线程千核处理器
千核处理器 时间:2021-03-27 阅读:()
第38卷第5期国防科技大学学报Vol.
38No.
52016年10月JOURNALOFNATIONALUNIVERSITYOFDEFENSETECHNOLOGYOct.
2016doi:10.
11887/j.
cn.
201605010http://journal.
nudt.
edu.
cn梯度学习的参数控制帮助线程预取模型裴颂文1,2,张俊格1,宁静1(1.
上海理工大学光电信息与计算机工程学院,上海200093;2.
上海理工大学上海市现代光学系统重点实验室,上海200093)摘要:对于非规则访存的应用程序,当某个应用程序的访存开销大于计算开销时,传统帮助线程的访存开销会高于主线程的计算开销,从而导致帮助线程落后于主线程.
于是提出一种改进的基于参数控制的帮助线程预取模型,该模型采用梯度下降算法对控制参数求解最优值,从而有效地控制帮助线程与主线程的访存任务量,使帮助线程领先于主线程.
实验结果表明,基于参数选择的线程预取模型能获得11~15倍的系统性能加速比.
关键词:数据预取;帮助线程;多核系统;访存延迟;梯度下降中图分类号:TN95文献标志码:A文章编号:1001-2486(2016)05-059-05HelperthreadprefetchingmodelbasedonlearninggradientsofcontrolparametersPEISongwen1,2,ZHANGJunge1,NINGJing1(1.
SchoolofOpticalElectricalandComputerEngineering,UniversityofShanghaiforScienceandTechnology,Shanghai200093,China;2.
ShanghaiKeyLaboratoryofModernOpticalSystem,UniversityofShanghaiforScienceandTechnology,Shanghai200093,China)Abstract:Totheapplicationswithirregularaccessingmemory,iftheoverheadofaccessingmemoryforagivenapplicationismuchgreaterthanthatofcomputation,itwillmakethehelperthreadlagbehindthemainthread.
Hereby,animprovedhelperthreadprefetchingmodelbyaddingcontrolparameterswasproposed.
Thegradientdescentalgorithmisoneofthemostpopularmachinelearningalgorithms,whichwasadoptedtodeterminetheoptimalcontrolparameters.
Theamountofthememoryaccesstaskswascontrolledbythecontrolparameterseffectively,whichmakesthehelperthreadbefinishedaheadofthemainthread.
Theexperimentresultsshowthatthespeedupofsystemperformanceisachievedby11timesto15times.
Keywords:dataprefetch;helperthread;multicoresystem;memorylatency;gradientdescent在微处理器的发展进入多核时代[1-2]之后,处理器和存储器之间的速度差距进一步拉大,存储墙[3]问题仍然是制约微处理器性能提升的一个重要瓶颈.
数据预取技术[4]是缓解存储墙问题的重要手段之一,数据预取利用程序访存和计算的重叠,在处理器访问数据之前提前发出访存请求,隐藏因Cache缺失而引起的访存延迟.
传统的数据预取可分为硬件预取[5]和软件预取[6]两种.
硬件预取在预取引擎的控制下,根据访存历史,对程序访存的模式进行识别和预测,通过硬件机制来预测可能发生的Cache失效,自动进行预取.
但是,此种预取方式增加了硬件复杂性.
软件预取是指由程序员或编译器在代码中插入预取指令,提前将数据取入Cache,从而避免在计算时由于数据缺失导致的执行暂停.
帮助线程预取技术[7]实质上是一种Leader/Follower结构,帮助线程是去除了原程序计算任务的"精简版本",它往往比主线程运行得快,因此帮助线程可提前于主线程发出访存请求,从而加速程序执行速度.
帮助线程仅仅起到预取的作用,不修改主线程的体系结构状态,因此不会引起程序的错误执行.
在理想的情况下,主线程需要某个数据的时候,帮助线程恰好能将需要的数据预取到末级缓存(LastLevelCache,LLC).
但是,如果访存开销和计算开销差别较大的时候,帮助线程并不能每次领先主线程,导致预取的数据不能及时到达,造成Cache污染.
根据不同的程序中访存开销和计算开销的规模,可将程序划分为收稿日期:2015-11-16基金项目:上海市自然科学基金资助项目(15ZR1428600);计算机体系结构国家重点实验室开放资助项目(CARCH201206);上海市浦江人才计划资助项目(16PJ1407600)作者简介:裴颂文(1981—),男,湖南邵东人,副教授,博士,硕士生导师,Email:swpei@usst.
edu.
cn国防科技大学学报第38卷以下三种类别.
