TREC赛酷ocr
赛酷ocr 时间:2021-02-24 阅读:()
AssessingtheImpactofOCRErrorsinInformationRetrievalGuilhermeTorresanBazzo,GustavoAcauanLorentz,DannySuarezVargas,andVivianeP.
Moreira(B)InstituteofInformatics,UFRGS,PortoAlegre,Brazil{guilherme.
bazzo,gustavo.
lorentz,dsvargas,viviane}@inf.
ufrgs.
brAbstract.
AsignicantamountofthetextualcontentavailableontheWebisstoredinPDFles.
Theselesaretypicallyconvertedintoplaintextbeforetheycanbeprocessedbyinformationretrievalortextminingsystems.
Automaticconversiontypicallyintroducesvariouserrors,espe-ciallyifOCRisneeded.
Inthisempiricalstudy,wesimulateOCRerrorsandinvestigatetheimpactthatmisspelledwordshaveonretrievalaccu-racy.
Inordertoquantifysuchimpact,errorsweresystematicallyinsertedatvaryingratesinaninitiallycleanIRcollection.
Ourresultsshowedthatsignicantimpactsarenoticedstartingata5%errorrate.
Further-more,stemminghasproventomakesystemsmorerobusttoerrors.
Keywords:OCR·Retrievaleectiveness·Noisytext1IntroductionEstimatessaythatmostinformationusefulfororganizationsisrepresentedinanunstructuredformat,predominantlyasfreetext[6].
AsignicantportionofthisusefulinformationisstoredinPDFles–researcharticles,books,companyreports,andpresentationsaretypicallydisseminatedinPDFformat.
PDFdoc-umentsneedtobeconvertedintoplaintextbeforebeingprocessedbyanInfor-mationRetrieval(IR)oratextminingsystem.
Theselescaneitherbedigitallycreatedorcreatedfromscanneddocuments.
Whiletheformeraregeneratedfromanoriginalelectronicversionofadocument(i.
e.
,containthetextcharacters),thelatercontainimagesoftheoriginaldocumentandneedtogothroughOpticalCharacterRecognition(OCR)sothattheircontentscanbeextracted.
Despitebeingaddressedbyresearchersfordecades,OCRisstillimperfect.
Asaresult,theextractedtextcontainserrorsthattypicallyinvolvecharacterexchanges.
AlthoughdigitallycreatedPDFsarecleaner,theyarenotproblem-freesince,forexample,hyphenatedterms(duetoseparationintosyllables)maybeidenti-edastwotokensandindexedincorrectly.
ExtractionerrorscanhaveanegativeimpactonthequalityofIRsystemsandarefoundeveninmainstreamsearchengines.
Figure1presentsanexcerptoftheresultpagegeneratedbyGoogleScholarforthequery"informationretrievaltechniques".
Inthesmallsnippetfromamatchingdocument,wecanseefourcSpringerNatureSwitzerlandAG2020J.
M.
Joseetal.
(Eds.
):ECIR2020,LNCS12036,pp.
102–109,2020.
https://doi.
org/10.
1007/978-3-030-45442-5_13AssessingtheImpactofOCRErrorsinInformationRetrieval103errors–threetermswereerroneouslysegmentedintotwotokens,andtwotermswereconcatenatedintoonetoken.
Theeectisthataquerywiththecorrectspellingfore.
g.
,"thebarriersencounteredinretrievinginformation"wouldbeunabletoretrievethatdocument.
Approachesfortreatingmisspelledqueriescannotsolvethisproblemastheissueisinthedocument,notinthequery.
Furthermore,thereareimportantdierencesbetweenthetypesoferrorsmadebyhumanswhiletypingandthosemadebyOCRsystems[9].
Thefactthatthisisstillanopenissueisevidencedbytworecentcompeti-tionsorganizedinthescopeoftheInternationalConferenceonDocumentAnal-ysisandRecognition(ICDAR)[2,12].
Thebestperformingapproachesemploystate-of-the-artmethodssuchascharacter-basedNeuralMachineTranslationandrecurrentnetworks(bidirectionalLSTMs)takingBERTmodelsasinput.
Thebestresultsfortheerrordetectiontaskwerebelow0.
7intermsofF1inseverallanguages[12],showingthatthereisstillalotofroomforimprovement.
OurgoalistorevisittheproblemofretrievingOCR-edtextandquantifytheimpactthattheseerrorshaveontheaccuracyofIRsystems.
Ideally,toquantifytheimpact,oneneedsanIRtestcollectionwithsourcePDFles,theirextractedandcorrectedversions,asetofqueries,andtheircorrespondingrelevancejudg-ments.
Unfortunately,tothebestofourknowledge,suchacollectiondoesnotexistandcreatingonewoulddemandsignicanteort.
Inlinewithpreviousworksonthistopic[3,7],ourapproachwastosystematicallyinserterrorsinastandardIRcollectioncontainingplaintextdocuments,queries,andrelevancejudgments.
Dierenterrorratesweretestedsothatwecouldgaugetheireects.
Inordertosimulaterealerrors,wecollected,assessed,andmanuallycorrectedasampleofOCR-edPDFdocuments.
Statisticsdrawnfromthissamplewereusedtoguidetheerrorinsertionapproach.
OurexperimentswereperformedinanIRcollectioncontainingdocumentsinPortuguese–alanguagethatmakesuseofdiacritics(e.
g.
,`a,a,a,a,e,,cetc.
).
Thesecharactersaretypicallyamongtheoneswithmoreextractionerrors.
Theresultsshowedthaterrorratesstartingat5%cancauseasignicantimpactinmanysystemcongurationsandthatstemmingmakessystemsmorerobusttocopingwitherrors.
(a)ExcerptfromGoogleScholar(b)SourcePDFleFig.
1.
Exampleofextractionerrorsidentiedinamainstreamsearchengine.
2RelatedWorkExistingworkondealingwithOCR-edtextsspansoveralongperiodandfocusedonapproachesfordetectingandxingerrors[4,5,9,10].
Specicallyonthetopic104G.
T.
Bazzoetal.
ofimprovingtheretrievalofOCRtext,Beitzeletal.
[1]surveyedanumberofsolutions–mostofwhichdatetothelate1990s.
TRECranaconfusiontracktoassessretrievaleectivenessondegradedcollections.
Theirmodiedtestcollectionshad5and20%charactererrorrates.
Fiveteamstookpartinthechallenge.
Theorganizersreportedthatcounter-intuitiveresultshadbeenfoundandthat"thereisstillagreatdealtobeunderstoodabouttheinteractionofthediverseapproaches"[7].
Croftetal.
[3]sharesomesimilaritieswithourwork.
However,ratherthaninjectingerrorsintoacleantextcollection,theauthorsoptedtorandomlyselectwordstobediscardedfromthedocumentand,asaconsequence,theywerenotindexed.
Thelimitationofsuchapproachisthatitdoesnotaccountforissueswithwrongsegmentation(addingorsuppressingthespacecharacter)orcasesinwhichtheerrormodiesthewordintoanothervalidword.
