缓存多核处理器中改进的动态缓存优化技术(计算机论文)
封面
《多核处理器中改进的动态缓存优化技术》Word格式可编辑含目录
内容含搞要关键字正文参考文献等。
精心整理放心阅读质优价廉欢迎下载
文档信息
多核处理器中改进的动态缓存优化技术
目录
三维集成技术可以实现不同技术的异构集成
2基于缓存资源共享的三维多核结构
三维多核系统
三维缓存数据通道管理
3在线应用感知作业分配和缓存共享策略
4更大规模的三维多核系统作业分配
5仿真实验与结果分析
6结束语
32(1) : 131438
J] .HPLaboratories 2008 2(11) : 111. . .
正文
摘要为提高多核处理器中缓存资源池效率并降低芯片总面积设计三维多核结构 同时给出在线应用感知作业分配和缓存共享策略。通过分析应用程序性能特征预测资源需求量将相邻层中具有不同缓存特点的作业分配给三维多核结构内核使应用程序与缓存用途相匹配 同时根据应用程序对缓存需求度分配缓存资源实现缓存资源利
用率的最大化。实验结果表明该策略可提高系统性能降低能耗和芯片面积与基于静态缓存的三维多核存储器相比该三维多核结构的能量延迟乘积和能量延迟面积乘积分别提高了%和
关键字缓存资源池;缓存共享多核处理器三维多核结构作业分配
1概述
三维集成技术可以实现不同技术的异构集成
提高单位芯片的晶体管密度和系统性能m。先前对于三维多核系统的大部分研究主要是通过考察固定且同质的计算和内存资源来考虑三维系统能效0。
然而异构多核设计可显著降低能耗和成本。这是因为不同应用有不同的资源需求比如不同的缓存使用量 通过在单个芯片内集成具有不同结构性资源的内核可以解决这_问题。
目前研究人员已经为多核系统提出多内核之间的资源池共享及相应的缓存优化技术M。如文献5]提出一种重用感知的缓存块迁移
RABM)策略采用缓存块的历史迁移信息来预测将来的缓存块迁移从而降低整个缓存系统的功耗。文献6]提出一种共享缓存分配方法通过将并行应用时对共享缓存访问未命中的情况进行分类与追踪并根据建立的性能增益模型在行粒度上进行动态分配共享缓存使系统得到整体性能改善。文献7]提出一种创建动态异构缓存区域的分子缓
存概念。文献8]引入一种低开销在线机制根据缓存丢失率在多个应用间分配缓存。文献9]证明若考虑互通开销则L2缓存的多核共享效果会显著下降。
然而以上方法仍存在不足 1)没有解决应用对缓存的实时需求问题 2)关于三维缓存和内存的研究要么在三维结构内集成了异构静态随机存取存储器StaticRandomAccessMemory SRAM)或动态随机存取存储器DynamicRandomAccessMemory DRAM)层要么需要对传统缓存设计进行重大改动成本较高"3)主要考虑基于静态缓存资源的三维系统对于动态缓存优化不具有适用性。为此本文对缓存资源池技术进行研究设计三维多核结构与在线应用感知作业分配和缓存共享策略通过实现缓存资源的多样性提高三维多核处理器的能效。该策略将作业动态分配给三维多核系统内核使应用与缓存用途相匹配 同时根据应用对缓存的需求度分配缓存资源。
2基于缓存资源共享的三维多核结构
本节描述可以实现缓存资源共享的三维结构。图1表示每层均有_个私有L2缓存和_个内核的4层三维系统组成。其中 图1(a)和图1 (b)分别是带有2MB和1MB静态私有L2缓存的基准三维结构。图1 (c)给出的本文三维结构设计中每个内核均有_个1MBL2缓存垂直相邻缓存利用硅通孔技术(Through~s ilicon-da TSV)相连实现缓存资源共享。
三维多核系统