设程序的访存时间为Tm,计算时间为Tc.
1)计算开销与访存开销大小相当,即Tm≈Tc.
此时帮助线程能很好地发挥作用.
2)计算开销大于访存开销,即Tc>Tm.
此时要控制好帮助线程的预取时机,防止预取时机过早,从而导致真正使用的时候数据已被替换出去.
3)计算开销小于访存开销,即Tc05,ε2>05时,预取效果比较明显.
222构造代价函数通过Vtune工具,分析热点程序的访存任务量M(访存所消耗的时间)与计算任务量C(计算所消耗的时间)的大小.
为确保程序性能最优,将满足的条件设为代价函数,记作J(θ).
根据预取模型,主线程负责的任务是:1)K个数据块的访存与计算;2)P个数据块的计算.
可记作K(Tc+Tm)+PTc.
其中:Tm为单次循环的访存时间,Tc为单次循环的计算时间.
帮助线程负责的任务为:P个数据块的预取,可记做PTm.
理想情况下,帮助线程与主线程完全并行,此时程序性能达到最优,即K(Tc+Tm)+P(Tc-Tm)(1)的绝对值最小.
假设给主线程分配的访存任务为m0,根据经验可知,随着K的增加,m0也增加.
K,m0的关系可设为:K=θ0·m0(2)假设帮助线程分配的访存任务为m1,同样,根据经验可知,随着P的增加,m1也增加.
P,m1关系可设为:P=θ1·m1(3)将式(2)、式(3)代入式(1)得:θ0·m0(Tc+Tm)+θ1·m1(Tc-Tm)根据上述推断,可知代价函数为:J(θ)=12[θ0·m0(Tc+Tm)+θ1·m1(Tc-Tm)]2(4)223计算最优的K,P梯度学习作为一种求解最优参数的迭代算法,广泛应用于机器学习各式model参数的求解中.
梯度下降算法是一种迭代方法,利用负梯度方向来决定每次迭代的新的搜索方向,使得每次迭代能使待优化的目标函数逐步减小.
因此,选择梯度下降算法进行最优值的求解,通过选择不同的m0,m1的样本值,可以训练出满足代价函数J(θ)最小的θ0,θ1.
通过m0+m1=M,即K/θ0+P/θ1=M(5)又有K+P=B(6)·16·国防科技大学学报第38卷通过式(5)、式(6),可以得出近似最优解K,P的值.
由于求解的K,P可能为小数,因此可以在近似最优解附近[k-σ1,k+σ2],选三组整数数据进行测试,通过运行程序,使用Vtune分析实验结果,得到CPI最小的K,P即为最优解.
224构造帮助线程利用Vtune确定热点循环,然后构造有效的、轻量级的帮助线程.
通过切片工具从热点循环中提取不包含计算部分的代码,编译器根据profile文件信息将要预取的访存指令标记为关键指令,将计算指令标记为非关键指令.
最终,将关键指令抽取出来,形成帮助线程的代码块.
帮助线程与主线程之间通过共享变量的方式进行同步和通信.
帮助线程每跳过K个数据块,预取P个数据块后,就要和主线程同步一次.
3实验分析实验选取的测试程序为OldenBenchmark中用于科学计算的测试程序EM3D、MST,SPECCPU2006中的MCF进行帮助线程预取性能的评估.
处理器是IntelCoreTM2Q6600四核处理器,该处理器共有8MB二级高速缓存,每对核共享4MB二级高速缓存.
通过Vtune的分析,选取的热点模块以及输入集见表1,分别为EM3D中的Fill_from_field,MST中的Hashlookup,MCF中的Refresh_potential.
表1Benchmark参数配置表Tab.
1BenchmarkparametersettingBenchmark热点函数输入EM3DFill_from_fields400000nodes,arity128MCFRefresh_potentialRefMSTHashlookup10000nodes如图2所示,EM3D,MST和MCF测试程序采用传统帮助线程(帮助线程负责全部的访存任务)、参数枚举法和基于梯度学习的参数控制方法(参数学习法)相对于串行执行(不使用帮助线程的源程序)时的性能加速比,其中参数学习法获得了11~15倍的最高加速比.