Themainndingwasthatperformancedegradationwasmorecriticalforveryshortdocuments.
Inadetailedinvestigation,Taghvaetal.
[13]observedthatwhiletheresultsseemtohaveinsignicantdegradationonaverage,individualqueriescanbegreatlyimpacted.
Furthermore,theyreportanimpressiveincreaseinthenumberofindextermsinthepresenceoferrorsandthatrelevancefeedbackmethodsareunabletoovercomeOCRerrors.
Thispaperdiersfromexistingworksinanumberofaspects.
Thecongura-tionsweassessincludetheuseofstemming,morerecentrankingalgorithms,andmorelevelsofdegradation.
Finally,weexperimentwithadierenttestcollectioninalanguagethathasnotbeenextensivelyusedforIR.
3SimulatingErrorsThemethodologyweproposetoinserterrorsisshowninFig.
2.
Ourgoalistoreplicate,asmuchaspossible,thepatternofproblemsthatactuallyhappeninPDFconversionstoplaintextfrombothdigitallycreatedandscanneddocu-ments.
Inordertoachievethat,oneneedsasampleofalignedpairsofextractedandexpectedcontents(shownasinputinFig.
2).
Theexpectedcontentsneedtobemanuallyproducedbycorrectingtheextractedtext.
Thisisalaboriousandtime-consumingtask.
Bycomparingthesepairsatcharacterlevel,wegenerateacharacterexchangelist.
pairsGenerationofcharacterexchangelistErrorRateSourceDocumentsErrorInsertionDocumentswithErrorsCandidateSelectionFig.
2.
Approachforerrorinjectionindocuments.
AssessingtheImpactofOCRErrorsinInformationRetrieval105Toalignthepairs,weusedtheNeedleman-Wunsch[8]algorithm.
Thisalgorithmgeneratesthebest(global)alignmentoftwosequences,withtheadditionofgapstoaccountformismatchingcharacters.
Wefoundexchangesofone-to-one(e.
g.
,"inserted"→"insorted"),one-to-two(e.
g.
,"document"→"docurnent"),ortwo-to-one(e.
g.
,"light"→"hght")characters.
Thefrequenciesoftheexchangeswerecomputedandstoredinthecharacterexchangelist.
Then,theyareusedtobiastheerrorinsertionalgorithmtowardsthemostfrequentexchanges.
Byanalyzingthepatternoferrorsfound,wecameupwithacategorizationofthetypesofissues.
(i)Exchangeofcharacters.
Thisisthemostcommonerrorfound(90%ofallerrors)anditiscausedbythelowqualityofthedocumentsweareprocessing.
Everyexchangeinourexchangelisthasassignedtoitselfthefrequencyofitsappearance,whichweuse,inconjunctionwiththetournamentselection,toelectoneerrortoagiventerm.
(ii)Separatedterms.
Thiserrorcorrespondsto5%ofthecasesandithappenswhenaspacecharacteriserro-neouslyinsertedinthemiddleofaterm.
(iii)Joinedterms.
Thiserror,whichhasafrequencyof4.
9%,happenswhenthespacebetweentermsisomitted,resultingintheunexpectedconcatenationofterms.
(iv)Erroneoussymbol.
Thisissueaccountsfor0.
1%ofallerrors,usuallyrepresentsdirtoraprintingerroratthescanneddocument.
Issues(i)to(iii)canpotentiallyaectrecallasrelevantdocumentscontain-ingtermswiththeseproblemswillnotberetrievedbythequery.
Issue(iv)canalsolowerprecisionsincethefragmentofatermcanmatchaqueryforwhichthedocumentisnotrelevant(e.
g.
,iftheterm"encounter"foundinadocumentdisfragmentedintothetokens"en"and"counter",thendcanerroneouslymatchaquerywiththeterm"counter").
Twoalternativesfortheselectionofcandidatetermswereemployed.
Intherst,anytermfromanydocumentcouldbeselected.
Inthesecond,amoretargetedselectionwasmadeinwhichcandidatetermsweretakenonlyfromjudgeddocuments(i.
e.
,thedocumentsintheqrelsle).
Usingthedesirederrorrate,weiteratethrougheverycandidateterminthedocuments.
Thetermischosentobemodiedwithaprobabilityequivalenttothegivenerrorrate.
Ifthetermisselected,thenthechoiceoferrorismadetakingtheobservedfrequency.
Thiswasachievedbydrawingarandomoatbetween0and1andmatchingitagainstthecorrespondingerrorfrequency.
Theselectionofwhichexchangetoapplywasmadeusingtournamentselectionintenroundsaccordingtothefrequencyoftheexchange.
4ExperimentalEvaluationThisSectiondescribestheexperimentalevaluationoftheerrorinsertionmethodtoassesstheimpactofOCRerrorsinIRsystems.
Theresources,tools,andcongurationsusedinourexperimentswereasfollows.
Data.
Togeneratethecharacterexchangelist,wetookasampleof900PDFdocumentscontainingabstractsfromresearcharticlespublishedatthewebsite106G.
T.
Bazzoetal.
ofaBrazilianOilCompany1.
Theextractedtextwasmanuallycheckedandtheextractionerrorswerexedtocreatethelistofpairs.
TheIRcollectionusedwasFolhadeSaoPaulo,aBrazilianNewspaper.
Ithas103Kdocuments,100queries,andithasbeenusedinimportantevaluationcampaignssuchasCLEF[11].
Table1.
Numberofindexterms(inthousands)andtheproportionalincreaseincomparisontothebaseline.
SettingBaseline1%5%10%25%50%ALL-NS273355(30%)523(91%)659(141%)937(243%)1,243(355%)ALLST203253(24%)352(73%)434(113%)605(197%)801(293%)JDNS273342(25%)473(73%)574(110%)770(182%)983(260%)JDST203245(20%)324(59%)386(90%)514(153%)660(224%)Tools.
TheOCRsoftwareusedwasAbbyyFinereader142.
ThechoicewasmadeafteritsgoodresultcomparedtoanumberofotheralternativesincludingTesseract,a9t9,Omnipage,andWondershare.
TheIRSystemwasApacheSolr3.
ExperimentalProcedure.
Inourexperimentalprocedure,wevariedthefol-lowingparameters.
TheRankingfunction,takingthreepossibilities:Cosine(COS)usingTF-IDFweighting,BM25,andDivergencefromRandomness(DFR).
Theuseofstemming:applyingalightstemmer(ST)andnostem-ming(NS).
Theerrorrateswere1%,5%,10%,25%,and50%.
Baselinerunsusingtheoriginaldocumentswerealsocreated.
Thecandidatetermsforerrorinsertionwereeitheranytermfromanydocument(ALL)oranytermfromthejudgeddocuments(JD).
Thesevariationsamountedtoatotalof72experimen-talruns,whichwereevaluatedusingstandardIRmetrics.
StatisticalsignicancewasmeasuredusingT-tests.
