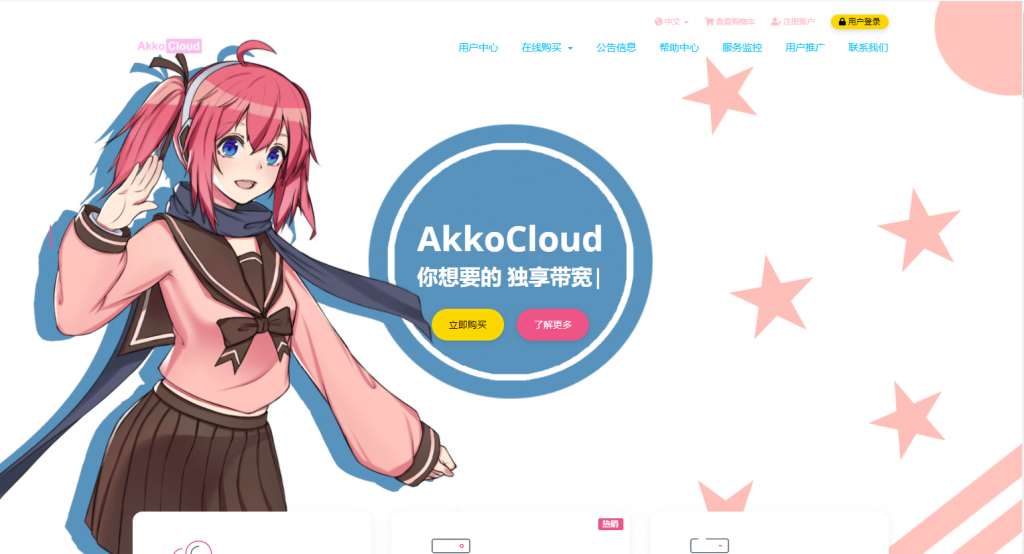
易探云(QQ音乐绿钻)北京/深圳云服务器8核8G10M带宽低至1332.07元/年起
易探云怎么样?易探云香港云服务器比较有优势,他家香港BGP+CN2口碑不错,速度也很稳定。尤其是今年他们动作很大,推出的香港云服务器有4个可用区价格低至18元起,试用过一个月的用户基本会续费,如果年付的话还可以享受8.5折或秒杀价格。今天,云服务器网(yuntue.com)小编推荐一下易探云国内云服务器优惠活动,北京和深圳这二个机房的云服务器2核2G5M带宽低至330.66元/年,还有高配云服务器...
2022年最新PHP短网址生成系统/短链接生成系统/URL缩短器系统源码
全新PHP短网址系统URL缩短器平台,它使您可以轻松地缩短链接,根据受众群体的位置或平台来定位受众,并为缩短的链接提供分析见解。系统使用了Laravel框架编写,前后台双语言使用,可以设置多域名,还可以开设套餐等诸多功能,值得使用。链接: https://pan.baidu.com/s/1ti6XqJ22tp1ULTJw7kYHog?pwd=sarg 提取码: sarg文件解压密码 www.wn7...
千核处理器为你推荐
-
bbs.99nets.com送点卷的冒险岛私服bbs.99nets.com做一款即时通讯软件难吗 像hi qq这类的关键字关键词标签里写多少个关键词为最好杰景新特杰普特长笛JFL-511SCE是不是有纯银的唇口片??价格怎样??同一ip网站如何用不同的IP同时登陆一个网站百度关键词工具如何通过百度官方工具提升关键词排名www.gegeshe.com有什么好听的流行歌曲www.zhiboba.com看NBA直播的网站哪个知道www.ijinshan.com金山毒霸的网站是多少yinrentangzimotang氨基酸洗发水的功效咋样?