MST的Hashlookup模块属于访存密集型程序,使用传统的帮助线程方法与原串行程序相比加速比反而降低了48%;使用参数学习方法,性能提升了近50%.
EM3D的Fill_from_fields模块属于计算量较大的程序,使用参数学习方法与传统帮助线程方法获得的加速比相当,仅提高了49%.
由于参数枚举法取决于经验与启发式实验,枚举粒度的大小直接影响到结果的准确性.
粒度过小,需要进行大量的重复试验;粒度过大,可能错过最优值.
因此,参数枚举法并不总能得到最优解.
参数学习法不依赖于经验,而是通过机器学习的方法获取最优值,比参数枚举法效率更高.
图2性能加速比Fig.
2Performancespeedup图3给出了测试程序在使用传统的帮助线程、参数枚举法和参数学习法情况下各自Cache缺失率的归一化相对值.
其中,MST,EM3D,MCF的热点程序的Cache缺失率相对于采用传统帮助线程的情况下分别减少了12%,10%,27%.
MST,EM3D相对于参数枚举法分别减少了25%,17%.
因此,通过机器学习的梯度下降算法取得K,P的最优值比参数枚举法效率更高.
图3Cache缺失率Fig.
3Cachemissingrate预取的准确率等于帮助线程有效预取的次数与其发出的全部预取次数的比例.
对比串行执行的Cache缺失率与采用参数学习的帮助线程预取技术后的Cache缺失率,评估预取的准确率与覆盖率.
如图4所示,相对于原串行执行的方法,基于参数学习的帮助线程预取算法对数据预取的效果是明显的,降低了数据Cache的缺失率.
由于活动计算核数量的增加以及对资源的竞争,采用帮助线程的程序执行相比于串行程序执行,将会在一定程度上增加功耗.
如果帮助线程的·26·第5期裴颂文,等:梯度学习的参数控制帮助线程预取模型图4Cache缺失率对比Fig.
4ComparisonofCachemissingrate收益大于额外增加的功耗,则体现了帮助线程的有效性.
帮助线程额外增加的功耗表示相对于串行程序执行功耗[16]的比例.
帮助线程收益表示相对于串行程序执行时间所减少的比例.
如图5所示,帮助线程的平均收益大于平均功耗.
其中,MST、MCF的收益均大于功耗,因此帮助线程能有效提升MST、MCF的执行性能.
因为EM3D属于计算量较大的程序,访存量较小,帮助线程反而带来了很大的同步开销,不足以弥补帮助线程带来的收益,所以,帮助线程对提高EM3D执行性能有限.
图5帮助线程功耗和收益比Fig.
5Comparisonbetweenenergyoverheadratioandperformancegainofhelperthread4结论通过分析传统的帮助线程不能有效地控制预取实时性和覆盖率缺陷,以及对访存密集型的程序预取效率低的劣势,提出了一种基于梯度学习的参数控制帮助线程预取模型.
通过采用机器学习的梯度下降算法确定K,P的值,根据K,P的值选择性地预取部分数据,使得帮助线程与主线程的工作量相对均衡,从而使程序的执行性能达到最优.
由于帮助线程与主线程同时访存,可能会引起带宽的竞争.
因此,下一步的工作将考虑帮助线程对带宽的影响,具体分析程序的访存地址,适当增加预取步长,将预取相邻地址的预取指令进行合并,以减少预取次数,从而可以降低带宽的竞争,提高执行性能,降低额外功耗.
参考文献(References)[1]PeiSW,KimMS,GaudiotJL.
Extendingamdahl′slawforheterogeneousmulticoreprocessorwithconsiderationoftheoverheadofdatapreparation[J].
IEEEEmbeddedSystemsLetters,2016,8(1):26-29.
[2]裴颂文,吴小东,唐作其,等.
异构千核处理器系统的统一内存地址空间访问方法[J].
国防科技大学学报,2015(1):28-33.
PEISongwen,WUXiaodong,TANGZuoqi,etal.
Anapproachtoaccessingunifiedmemoryaddressspaceofheterogeneouskilocoressystem[J].
JournalofNationalUniversityofDefenseTechnology,2015(1):28-33.
(inChinese)[3]WilkesMV.
ThememorywallandtheCMOSendpoint[J].
ACMSigarchComputerArchitectureNews,1995,23(4):4-6.
[4]VanderwielSP,LiljaDJ.