Queriesweremadebysimplytakingthetitleeldfromthetopics.
Thegoalwastosimulaterealqueriesthataretypicallyshort.
Table1showsthenumberofindextermsforthecombinationoferrorrates,useofstemming,andcandidateterms.
Asexpected,thenumberofindexentriesgrowsremarkablywiththeerrorrates,reachingmorethanafour-foldincreaseforunstemmedrunswitha50%errorrate.
TheresultsforallexperimentalrunsareinTable2.
Therunsinwhichthemeanaverageprecision(MAP)decreasewasfoundtobestatisticallysignicant(inrelationtothebaseline)ata99%condenceintervalareinadarkershadeandtheoneswitha95%signicanceareinalightershade.
ThebestrankingfunctionintermsofabsoluteMAPvalueswasDFR,fol-lowedbyBM25.
However,therewerenodierencesontheirrobustnessin1http://publicacoes.
petrobras.
com.
br/.
2https://www.
abbyy.
com/.
3https://lucene.
apache.
org/solr/.
AssessingtheImpactofOCRErrorsinInformationRetrieval107Table2.
MAPResultsforallcongurations.
Thenumbersinbracketsindicatetheproportionalchange.
SettingBaseline1%5%10%25%50%ALL-BM25-NS0.
2510.
249(0.
8%)0.
243(3.
2%)0.
232(7.
7%)0.
211(16.
2%)0.
156(38.
1%)ALL-BM25-ST0.
2940.
291(0.
8%)0.
288(1.
9%)0.
281(4.
4%)0.
263(10.
4%)0.
223(23.
9%)ALL-COS-NS0.
2420.
243(0.
2%)0.
239(1.
3%)0.
218(9.
8%)0.
202(16.
5%)0.
166(31.
6%)ALL-COS-ST0.
2750.
273(0.
9%)0.
266(3.
6%)0.
256(7.
1%)0.
251(8.
8%)0.
223(19.
0%)ALL-DFR-NS0.
2630.
262(0.
2%)0.
258(1.
8%)0.
240(8.
8%)0.
222(15.
6%)0.
180(31.
5%)ALL-DFR-ST0.
3070.
304(1.
1%)0.
306(0.
4%)0.
295(4.
2%)0.
276(10.
1%)0.
250(18.
7%)JD-BM25-NS0.
2510.
248(1.
4%)0.
243(3.
4%)0.
232(7.
6%)0.
226(10.
2%)0.
169(32.
9%)JD-BM25-ST0.
2940.
290(1.
2%)0.
284(3.
4%)0.
280(4.
6%)0.
261(11.
2%)0.
229(21.
9%)JD-COS-NS0.
2420.
240(0.
6%)0.
237(2.
0%)0.
218(10.
0%)0.
200(17.
3%)0.
152(37.
1%)JD-COS-ST0.
2750.
277(0.
7%)0.
271(1.
7%)0.
263(4.
5%)0.
247(10.
4%)0.
209(24.
2%)JD-DFR-NS0.
2630.
263(0.
0%)0.
252(4.
2%)0.
239(9.
2%)0.
221(16.
2%)0.
163(38.
2%)JD-DFR-ST0.
3070.
306(0.
4%)0.
300(2.
3%)0.
294(4.
3%)0.
281(8.
6%)0.
236(23.
2%)thepresenceofOCRerrorsastheirpatternofMAPdecreasewasthesame.
Strangely,intworunsinwhichthecosinewasused,theinsertionoferrorsata1%rateimprovedtheperformance(ALL-COS-NSandJD-COS-ST).
Thiscanbeexplainedbythefactthaterrorsareinsertedbothrelevantandnon-relevantdocuments.
Inthesecases,theerrorswereintroducedinnon-relevantdocumentswhichmaderelevantdocumentsberankedhigher.
Theuseofstemmingconsistentlyimprovedtheresults–i.
e.
,allrunsinwhichstemmingwasusedhadhigherscoresthantheirunstemmedcounterparts.
StemminghasmadetherunsmorerobusttotheOCRerrors.
ThiscanbeseencomparingthelossinMAPoftherunswithandwithoutstemming.
Nearlyallrunsinwhichstemmingwasusedhadsmallerlossesthantheircounterparts.
Furthermore,theaidofstemmingismorenoticeableintherunswithhighererrorrates.
ThebenetofstemmingcanbeexplainedbythefactthattheOCRerrorcanbeinthesuxthatisremoved.
Lookingatthecorrelationbetweenthenumberofindexterms(Table2)andMAP,wendastrongnegativecorrelationof0.
86.
Whenthecorrelationismeasuredforstemmedandunstemmedrunsseparately,thenegativecorrelationsare0.
81and0.
90,respectively.
Thisgivesfurthersupporttothebenetsofstemming.
Lookingatoursampleofalignedextractedandexpectedtexts(assembledfromrealdocuments)weobservedanerrorrateof1.
5%.
ConsideringthisrateandtheresultsinTable2,onecanconcludethattheerrorsdonothaveasevereimpactonIRassignicantimpactsareobservedstartingat5%.
Ata10%rate,allrunsaresignicantlyaected.
Recallthatthissmallerrorratewasfoundusingthesoftwarewhichprovidedthebestresultsonrelativelyrecentdocuments.
SomestudiesthatprovidestatisticsoftheproportionoferrorsfoundinOCR-eddocumentsreportndingerrorratesofaround20%inhistoricaldocuments[4,5,14].
Atthaterrorrate,thedegradationisconsideredstatisticallysignicant.
108G.
T.
Bazzoetal.
Comparingthetwochoicesofcandidatetermsforerrorinsertionwendclosescores.
Thismeansthattheerrorinjectiontargetingthejudgeddocumentsdidnothaveaninuenceontheresults.
5ConclusionDespitehavingbeeninvestigatedfordecades,theissuesassociatedwithretriev-ingnoisytextstillremainunsolvedinmanyIRsystems.
Inthispaper,werevisitthistopicbyassessingtheimpactthatdierenterrorrateshaveonretrievalper-formance.
Wetesteddierentsetups,includingrankingalgorithmsandtheuseofstemming.
Ourndingssuggestthatstatisticallysignicantdegradationstartsataworderrorrateof5%andthatstemmingisabletomakesystemsmoreresilienttotheseerrors.
Asfuturework,itwouldbeusefultoassesswhichtypeoferroridentiedin(Sect.
3)hasthegreatestimpactinretrievalquality.
Acknowledgments.
ThisworkwaspartiallysupportedbyPetrobras,CNPq/Brazil,andbyCAPESFinanceCode001.
References1.
Beitzel,S.
M.
,Jensen,E.
C.
,Grossman,D.
A.
:AsurveyofretrievalstrategiesforOCRtextcollections.
In:ProceedingsoftheSymposiumonDocumentImageUnderstandingTechnologies(2003)2.
Chiron,G.
,Doucet,A.
,Coustaty,M.
,Moreux,J.