相比传统缓存结构本文实现的三维多核系统缓存资源共享允许三维多核系统中的内核通过利用其他层的缓存资源访问延时忽略不计来增加自身私有L2缓存规模。该设计的目的如下 1)通过在需要时增加缓存规模来提升性能 2)通过关闭未被使用的缓存区来节约能耗。因为不同应用的L2缓存使用特点区别较大所以本文重点讨论L2缓存的共享问题可以将获得的策略拓展到其他数据缓存层。缓存尺寸取决于块尺寸、集合数量和结合性水平。本文通过改变缓存的结合性来调整缓存尺寸。使用文献10中的选择性通道缓存结构该结构通过关闭不必要的缓存通道来节约二维系统能耗。每个缓存通道称为缓存区。每个区均可被某_个相邻层独立共享。为维持设计的可拓展性并使访问不同区时访问时间相等不允许跨层内核共享缓存。 同时不允许内核同时共享上层或下层的缓存区 以降低设计复杂度。
三维缓存数据通道管理
为实现三维系统缓存资源共享对缓存状态寄存器和缓存控制逻辑进行变动。对三维缓存资源共享 内核需要能够与不同层的缓存区进行交互。为每个本地L2缓存区引入_种本地缓存状态寄存器
(LocalCacheStatusRegister LCSR) (比如本文设计中的1MB缓存有4个区 以记录缓存区的状态。本文为L2缓存引入远程缓存状态寄存器RemoteCacheStatusRegister RCSR) 因此 L1缓存可感知到其远程缓存区。图2(a) 、 图2(b)和图2(c)描述了RCSR和LCSR逻辑通过在线管理策略确定寄存器数值。每个本地缓存区可能有4种情形:关
闭 由本地层使用 由上层或下层使用。每个LCSR保存2个比特来表示对应缓存区的当前状态如图2(d)所示。
此外还在L1缓存中为每个内核维护2个单比特RCSR 以感知其远程缓存区。 L1的I和D缓存可以使用相同的RCSR比特 因为2个缓存的丢失均朝向L2。如果L1缓存的2个RCSR均被设为0则表示没有远程缓存区正被使用。相反如果内核正在使用对应相邻层上的缓存区则RCSR位设为1。 RCSR_0表示下层 RCSR_1表示上层。
内核利用来自LCSR和RCSR的信息可以与多个层上的缓存区通信。如果有L2请求则内核根据RCSR数值发送该请求及被请求的地址。 _旦请求和地址到达缓存块则比较被请求地址的标签与标签数组。同时根据索引来选择每个通道的入口。数据的输出目的地和命中信号由缓存命中之后对应缓存区的LCSR数值确定。本文添加一个多路复用器来选择输出目的地如图2(c)所示。当有一次L2缓存命中时命中信号根据LCSR数值返回给输出目的地处的缓存。当本地命中信号和远程命中信号均为0时表明L2未命中。
因为在线策略可以动态分配缓存区所以需要维护所有缓存的数据完整性。如果重新分配缓存区(比如选择为远程层提供服务的分区来为本地缓存提供服务 则需要在重新分配前清洗缓存通道下的所有缓存块。本文使用与传统二维缓存相同的缓存-致性协议如果有缓存行失效则LCSR和RCSR均重设为0使其无法对远程层进行访问并且删除本地缓存中的数据项。
面积和性能开销
每个单比特寄存器需要多达12个晶体管每个单比特多路复用器需要多达24个晶体管。因此本文设计中额外的寄存器和逻辑器需要的晶体管总数量为2568个10x1-比特寄存器+2x64-比特解复用器+1x30-比特复用器+1x2-比特复用器+1x1-比特解复用器 。假设缓存间的双通道数据传输有128个TSV 内存地址比特有64个TSV在垂直相邻层上的缓存间传输L2请求和命中比特有额外4个TSV。 TSV功耗低于芯片总功耗。因此在仿真时没有考虑TSV功耗。假设TSV的直径为10中心到中心间距为20pm。 TSV的总体面