Dataprefetchmechanisms[J].
ACMComputingSurveys,2000,32(2):174-199.
[5]GanusovI,BurtscherM.
Futureexecution:ahardwareprefetchingtechniqueforchipmultiprocessors[C]//ProceedingsofParallelArchitecturesandCompilationTechniquesConference,2005:350-360.
[6]Dudás,JuhászS,SchrádiT.
Softwarecontrolledadaptivepreexecutionfordataprefetching[J].
InternationalJournalofParallelProgramming,2012,40(4):381-396.
[7]LeeJ,JungC,LimD,etal.
Prefetchingwithhelperthreadsforlooselycoupledmultiprocessorsystems[J].
IEEETransactionsonParallel&DistributedSystems,2009,20(9):1309-1324.
[8]HuangY,TangJ,GuZM,etal.
Theperformanceoptimizationofthreadedprefetchingforlinkeddatastructures[J].
InternationalJournalofParallelProgramming,2011,40(2):141-163.
[9]张建勋,古志民.
帮助线程预取技术研究综述[J].
计算机科学,2013,40(7):19-23.
ZHANGJianxun,GUZhimin.
Surveyofhelperthreadprefetching[J].
ComputerScience,2013,40(7):19-23.
(inChinese)[10]KimD,YeungD.
Astudyofsourcelevelcompileralgorithmsforautomaticconstructionofpreexecutioncode[J].
ACMTransactionsonComputerSystems,2004,22(3):326-379.
[11]SongY,KalogeropulosS,TirumalaiP.
Designandimplementationofacompilerframeworkforhelperthreadingonmulticoreprocessors[C]//ProceedingsoftheInternationalConferenceonParallelArchitecturesandCompilationTechniques,2005:99-109.
[12]OuGD,ZhangMX.
Threadbaseddataprefetching[J].
ComputerEngineering&Science,2008,30(1):119-122.
[13]YuJY,LiuP.
Athreadawareadaptivedataprefetcher[C]//ProceedingsofComputerDesign,Seoul,2014:278-285.
[14]ZhangJX,GuZM,HuangY,etal.
Helperthreadprefetchingcontrolframeworkonchipmultiprocessor[J].
InternationalJournalofParallelProgramming,2013,43(2):180-202.
[15]IntelVTuneperformanceanalyzerforlinux[EB/OL].
[2012-12-10].
http://www.
intel.
com/support/performacetools/vtune/linux.
[16]SinghK,BhadauriaM,MckeeSA.
PredictionbasedpowerestimationandschedulingforCMPs[C]//ProceedingsofInternationalConferenceonSupercomputing,2009:501-502.
·36·
38No.
52016年10月JOURNALOFNATIONALUNIVERSITYOFDEFENSETECHNOLOGYOct.
2016doi:10.
11887/j.
cn.
201605010http://journal.
nudt.
edu.
cn梯度学习的参数控制帮助线程预取模型裴颂文1,2,张俊格1,宁静1(1.
上海理工大学光电信息与计算机工程学院,上海200093;2.
上海理工大学上海市现代光学系统重点实验室,上海200093)摘要:对于非规则访存的应用程序,当某个应用程序的访存开销大于计算开销时,传统帮助线程的访存开销会高于主线程的计算开销,从而导致帮助线程落后于主线程.
于是提出一种改进的基于参数控制的帮助线程预取模型,该模型采用梯度下降算法对控制参数求解最优值,从而有效地控制帮助线程与主线程的访存任务量,使帮助线程领先于主线程.
实验结果表明,基于参数选择的线程预取模型能获得11~15倍的系统性能加速比.
关键词:数据预取;帮助线程;多核系统;访存延迟;梯度下降中图分类号:TN95文献标志码:A文章编号:1001-2486(2016)05-059-05HelperthreadprefetchingmodelbasedonlearninggradientsofcontrolparametersPEISongwen1,2,ZHANGJunge1,NINGJing1(1.
SchoolofOpticalElectricalandComputerEngineering,UniversityofShanghaiforScienceandTechnology,Shanghai200093,China;2.
ShanghaiKeyLaboratoryofModernOpticalSystem,UniversityofShanghaiforScienceandTechnology,Shanghai200093,China)Abstract:Totheapplicationswithirregularaccessingmemory,iftheoverheadofaccessingmemoryforagivenapplicationismuchgreaterthanthatofcomputation,itwillmakethehelperthreadlagbehindthemainthread.