:ICDAR2017competitiononpost-OCRtextcorrection.
In:InternationalConferenceonDocumentAnalysisandRecognition(ICDAR),vol.
01,pp.
1423–1428(2017)3.
Croft,W.
B.
,Harding,S.
,Taghva,K.
,Borsack,J.
:AnevaluationofinformationretrievalaccuracywithsimulatedOCRoutput.
In:SymposiumofDocumentAnal-ysisandInformationRetrieval(1994)4.
Droettboom,M.
:Correctingbrokencharactersintherecognitionofhistoricalprinteddocuments.
In:Proceedings2003JointConferenceonDigitalLibraries,pp.
364–366,May20035.
Evershed,J.
,Fitch,K.
:CorrectingnoisyOCR:contextbeatsconfusion.
In:Pro-ceedingsoftheFirstInternationalConferenceonDigitalAccesstoTextualCulturalHeritage(DATeCH2014),pp.
45–51(2014)6.
Grimes,S.
:Unstructureddataandthe80percentrule,p.
10.
CarabridgeBridge-points(2008)7.
Kantor,P.
B.
,Voorhees,E.
M.
:TheTREC-5confusiontrack:comparingretrievalmethodsforscannedtext.
Inf.
Retrieval2(2),165–176(2000).
https://doi.
org/10.
1023/A:10099026095708.
Needleman,S.
,Wunsch,C.
:Ageneralmethodapplicabletothesearchforsim-ilaritiesintheaminoacidsequenceoftwoproteins.
J.
Mol.
Biol.
48,443–453(1970)9.
Nguyen,T.
,Jatowt,A.
,Coustaty,M.
,Nguyen,N.
,Doucet,A.
:DeepstatisticalanalysisofOCRerrorsforeectivepost-OCRprocessing.
In:ACM/IEEEJointConferenceonDigitalLibraries(JCDL),pp.
29–38,June2019AssessingtheImpactofOCRErrorsinInformationRetrieval10910.
Parapar,J.
,Freire,A.
,Barreiro,A.
:RevisitingN-grambasedmodelsforretrievalindegradedlargecollections.
In:Boughanem,M.
,Berrut,C.
,Mothe,J.
,Soule-Dupuy,C.
(eds.
)ECIR2009.
LNCS,vol.
5478,pp.
680–684.
Springer,Heidelberg(2009).
https://doi.
org/10.
1007/978-3-642-00958-76611.
Peters,C.
,Braschler,M.
:Europeanresearchletter:cross-languagesystemeval-uation:theCLEFcampaigns.
J.
Am.
Soc.
Inf.
Sci.
Technol.
52(12),1067–1072(2001)12.
Rigaud,C.
,Doucet,A.
,Coustaty,M.
,Moreux,J.
P.
:ICDAR2019competitiononpost-OCRtextcorrection.
In:InternationalConferenceonDocumentAnalysisandRecognition(ICDAR)(2019)13.
Taghva,K.
,Borsack,J.
,Condit,A.
:Evaluationofmodel-basedretrievaleective-nesswithOCRtext.
ACMTrans.
Inf.
Syst.
14(1),64–93(1996)14.
Tanner,S.
,Munoz,T.
,Ros,P.
H.
:Measuringmasstextdigitizationqualityandusefulness:lessonslearnedfromassessingtheOCRaccuracyoftheBritishlibrary's19thcenturyonlinenewspaperarchive.
D-LibMag.
15(7/8),1082–9873(2009)
Moreira(B)InstituteofInformatics,UFRGS,PortoAlegre,Brazil{guilherme.
bazzo,gustavo.
lorentz,dsvargas,viviane}@inf.
ufrgs.
brAbstract.
AsignicantamountofthetextualcontentavailableontheWebisstoredinPDFles.
Theselesaretypicallyconvertedintoplaintextbeforetheycanbeprocessedbyinformationretrievalortextminingsystems.
Automaticconversiontypicallyintroducesvariouserrors,espe-ciallyifOCRisneeded.
Inthisempiricalstudy,wesimulateOCRerrorsandinvestigatetheimpactthatmisspelledwordshaveonretrievalaccu-racy.
Inordertoquantifysuchimpact,errorsweresystematicallyinsertedatvaryingratesinaninitiallycleanIRcollection.
Ourresultsshowedthatsignicantimpactsarenoticedstartingata5%errorrate.
Further-more,stemminghasproventomakesystemsmorerobusttoerrors.
Keywords:OCR·Retrievaleectiveness·Noisytext1IntroductionEstimatessaythatmostinformationusefulfororganizationsisrepresentedinanunstructuredformat,predominantlyasfreetext[6].
AsignicantportionofthisusefulinformationisstoredinPDFles–researcharticles,books,companyreports,andpresentationsaretypicallydisseminatedinPDFformat.
PDFdoc-umentsneedtobeconvertedintoplaintextbeforebeingprocessedbyanInfor-mationRetrieval(IR)oratextminingsystem.
Theselescaneitherbedigitallycreatedorcreatedfromscanneddocuments.
Whiletheformeraregeneratedfromanoriginalelectronicversionofadocument(i.
e.
,containthetextcharacters),thelatercontainimagesoftheoriginaldocumentandneedtogothroughOpticalCharacterRecognition(OCR)sothattheircontentscanbeextracted.
Despitebeingaddressedbyresearchersfordecades,OCRisstillimperfect.
Asaresult,theextractedtextcontainserrorsthattypicallyinvolvecharacterexchanges.
AlthoughdigitallycreatedPDFsarecleaner,theyarenotproblem-freesince,forexample,hyphenatedterms(duetoseparationintosyllables)maybeidenti-edastwotokensandindexedincorrectly.
ExtractionerrorscanhaveanegativeimpactonthequalityofIRsystemsandarefoundeveninmainstreamsearchengines.
Figure1presentsanexcerptoftheresultpagegeneratedbyGoogleScholarforthequery"informationretrievaltechniques".
Inthesmallsnippetfromamatchingdocument,wecanseefourcSpringerNatureSwitzerlandAG2020J.
M.
Joseetal.
(Eds.
):ECIR2020,LNCS12036,pp.
102–109,2020.
https://doi.
org/10.
1007/978-3-030-45442-5_13AssessingtheImpactofOCRErrorsinInformationRetrieval103errors–threetermswereerroneouslysegmentedintotwotokens,andtwotermswereconcatenatedintoonetoken.
Theeectisthataquerywiththecorrectspellingfore.
g.
,"thebarriersencounteredinretrievinginformation"wouldbeunabletoretrievethatdocument.
Approachesfortreatingmisspelledqueriescannotsolvethisproblemastheissueisinthedocument,notinthequery.
Furthermore,thereareimportantdierencesbetweenthetypesoferrorsmadebyhumanswhiletypingandthosemadebyOCRsystems[9].
Thefactthatthisisstillanopenissueisevidencedbytworecentcompeti-tionsorganizedinthescopeoftheInternationalConferenceonDocumentAnal-ysisandRecognition(ICDAR)[2,12].