积开销低于与芯片总面积开销相比可以忽略不计。已有研究表明 TSV导致的层-层延时为远小于1 GHz的CPU时钟周期 因此对性能没有影响。
3在线应用感知作业分配和缓存共享策略
图3给出在线作业分配和缓存资源共享策略的流程。该策略包括2个阶段 1)作业分配确定每个作业应运行于哪个内核上 2)缓存资源共享在_对应用间分配_组可以共享的缓存区。其中只有o/和为同一分区展开竞争时才检测条件。
栈内作业分配
栈内作业分配在考虑能效和热力学因素的条件下将作业分配给三维系统。基于有4个缓存区时的作业IPC(ItructionPerClock)相对只有
1个缓存区时的提升估计值(^)进行分配。利用将在线性能计数数据作为模型输入的离线线性回归模型来估计值。首先将个作业随机分配给三维系统内的个内核然后开始使用默认的预留缓存区使作业运行_段时间每个内核有_个无法共享的256 KB预留L 2缓存区 。估计时使用的性能计数器包括L2缓存替代物、 L2缓存写访问、 L2缓存读取丢失、 L2缓存指令丢失和周期数量。利用线性和交叉条目来构建线性回归模型使用本文仿真中15个基准性能统计数据来训练回归模型采用其余5个基准来证明模型的合理性。在仿真实验中发现系统实际性能的提升与预测误差不超过5%
根据作业的预测性能提升情况对所有作业进行排序通过选择剩余排序列表中的最高值和最小值对这些作业两两分组。
例如在图4中 4个作业按照排序为义為厶為J3為/4。将这些作业两两分组A与J4 2与J3。通过使IPC较高的作业对更接近于散热片可以将本文分配策略与热力学感知试探法H相集成。此时将平均IPC较高的作业对分配给距离散热片最近的可用内核如图4所示。做出该决策是因为相比距离散热器更远的内核距离散热器较近的层上的内缓存资源共享
缓存资源共享为每个作业对内的缓存资源进行管理。为确定一个作业是否需要更多的缓存区首先引入一种性能提升阈值t) 。该阈值表示作业使用额外缓存区时可以降低能量延迟乘积Energy-de layProduct EDP)的最小性能提升幅度。获得t的关键是基于如下
- 缓存多核处理器中改进的动态缓存优化技术(计算机论文)相关文档
- 线程千核处理器
- 计算千核处理器
- 光电千核处理器
- 上海市千核处理器
- 算法千核处理器
- 报文基于OCTEON多核处理器的高精度网络报文处理系统(计算机论文)
亚州云-美国Care云服务器,618大带宽美国Care年付云活动服务器,采用KVM架构,支持3天免费无理由退款!
官方网站:点击访问亚州云活动官网活动方案:地区:美国CERA(联通)CPU:1核(可加)内存:1G(可加)硬盘:40G系统盘+20G数据盘架构:KVM流量:无限制带宽:100Mbps(可加)IPv4:1个价格:¥128/年(年付为4折)购买:直达订购链接测试IP:45.145.7.3Tips:不满意三天无理由退回充值账户!地区:枣庄电信高防防御:100GCPU:8核(可加)内存:4G(可加)硬盘:...

月神科技 国内上新成都高防 全场八折促销续费同价!
月神科技是由江西月神科技有限公司运营的一家自营云产品的IDC服务商,提供香港安畅、香港沙田、美国CERA、成都电信等机房资源,月神科技有自己的用户群和拥有创宇认证,并且也有电商企业将业务架设在月神科技的平台上。本次带来的是全场八折促销,续费同价。并且上新了国内成都高防服务器,单机100G集群1.2T真实防御,上层屏蔽UDP,可定制CC策略。非常适合网站用户。官方网站:https://www.ysi...