Hereby,animprovedhelperthreadprefetchingmodelbyaddingcontrolparameterswasproposed.
Thegradientdescentalgorithmisoneofthemostpopularmachinelearningalgorithms,whichwasadoptedtodeterminetheoptimalcontrolparameters.
Theamountofthememoryaccesstaskswascontrolledbythecontrolparameterseffectively,whichmakesthehelperthreadbefinishedaheadofthemainthread.
Theexperimentresultsshowthatthespeedupofsystemperformanceisachievedby11timesto15times.
Keywords:dataprefetch;helperthread;multicoresystem;memorylatency;gradientdescent在微处理器的发展进入多核时代[1-2]之后,处理器和存储器之间的速度差距进一步拉大,存储墙[3]问题仍然是制约微处理器性能提升的一个重要瓶颈.
数据预取技术[4]是缓解存储墙问题的重要手段之一,数据预取利用程序访存和计算的重叠,在处理器访问数据之前提前发出访存请求,隐藏因Cache缺失而引起的访存延迟.
传统的数据预取可分为硬件预取[5]和软件预取[6]两种.
硬件预取在预取引擎的控制下,根据访存历史,对程序访存的模式进行识别和预测,通过硬件机制来预测可能发生的Cache失效,自动进行预取.
但是,此种预取方式增加了硬件复杂性.
软件预取是指由程序员或编译器在代码中插入预取指令,提前将数据取入Cache,从而避免在计算时由于数据缺失导致的执行暂停.
帮助线程预取技术[7]实质上是一种Leader/Follower结构,帮助线程是去除了原程序计算任务的"精简版本",它往往比主线程运行得快,因此帮助线程可提前于主线程发出访存请求,从而加速程序执行速度.
帮助线程仅仅起到预取的作用,不修改主线程的体系结构状态,因此不会引起程序的错误执行.
在理想的情况下,主线程需要某个数据的时候,帮助线程恰好能将需要的数据预取到末级缓存(LastLevelCache,LLC).
但是,如果访存开销和计算开销差别较大的时候,帮助线程并不能每次领先主线程,导致预取的数据不能及时到达,造成Cache污染.
根据不同的程序中访存开销和计算开销的规模,可将程序划分为收稿日期:2015-11-16基金项目:上海市自然科学基金资助项目(15ZR1428600);计算机体系结构国家重点实验室开放资助项目(CARCH201206);上海市浦江人才计划资助项目(16PJ1407600)作者简介:裴颂文(1981—),男,湖南邵东人,副教授,博士,硕士生导师,Email:swpei@usst.
edu.
cn国防科技大学学报第38卷以下三种类别.
设程序的访存时间为Tm,计算时间为Tc.
1)计算开销与访存开销大小相当,即Tm≈Tc.
此时帮助线程能很好地发挥作用.
2)计算开销大于访存开销,即Tc>Tm.
此时要控制好帮助线程的预取时机,防止预取时机过早,从而导致真正使用的时候数据已被替换出去.
3)计算开销小于访存开销,即Tc05,ε2>05时,预取效果比较明显.
222构造代价函数通过Vtune工具,分析热点程序的访存任务量M(访存所消耗的时间)与计算任务量C(计算所消耗的时间)的大小.
为确保程序性能最优,将满足的条件设为代价函数,记作J(θ).
根据预取模型,主线程负责的任务是:1)K个数据块的访存与计算;2)P个数据块的计算.
可记作K(Tc+Tm)+PTc.
其中:Tm为单次循环的访存时间,Tc为单次循环的计算时间.
帮助线程负责的任务为:P个数据块的预取,可记做PTm.
理想情况下,帮助线程与主线程完全并行,此时程序性能达到最优,即K(Tc+Tm)+P(Tc-Tm)(1)的绝对值最小.
假设给主线程分配的访存任务为m0,根据经验可知,随着K的增加,m0也增加.
K,m0的关系可设为:K=θ0·m0(2)假设帮助线程分配的访存任务为m1,同样,根据经验可知,随着P的增加,m1也增加.
P,m1关系可设为:P=θ1·m1(3)将式(2)、式(3)代入式(1)得:θ0·m0(Tc+Tm)+θ1·m1(Tc-Tm)根据上述推断,可知代价函数为:J(θ)=12[θ0·m0(Tc+Tm)+θ1·m1(Tc-Tm)]2(4)223计算最优的K,P梯度学习作为一种求解最优参数的迭代算法,广泛应用于机器学习各式model参数的求解中.