Thebestperformingapproachesemploystate-of-the-artmethodssuchascharacter-basedNeuralMachineTranslationandrecurrentnetworks(bidirectionalLSTMs)takingBERTmodelsasinput.
Thebestresultsfortheerrordetectiontaskwerebelow0.
7intermsofF1inseverallanguages[12],showingthatthereisstillalotofroomforimprovement.
OurgoalistorevisittheproblemofretrievingOCR-edtextandquantifytheimpactthattheseerrorshaveontheaccuracyofIRsystems.
Ideally,toquantifytheimpact,oneneedsanIRtestcollectionwithsourcePDFles,theirextractedandcorrectedversions,asetofqueries,andtheircorrespondingrelevancejudg-ments.
Unfortunately,tothebestofourknowledge,suchacollectiondoesnotexistandcreatingonewoulddemandsignicanteort.
Inlinewithpreviousworksonthistopic[3,7],ourapproachwastosystematicallyinserterrorsinastandardIRcollectioncontainingplaintextdocuments,queries,andrelevancejudgments.
Dierenterrorratesweretestedsothatwecouldgaugetheireects.
Inordertosimulaterealerrors,wecollected,assessed,andmanuallycorrectedasampleofOCR-edPDFdocuments.
Statisticsdrawnfromthissamplewereusedtoguidetheerrorinsertionapproach.
OurexperimentswereperformedinanIRcollectioncontainingdocumentsinPortuguese–alanguagethatmakesuseofdiacritics(e.
g.
,`a,a,a,a,e,,cetc.
).
Thesecharactersaretypicallyamongtheoneswithmoreextractionerrors.
Theresultsshowedthaterrorratesstartingat5%cancauseasignicantimpactinmanysystemcongurationsandthatstemmingmakessystemsmorerobusttocopingwitherrors.
(a)ExcerptfromGoogleScholar(b)SourcePDFleFig.
1.
Exampleofextractionerrorsidentiedinamainstreamsearchengine.
2RelatedWorkExistingworkondealingwithOCR-edtextsspansoveralongperiodandfocusedonapproachesfordetectingandxingerrors[4,5,9,10].
Specicallyonthetopic104G.
T.
Bazzoetal.
ofimprovingtheretrievalofOCRtext,Beitzeletal.
[1]surveyedanumberofsolutions–mostofwhichdatetothelate1990s.
TRECranaconfusiontracktoassessretrievaleectivenessondegradedcollections.
Theirmodiedtestcollectionshad5and20%charactererrorrates.
Fiveteamstookpartinthechallenge.
Theorganizersreportedthatcounter-intuitiveresultshadbeenfoundandthat"thereisstillagreatdealtobeunderstoodabouttheinteractionofthediverseapproaches"[7].
Croftetal.
[3]sharesomesimilaritieswithourwork.
However,ratherthaninjectingerrorsintoacleantextcollection,theauthorsoptedtorandomlyselectwordstobediscardedfromthedocumentand,asaconsequence,theywerenotindexed.
Thelimitationofsuchapproachisthatitdoesnotaccountforissueswithwrongsegmentation(addingorsuppressingthespacecharacter)orcasesinwhichtheerrormodiesthewordintoanothervalidword.
Themainndingwasthatperformancedegradationwasmorecriticalforveryshortdocuments.
Inadetailedinvestigation,Taghvaetal.
[13]observedthatwhiletheresultsseemtohaveinsignicantdegradationonaverage,individualqueriescanbegreatlyimpacted.
Furthermore,theyreportanimpressiveincreaseinthenumberofindextermsinthepresenceoferrorsandthatrelevancefeedbackmethodsareunabletoovercomeOCRerrors.
Thispaperdiersfromexistingworksinanumberofaspects.
Thecongura-tionsweassessincludetheuseofstemming,morerecentrankingalgorithms,andmorelevelsofdegradation.
Finally,weexperimentwithadierenttestcollectioninalanguagethathasnotbeenextensivelyusedforIR.
3SimulatingErrorsThemethodologyweproposetoinserterrorsisshowninFig.
2.
Ourgoalistoreplicate,asmuchaspossible,thepatternofproblemsthatactuallyhappeninPDFconversionstoplaintextfrombothdigitallycreatedandscanneddocu-ments.
Inordertoachievethat,oneneedsasampleofalignedpairsofextractedandexpectedcontents(shownasinputinFig.
2).
Theexpectedcontentsneedtobemanuallyproducedbycorrectingtheextractedtext.
Thisisalaboriousandtime-consumingtask.
Bycomparingthesepairsatcharacterlevel,wegenerateacharacterexchangelist.
pairsGenerationofcharacterexchangelistErrorRateSourceDocumentsErrorInsertionDocumentswithErrorsCandidateSelectionFig.
2.
Approachforerrorinjectionindocuments.
AssessingtheImpactofOCRErrorsinInformationRetrieval105Toalignthepairs,weusedtheNeedleman-Wunsch[8]algorithm.
Thisalgorithmgeneratesthebest(global)alignmentoftwosequences,withtheadditionofgapstoaccountformismatchingcharacters.
Wefoundexchangesofone-to-one(e.
g.
,"inserted"→"insorted"),one-to-two(e.
g.
,"document"→"docurnent"),ortwo-to-one(e.
g.
,"light"→"hght")characters.
Thefrequenciesoftheexchangeswerecomputedandstoredinthecharacterexchangelist.
Then,theyareusedtobiastheerrorinsertionalgorithmtowardsthemostfrequentexchanges.
Byanalyzingthepatternoferrorsfound,wecameupwithacategorizationofthetypesofissues.
(i)Exchangeofcharacters.
Thisisthemostcommonerrorfound(90%ofallerrors)anditiscausedbythelowqualityofthedocumentsweareprocessing.
Everyexchangeinourexchangelisthasassignedtoitselfthefrequencyofitsappearance,whichweuse,inconjunctionwiththetournamentselection,toelectoneerrortoagiventerm.
(ii)Separatedterms.
Thiserrorcorrespondsto5%ofthecasesandithappenswhenaspacecharacteriserro-neouslyinsertedinthemiddleofaterm.
(iii)Joinedterms.
Thiserror,whichhasafrequencyof4.
9%,happenswhenthespacebetweentermsisomitted,resultingintheunexpectedconcatenationofterms.
(iv)Erroneoussymbol.
Thisissueaccountsfor0.
1%ofallerrors,usuallyrepresentsdirtoraprintingerroratthescanneddocument.
Issues(i)to(iii)canpotentiallyaectrecallasrelevantdocumentscontain-ingtermswiththeseproblemswillnotberetrievedbythequery.
Issue(iv)canalsolowerprecisionsincethefragmentofatermcanmatchaqueryforwhichthedocumentisnotrelevant(e.
g.
,iftheterm"encounter"foundinadocumentdisfragmentedintothetokens"en"and"counter",thendcanerroneouslymatchaquerywiththeterm"counter").