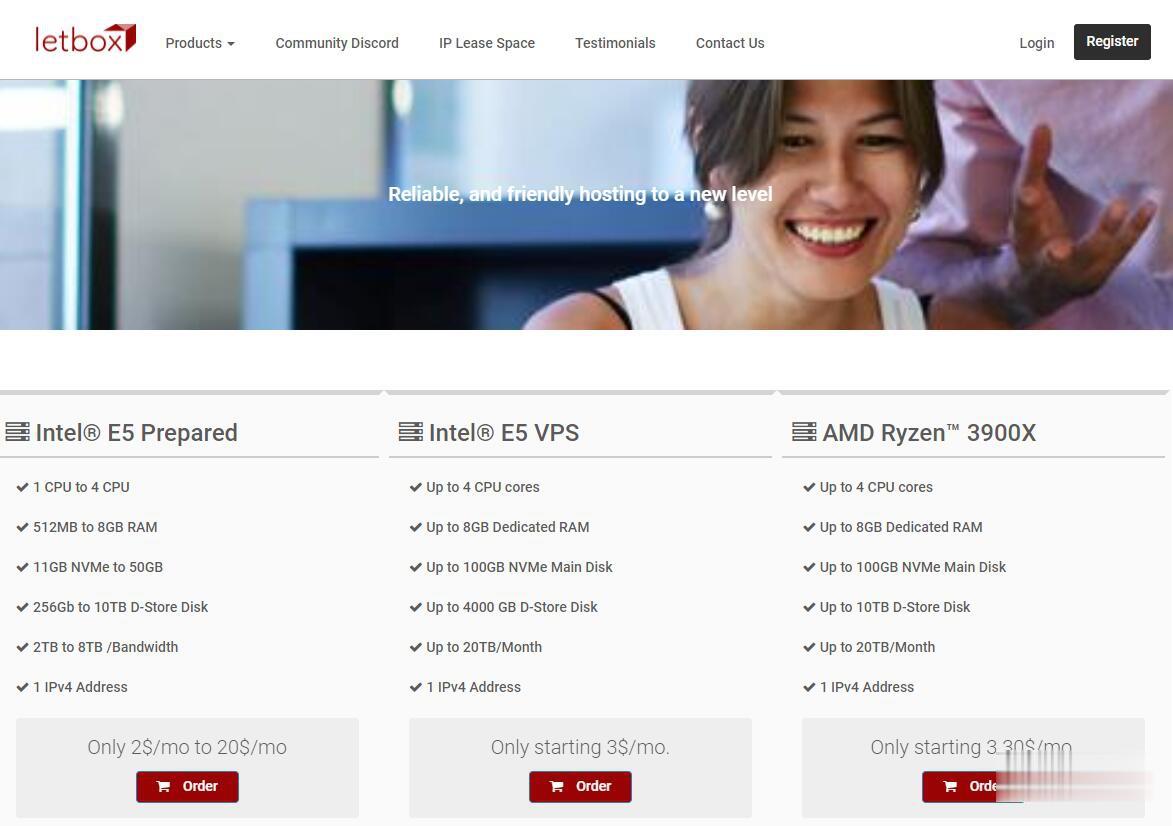
LetBox:美国洛杉矶/新泽西AMD大硬盘VPS,10TB流量,充值返余额,最低3.3美元两个月
LetBox此次促销依然是AMD Ryzen处理器+NVME硬盘+HDD大硬盘,以前是5TB月流量,现在免费升级到10TB月流量。另外还有返余额的活动,如果月付,月付多少返多少;如果季付或者半年付,返25%;如果年付,返10%。依然全部KVM虚拟化,可自定义ISO系统。需要大硬盘vps、大流量vps、便宜AMD VPS的朋友不要错过了。不过LetBox对帐号审核严格,最好注册邮箱和paypal帐号...
-
sonicchatwe chat和微信区别Baby被问婚变绯闻黄晓明婚礼上说baby碰他哪里最兴奋梦之队官网史上最强的nba梦之队是哪一年月神谭有没有什么好看的小说?拒绝言情小说!百花百游百花净斑方效果怎么样?同ip网站同IP的两个网站,做单向链接,会不会被K掉??同ip域名不同域名解析到同一个IP是否有影响haole16.com国色天香16 17全集高清在线观看 国色天香qvod快播迅雷下载地址336.com求那个网站 你懂得 1552517773@qqwww.493333.comwww.xiaonei.com