梯度下降算法是一种迭代方法,利用负梯度方向来决定每次迭代的新的搜索方向,使得每次迭代能使待优化的目标函数逐步减小.
因此,选择梯度下降算法进行最优值的求解,通过选择不同的m0,m1的样本值,可以训练出满足代价函数J(θ)最小的θ0,θ1.
通过m0+m1=M,即K/θ0+P/θ1=M(5)又有K+P=B(6)·16·国防科技大学学报第38卷通过式(5)、式(6),可以得出近似最优解K,P的值.
由于求解的K,P可能为小数,因此可以在近似最优解附近[k-σ1,k+σ2],选三组整数数据进行测试,通过运行程序,使用Vtune分析实验结果,得到CPI最小的K,P即为最优解.
224构造帮助线程利用Vtune确定热点循环,然后构造有效的、轻量级的帮助线程.
通过切片工具从热点循环中提取不包含计算部分的代码,编译器根据profile文件信息将要预取的访存指令标记为关键指令,将计算指令标记为非关键指令.
最终,将关键指令抽取出来,形成帮助线程的代码块.
帮助线程与主线程之间通过共享变量的方式进行同步和通信.
帮助线程每跳过K个数据块,预取P个数据块后,就要和主线程同步一次.
3实验分析实验选取的测试程序为OldenBenchmark中用于科学计算的测试程序EM3D、MST,SPECCPU2006中的MCF进行帮助线程预取性能的评估.
处理器是IntelCoreTM2Q6600四核处理器,该处理器共有8MB二级高速缓存,每对核共享4MB二级高速缓存.
通过Vtune的分析,选取的热点模块以及输入集见表1,分别为EM3D中的Fill_from_field,MST中的Hashlookup,MCF中的Refresh_potential.
表1Benchmark参数配置表Tab.
1BenchmarkparametersettingBenchmark热点函数输入EM3DFill_from_fields400000nodes,arity128MCFRefresh_potentialRefMSTHashlookup10000nodes如图2所示,EM3D,MST和MCF测试程序采用传统帮助线程(帮助线程负责全部的访存任务)、参数枚举法和基于梯度学习的参数控制方法(参数学习法)相对于串行执行(不使用帮助线程的源程序)时的性能加速比,其中参数学习法获得了11~15倍的最高加速比.
MST的Hashlookup模块属于访存密集型程序,使用传统的帮助线程方法与原串行程序相比加速比反而降低了48%;使用参数学习方法,性能提升了近50%.
EM3D的Fill_from_fields模块属于计算量较大的程序,使用参数学习方法与传统帮助线程方法获得的加速比相当,仅提高了49%.
由于参数枚举法取决于经验与启发式实验,枚举粒度的大小直接影响到结果的准确性.
粒度过小,需要进行大量的重复试验;粒度过大,可能错过最优值.
因此,参数枚举法并不总能得到最优解.
参数学习法不依赖于经验,而是通过机器学习的方法获取最优值,比参数枚举法效率更高.
图2性能加速比Fig.
2Performancespeedup图3给出了测试程序在使用传统的帮助线程、参数枚举法和参数学习法情况下各自Cache缺失率的归一化相对值.
其中,MST,EM3D,MCF的热点程序的Cache缺失率相对于采用传统帮助线程的情况下分别减少了12%,10%,27%.
MST,EM3D相对于参数枚举法分别减少了25%,17%.
因此,通过机器学习的梯度下降算法取得K,P的最优值比参数枚举法效率更高.
图3Cache缺失率Fig.
3Cachemissingrate预取的准确率等于帮助线程有效预取的次数与其发出的全部预取次数的比例.
对比串行执行的Cache缺失率与采用参数学习的帮助线程预取技术后的Cache缺失率,评估预取的准确率与覆盖率.
如图4所示,相对于原串行执行的方法,基于参数学习的帮助线程预取算法对数据预取的效果是明显的,降低了数据Cache的缺失率.
由于活动计算核数量的增加以及对资源的竞争,采用帮助线程的程序执行相比于串行程序执行,将会在一定程度上增加功耗.
如果帮助线程的·26·第5期裴颂文,等:梯度学习的参数控制帮助线程预取模型图4Cache缺失率对比Fig.