Twoalternativesfortheselectionofcandidatetermswereemployed.
Intherst,anytermfromanydocumentcouldbeselected.
Inthesecond,amoretargetedselectionwasmadeinwhichcandidatetermsweretakenonlyfromjudgeddocuments(i.
e.
,thedocumentsintheqrelsle).
Usingthedesirederrorrate,weiteratethrougheverycandidateterminthedocuments.
Thetermischosentobemodiedwithaprobabilityequivalenttothegivenerrorrate.
Ifthetermisselected,thenthechoiceoferrorismadetakingtheobservedfrequency.
Thiswasachievedbydrawingarandomoatbetween0and1andmatchingitagainstthecorrespondingerrorfrequency.
Theselectionofwhichexchangetoapplywasmadeusingtournamentselectionintenroundsaccordingtothefrequencyoftheexchange.
4ExperimentalEvaluationThisSectiondescribestheexperimentalevaluationoftheerrorinsertionmethodtoassesstheimpactofOCRerrorsinIRsystems.
Theresources,tools,andcongurationsusedinourexperimentswereasfollows.
Data.
Togeneratethecharacterexchangelist,wetookasampleof900PDFdocumentscontainingabstractsfromresearcharticlespublishedatthewebsite106G.
T.
Bazzoetal.
ofaBrazilianOilCompany1.
Theextractedtextwasmanuallycheckedandtheextractionerrorswerexedtocreatethelistofpairs.
TheIRcollectionusedwasFolhadeSaoPaulo,aBrazilianNewspaper.
Ithas103Kdocuments,100queries,andithasbeenusedinimportantevaluationcampaignssuchasCLEF[11].
Table1.
Numberofindexterms(inthousands)andtheproportionalincreaseincomparisontothebaseline.
SettingBaseline1%5%10%25%50%ALL-NS273355(30%)523(91%)659(141%)937(243%)1,243(355%)ALLST203253(24%)352(73%)434(113%)605(197%)801(293%)JDNS273342(25%)473(73%)574(110%)770(182%)983(260%)JDST203245(20%)324(59%)386(90%)514(153%)660(224%)Tools.
TheOCRsoftwareusedwasAbbyyFinereader142.
ThechoicewasmadeafteritsgoodresultcomparedtoanumberofotheralternativesincludingTesseract,a9t9,Omnipage,andWondershare.
TheIRSystemwasApacheSolr3.
ExperimentalProcedure.
Inourexperimentalprocedure,wevariedthefol-lowingparameters.
TheRankingfunction,takingthreepossibilities:Cosine(COS)usingTF-IDFweighting,BM25,andDivergencefromRandomness(DFR).
Theuseofstemming:applyingalightstemmer(ST)andnostem-ming(NS).
Theerrorrateswere1%,5%,10%,25%,and50%.
Baselinerunsusingtheoriginaldocumentswerealsocreated.
Thecandidatetermsforerrorinsertionwereeitheranytermfromanydocument(ALL)oranytermfromthejudgeddocuments(JD).
Thesevariationsamountedtoatotalof72experimen-talruns,whichwereevaluatedusingstandardIRmetrics.
StatisticalsignicancewasmeasuredusingT-tests.
Queriesweremadebysimplytakingthetitleeldfromthetopics.
Thegoalwastosimulaterealqueriesthataretypicallyshort.
Table1showsthenumberofindextermsforthecombinationoferrorrates,useofstemming,andcandidateterms.
Asexpected,thenumberofindexentriesgrowsremarkablywiththeerrorrates,reachingmorethanafour-foldincreaseforunstemmedrunswitha50%errorrate.
TheresultsforallexperimentalrunsareinTable2.
Therunsinwhichthemeanaverageprecision(MAP)decreasewasfoundtobestatisticallysignicant(inrelationtothebaseline)ata99%condenceintervalareinadarkershadeandtheoneswitha95%signicanceareinalightershade.
ThebestrankingfunctionintermsofabsoluteMAPvalueswasDFR,fol-lowedbyBM25.
However,therewerenodierencesontheirrobustnessin1http://publicacoes.
petrobras.
com.
br/.
2https://www.
abbyy.
com/.
3https://lucene.
apache.
org/solr/.
AssessingtheImpactofOCRErrorsinInformationRetrieval107Table2.
MAPResultsforallcongurations.
Thenumbersinbracketsindicatetheproportionalchange.
SettingBaseline1%5%10%25%50%ALL-BM25-NS0.
2510.
249(0.
8%)0.
243(3.
2%)0.
232(7.
7%)0.
211(16.
2%)0.
156(38.
1%)ALL-BM25-ST0.
2940.
291(0.
8%)0.
288(1.
9%)0.
281(4.
4%)0.
263(10.
4%)0.
223(23.
9%)ALL-COS-NS0.
2420.
243(0.
2%)0.
239(1.
3%)0.
218(9.
8%)0.
202(16.
5%)0.
166(31.
6%)ALL-COS-ST0.
2750.
273(0.
9%)0.
266(3.
6%)0.
256(7.
1%)0.
251(8.
8%)0.
223(19.
0%)ALL-DFR-NS0.
2630.
262(0.
2%)0.
258(1.
8%)0.
240(8.
8%)0.
222(15.
6%)0.
180(31.
5%)ALL-DFR-ST0.
3070.
304(1.
1%)0.
306(0.
4%)0.
295(4.
2%)0.
276(10.
1%)0.
250(18.
7%)JD-BM25-NS0.
2510.
248(1.
4%)0.
243(3.
4%)0.
232(7.
6%)0.
226(10.
2%)0.
169(32.
9%)JD-BM25-ST0.
2940.
290(1.
2%)0.
284(3.
4%)0.
280(4.
6%)0.
261(11.
2%)0.
229(21.
9%)JD-COS-NS0.
2420.
240(0.
6%)0.
237(2.
0%)0.
218(10.
0%)0.
200(17.
3%)0.
152(37.
1%)JD-COS-ST0.
2750.
277(0.
7%)0.
271(1.
7%)0.
263(4.
5%)0.
247(10.
4%)0.
209(24.
2%)JD-DFR-NS0.
2630.
263(0.
0%)0.
252(4.
2%)0.
239(9.
2%)0.
221(16.
2%)0.
163(38.
2%)JD-DFR-ST0.
3070.
306(0.
4%)0.
300(2.
3%)0.
294(4.
3%)0.
281(8.
6%)0.
236(23.
2%)thepresenceofOCRerrorsastheirpatternofMAPdecreasewasthesame.
Strangely,intworunsinwhichthecosinewasused,theinsertionoferrorsata1%rateimprovedtheperformance(ALL-COS-NSandJD-COS-ST).
Thiscanbeexplainedbythefactthaterrorsareinsertedbothrelevantandnon-relevantdocuments.
Inthesecases,theerrorswereintroducedinnon-relevantdocumentswhichmaderelevantdocumentsberankedhigher.
Theuseofstemmingconsistentlyimprovedtheresults–i.
e.
,allrunsinwhichstemmingwasusedhadhigherscoresthantheirunstemmedcounterparts.
StemminghasmadetherunsmorerobusttotheOCRerrors.
ThiscanbeseencomparingthelossinMAPoftherunswithandwithoutstemming.
Nearlyallrunsinwhichstemmingwasusedhadsmallerlossesthantheircounterparts.
Furthermore,theaidofstemmingismorenoticeableintherunswithhighererrorrates.
ThebenetofstemmingcanbeexplainedbythefactthattheOCRerrorcanbeinthesuxthatisremoved.
Lookingatthecorrelationbetweenthenumberofindexterms(Table2)andMAP,wendastrongnegativecorrelationof0.
86.
Whenthecorrelationismeasuredforstemmedandunstemmedrunsseparately,thenegativecorrelationsare0.
81and0.
90,respectively.
Thisgivesfurthersupporttothebenetsofstemming.
Lookingatoursampleofalignedextractedandexpectedtexts(assembledfromrealdocuments)weobservedanerrorrateof1.
5%.
ConsideringthisrateandtheresultsinTable2,onecanconcludethattheerrorsdonothaveasevereimpactonIRassignicantimpactsareobservedstartingat5%.
Ata10%rate,allrunsaresignicantlyaected.
Recallthatthissmallerrorratewasfoundusingthesoftwarewhichprovidedthebestresultsonrelativelyrecentdocuments.
SomestudiesthatprovidestatisticsoftheproportionoferrorsfoundinOCR-eddocumentsreportndingerrorratesofaround20%inhistoricaldocuments[4,5,14].
Atthaterrorrate,thedegradationisconsideredstatisticallysignicant.
108G.
T.
Bazzoetal.
Comparingthetwochoicesofcandidatetermsforerrorinsertionwendclosescores.
Thismeansthattheerrorinjectiontargetingthejudgeddocumentsdidnothaveaninuenceontheresults.
5ConclusionDespitehavingbeeninvestigatedfordecades,theissuesassociatedwithretriev-ingnoisytextstillremainunsolvedinmanyIRsystems.
Inthispaper,werevisitthistopicbyassessingtheimpactthatdierenterrorrateshaveonretrievalper-formance.
Wetesteddierentsetups,includingrankingalgorithmsandtheuseofstemming.
Ourndingssuggestthatstatisticallysignicantdegradationstartsataworderrorrateof5%andthatstemmingisabletomakesystemsmoreresilienttotheseerrors.
Asfuturework,itwouldbeusefultoassesswhichtypeoferroridentiedin(Sect.
3)hasthegreatestimpactinretrievalquality.
Acknowledgments.
ThisworkwaspartiallysupportedbyPetrobras,CNPq/Brazil,andbyCAPESFinanceCode001.
References1.
Beitzel,S.
M.
,Jensen,E.
C.
,Grossman,D.
A.
:AsurveyofretrievalstrategiesforOCRtextcollections.
In:ProceedingsoftheSymposiumonDocumentImageUnderstandingTechnologies(2003)2.
Chiron,G.
,Doucet,A.
,Coustaty,M.
,Moreux,J.
:ICDAR2017competitiononpost-OCRtextcorrection.
In:InternationalConferenceonDocumentAnalysisandRecognition(ICDAR),vol.
01,pp.
1423–1428(2017)3.
Croft,W.
B.
,Harding,S.
,Taghva,K.
,Borsack,J.
:AnevaluationofinformationretrievalaccuracywithsimulatedOCRoutput.
In:SymposiumofDocumentAnal-ysisandInformationRetrieval(1994)4.
Droettboom,M.
:Correctingbrokencharactersintherecognitionofhistoricalprinteddocuments.
In:Proceedings2003JointConferenceonDigitalLibraries,pp.
364–366,May20035.
Evershed,J.
,Fitch,K.
:CorrectingnoisyOCR:contextbeatsconfusion.
In:Pro-ceedingsoftheFirstInternationalConferenceonDigitalAccesstoTextualCulturalHeritage(DATeCH2014),pp.
45–51(2014)6.
Grimes,S.
:Unstructureddataandthe80percentrule,p.
10.
CarabridgeBridge-points(2008)7.
Kantor,P.
B.
,Voorhees,E.
M.
:TheTREC-5confusiontrack:comparingretrievalmethodsforscannedtext.
Inf.
Retrieval2(2),165–176(2000).
https://doi.
org/10.
1023/A:10099026095708.
Needleman,S.
,Wunsch,C.
:Ageneralmethodapplicabletothesearchforsim-ilaritiesintheaminoacidsequenceoftwoproteins.
J.
Mol.
Biol.
48,443–453(1970)9.
Nguyen,T.
,Jatowt,A.
,Coustaty,M.
,Nguyen,N.
,Doucet,A.
:DeepstatisticalanalysisofOCRerrorsforeectivepost-OCRprocessing.
In:ACM/IEEEJointConferenceonDigitalLibraries(JCDL),pp.
29–38,June2019AssessingtheImpactofOCRErrorsinInformationRetrieval10910.
Parapar,J.
,Freire,A.
,Barreiro,A.
:RevisitingN-grambasedmodelsforretrievalindegradedlargecollections.
In:Boughanem,M.
,Berrut,C.
,Mothe,J.
,Soule-Dupuy,C.
(eds.
)ECIR2009.
LNCS,vol.
5478,pp.
680–684.
Springer,Heidelberg(2009).
https://doi.
org/10.
1007/978-3-642-00958-76611.
Peters,C.
,Braschler,M.
:Europeanresearchletter:cross-languagesystemeval-uation:theCLEFcampaigns.
J.
Am.
Soc.
Inf.
Sci.
Technol.
52(12),1067–1072(2001)12.
Rigaud,C.
,Doucet,A.
,Coustaty,M.
,Moreux,J.
P.
:ICDAR2019competitiononpost-OCRtextcorrection.
In:InternationalConferenceonDocumentAnalysisandRecognition(ICDAR)(2019)13.
Taghva,K.
,Borsack,J.
,Condit,A.
:Evaluationofmodel-basedretrievaleective-nesswithOCRtext.
ACMTrans.
Inf.
Syst.
14(1),64–93(1996)14.
Tanner,S.
,Munoz,T.
,Ros,P.
H.
:Measuringmasstextdigitizationqualityandusefulness:lessonslearnedfromassessingtheOCRaccuracyoftheBritishlibrary's19thcenturyonlinenewspaperarchive.
D-LibMag.
15(7/8),1082–9873(2009)
六一云互联(41元)美国(24元)/香港/湖北/免费CDN/免费VPS
六一云互联六一云互联为西安六一网络科技有限公司的旗下产品。是一个正规持有IDC/ISP/CDN的国内公司,成立于2018年,主要销售海外高防高速大带宽云服务器/CDN,并以高质量.稳定性.售后相应快.支持退款等特点受很多用户的支持!近期公司也推出了很多给力的抽奖和折扣活动如:新用户免费抽奖,最大可获得500元,湖北新购六折续费八折折上折,全场八折等等最新活动:1.湖北100G高防:新购六折续费八折...