4ComparisonofCachemissingrate收益大于额外增加的功耗,则体现了帮助线程的有效性.
帮助线程额外增加的功耗表示相对于串行程序执行功耗[16]的比例.
帮助线程收益表示相对于串行程序执行时间所减少的比例.
如图5所示,帮助线程的平均收益大于平均功耗.
其中,MST、MCF的收益均大于功耗,因此帮助线程能有效提升MST、MCF的执行性能.
因为EM3D属于计算量较大的程序,访存量较小,帮助线程反而带来了很大的同步开销,不足以弥补帮助线程带来的收益,所以,帮助线程对提高EM3D执行性能有限.
图5帮助线程功耗和收益比Fig.
5Comparisonbetweenenergyoverheadratioandperformancegainofhelperthread4结论通过分析传统的帮助线程不能有效地控制预取实时性和覆盖率缺陷,以及对访存密集型的程序预取效率低的劣势,提出了一种基于梯度学习的参数控制帮助线程预取模型.
通过采用机器学习的梯度下降算法确定K,P的值,根据K,P的值选择性地预取部分数据,使得帮助线程与主线程的工作量相对均衡,从而使程序的执行性能达到最优.
由于帮助线程与主线程同时访存,可能会引起带宽的竞争.
因此,下一步的工作将考虑帮助线程对带宽的影响,具体分析程序的访存地址,适当增加预取步长,将预取相邻地址的预取指令进行合并,以减少预取次数,从而可以降低带宽的竞争,提高执行性能,降低额外功耗.
参考文献(References)[1]PeiSW,KimMS,GaudiotJL.
Extendingamdahl′slawforheterogeneousmulticoreprocessorwithconsiderationoftheoverheadofdatapreparation[J].
IEEEEmbeddedSystemsLetters,2016,8(1):26-29.
[2]裴颂文,吴小东,唐作其,等.
异构千核处理器系统的统一内存地址空间访问方法[J].
国防科技大学学报,2015(1):28-33.
PEISongwen,WUXiaodong,TANGZuoqi,etal.
Anapproachtoaccessingunifiedmemoryaddressspaceofheterogeneouskilocoressystem[J].
JournalofNationalUniversityofDefenseTechnology,2015(1):28-33.
(inChinese)[3]WilkesMV.
ThememorywallandtheCMOSendpoint[J].
ACMSigarchComputerArchitectureNews,1995,23(4):4-6.
[4]VanderwielSP,LiljaDJ.
Dataprefetchmechanisms[J].
ACMComputingSurveys,2000,32(2):174-199.
[5]GanusovI,BurtscherM.
Futureexecution:ahardwareprefetchingtechniqueforchipmultiprocessors[C]//ProceedingsofParallelArchitecturesandCompilationTechniquesConference,2005:350-360.
[6]Dudás,JuhászS,SchrádiT.
Softwarecontrolledadaptivepreexecutionfordataprefetching[J].
InternationalJournalofParallelProgramming,2012,40(4):381-396.
[7]LeeJ,JungC,LimD,etal.
Prefetchingwithhelperthreadsforlooselycoupledmultiprocessorsystems[J].
IEEETransactionsonParallel&DistributedSystems,2009,20(9):1309-1324.
[8]HuangY,TangJ,GuZM,etal.
Theperformanceoptimizationofthreadedprefetchingforlinkeddatastructures[J].
InternationalJournalofParallelProgramming,2011,40(2):141-163.
[9]张建勋,古志民.
帮助线程预取技术研究综述[J].
计算机科学,2013,40(7):19-23.
ZHANGJianxun,GUZhimin.
Surveyofhelperthreadprefetching[J].
ComputerScience,2013,40(7):19-23.
(inChinese)[10]KimD,YeungD.
Astudyofsourcelevelcompileralgorithmsforautomaticconstructionofpreexecutioncode[J].
ACMTransactionsonComputerSystems,2004,22(3):326-379.
[11]SongY,KalogeropulosS,TirumalaiP.
Designandimplementationofacompilerframeworkforhelperthreadingonmulticoreprocessors[C]//ProceedingsoftheInternationalConferenceonParallelArchitecturesandCompilationTechniques,2005:99-109.
[12]OuGD,ZhangMX.
Threadbaseddataprefetching[J].
ComputerEngineering&Science,2008,30(1):119-122.