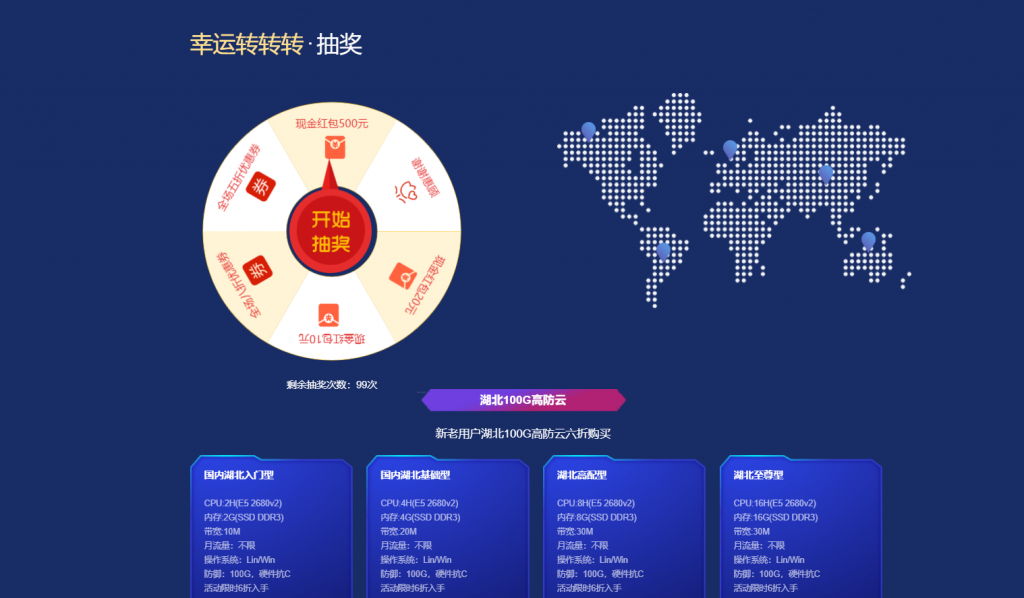
搬瓦工香港 PCCW 机房已免费迁移升级至香港 CN2 GIA 机房
搬瓦工最新优惠码优惠码:BWH3HYATVBJW,节约6.58%,全场通用!搬瓦工关闭香港 PCCW 机房通知下面提炼一下邮件的关键信息,原文在最后面。香港 CN2 GIA 机房自从 2020 年上线以来,网络性能大幅提升,所有新订单都默认部署在香港 CN2 GIA 机房;目前可以免费迁移到香港 CN2 GIA 机房,在 KiwiVM 控制面板选择 HKHK_8 机房进行迁移即可,迁移会改变 IP...
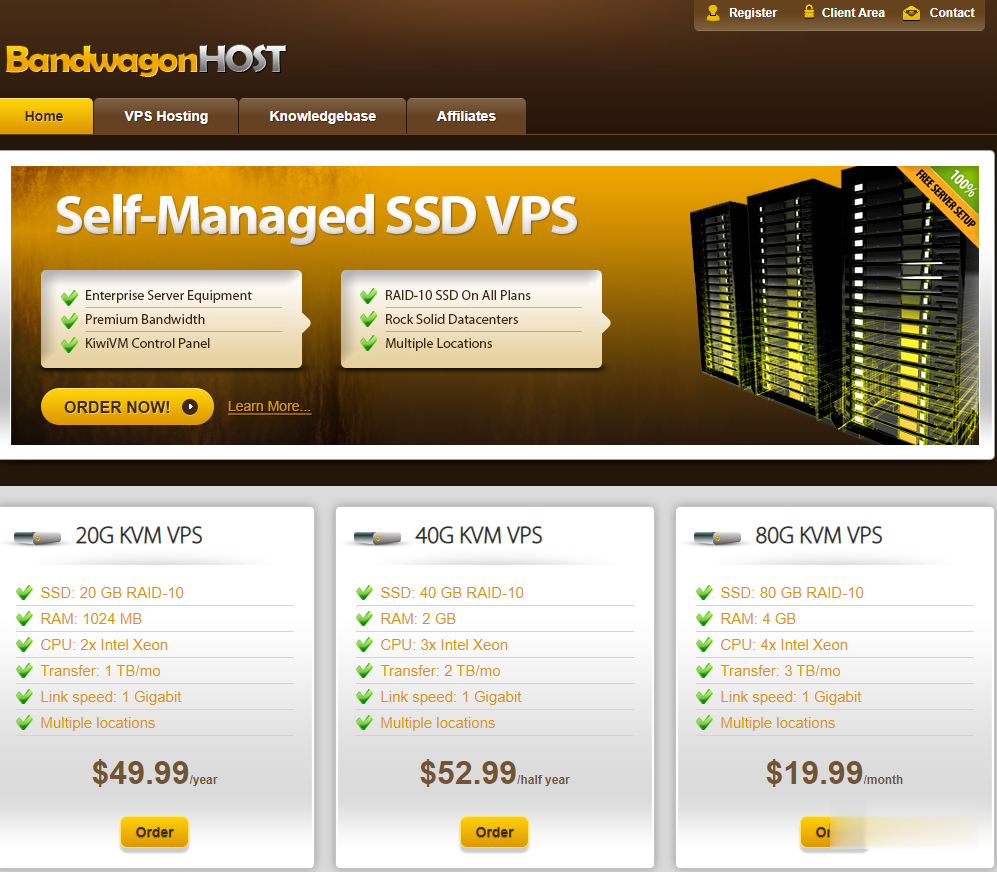
Fiberia.io:$2.9/月KVM-4GB/50GB/2TB/荷兰机房
Fiberia.io是个新站,跟ViridWeb.com同一家公司的,主要提供基于KVM架构的VPS主机,数据中心在荷兰Dronten。商家的主机价格不算贵,比如4GB内存套餐每月2.9美元起,采用SSD硬盘,1Gbps网络端口,提供IPv4+IPv6,支持PayPal付款,有7天退款承诺,感兴趣的可以试一试,年付有优惠但建议月付为宜。下面列出几款主机配置信息。CPU:1core内存:4GB硬盘:...
赛酷ocr为你推荐
-
中国电信互联星空中国电信宽带于互联星空的区别bluestacks安卓模拟器BlueStacks如何安装使用?网店推广网站网店怎么推广?iphone越狱后怎么恢复苹果手机越狱后怎么恢复硬盘人移动硬盘的优缺点宽带接入服务器用wifi连不上服务器怎么办rewritebase为什么我写.htaccess这个 rewriterule 进入死循环了,高手帮忙修改去鼠标加速度怎样去除电脑鼠标加速?关闭qq相册图标怎样熄灭QQ相册图标熊猫直播频道熊猫tv主播怎么赚钱?