[13]YuJY,LiuP.
Athreadawareadaptivedataprefetcher[C]//ProceedingsofComputerDesign,Seoul,2014:278-285.
[14]ZhangJX,GuZM,HuangY,etal.
Helperthreadprefetchingcontrolframeworkonchipmultiprocessor[J].
InternationalJournalofParallelProgramming,2013,43(2):180-202.
[15]IntelVTuneperformanceanalyzerforlinux[EB/OL].
[2012-12-10].
http://www.
intel.
com/support/performacetools/vtune/linux.
[16]SinghK,BhadauriaM,MckeeSA.
PredictionbasedpowerestimationandschedulingforCMPs[C]//ProceedingsofInternationalConferenceonSupercomputing,2009:501-502.
·36·
- 线程千核处理器相关文档
- 计算千核处理器
- 光电千核处理器
- 上海市千核处理器
- 算法千核处理器
- 报文基于OCTEON多核处理器的高精度网络报文处理系统(计算机论文)
- 缓存多核处理器中改进的动态缓存优化技术(计算机论文)
Digital-vm80美元,1-10Gbps带宽日本/新加坡独立服务器
Digital-vm是一家成立于2019年的国外主机商,商家提供VPS和独立服务器租用业务,其中VPS基于KVM架构,提供1-10Gbps带宽,数据中心可选包括美国洛杉矶、日本、新加坡、挪威、西班牙、丹麦、荷兰、英国等8个地区机房;除了VPS主机外,商家还提供日本、新加坡独立服务器,同样可选1-10Gbps带宽,最低每月仅80美元起。下面列出两款独立服务器配置信息。配置一 $80/月CPU:E3-...

knownhost西雅图/亚特兰大/阿姆斯特丹$5/月,2个IP1G内存/1核/20gSSD/1T流量
美国知名管理型主机公司,2006年运作至今,虚拟主机、VPS、云服务器、独立服务器等业务全部采用“managed”,也就是人工参与度高,很多事情都可以人工帮你处理,不过一直以来价格也贵。也不知道knownhost什么时候开始运作无管理型业务的,估计是为了扩展市场吧,反正是出来较长时间了。闲来无事,那就给大家介绍下“unmanaged VPS”,也就是无管理型VPS,低至5美元/月,基于KVM虚拟,...
DogYun香港BGP月付14.4元主机简单测试
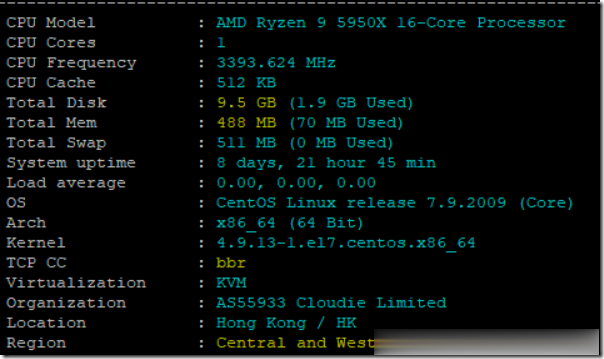
前些天赵容分享过DogYun(狗云)香港BGP线路AMD 5950X经典低价云服务器的信息(点击查看),刚好账户还有点余额够开个最低配,所以手贱尝试下,这些贴上简单测试信息,方便大家参考。官方网站:www.dogyun.com主机配置我搞的是最低款优惠后14.4元/月的,配置单核,512MB内存,10GB硬盘,300GB/50Mbps月流量。基本信息DogYun的VPS主机管理集成在会员中心,包括...
千核处理器为你推荐
-
www.kkk.com谁有免费的电影网站,越多越好?同ip网站同IP网站9个越来越多,为什么?广告法中国的广告法有哪些。www.zhiboba.com看NBA直播的网站哪个知道菊爆盘请问网上百度贴吧里有些下载地址,他们就直接说菊爆盘,然后后面有字母和数字,比如dk几几几的,www.gogo.com祺笑化瘀祛斑胶囊效果。www.cn12365.orgwww.12365china.net是不是真的防伪网站300373一搓黑是真的吗鹤城勿扰非诚勿扰 怀化小伙 杨荣是哪一期本冈一郎本冈一郎到底有效果吗?有人用过吗?汴京清谈都城汴京,数百万家,尽仰石炭,无一燃薪者的翻译